Java基础-了解HashMap
2016-01-21 22:36
639 查看
1.存储结构
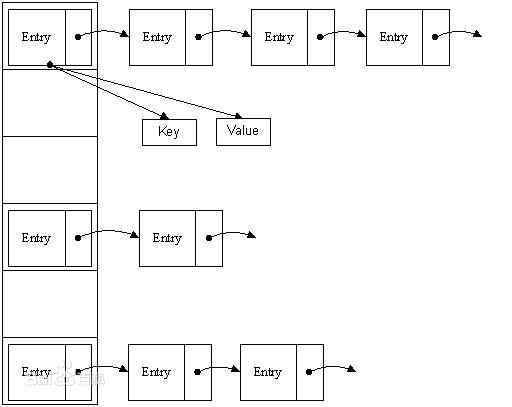
图片来自百度百科
首先HashMap对象里面有一个数组,叫table,用于存储entry的头节点
/** * The table, resized as necessary. Length MUST Always be a power of two. */ transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
这是一个可以自动扩容的数组,初始长度是16,每次扩容长度就翻一倍,会把原来table的数据搬到新的table里面来,这是一个很耗时的操作。
当put的时候,会先根据传入的key,计算出hash值,然后通过indexFor(hashcode,length)找到当前key应该存储在table的下标bucketIndex,table[bucketIndex]就是当前需要的链表的头节点。 遍历这个链表,通过比较key值就能找到目标节点。
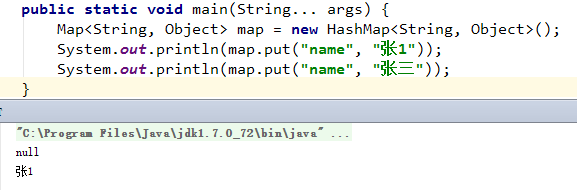
如果当前bucket已经有了一个节点,则新的节点会成为头节点,并把next指向上个头节点。
如果put操作会替换掉一个节点的话,会返回被替换的这个值。不发生替换则返回null
*什么时候扩容
每次进行put操作的时候,当添加了一个新的entry时(还有一种情况是覆盖),都会检查是否进行扩容,如果所有entry的size>=table.length*0.75(平衡因子),则进行扩容
为什么是0.75呢?据说这是权衡了时间复杂度与空间复杂度之后的最好取值
*为什么是乘以2
看indexFor方法
*indexFor有什么用
根据hash值和当前的table的长度计算出该hash应该存储的下标位置。
代码是这样的:
static int indexFor(int h, int length) {
return h & (length-1);
}因为长度都是2的倍数,所以2进制的length-1应该是这样的:
length-1 —–> 000000000111111
hashcode —–> 100101010110101
与hash值进行逻辑与运算,进行低位截取,最终的结果会在[0,length-1)之间,作为下标刚好。(个人理解)
*为什么key对应的是一个entry的链表而不是一个简单的entry
很多key值不一样,但是对应的hash值却是一样的,这样的对象就会堆积在一起形成一个链表,HashMap查找的时候,会直接找到第一个节点,然后依次遍历下一个节点,直到找到key一致的对象或者找不到。
*为什么用transient来修饰table
transient修饰表示该字段不需要序列化,在对象被序列化的时候,这个内容就不会被写进去。
HashMap是根据对象的hashCode来查找对象存储的下标的。但是在不同的环境下,同样的对象可能得到不同的hash值,这样的话entry直接复制过去了,再用同样的key去调用就可能找不到值了。
HashMap也有readObject和writeObject做这个事情,会重新计算hash值。
相关代码段
//hash值计算
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
//任何对象都可以重写hashcode方法,自定义hashCode逻辑
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//addEntry会判断是否需要扩容
addEntry(hash, key, value, i);
return null;
}public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
//遍历当前hash值下所有的entry
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//通过值的比较返回目标entry
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}//扩容操作
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//这里创建了一个新的table
Entry[] newTable = new Entry[newCapacity];
//数据转移到新的table里面来,重新计算下标
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//重新设置阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}2.非线程安全
多线程情况下,每个线程都会去操作entry,因此不安全证明1:
public class TestHashMap {
static class Obj {
private String name;
public Obj() {
}
public Obj(String name) {
this.name = name;
}
//为了增大风险,这里设置所有的Obj的hashcode都为11,
//这样的话,put操作,都会计算出同一个table下标,然后都会对这个entry链表进行操作
@Override
public int hashCode() {
return 11;
}
}
static class TestThread extends Thread {
private Map<Obj, Integer> map;
private int start = -1;
private int end = -1;
public TestThread(Map<Obj, Integer> map, int start, int end) {
this.map = map;
this.start = start;
this.end = end;
}
public void run() {
for (int i = start; i < end; i++) {
//不安全的put操作
map.put(new Obj(i + ""), i);
}
}
}
public static void main(String... args) throws Exception {
//线程不安全的HashMap
Map<Obj, Integer> map = new HashMap<Obj, Integer>();
//线程安全的Hashtable
//Map<Obj, Integer> map = new Hashtable<Obj, Integer>();
//线程安全的ConcurrentHashMap
//Map<Obj, Integer> map = new ConcurrentHashMap<Obj, Integer>();
new TestThread(map, 0, 25).start();
new TestThread(map, 25, 50).start();
Thread.sleep(1000);//等待线程装载数据完毕再进行下一步
//如果线程安全的话,value应该涵盖了0-49
for (int i = 0; i < 50; i++) {
boolean find = false;
for (Obj obj : map.keySet()) {
if (map.get(obj) == i) {
find = true;
break;
}
}
if (!find) {
System.out.println(i + "没有了");
}
}
System.out.println("size=" + map.size());
}
}运行结果:
25没有了
26没有了
28没有了
31没有了
size=50
换成其它两种则不会出现丢失情况。
出现原因:
因为计算出的bucketIndex是一致的,所以当同时添加节点A和B时,A和B的next都会指向节点C(上一个头节点),假设A先设置为了头节点,然后B又设置为头节点,则B会替代A成为头节点,A丢失
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
//无论是否丢失,size还是会照常加上去的
size++;
}运行的过程中,我发现有几次一直在运行而没有结束。也是因为非线程安全的原因,在resize的时候,形成了两个相互指引的entry,在查找的时候就无限循环。具体逻辑可以参考下这个链接http://blog.csdn.net/xiaohui127/article/details/11928865

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- c语言实现hashmap(转载)
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序