Redis+Mysql模式和内存+硬盘模式的异同及redis的应用场景——转载
2016-01-29 00:00
766 查看
摘要: redis擅长保存元数据类的数据,也就是说描述性的而不是数据本身

首先,我们知道,mysql是持久化存储,存放在磁盘里面,检索的话,会涉及到一定的IO,为了解决这个瓶颈,于是出现了缓存,比如现在用的最多的 memcached(简称mc)。首先,用户访问mc,如果未命中,就去访问mysql,之后像内存和硬盘一样,把数据复制到mc一部分。
redis和mc都是缓存,并且都是驻留在内存中运行的,这大大提升了高数据量web访问的访问速度。然而mc只是提供了简单的数据结构,比如 string存储;redis却提供了大量的数据结构,比如string、list、set、hashset、sorted set这些,这使得用户方便了好多,毕竟封装了一层实用的功能,同时实现了同样的效果,当然用redis而慢慢舍弃mc。
内存和硬盘的关系,硬盘放置主体数据用于持久化存储,而内存则是当前运行的那部分数据,CPU访问内存而不是磁盘,这大大提升了运行的速度,当然这是基于程序的局部化访问原理。
推理到redis+mysql,它是内存+磁盘关系的一个映射,mysql放在磁盘,redis放在内存,这样的话,web应用每次只访问redis,如果没有找到的数据,才去访问Mysql。
然而redis+mysql和内存+磁盘的用法最好是不同的。
其实redis的强项也不在此,它擅长保存元数据类的数据,也就是说描述性的而不是数据本身
就此我假定了redis的几个应用场景,请大家批评指正:
存放计数器的数字
存放检索关键词的id列表(不放内容)
存放用户之间的follow关系(非用户信息)
存放简单的静态Html,而非所有的CSS和JS
总之发现,就是redis大量存放的是数据表的索引字段,如果刚好用到符合条件的信息,可以根据索引字段,再去 mysql查找,比如搜索关键词”redis”,第一步我们去mysql获取redis相关的信息返回给用户,然后记录一个zset,将redis作为名 字,将搜索到的每个Id以先后顺序存在里面,那么下次有人搜索”redis”,直接根据该列表去mysql找对应id的信息就行了,这已经大大提升了访问 速度。
下图是一个检索的流程图:

