python学习第十课 多路复用、ThreadingTCPServer、线程与进程
2016-01-09 00:39
726 查看
python 第十课
多路复用
I/O多路复用指:通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作select poll epoll网络操作、文件操作、终端操作等均属于IO操作,对于windows只支持Socket操作,其他系统支持其他IO操作,但是无法检测。如普通文件操作自动上次读取是否已经变化。所以主要用来网络操作windows 和 mac的python 只提供select,linux上的python提供 select poll epoll方法
句柄列表11, 句柄列表22, 句柄列表33 = select.select(句柄序列1, 句柄序列2, 句柄序列3, 超时时间)
参数:可接受四个参数(前三个必须)
返回值:三个列表
select方法用来监视文件句柄,如果句柄发生变化,则获取该句柄。
1、当参数1 序列中的句柄发生可读时(accetp和read),则获取发生变化的句柄并添加到返回值1 序列中
2、当参数2 序列中含有句柄时,则将该序列中所有的句柄添加到返回值2 序列中
3、当参数3 序列中的句柄发生错误时,则将该发生错误的句柄添加到返回值3 序列中
4、当超时时间未设置,则select会一直阻塞,直到监听的句柄发生变化
当超时时间= 1时,那么如果监听的句柄均无任何变化,则select会阻塞 1 秒,之后返回三个空列表,如果监听的句柄有变化,则直接执行。
利用select 监听终端输入
import select
import threading
import sys
while True:
readable, writeable, error = select.select([sys.stdin,],[],[],1)
if sys.stdin in readable:
print 'select get stdin',sys.stdin.readline()
sys.stdin.readline() 与raw_input()的效果是一样的,都是接收用户输入,返回字符串,但是sys.stdin.readline()后面会多一个回车
raw_input 与 input()
raw_input() 直接读取控制台的输入(任何类型的输入它都可以接收)。而对于 input() ,它希望能够读取一个合法的 python 表达式,即你输入字符串的时候必须使用引号将它括起来,否则它会引发一个 SyntaxError 。
input([prompt])
Equivalent to eval(raw_input(prompt)) 它是调用完 raw_input() 之后再调用 eval() 函数,所以,你甚至可以将表达式作为 input() 的参数,并且它会计算表达式的值并返回它 2. 利用select实现伪同时处理多个socket客户端请求:服务端import socketimport select sk1 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)sk1.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) #端口重用 SOL_SOCKET,意思是正在使用的socket选项,socket.SO_REUSEADDR,当socket关闭后,本地端用于该socket的端口号立刻就可以被重用。通常来说,只有经过系统定义一段时间后,才能被重用。最后一个 1,表示将SO_REUSEADDR标记为TRUE,操作系统会在服务器socket被关闭或服务器进程终止后马上释放该服务器的端口,否则操作系统会保留几分钟该端口sk1.bind(('127.0.0.1',8002))sk1.listen(5)sk1.setblocking(0) inputs = [sk1,] while True: readable_list, writeable_list, error_list = select.select(inputs, [], inputs, 1) #监听inputs列表所含的所有元素,一有变化,就放入readalbe_list, 