Swarm中binpack策略引起的棘手问题
2016-01-04 11:22
916 查看
Docker Swarm--Docker的本地化集群方案,自带两种调度策略,spread和binpack。Spread策略会尝试把每个容器平均地部署到每个节点上,而binpack策略会把容器尽量部署在主要的负载节点上。Spread的优点是如果一个节点失效了,只会有最少量的容器受影响,而binpack的优点是能提高资源使用率,保证空闲的资源得到最大化利用。

(Binpack vs Spread 策略)
长远来看,我相信以后会越来越多地使用binpack这种方式,因为它可以提高主机资源使用率。而主机宕机的风险也有办法尽量降低,那就是尽量使用无状态的微服务,因为无状态的服务能够自动快速的迁移到可用的节点上,从而把宕机的危害减到最小。
但是,如果你现在正使用着binpack,你需要特别小心的是容器间的协调关系,确保某些必须运行在同一个节点上的容器总能在相同的节点上运行着。
考虑一下这个场景,假如我们有两个有空闲资源的节点,其中一个几乎占用满了,而另一个几乎是没被占用,我们可以用两个装有[Docker的虚拟机]来模拟这个场景:
```sh
$ docker run swarm create
7a6441b8b92448475fb3f8e166ed2170
$ docker-machine create -d virtualbox --swarm --swarm-master --swarm-strategy binpack --swarm-discovery token://7a6441b8b92448475fb3f8e166ed2170 swarm-1
...
$ docker-machine create -d virtualbox --swarm --swarm-strategy binpack --swarm-discovery token://7a6441b8b92448475fb3f8e166ed2170 swarm-2
...
$ eval $(docker-machine env --swarm swarm-1)
$ docker info
Containers: 3
Images: 8
Role: primary
Strategy: binpack
Filters: health, port, dependency, affinity, constraint
Nodes: 2
swarm-1: 192.168.99.103:2376
└ Containers: 2
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 0 B / 1.021 GiB
└ Labels: executiondriver=native-0.2, kernelversion=4.1.12-boot2docker, operatingsystem=Boot2Docker 1.9.0 (TCL 6.4); master : 16e4a2a - Tue Nov 3 19:49:22 UTC 2015, provider=virtualbox, storagedriver=aufs
swarm-2: 192.168.99.104:2376
└ Containers: 1
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 0 B / 1.021 GiB
└ Labels: executiondriver=native-0.2, kernelversion=4.1.12-boot2docker, operatingsystem=Boot2Docker 1.9.0 (TCL 6.4); master : 16e4a2a - Tue Nov 3 19:49:22 UTC 2015, provider=virtualbox, storagedriver=aufs
CPUs: 2
Total Memory: 2.043 GiB
Name: 4da00a74a9b1
```
然后启动一个容器,而且这个容器占用了整个节点的一半内存(注意,当使用binpack策略时,必须指定资源的占用大小):
```sh
$ docker run -d --name web -m 512MB nginx
55c099f324e7a95aff47539231fdad3431077ee80200d418c49c10f30d5c8d52
$ docker info
Containers: 4
Images: 8
Role: primary
Strategy: binpack
Filters: health, port, dependency, affinity, constraint
Nodes: 2
swarm-1: 192.168.99.103:2376
└ Containers: 3
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 512 MiB / 1.021 GiB
└ Labels: executiondriver=native-0.2, kernelversion=4.1.12-boot2docker, operatingsystem=Boot2Docker 1.9.0 (TCL 6.4); master : 16e4a2a - Tue Nov 3 19:49:22 UTC 2015, provider=virtualbox, storagedriver=aufs
swarm-2: 192.168.99.104:2376
└ Containers: 1
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 0 B / 1.021 GiB
