七.学习数据结构之树
2016-01-25 12:24
393 查看
1.简单的总结
为何数据结构难学:因为计算机内存是线性一维的,而我们要处理的数据都是比较复杂的,那么怎么把这么多复杂的数据保存在计算机中来保存本
身就是一个难题,而计算机在保存线性结构的时候比较好理解,尤其是数
组和链表只不过是连续和离散的问题,线性结构是我们学习的重点,因为
线性算法比较成熟,无论C++还是Java中都有相关的工具例如Arraylist.
Linkedlist,但是在Java中没有树和图,因为非线性结构太复杂了,他的
操作远远大于线性结构的操作。即使SUN公司也没造出来。
1.1 逻辑结构:(就是在你大脑里面能产生的,不考虑在计算机中存储)
线性(用一根直线穿)
在计算机中存储用: 数组 链表 栈和队列是一种特殊的线性结构,是具体应用。 (操作受限的线性结构,不受限的应该是在任何地方可以增删改查可以用数组和链表实现。只要把链表学会,栈和队列都能搞定,数组稍微复杂一些。)
非线性:
树 图
1.2 物理结构:
数组
链表
模块二:非线性结构(现在人类还没有造出一个容器,能把树和图
都装进去的,因为他们确实是太复杂了)
(都要靠链表去实现)
2.树定义
专业定义:1、有且只有一个称为根的节点
2、有若干个互不相交的子树,这些子树本身也是一棵树
通俗定义:
1、树是由节点和边组成
2、每个节点只有一个父节点但可以有多个子节点
3、但有一个节点例外,该节点没有根节点,此节点称为根节点
3.专业术语
节点 父节点 子节点 子孙 堂兄弟深度:从根节点到最底层节点的层数称之为深度,根节点是第一层
叶子节点(叶子就不能劈叉了):没有子节点的节点
非终端节点:实际就是非叶子节点。根节点既可以是叶子也可以是非叶子节点
度:子节点的个数称为度。(一棵树看最大的)
4.树分类
一般树:任意一个节点的子节点的个数都不受限制二叉树(有序树):任意一个节点的子节点的个数最多两个,且子节点的位置不可更改。
分类:
一般二叉树
满二叉树
在不增加树的层数的前提下。无法再多添加一个节点的二叉树就是满二叉树。
完全二叉树
如果只是删除了满二叉树最底层最右边的连续若干个节点,这样形成的二叉树就是完全二叉树。
附图说明:
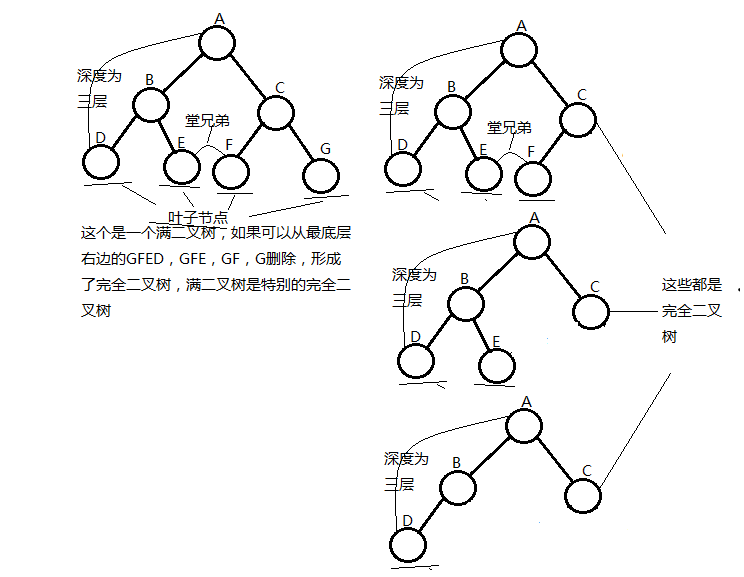
森林:n个互不相交的树的集合
一般的二叉树要以数组的方式存储,要先转化成完全二叉树,因为如果你只存有效节点(无论先序,中序,后序),则无法知道这个树的组成方式是什么样子的。
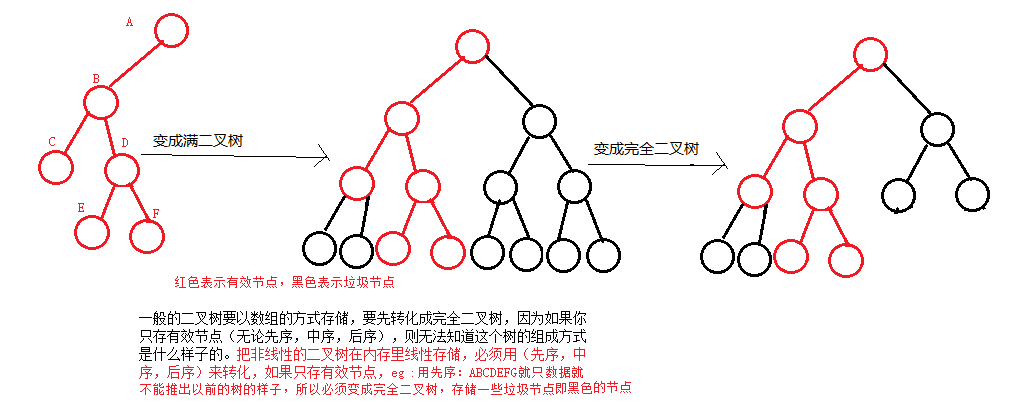
5.树的存储(都是转化成二叉树来存储)
1.二叉树的存储连续存储【完全二叉树】
优点:
查找某个节点的父节点和子节点(也包括判断有咩有)速度很快
缺点:
耗用内存空间过大
链式存储
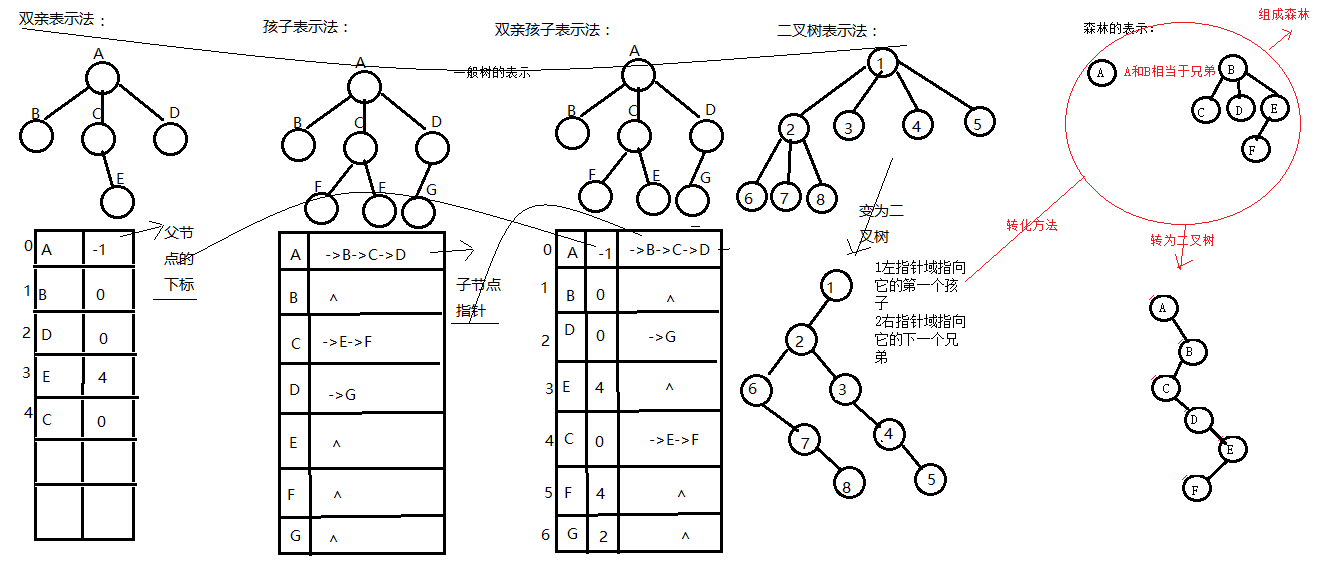
2.一般树的存储
双亲表示法:求父节点方便
孩子表示法:求子节点方便
双亲孩子表示法:求父节点和子节点都很方便
二叉树表示法:把一个普通树转化成二叉树来存储
3.转化为二叉树的具体转换方法:
设法保证任意一个节点的a.左指针域指向它的第一个孩子b.右指针域指向它的下一个兄弟,只要能满足此条件,就可以把一个普通树转化成二叉树一个普通树转化成的二叉树一定没有右子树
4.森林的存储
先把森林转化为二叉树,再存储二叉树,具体方式为:根节点 之间可以当成是兄弟来看待
