Apache Spark 初识
2016-01-06 20:21
621 查看
同时更新在个人博客:tintinsnowy.com
—-Albert Einstein
Apache Spark is a fast and general
它是一种快速、通用的大数据分析引擎。spark 是集批处理、实时流处理(spark streaming)、交互式查询(spark SQL)、图计算(GraphX)于一体的。
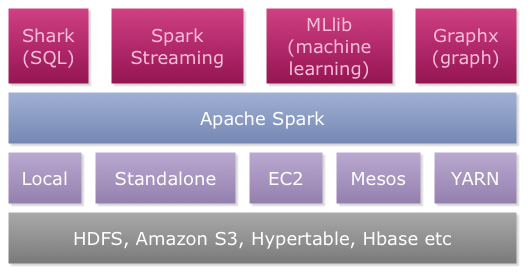
内存管理和故障恢复
在集群上安排、分布和监控作业
和存储系统进行交互
Spark引入了一个称为弹性分布式数据集(RDD,Resilient Distributed Dataset)的概念,它是一个不可变的、容错的、分布式对象集合,我们可以并行的操作这个集合。RDD可以包含任何类型的对象,它在加载外部数据集或者从驱动应用程序分发集合时创建。
RDD支持两种操作类型:
转换是一种操作(例如映射、过滤、联接、联合等等),它在一个RDD上执行操作,然后创建一个新的RDD来保存结果。
行动是一种操作(例如归并、计数、第一等等),它在一个RDD上执行某种计算,然后将结果返回。
在Spark中,转换是“懒惰”(lazy)的,也就是说它们不会立刻计算出结果。相反,它们只是“记住”要执行的操作以及要操作的数据集(例如文件)。只有当行为被调用时,转换才会真正的进行计算,并将结果返回给驱动器程序。这种设计让Spark运行得更有效率。例如,如果一个大文件要通过各种方式进行转换操作,并且文件被传递给第一个行为,那么Spark只会处理文件的第一行内容并将结果返回,而不会处理整个文件。
默认情况下,当你在经过转换的RDD上运行一个行为时,这个RDD有可能会被重新计算。然而,你也可以通过使用持久化或者缓存的方法,将一个RDD持久化从在尽可能多地在内存中而然后才往磁盘中去写,这样,Spark就会在集群上保留这些元素,当你下一次查询它时,查询速度会快很多。
// sc is an existing SparkContext.启动shell后sc is available
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql(“CREATE TABLE IF NOT EXISTS src (key INT, value STRING)”)
sqlContext.sql(“LOAD DATA LOCAL INPATH examples/src/main/resources/kv1.txt’ INTO TABLE src”)
// Queries are expressed in HiveQL
sqlContext.sql(“FROM src SELECT key, value”).collect().foreach(println)
val sqlContext = new SQLContext(sc)
df = sqlContext.read.format(“com.databricks.spark.csv”).options(opts).load(hdfs
+ “/s_user”) //将hdfs dfs ls /s_user/*下所有文件读入形成dataframe的格式
“`
可以通过JDBC API将Spark数据集暴露出去,而且还可以用传统的BI和可视化工具在Spark数据上执行类似SQL的查询(比如Tableau)。也可以从外部(hive,文件,hdfs)上读入文件,进行sql语句的查询。
关于sparksql 的使用会在后面几篇文章中重点介绍。


GraphX是一个库,用来处理图,执行基于图的并行操作。它针对ETL、探索性分析和迭代图计算提供了统一的工具。除了针对图处理的内置操作,GraphX还提供了一个库,用于通用的图算法,例如PageRank。
Spark还支持大数据查询的延迟计算,这可以帮助优化大数据处理流程中的处理步骤。Spark还提供高级的API以提升开发者的生产力,除此之外还为大数据解决方案提供一致的体系架构模型。
Spark将中间结果保存在内存中而不是将其写入磁盘,当需要多次处理同一数据集时,这一点特别实用。Spark的设计初衷就是既可以在内存中又可以在磁盘上工作的执行引擎。当内存中的数据不适用时,Spark操作符就会执行外部操作。Spark可以用于处理大于集群内存容量总和的数据集。
Spark会尝试在内存中存储尽可能多的数据然后将其写入磁盘。它可以将某个数据集的一部分存入内存而剩余部分存入磁盘。开发者需要根据数据和用例评估对内存的需求。Spark的性能优势得益于这种内存中的数据存储。
优化任意操作算子图(operator graphs)。
可以帮助优化整体数据处理流程的大数据查询的延迟计算。
提供简明、一致的Scala,Java和Python API。
支持语言:scala、java、Python、R
提供交互式Scala和Python Shell。目前暂不支持Java。

Apache Spark 入门简介
Spark源码剖析
楔子
Every day I remind myself that my inner and outer life are based on the labors of other men,living and dead,and that I must exert myself in order to give in the same measure as I have received and am still receiving.—-Albert Einstein
Apache Spark
了解一项新技术的最好方式就是看官网+源码+文档Apache Spark is a fast and general
enginefor large-scale data processing.