第四个参数 1 代表,阻塞1秒,然后就往下走 for r in readable_list: # 当客户端第一次连接服务端时 if sk1 == r: print 'accept' request, address = r.accept() request.setblocking(0) inputs.append(request) #将此次的连接放入inputs 的监听队列 # 当客户端连接上服务端之后,再次发送数据时 else: received = r.recv(1024) # 当正常接收客户端发送的数据时 if received: print 'received data:', received # 当客户端关闭程序时,会发送过来空数据 else: inputs.remove(r) sk1.close() 利用select实现伪同时处理多个socket客户端请求:客户端import socket ip_port = ('127.0.0.1',8002)sk = socket.socket()sk.connect(ip_port) while True: inp = raw_input('please input:') sk.sendall(inp)sk.close() 对于端口重用
import socket
tcp1 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp2 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#在绑定前调用setsockopt让套接字允许地址重用
tcp1.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
tcp2.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
#接下来两个套接字都也可以绑定到同一个端口上
tcp1.bind(('0.0.0.0', 12345))
tcp2.bind(('0.0.0.0', 12345))
#先监听tcp1,执行 tcp1连接,接收和发送,只有当tcp1断开后,才能轮到tcp2
端口重用最常用的用途是:防止服务器重启时之前绑定的端口还未释放,或者其它异常情况下程序出错但是端口未释放。这种情况下如果设定了端口复用,则新启动的服务器进程可以直接绑定端口。如果没有设定端口复用,绑定会失败,提示ADDR已经在使用中
使用了IO多路复用的Socket服务端相比与原生的Socket,他支持当某一个请求不再发送数据时,服务器端不会等待而是可以去处理其他请求的数据。但是,如果每个请求的耗时比较长时,select版本的服务器端也无法完成同时操作
模块
SocketServer内部使用 IO多路复用以及“多线程”和“多进程”,从而实现并发处理多个客户端请求的Socket服务端。即:每个客户端请求连接到服务器时,Socket服务端都会在服务器是创建一个“线程”或者“进程”专门负责处理当前客户端的所有请求。
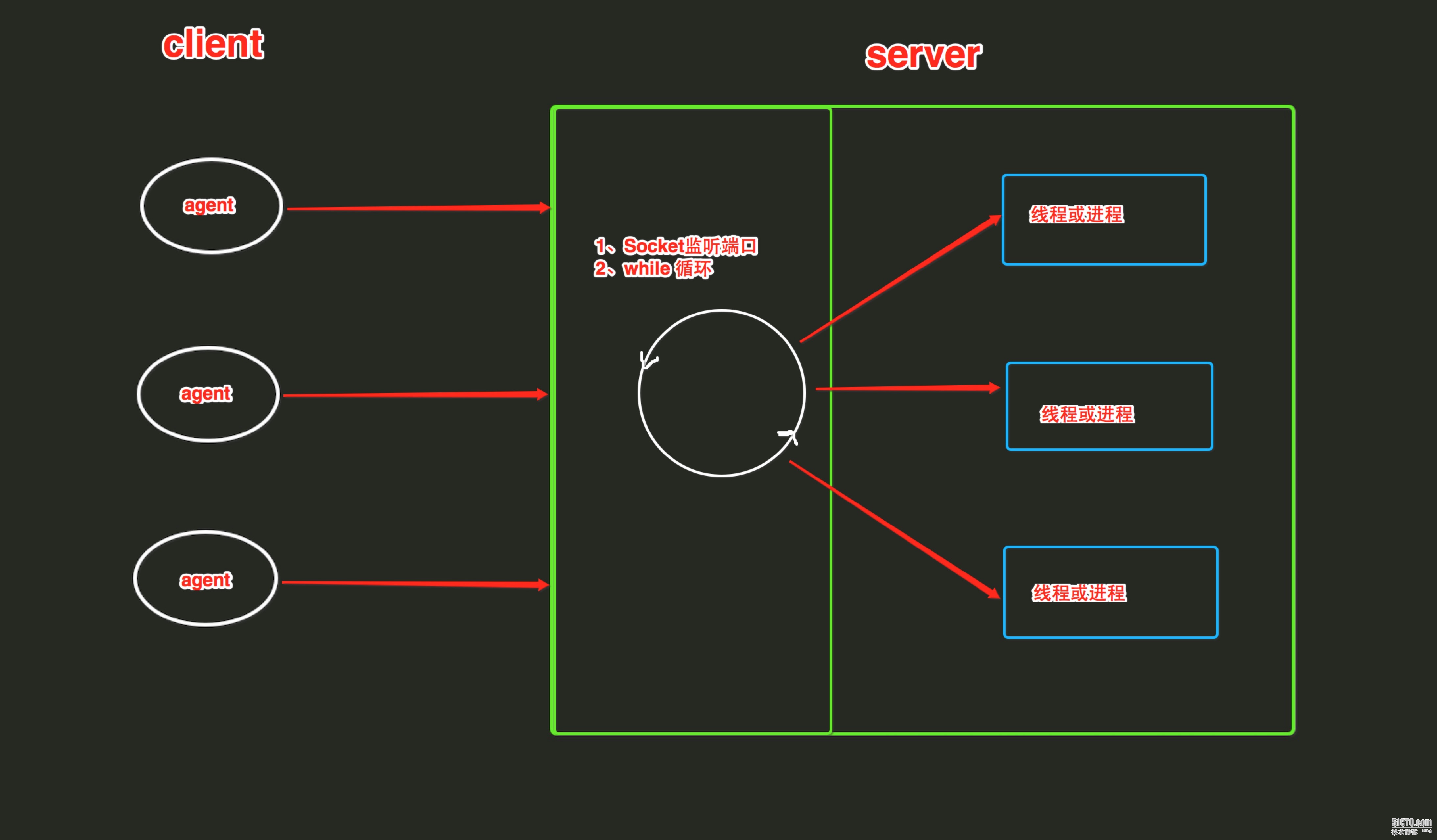
ThreadingTCPServerThreadingTCPServer实现的Soket服务器内部会为每个client创建一个“线程”,该线程用来和客户端进行交互1、ThreadingTCPServer基础
使用ThreadingTCPServer:
.创建一个继承自 SocketServer.BaseRequestHandler 的类
.类中必须定义一个名称为 handle 的方法 (因为父类即SocketServer.BaseRequestHandler中的handle方法为空)
.启动ThreadingTCPServersocket服务器端
import SocketServer
class MyServer(SocketServer.BaseRequestHandler):
def handle(self):
# print self.request,self.client_address,self.server
conn = self.request
conn.sendall('欢迎致电 10086,请输入1xxx,0转人工服务.')
