XML——解析XML文档
2016-01-24 11:08
786 查看
【0】README
0.1)本文描述 转自 core java volume 2, 旨在理解 XML——解析XML文档 的基础知识;0.2) for source code, please visit https://github.com/pacosonTang/core-java-volume/blob/master/coreJavaAdvanced/chapter2/ParseXMLTest.java
【1】解析XML文档相关
0)解析器0.1)树型解析器:(树结构)
0.2)流机制解析器:读入XML文档时生成相应的事件;
1)解析器定义: 解析器是这样一个程序, 它读入一个文件,确认这个文件具有正确的格式,然后将其分解成各种元素,使得程序员能够访问这些元素; (干货——解析器定义)
2)java 库提供了两种XML解析器: (干货——两种XML解析器定义)
2.1)树型解析器:像文档对象模型(Document Object Model, DOM)解析器这样的树型解析器,它们将读入的XML文档转换为 树结构;
2.2)流机制解析器:像XML简单API(Simple API for XML, SAX)解析器这样的流机制解析器, 它们在读入XML文档时生成相应的事件;
3)java XML 处理API(java API for XML Processing, JAXP)库:使得实际上可以以插件形式使用这些解析器中的任意一个, 但JDK 包含了自己的DOM解析器;
3.1)解析步骤(steps):
s1)创建一个 DocumentBuilder 对象,可以从DocumentBuilderFactory中得到这个对象,如:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder();
s2)可以从文件中读入某个文档:
File f = ...; Document doc = builder.parse(f);
s2.1)或者用一个URL:
URL u = ...; Document doc = builder.parse(u);
s2.2)甚至可以指定一个任意输入 流:
InputStream is = ...; Document doc = builder.parse(is);
Attention) 如果使用输入流作为输入源,那么对于那些以该文档的位置为相对路径而被引用的文档,解析器将无法定位;但是可以安装一个“实体解析器”来解决这个问题;
3.2)Document对象: 是XML 文档的树型结构在内存中的表现,它由实现了Node 接口及其各种子接口的类的对象构成;Node 接口及其子接口的层次结构如下: (干货——Document对象)
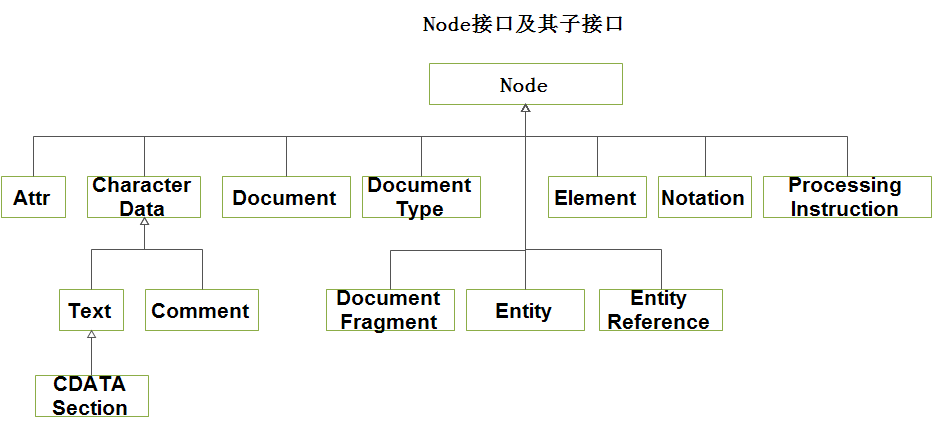
3.2.1)可以通过调用 getDocumentElement 方法来启动对文档内容的分析,它将返回根元素:
Element root = doc.getDocumentElement();
3.2.2)如果要得到该元素的子元素,使用 getChildNodes 方法,这个方法返回一个类型为 NodeList 的 集合;
3.2.3)item 方法:将得到指定索引值的项;
3.2.4)getLength方法: 则提供了项的总数;
3.2.5) 看个荔枝:像这样枚举所有子元素:
NodeList children = root.getChildNodes(); for (i < children.getLength()) Node child = children.item(i);
3.2.6)如果只希望获得子元素,可以忽略空白字符:
for (i < children.getLength())
{
Node child = children.item(i);
if(child instanceof Element)
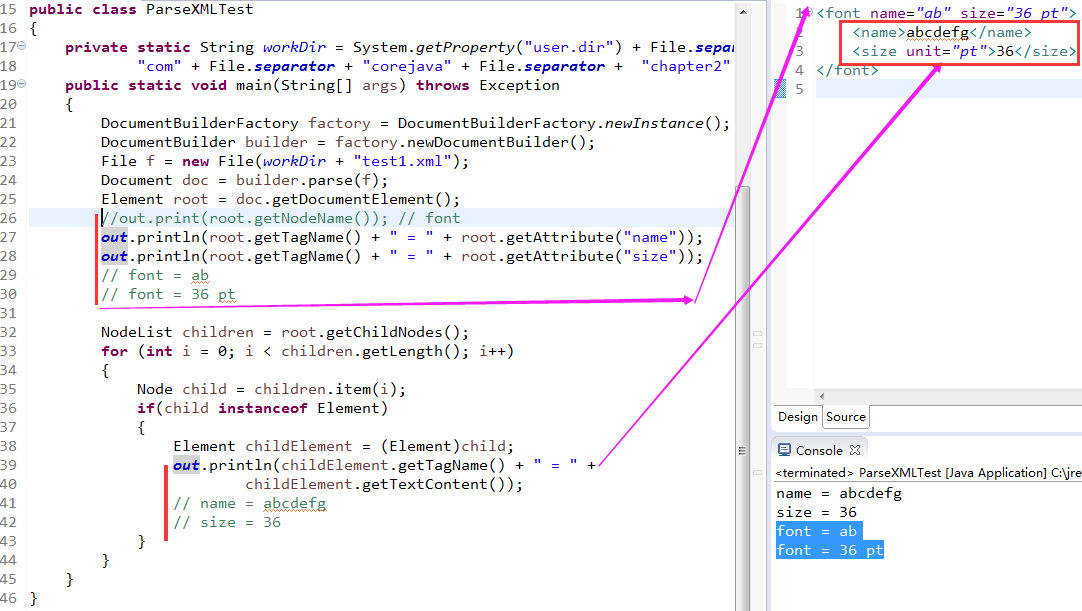
}现在,只会看到两个元素: 标签名是 name 和 size;
3.3) 方法集合:
3.3.1) getLashChild, getNextSibling 方法;
3.3.2)枚举节点属性, getAtributes;
3.3.3)调用getNodeName 和getNodeValue 方法可以得到 属性名和属性值(getAttribute 方法);
3.3.4)知道属性名, 可以直接获取属性值:
String unit = element.getAttribtte("unit");4)解析来自给定文件, URL 或输入流的 XML 文档,返回解析后的文档的三种方法(Methods); (干货——三种解析来自给定文件的方法,分别是文件对象,String对象 和 输入流对象)
M1) Document parse(File f) ;
M2) Document parse(String url) ;
M3) Document parse(InputStrema in) ;

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序