它是一种快速、通用的大数据分析引擎。spark 是集批处理、实时流处理(spark streaming)、交互式查询(spark SQL)、图计算(GraphX)于一体的。
Spark core
Spark Core是一个基本引擎,用于大规模并行和分布式数据处理。它主要负责:内存管理和故障恢复
在集群上安排、分布和监控作业
和存储系统进行交互
Spark引入了一个称为弹性分布式数据集(RDD,Resilient Distributed Dataset)的概念,它是一个不可变的、容错的、分布式对象集合,我们可以并行的操作这个集合。RDD可以包含任何类型的对象,它在加载外部数据集或者从驱动应用程序分发集合时创建。
RDD支持两种操作类型:
转换是一种操作(例如映射、过滤、联接、联合等等),它在一个RDD上执行操作,然后创建一个新的RDD来保存结果。
行动是一种操作(例如归并、计数、第一等等),它在一个RDD上执行某种计算,然后将结果返回。
在Spark中,转换是“懒惰”(lazy)的,也就是说它们不会立刻计算出结果。相反,它们只是“记住”要执行的操作以及要操作的数据集(例如文件)。只有当行为被调用时,转换才会真正的进行计算,并将结果返回给驱动器程序。这种设计让Spark运行得更有效率。例如,如果一个大文件要通过各种方式进行转换操作,并且文件被传递给第一个行为,那么Spark只会处理文件的第一行内容并将结果返回,而不会处理整个文件。
默认情况下,当你在经过转换的RDD上运行一个行为时,这个RDD有可能会被重新计算。然而,你也可以通过使用持久化或者缓存的方法,将一个RDD持久化从在尽可能多地在内存中而然后才往磁盘中去写,这样,Spark就会在集群上保留这些元素,当你下一次查询它时,查询速度会快很多。
SparkSQL
“`// sc is an existing SparkContext.启动shell后sc is available
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql(“CREATE TABLE IF NOT EXISTS src (key INT, value STRING)”)
sqlContext.sql(“LOAD DATA LOCAL INPATH examples/src/main/resources/kv1.txt’ INTO TABLE src”)
// Queries are expressed in HiveQL
sqlContext.sql(“FROM src SELECT key, value”).collect().foreach(println)
或者从Hdfs中读入数据表:
val sqlContext = new SQLContext(sc)
df = sqlContext.read.format(“com.databricks.spark.csv”).options(opts).load(hdfs
+ “/s_user”) //将hdfs dfs ls /s_user/*下所有文件读入形成dataframe的格式
“`
可以通过JDBC API将Spark数据集暴露出去,而且还可以用传统的BI和可视化工具在Spark数据上执行类似SQL的查询(比如Tableau)。也可以从外部(hive,文件,hdfs)上读入文件,进行sql语句的查询。
关于sparksql 的使用会在后面几篇文章中重点介绍。
Spark Streaming
Spark Streaming支持对流数据的实时处理,例如产品环境web服务器的日志文件(例如Apache Flume和HDFS/S3)、诸如Twitter的社交媒体以及像Kafka那样的各种各样的消息队列。在这背后,Spark Streaming会接收输入数据,然后将其分为不同的批次,接下来Spark引擎来处理这些批次,并根据批次中的结果,生成最终的流。整个过程如下所示。MLlib