附图说明:
6.二叉树操作
1.遍历先序遍历【先访问根节点】
先访问根节点
再先序访问左子树
再先序访问右子树
中序遍历【中间访问根节点】
中序遍历左子树
再访问根节点
再中序遍历右子树
后序遍历【最后访问根节点】
先后序遍历左子树
再后序遍历右子树
再访问根节点
三种遍历的代码:
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
struct BTNode {
char data;
BTNode * pLchild;
BTNode * pRchild;
};
struct BTNode * createBTree();
void preTraverseBTree(struct BTNode *);
void intTraverseBTree(struct BTNode *);
void postTraverseBTree(struct BTNode *);
int main(void)
{
struct BTNode * pT = createBTree();
//preTraverseBTree(pT);
intTraverseBTree(pT);
system("pause");
return 0;
}
//-----------静态的初始化二叉树-------
struct BTNode * createBTree()
{
struct BTNode * pA = (struct BTNode *)malloc(sizeof(struct BTNode));
struct BTNode * pB = (struct BTNode *)malloc(sizeof(struct BTNode));
struct BTNode * pC = (struct BTNode *)malloc(sizeof(struct BTNode));
struct BTNode * pD = (struct BTNode *)malloc(sizeof(struct BTNode));
struct BTNode * pE = (struct BTNode *)malloc(sizeof(struct BTNode));
pA->data = 'A';
pB->data = 'B';
pC->data = 'C';
pD->data = 'D';
pE->data = 'E';
pA->pLchild = pB;
pA->pRchild = pC;
pB->pLchild = pB->pRchild=NULL;
pC->pLchild = pD;
pC->pRchild = NULL;
pD->pLchild = NULL;
pD->pRchild = pE;
pE->pLchild = pE->pRchild = NULL;
return pA;
}
//-----------动态的初始化二叉树-------
struct BTNode * createBTree2()
{
}
//-----------先序遍历二叉树-----------
void preTraverseBTree(struct BTNode * pT)
{
/*先访问根节点,再先序遍历左子树,再先序遍历右子树*/
if (pT != NULL)//当
{
printf("%c\n", pT->data);
if (pT->pLchild != NULL)//筛选条件