redis+mysql和内存+硬盘类似的地方
首先看图: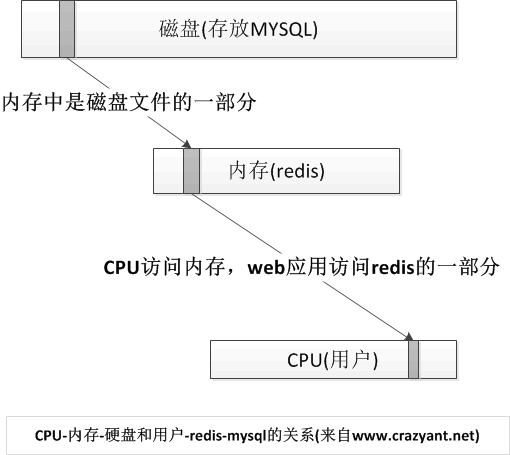
首先,我们知道,mysql是持久化存储,存放在磁盘里面,检索的话,会涉及到一定的IO,为了解决这个瓶颈,于是出现了缓存,比如现在用的最多的 memcached(简称mc)。首先,用户访问mc,如果未命中,就去访问mysql,之后像内存和硬盘一样,把数据复制到mc一部分。
redis和mc都是缓存,并且都是驻留在内存中运行的,这大大提升了高数据量web访问的访问速度。然而mc只是提供了简单的数据结构,比如 string存储;redis却提供了大量的数据结构,比如string、list、set、hashset、sorted set这些,这使得用户方便了好多,毕竟封装了一层实用的功能,同时实现了同样的效果,当然用redis而慢慢舍弃mc。
内存和硬盘的关系,硬盘放置主体数据用于持久化存储,而内存则是当前运行的那部分数据,CPU访问内存而不是磁盘,这大大提升了运行的速度,当然这是基于程序的局部化访问原理。
推理到redis+mysql,它是内存+磁盘关系的一个映射,mysql放在磁盘,redis放在内存,这样的话,web应用每次只访问redis,如果没有找到的数据,才去访问Mysql。
然而redis+mysql和内存+磁盘的用法最好是不同的。
redis+mysql和内存+硬盘运行模式是不同的
了解过内存和硬盘运行过程的同学,都知道他俩之间通过页面置换算法进行调度,也就是说每次是按块将数据从硬盘换入或者换出内存,比如硬盘有一个100G的文件,如果要读这个文件,内存中每次只放该文件10MB的一部分(图1中的小块就是这个意思)。
于是有人会猜测,mysql存储了100G的数据,用户访问mysql的时候,把10MB数据拷贝到redis,比如select一个id=1000的数 据,那就把id=10到id=9999的数据放到redis,用于下次访问。可是关键在于mysql数据的访问,并不是文件这种局部性原理,不同的用户访 问的是完全不同的东西,跟id的次序没有任何关系。其实redis的强项也不在此,它擅长保存元数据类的数据,也就是说描述性的而不是数据本身
就此我假定了redis的几个应用场景,请大家批评指正:
存放计数器的数字
存放检索关键词的id列表(不放内容)
存放用户之间的follow关系(非用户信息)
存放简单的静态Html,而非所有的CSS和JS
总之发现,就是redis大量存放的是数据表的索引字段,如果刚好用到符合条件的信息,可以根据索引字段,再去 mysql查找,比如搜索关键词”redis”,第一步我们去mysql获取redis相关的信息返回给用户,然后记录一个zset,将redis作为名 字,将搜索到的每个Id以先后顺序存在里面,那么下次有人搜索”redis”,直接根据该列表去mysql找对应id的信息就行了,这已经大大提升了访问 速度。
下图是一个检索的流程图:
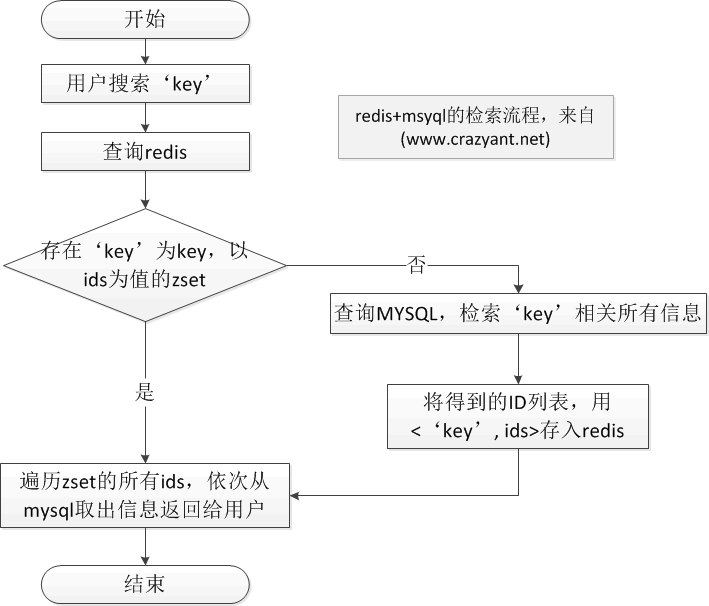

相关文章推荐
- 关于Redis中的Replication
- Redis-分片
- Windows上安装Redis
- Redis
- 基于Java Client的Redis与Tarantool HASH性能对比
- Redis-分片
- Redis整合Spring结合使用缓存实例
- Redis (一) CentOS 安装Redis 2.8.9
- Redis集群搭建与应用
- c#之Redis实践list,hashtable
- redis练习手册<二>快速入门
- Redis缓存相关
- Redis 笔记
- 学习Redis多数据库
- linux下redis的安装
- SpringMVC通过Redis实现缓存主页
- redis练习手册<一>redis的介绍和安装
- Redis 集群方案
- Linux下php安装Redis扩展
- linux下编译php扩展:php7安装redis为例