MLlib是一个机器学习库,它提供了各种各样的算法,这些算法用来在集群上针对分类、回归、聚类、协同过滤等(可以在 machine learning 上查看Toptal的文章,来获取更过的信息)。其中一些算法也可以应用到流数据上,例如使用普通最小二乘法或者K均值聚类(还有更多)来计算线性回归。Apache Mahout(一个针对Hadoop的机器学习库)已经脱离MapReduce,转而加入Spark MLlib。GraphX
GraphX是一个库,用来处理图,执行基于图的并行操作。它针对ETL、探索性分析和迭代图计算提供了统一的工具。除了针对图处理的内置操作,GraphX还提供了一个库,用于通用的图算法,例如PageRank。
Spark特性
Spark通过在数据处理过程中成本更低的洗牌(Shuffle)方式,将MapReduce提升到一个更高的层次。利用内存数据存储和接近实时的处理能力,Spark比其他的大数据处理技术的性能要快很多倍。Spark还支持大数据查询的延迟计算,这可以帮助优化大数据处理流程中的处理步骤。Spark还提供高级的API以提升开发者的生产力,除此之外还为大数据解决方案提供一致的体系架构模型。
Spark将中间结果保存在内存中而不是将其写入磁盘,当需要多次处理同一数据集时,这一点特别实用。Spark的设计初衷就是既可以在内存中又可以在磁盘上工作的执行引擎。当内存中的数据不适用时,Spark操作符就会执行外部操作。Spark可以用于处理大于集群内存容量总和的数据集。
Spark会尝试在内存中存储尽可能多的数据然后将其写入磁盘。它可以将某个数据集的一部分存入内存而剩余部分存入磁盘。开发者需要根据数据和用例评估对内存的需求。Spark的性能优势得益于这种内存中的数据存储。
Spark的其他特性包括:
支持比Map和Reduce更多的函数。优化任意操作算子图(operator graphs)。
可以帮助优化整体数据处理流程的大数据查询的延迟计算。
提供简明、一致的Scala,Java和Python API。
支持语言:scala、java、Python、R
提供交互式Scala和Python Shell。目前暂不支持Java。
Spark体系架构
1.数据存储
支持从hadoop存储框架里的任何读入包括HDFS,HBase,Cassandra,hive。同时也可支持本地文件,输入2.API
通过API 开发者可以制定任何基于spark的应用。API的文档在spark 官方网站中3.资源调度
spark可以安装在单机pc下,也支持部署在yarn这样的分布式计算框架下Reference
用Apache Spark进行大数据处理Apache Spark 入门简介
Spark源码剖析

相关文章推荐
- linux服务器 Apache服务的源码安装与基本配置
- django apache error.log过大
- Apache Spark 1.6发布(新特性介绍)
- 【通信框架】Apache的开源通信框架thrift概述
- org.apache.log4j.Logger用法
- 入门: FreeBSD10.1+Apache2.4+PHP5.4+MySQL5.5
- chapter1 Apache ActiveMQ简介
- apache开源项目 --Struts
- apache开源项目--subversion
- apache开源项目--Syncope
- apache开源项目--Synapse
- apache开源项目 -- tez
- apache开源项目 -- tajo
- apache开源项目 -- tomee
- apache开源项目-- Turbine
- apache开源项目 -- Tuscany
- apache开源项目-- UIMA
- apache开源项目-- Usergrid
- apache开源项目-- Velocity
- apache开源项目 -- VXQuery