Flag = True
while Flag:
data = conn.recv(1024)
if data == 'exit':
Flag = False
elif data == '0':
conn.sendall('通过可能会被录音.balabala一大推')
else:
conn.sendall('请重新输入.')
if __name__ == '__main__':
server = SocketServer.ThreadingTCPServer(('127.0.0.1',8009),MyServer)
server.serve_forever()
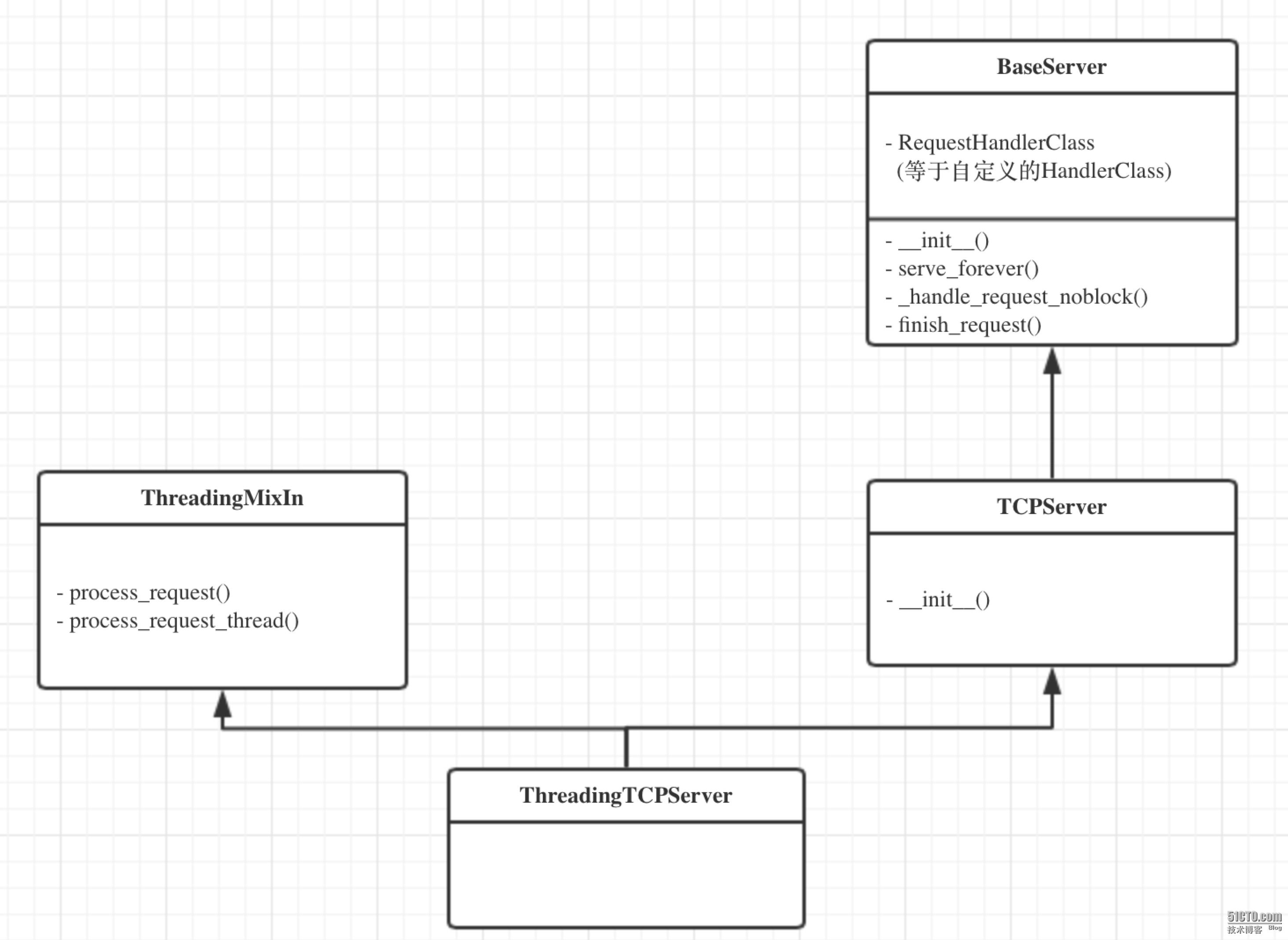
2、ThreadingTCPServer源码剖析
ThreadingTCPServer的类图关系如下:
内部调用流程为:
启动服务端程序
执行 TCPServer.__init__ 方法,创建服务端Socket对象并绑定 IP 和端口
执行 BaseServer.__init__ 方法,将自定义的继承自SocketServer.BaseRequestHandler 的 类 MyRequestHandle赋值给 self.RequestHandlerClass
执行 BaseServer.server_forever 方法,While 循环一直监听是否有客户端请求到达 ...
