爬虫的常见陷阱以及Java的爬虫思路
2016-01-16 11:05
399 查看
前言
本文是这篇文章《Java实现爬虫给App提供数据(Jsoup 网络爬虫)》 http://blog.csdn.net/never_cxb/article/details/50524571 的衍生。当时面阿里的时候,聊到我做新闻 App 的时候,使用 Jsoup 爬虫,面试官随即问我对爬虫了解多深。所以稍微深入了解爬虫底层原理,后期打算看一下 Jsoup 底层实现。笔者做的爬虫侧重于对于网页内容的提取,url 遵守一定概率(比如末尾数字递增)。
比如 http://blog.csdn.net/never_cxb/article/details/50524571 是一篇博客的地址,把数字50524571换成50515216就可以得到另一篇博客的地址 http://blog.csdn.net/never_cxb/article/details/50515216。
爬虫的基本思路如下
1. 根据 Url 获取相应页面的 Html 代码
2. 利用正则匹配或者 Jsoup 等库解析 Html 代码,提取需要的内容
3. 将获取的内容持久化到数据库中
4. 处理好中文字符的编码问题,可以采用多线程提高效率
Jsoup 简介
关于 Html 和 Jsoup 的基本介绍请看这篇文章 https://liuzhichao.com/p/1484.html,写得很好。从 Jsoup 的 Api 可以看出,Element 继承自 Node。

根据 DOM,HTML 文档中的每个成分都是一个Node。Node 之间有等级关系,父 Node、子 Node、兄弟 Node 等等。
Joup 其实是 Html 解析器,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。如果不使用 Jsoup 解析,也可以利用正则匹配找出 Html 中需要的内容。
如何获取 url 呢?有一种方法从文章列表中获取,比如下面的博客目录视图中,文章的对于的 html代码中可以获取href=”/never_cxb/article/details/50524571”, 标题为Java实现爬虫给App提供数据(Jsoup 网络爬虫)。
<h1> <span class="link_title"><a href="/never_cxb/article/details/50524571"> <font color="red">[置顶]</font> Java实现爬虫给App提供数据(Jsoup 网络爬虫) </a></span> </h1>
爬虫基本原理
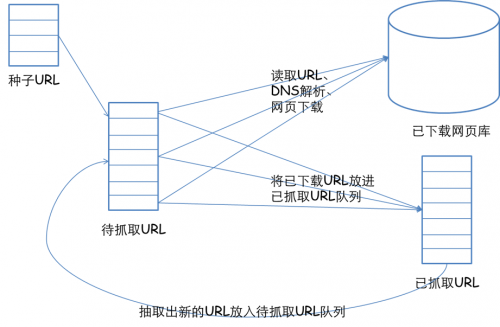
更宽泛意义上的爬虫侧重于如果在大量的 url 中寻找出高质量的资源,如何在有限的时间内访问更多页面等等。网络爬虫的基本工作流程如下:1.首先选取一部分精心挑选的种子URL; 2.将这些URL放入待抓取URL队列; 3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。 4.分析已抓取URL队列中的URL,分析页面里包含的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
有几个概念,一个是发http请求,一个是正则匹配你感兴趣的链接,一个是多线程,另外还有两个队列。
来源于 该文章 的一张图
爬虫难点1 环路
网络爬虫有时候会陷入循环或者环路中,比如从页面 A,A 链接到页面 B,B 链接 页面C,页面 C 又会链接到页面 A。这样就陷入到环路中。环路影响
消耗网络带宽,无法获取其他页面对 Web 服务器也是负担,可能击垮该站点,可能阻止正常用户访问该站点
即使没有性能影响,但获取大量重复页面也导致数据冗余
解决方案
1. 简单限定爬虫的最大循环次数,对于某 web 站点访问超过一定阈值就跳出,避免无限循环 2. 保存一个已访问 url 列表,记录页面是否被访问过的技术
二叉树和散列表,快速判定某个 url 是否访问过
存在位图
就是 new int[length],然后把第几个数置为1,表示已经访问过了。可不可以再优化,int 是32位,32位可以表示32个数字。HashCode 会存在冲突的情况,两个 url 映射到同一个存在位上,冲突的后果是某个页面被忽略(这比死循环的恶作用小)
保存检查
一定要即使把已访问的 url 列表保存在硬盘上,防止爬虫崩溃,内存里的数据会丢失
集群 ,分而治之
多台机器一起爬虫,可以根据 url 计算 hashcode,然后根据 hashcode 映射到相应机器的 id (第0台、第1台、第2台等等)
难点2 URL别名
有些 url 名称不一样,但是指向同一个资源。该表格来自于 《HTTP 权威指南》
| URl 1 | URL 2 | 什么时候是别名 |
|---|---|---|
| www.foo.com/bar.html | www.foo.com:80/bar.html | 默认端口是80 |
| www.foo.com/~fred | www.foo.com/%7Ffred | %7F与~相同 |
| www.foo.com/x.html#top | www.foo.com/x.html#middle | %7F与~相同 |
| https://www.baidu.com/ | https://www.BAIDU.com/ | 服务器是大小写无关 |
| www.foo.com/index.html | www.foo.com | 默认页面为 index.html |
| www.foo.com/index.html | 209.123.123/index.html | ip和域名相同 |
难点3 动态虚拟空间
比如日历程序,它会生成一个指向下一月的链接,真正的用户是不会不停地请求下个月的链接的。但是不了解这内容特性的爬虫蜘蛛可能会不断向这些资源发出无穷的请求。抓取策略
一般策略是深度优先或者广度优先。有些技术能使得爬虫蜘蛛有更好的表现广度优先的爬行,避免深度优先陷入某个站点的环路中,无法访问其他站点。
限制访问次数,限定一段时间内机器人可以从一个 web 站点获取的页面数量
内容指纹,根据页面的内容计算出一个校验和,但是动态的内容(日期,评论数目)会阻碍重复检测
维护黑名单
人工监视,特殊情况发出邮件通知
动态变化,根据当前热点新闻等等
规划化 url,把一些转义字符、ip 与域名之类的统一
限制 url 大小,环路可能会使得 url 长度增加,比如/index.html, /folder/index,html, /folder/folder/index.html …
全文索引
全文索引就是一个数据库,给它一个单词,它可以立刻提供包含那个单词的所有文字。创建了索引之后,就不必对文档自身进行扫描了。比如 文章 A 包含了 Java、学习、程序员
文章 B 包含了 Java 、Python、面试、招聘
如果搜索 Java,可以知道得到 文章 A 和文章 B,而不必对文章 A、B 全文扫描。
复习 Python 爬虫
自己曾实现了Python 爬虫,统计学校论坛上男女用户各占多少。Python实现爬虫统计学校BBS男女比例(一)前期准备、方案分析
http://blog.csdn.net/never_cxb/article/details/49934003
Python实现爬虫统计学校BBS男女比例(二)多线程爬虫
http://blog.csdn.net/never_cxb/article/details/49934961
Python实现爬虫统计学校BBS男女比例(三)数据处理
http://blog.csdn.net/never_cxb/article/details/49993353
我当时做的思路是 get 请求获取 html 源代码,对 html 用字符串匹配(前后多加一些限定单词进行正则匹配 比如
em>上次发表时间</em>后面跟的是活动时间)。
回过头来看,可能解析Dom 树可能更优雅一些。
参考文章
网络爬虫基本原理以及Jsoup基本使用方法
相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- Python动态类型的学习---引用的理解
- 从源码安装Mysql/Percona 5.5
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 介绍一款信息管理系统的开源框架---jeecg
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法