preTraverseBTree(pT->pLchild);//这传的参数可能为空,所以pT!=NULL判断一下
if (pT->pRchild != NULL)
preTraverseBTree(pT->pRchild);
}
}
//-----------中序遍历二叉树-----------
void intTraverseBTree(struct BTNode * pT)
{
/*先中序遍历左子树,再访问根节点,再中序遍历右子树*/
if (pT != NULL)//当
{
if(pT->pLchild!=NULL)
intTraverseBTree(pT->pLchild);//这传的参数可能为空,所以pT!=NULL判断一下
printf("%c\n", pT->data);
if(pT->pRchild!=NULL)
intTraverseBTree(pT->pRchild);
}
}
//-----------后序遍历二叉树-----------
void postTraverseBTree(struct BTNode * pT)
{
/*先后序遍历左子树,再后序遍历右子树,再访问根节点*/
if (pT != NULL)//当
{
if (pT->pLchild != NULL)
postTraverseBTree(pT->pLchild);//这传的参数可能为空,所以pT!=NULL判断一下
if (pT->pRchild != NULL)
postTraverseBTree(pT->pRchild);
printf("%c\n", pT->data);
}
}2.已知两种遍历序列求原始二叉树
通过先序和中序 或者 中序和后续我们可以
还原出原始的二叉树
但是通过先序和后续是无法还原出原始的二叉树的
换种说法:
只有通过先序和中序, 或通过中序和后序
我们才可以唯一的确定一个二叉树
7.应用
树是数据库中数据组织的一种重要形式(例如图书馆的图书分类一层一层往下分。)操作系统子父进程的关系本身就是一棵树
面向对象语言中类的继承关系本身就是一棵树
赫夫曼树(树的一个特例)

相关文章推荐
- C#数据结构之顺序表(SeqList)实例详解
- Lua教程(七):数据结构详解
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- C#数据结构之队列(Quene)实例详解
- C#数据结构揭秘一
- C#数据结构之单链表(LinkList)实例详解
- 数据结构之Treap详解
- C#数据结构之堆栈(Stack)实例详解
- C#数据结构之双向链表(DbLinkList)实例详解
- JavaScript数据结构和算法之图和图算法
- Java数据结构及算法实例:冒泡排序 Bubble Sort
- Java数据结构及算法实例:插入排序 Insertion Sort
- Java数据结构及算法实例:考拉兹猜想 Collatz Conjecture
- java数据结构之java实现栈
- java数据结构之实现双向链表的示例
- Java数据结构及算法实例:选择排序 Selection Sort
- Java数据结构及算法实例:朴素字符匹配 Brute Force
- Java数据结构及算法实例:汉诺塔问题 Hanoi
- Java数据结构及算法实例:快速计算二进制数中1的个数(Fast Bit Counting)
- java数据结构和算法学习之汉诺塔示例