当客户端连接到达服务器
执行 ThreadingMixIn.process_request 方法,创建一个“线程”用来处理请求
执行 ThreadingMixIn.process_request_thread 方法
执行 BaseServer.finish_request 方法,执行 self.RequestHandlerClass() 即:执行自定 义 MyRequestHandler 的构造方法(自动调用基类BaseRequestHandler的构造方法,在 该构造方法中又会调用 MyRequestHandler的handle方法)
源码精简:
import socket
import threading
import select
def process(request, client_address):
print request,client_address
conn = request
conn.sendall('欢迎致电 10086,请输入1xxx,0转人工服务.')
flag = True
while flag:
data = conn.recv(1024)
If data == 'exit':
flag = False
elif data == '0':
conn.sendall('通过可能会被录音.balabala一大推')
else:
conn.sendall('请重新输入.')
sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sk.bind(('127.0.0.1',8002))
sk.listen(5)
while True:
r, w, e = select.select([sk,],[],[],1)
print 'looping'
if sk in r:
print 'get request'
request, client_address = sk.accept()
t = threading.Thread(target=process, args=(request, client_address))
t.daemon = False
t.start()
sk.close()
ForkingTCPServer
ForkingTCPServer和ThreadingTCPServer的使用和执行流程基本一致,只不过在内部分 别为请求者建立“线程” 和“进程”
server = SocketServer.ForkingTCPServer(('127.0.0.1',8009),MyServer)
线程
Threading用于提供线程相关的操作,线程是应用程序中工作的最小单元
例:
import threading
import time
def run(num):
print ("thread...",num)
time.sleep(1)
for i in range(100):
t = threading.Thread(target=run,args =(i,))
t.start()
上面的例子建了十个线程,虚拟机解析之后将它们交给CPU执行,但它们并不是真正的多线程,而且根据一定的算法,分片执行,由于执行速度非常快,所以感觉像是并行
thread类的方法有:
start 线程准备就绪,等待CPU调度
setName 为线程设置名称
getName 获取线程名称
setDaemon 设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执 行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执 行完毕后,等待前台线程也执行完成后,程序停止
join 逐个执行每个线程,执行完毕后继续往下执行...
run 线程被cpu调度后执行此方法
线程锁
当多个线程都去修改一个变量时,有可能线程a取到变量值修改后还没返回时,线程b也拿到这个变量去修改,这样会导致变量的结果与期望的不一样,这时,就需要用锁来保证这个变量同时只能由一个线程来更改
import threading
import time
gl_num = 0
lock = threading.RLock()
def Func():
lock.acquire()
global gl_num
gl_num +=1
time.sleep(1)
print gl_num
lock.release()
for i in range(10):
t = threading.Thread(target=Func)
t.start()
线程事件
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False(默认),那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
clear:将“Flag”设置为False
set:将“Flag”设置为True
import threading
def do(event,i):
print 'start,%d' %iif i%2 == 0: event.wait() #执行到wait就去查看事件的值,如果为false就等,如果为true就接着往下走 print 'execute %d ' %i
event_obj = threading.Event() #定义一个事件对象
for i in range(10):
t = threading.Thread(target=do, args=(event_obj,i,))
t.start()
event_obj.clear()
inp = raw_input('input:')
if inp == 'true':
event_obj.set()
PYTHON进程
from multiprocessing import Process
def foo(i):
print 'say hi',i
for i in range(10):
p = Process(target=foo,args=(i,))
p.start()
会同时启十个进程执行foo
p.__parent_pid 可以得到父进程的PID,那如何得到子进程的PID? ----os.getpid()
进程数据共享
进程各自持有一份数据,默认无法共享数据
#!/usr/bin/env python
#coding:utf-8
from multiprocessing import Process
import time
li = []
def foo(i):
li.append(i)
print 'say hi',li
for i in range(10):
p = Process(target=foo,args=(i,))
p.start()
print 'ending',li
进程间实现共享的方式:
#方法一,Array
from multiprocessing import Process,Array
temp = Array('i', [11,22,33,44])
def Foo(i):
temp[i] = 100+i
for item in temp:
print i,'----->',item
for i in range(2):
p = Process(target=Foo,args=(i,))
p.start()
进程并不顺序执行,当先执行i=0时
i = 0 temp = [100,22,33,44]
i = 1 temp = [100,101,33,44]
当先执行i = 1时
i = 1 temp = [11,101,33,44]
i = 0 temp = [100,101,33,44]
>>> help(Array)
Help on function Array in module multiprocessing:
Array(typecode_or_type, size_or_initializer, **kwds)
Returns a synchronized shared array
Array的类型对照表
'c': ctypes.c_char, 'u': ctypes.c_wchar,
'b': ctypes.c_byte, 'B': ctypes.c_ubyte,
'h': ctypes.c_short, 'H': ctypes.c_ushort,
'i': ctypes.c_int, 'I': ctypes.c_uint,
'l': ctypes.c_long, 'L': ctypes.c_ulong,
'f': ctypes.c_float, 'd': ctypes.c_double
#方法二:manage.dict()共享数据
from multiprocessing import Process,Manager
manage = Manager() --?
dic = manage.dict() --SyncManager.register('dict', dict, DictProxy) ??
def Foo(i):
dic[i] = 100+i
print dic.values()
for i in range(2):
p = Process(target=Foo,args=(i,))
p.start()
p.join()
当创建进程时(非使用时),共享数据会被拿到子进程中,当进程中执行完毕后,再赋值给原值
>>> help(p.join)
Help on method join in module multiprocessing.process:
join(self, timeout=None) method of multiprocessing.process.
Process instance Wait until child process terminates
主进程会等待子进程结束,join放的位置不同,执行过程也会不同,如果像上例一样放在里面,主进程会先生成一个子进程,主进程会等待这个子进程结束后再生成另一个子进程;如果放在外面,那么会同时生成多个子进程,然后主进程等待这些子进程全部结束,例: from multiprocessing import Process def foo(i): print ‘hi’ pro_list = [] for i in range (10): p = Process(target=foo,args = (i,)) pro_list.append(p) p.start() for pro in pro_list: pro.join()
进程锁
与线程锁一样,为了避免同时使用或修改某个资源,需要使用进程锁
from multiprocessing import Process,Array,RLock
def foo(lock,temp,i):
lock.acquire()
temp[0] = 1+temp[0]
lock.release()
lock = RLock()
temp = Array('i',[11,22,33,44])
for i in range(5000):
p = Process(target=foo,args=(lock,temp,i,))
p.start()
print i,'--->',temp[0]
[han@localhost ~]$ ./test.py
4999 ---> 5006
[han@localhost ~]$ ./test.py
4999 ---> 4996
[han@localhost ~]$./test.py
4999--->5003
为什么加了锁,结果还变?因为,当主进程进行print的时候,有些子进程还没执行完,所以每次结果不同
进程池
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
apply
apply_async
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from multiprocessing import Process,Pool
import time
def Foo(i):
time.sleep(2)
return i+100
def Bar(arg):
print arg
pool = Pool(5)
#print pool.apply(Foo,(1,))
#print pool.apply_async(func =Foo, args=(1,)).get()
#apply() 就相当于apply_async().get()
for i in range(10):
pool.apply_async(func=Foo, args=(i,),callback=Bar)
print 'end'
pool.close()
pool.join()#进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
python setup.py build
python setup.py install
多路复用
I/O多路复用指:通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作select poll epoll网络操作、文件操作、终端操作等均属于IO操作,对于windows只支持Socket操作,其他系统支持其他IO操作,但是无法检测。如普通文件操作自动上次读取是否已经变化。所以主要用来网络操作windows 和 mac的python 只提供select,linux上的python提供 select poll epoll方法
句柄列表11, 句柄列表22, 句柄列表33 = select.select(句柄序列1, 句柄序列2, 句柄序列3, 超时时间)
参数:可接受四个参数(前三个必须)
返回值:三个列表
select方法用来监视文件句柄,如果句柄发生变化,则获取该句柄。
1、当参数1 序列中的句柄发生可读时(accetp和read),则获取发生变化的句柄并添加到返回值1 序列中
2、当参数2 序列中含有句柄时,则将该序列中所有的句柄添加到返回值2 序列中
3、当参数3 序列中的句柄发生错误时,则将该发生错误的句柄添加到返回值3 序列中
4、当超时时间未设置,则select会一直阻塞,直到监听的句柄发生变化
当超时时间= 1时,那么如果监听的句柄均无任何变化,则select会阻塞 1 秒,之后返回三个空列表,如果监听的句柄有变化,则直接执行。
利用select 监听终端输入
import select
import threading
import sys
while True:
readable, writeable, error = select.select([sys.stdin,],[],[],1)
if sys.stdin in readable:
print 'select get stdin',sys.stdin.readline()
sys.stdin.readline() 与raw_input()的效果是一样的,都是接收用户输入,返回字符串,但是sys.stdin.readline()后面会多一个回车
raw_input 与 input()
raw_input() 直接读取控制台的输入(任何类型的输入它都可以接收)。而对于 input() ,它希望能够读取一个合法的 python 表达式,即你输入字符串的时候必须使用引号将它括起来,否则它会引发一个 SyntaxError 。
input([prompt])
Equivalent to eval(raw_input(prompt)) 它是调用完 raw_input() 之后再调用 eval() 函数,所以,你甚至可以将表达式作为 input() 的参数,并且它会计算表达式的值并返回它 2. 利用select实现伪同时处理多个socket客户端请求:服务端import socketimport select sk1 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)sk1.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) #端口重用 SOL_SOCKET,意思是正在使用的socket选项,socket.SO_REUSEADDR,当socket关闭后,本地端用于该socket的端口号立刻就可以被重用。通常来说,只有经过系统定义一段时间后,才能被重用。最后一个 1,表示将SO_REUSEADDR标记为TRUE,操作系统会在服务器socket被关闭或服务器进程终止后马上释放该服务器的端口,否则操作系统会保留几分钟该端口sk1.bind(('127.0.0.1',8002))sk1.listen(5)sk1.setblocking(0) inputs = [sk1,] while True: readable_list, writeable_list, error_list = select.select(inputs, [], inputs, 1) #监听inputs列表所含的所有元素,一有变化,就放入readalbe_list, 第四个参数 1 代表,阻塞1秒,然后就往下走 for r in readable_list: # 当客户端第一次连接服务端时 if sk1 == r: print 'accept' request, address = r.accept() request.setblocking(0) inputs.append(request) #将此次的连接放入inputs 的监听队列 # 当客户端连接上服务端之后,再次发送数据时 else: received = r.recv(1024) # 当正常接收客户端发送的数据时 if received: print 'received data:', received # 当客户端关闭程序时,会发送过来空数据 else: inputs.remove(r) sk1.close() 利用select实现伪同时处理多个socket客户端请求:客户端import socket ip_port = ('127.0.0.1',8002)sk = socket.socket()sk.connect(ip_port) while True: inp = raw_input('please input:') sk.sendall(inp)sk.close() 对于端口重用
import socket
tcp1 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp2 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#在绑定前调用setsockopt让套接字允许地址重用
tcp1.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
tcp2.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
#接下来两个套接字都也可以绑定到同一个端口上
tcp1.bind(('0.0.0.0', 12345))
tcp2.bind(('0.0.0.0', 12345))
#先监听tcp1,执行 tcp1连接,接收和发送,只有当tcp1断开后,才能轮到tcp2
端口重用最常用的用途是:防止服务器重启时之前绑定的端口还未释放,或者其它异常情况下程序出错但是端口未释放。这种情况下如果设定了端口复用,则新启动的服务器进程可以直接绑定端口。如果没有设定端口复用,绑定会失败,提示ADDR已经在使用中
使用了IO多路复用的Socket服务端相比与原生的Socket,他支持当某一个请求不再发送数据时,服务器端不会等待而是可以去处理其他请求的数据。但是,如果每个请求的耗时比较长时,select版本的服务器端也无法完成同时操作
模块
SocketServer内部使用 IO多路复用以及“多线程”和“多进程”,从而实现并发处理多个客户端请求的Socket服务端。即:每个客户端请求连接到服务器时,Socket服务端都会在服务器是创建一个“线程”或者“进程”专门负责处理当前客户端的所有请求。
ThreadingTCPServerThreadingTCPServer实现的Soket服务器内部会为每个client创建一个“线程”,该线程用来和客户端进行交互1、ThreadingTCPServer基础
使用ThreadingTCPServer:
.创建一个继承自 SocketServer.BaseRequestHandler 的类
.类中必须定义一个名称为 handle 的方法 (因为父类即SocketServer.BaseRequestHandler中的handle方法为空)
.启动ThreadingTCPServersocket服务器端
import SocketServer
class MyServer(SocketServer.BaseRequestHandler):
def handle(self):
# print self.request,self.client_address,self.server
conn = self.request
conn.sendall('欢迎致电 10086,请输入1xxx,0转人工服务.')
Flag = True
while Flag:
data = conn.recv(1024)
if data == 'exit':
Flag = False
elif data == '0':
conn.sendall('通过可能会被录音.balabala一大推')
else:
conn.sendall('请重新输入.')
if __name__ == '__main__':
server = SocketServer.ThreadingTCPServer(('127.0.0.1',8009),MyServer)
server.serve_forever()
2、ThreadingTCPServer源码剖析
ThreadingTCPServer的类图关系如下:
内部调用流程为:
启动服务端程序
执行 TCPServer.__init__ 方法,创建服务端Socket对象并绑定 IP 和端口
执行 BaseServer.__init__ 方法,将自定义的继承自SocketServer.BaseRequestHandler 的 类 MyRequestHandle赋值给 self.RequestHandlerClass
执行 BaseServer.server_forever 方法,While 循环一直监听是否有客户端请求到达 ...
当客户端连接到达服务器
执行 ThreadingMixIn.process_request 方法,创建一个“线程”用来处理请求
执行 ThreadingMixIn.process_request_thread 方法
执行 BaseServer.finish_request 方法,执行 self.RequestHandlerClass() 即:执行自定 义 MyRequestHandler 的构造方法(自动调用基类BaseRequestHandler的构造方法,在 该构造方法中又会调用 MyRequestHandler的handle方法)
源码精简:
import socket
import threading
import select
def process(request, client_address):
print request,client_address
conn = request
conn.sendall('欢迎致电 10086,请输入1xxx,0转人工服务.')
flag = True
while flag:
data = conn.recv(1024)
If data == 'exit':
flag = False
elif data == '0':
conn.sendall('通过可能会被录音.balabala一大推')
else:
conn.sendall('请重新输入.')
sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sk.bind(('127.0.0.1',8002))
sk.listen(5)
while True:
r, w, e = select.select([sk,],[],[],1)
print 'looping'
if sk in r:
print 'get request'
request, client_address = sk.accept()
t = threading.Thread(target=process, args=(request, client_address))
t.daemon = False
t.start()
sk.close()
ForkingTCPServer
ForkingTCPServer和ThreadingTCPServer的使用和执行流程基本一致,只不过在内部分 别为请求者建立“线程” 和“进程”
server = SocketServer.ForkingTCPServer(('127.0.0.1',8009),MyServer)
线程
Threading用于提供线程相关的操作,线程是应用程序中工作的最小单元
例:
import threading
import time
def run(num):
print ("thread...",num)
time.sleep(1)
for i in range(100):
t = threading.Thread(target=run,args =(i,))
t.start()
上面的例子建了十个线程,虚拟机解析之后将它们交给CPU执行,但它们并不是真正的多线程,而且根据一定的算法,分片执行,由于执行速度非常快,所以感觉像是并行
thread类的方法有:
start 线程准备就绪,等待CPU调度
setName 为线程设置名称
getName 获取线程名称
setDaemon 设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执 行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执 行完毕后,等待前台线程也执行完成后,程序停止
join 逐个执行每个线程,执行完毕后继续往下执行...
run 线程被cpu调度后执行此方法
线程锁
当多个线程都去修改一个变量时,有可能线程a取到变量值修改后还没返回时,线程b也拿到这个变量去修改,这样会导致变量的结果与期望的不一样,这时,就需要用锁来保证这个变量同时只能由一个线程来更改
import threading
import time
gl_num = 0
lock = threading.RLock()
def Func():
lock.acquire()
global gl_num
gl_num +=1
time.sleep(1)
print gl_num
lock.release()
for i in range(10):
t = threading.Thread(target=Func)
t.start()
线程事件
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False(默认),那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
clear:将“Flag”设置为False
set:将“Flag”设置为True
import threading
def do(event,i):
print 'start,%d' %iif i%2 == 0: event.wait() #执行到wait就去查看事件的值,如果为false就等,如果为true就接着往下走 print 'execute %d ' %i
event_obj = threading.Event() #定义一个事件对象
for i in range(10):
t = threading.Thread(target=do, args=(event_obj,i,))
t.start()
event_obj.clear()
inp = raw_input('input:')
if inp == 'true':
event_obj.set()
PYTHON进程
from multiprocessing import Process
def foo(i):
print 'say hi',i
for i in range(10):
p = Process(target=foo,args=(i,))
p.start()
会同时启十个进程执行foo
p.__parent_pid 可以得到父进程的PID,那如何得到子进程的PID? ----os.getpid()
进程数据共享
进程各自持有一份数据,默认无法共享数据
#!/usr/bin/env python
#coding:utf-8
from multiprocessing import Process
import time
li = []
def foo(i):
li.append(i)
print 'say hi',li
for i in range(10):
p = Process(target=foo,args=(i,))
p.start()
print 'ending',li
进程间实现共享的方式:
#方法一,Array
from multiprocessing import Process,Array
temp = Array('i', [11,22,33,44])
def Foo(i):
temp[i] = 100+i
for item in temp:
print i,'----->',item
for i in range(2):
p = Process(target=Foo,args=(i,))
p.start()
进程并不顺序执行,当先执行i=0时
i = 0 temp = [100,22,33,44]
i = 1 temp = [100,101,33,44]
当先执行i = 1时
i = 1 temp = [11,101,33,44]
i = 0 temp = [100,101,33,44]
>>> help(Array)
Help on function Array in module multiprocessing:
Array(typecode_or_type, size_or_initializer, **kwds)
Returns a synchronized shared array
Array的类型对照表
'c': ctypes.c_char, 'u': ctypes.c_wchar,
'b': ctypes.c_byte, 'B': ctypes.c_ubyte,
'h': ctypes.c_short, 'H': ctypes.c_ushort,
'i': ctypes.c_int, 'I': ctypes.c_uint,
'l': ctypes.c_long, 'L': ctypes.c_ulong,
'f': ctypes.c_float, 'd': ctypes.c_double
#方法二:manage.dict()共享数据
from multiprocessing import Process,Manager
manage = Manager() --?
dic = manage.dict() --SyncManager.register('dict', dict, DictProxy) ??
def Foo(i):
dic[i] = 100+i
print dic.values()
for i in range(2):
p = Process(target=Foo,args=(i,))
p.start()
p.join()
当创建进程时(非使用时),共享数据会被拿到子进程中,当进程中执行完毕后,再赋值给原值
>>> help(p.join)
Help on method join in module multiprocessing.process:
join(self, timeout=None) method of multiprocessing.process.
Process instance Wait until child process terminates
主进程会等待子进程结束,join放的位置不同,执行过程也会不同,如果像上例一样放在里面,主进程会先生成一个子进程,主进程会等待这个子进程结束后再生成另一个子进程;如果放在外面,那么会同时生成多个子进程,然后主进程等待这些子进程全部结束,例: from multiprocessing import Process def foo(i): print ‘hi’ pro_list = [] for i in range (10): p = Process(target=foo,args = (i,)) pro_list.append(p) p.start() for pro in pro_list: pro.join()
进程锁
与线程锁一样,为了避免同时使用或修改某个资源,需要使用进程锁
from multiprocessing import Process,Array,RLock
def foo(lock,temp,i):
lock.acquire()
temp[0] = 1+temp[0]
lock.release()
lock = RLock()
temp = Array('i',[11,22,33,44])
for i in range(5000):
p = Process(target=foo,args=(lock,temp,i,))
p.start()
print i,'--->',temp[0]
[han@localhost ~]$ ./test.py
4999 ---> 5006
[han@localhost ~]$ ./test.py
4999 ---> 4996
[han@localhost ~]$./test.py
4999--->5003
为什么加了锁,结果还变?因为,当主进程进行print的时候,有些子进程还没执行完,所以每次结果不同
进程池
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
apply
apply_async
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from multiprocessing import Process,Pool
import time
def Foo(i):
time.sleep(2)
return i+100
def Bar(arg):
print arg
pool = Pool(5)
#print pool.apply(Foo,(1,))
#print pool.apply_async(func =Foo, args=(1,)).get()
#apply() 就相当于apply_async().get()
for i in range(10):
pool.apply_async(func=Foo, args=(i,),callback=Bar)
print 'end'
pool.close()
pool.join()#进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
python setup.py build
python setup.py install

相关文章推荐
- Python中线程编程之threading模块的使用详解
- python threading模块操作多线程介绍
- python中threading超线程用法实例分析
- 举例详解Python中threading模块的几个常用方法
- Python THREADING模块中的JOIN()方法深入理解
- Python threading多线程编程实例
- python基于queue和threading实现多线程下载实例
- Python中threading模块join函数用法实例分析
- C++爱好者博客
- python多线程队列安全
- http2特点
- 线程之间的通信
- 使用队列让线程同步
- Python使用条件变量保持线程同步
- Python简单线程同步
- Python线程的daemon属性
- Python线程的线程名
- Python线程isAlive方法
- Python的Threading模块的Thread对象的join方法
- IO复用&C10K浅析