└ Labels: executiondriver=native-0.2, kernelversion=4.1.12-boot2docker, operatingsystem=Boot2Docker 1.9.0 (TCL 6.4); master : 16e4a2a - Tue Nov 3 19:49:22 UTC 2015, provider=virtualbox, storagedriver=aufs
CPUs: 2
Total Memory: 2.043 GiB
Name: 4da00a74a9b1
```
现在假如我们要再启动两个容器,一个web应用和一个与之关联的redis缓存。我们需要把缓存运行在与web应用相同的节点上,那我们就得在启动容器时使用<code>affinity</code>这个限制参数(使用<code>--link</code> 或 <code>--volumes-from</code>同样能起到限制作用)。我们以下边的命令实现:
```sh
$ docker run -d --name cache -m 512MB redis
abec45a34912397e1f335714c856d47472855e61d0a4787be70f1088cfd30a64
$ docker run -d --name app -m 512MB -e affinity:container==cache nginx
Error response from daemon: no resources available to schedule container
```
为什么出错了呢?Swarm通过binpack策略把第一个容器调配到那个资源快被占满的节点上,所以当应用容器要启动时,那个节点已经没有资源能分配给这个新的容器,所以Swarm被迫中止了启动并返回一个报错。
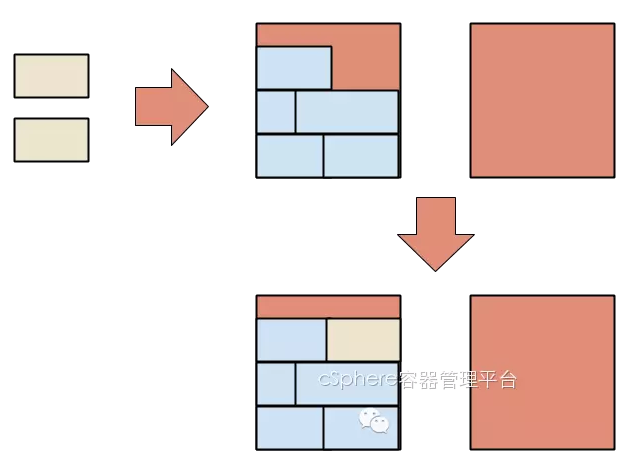
(binpack模式下尝试启动两个相互依赖的容器)
要避免这个情况并不简单,我们不能把这个缓存容器删掉再重新启动,因为Swarm还是会把它在同一个节点上启动,然后我们最终还是会遇到同样的问题。我们可以先启动另一个缓存容器和应用容器,然后才删除最初那个缓存容器,但是这样做又笨又浪费资源(而且第一个容器已经占用了<code>cache</code>这个名字)。另一个方案是在启动第一个容器时,强制它只能在满足两个容器所需资源的节点上运行:
```sh
$ docker run -d --name cache -m 512MB -e constraint:node==swarm-2 redis
95b66cb5c7a01b641a33d6cd20e32b33659e218fb9d6ba2ff352048901af2b57
$ docker run -d --name app -m 512MB -e affinity:container==cache nginx
d67a815a064f2e69492ab882f5c3b04dc788b756cb3a7753a26cb94c00417b77
```
这次成功了,但是还并不完美。我们现在只有手动去管理节点了,而这个工作正是我们最初希望Swarm能自动化实现的。另外,还有个可能是我们还没启动第二个容器前,就被系统或者其他用户占用掉了第二个节点的资源,那样的话,这个方案还是会失败。还有个方法是在同一个容器里一起运行着应用与缓存,这可能是目前最好的方案了,但这样不大灵活而且还得额外的工夫去重做镜像。
这种需要多个容器协调的情况不一定会经常出现,某种程度上来说,甚至可以认为是一种反模式,因为服务之间不应该有这种紧耦合。不过,假定这种多个容器的绑定就是我们想要的,我们实际想要的是让Swarm同时调度两个容器。这是Kubernetes中的pods概念,github上的issue 8781已经有很大的篇幅讨论在Docker中实现类似的概念,但是目前Docker的核心团队还没开始支持这个特性,这种情况下,还有其他方案可以解决吗?我们能想到仅有(可能这些突发奇想还有瑕疵):
使用”保持“状态,类似于Docker的创建,使容器能在节点上定义,但并不会运行。两个容器能被同时创建并运行,这时<code>Docker create</code>不满足这个需求,Swarm在创建期间会创建容器,但不会运行,类似这样:
```sh
$ docker hold -d --name cache -m 512MB redis
$ docker hold -d --name app -m 512MB -e affinity:container==cache nginx
$ docker unhold redis cache
...
```
"forward"限制了容器在依赖被满足之间都不会运行,类似这样:
```sh
$ docker run -d --name cache -m 512MB -e forward-affinity:container==nginx redis
Delaying container start until nginx container is scheduled
$ docker run -d --name app -m 512MB -e affinity:container==cache nginx
95b66cb5c7a01b641a33d6cd20e32b33659e218fb9d6ba2ff352048901af2b57
d67a815a064f2e69492ab882f5c3b04dc788b756cb3a7753a26cb94c00417b77
```
这样的话,当第二个容器启动时,Swarm能自动把第一个容器迁移到资源满足两个容器的节点上,这样系统会被中断并迁移,还有目前Swarm还没支持节点间的重新负载均衡,不过这已经在着手开发中了,有望在下一版本用到。
如了解更多docker相关知识,请观看培训视频:https://csphere.cn/training!
(Binpack vs Spread 策略)
长远来看,我相信以后会越来越多地使用binpack这种方式,因为它可以提高主机资源使用率。而主机宕机的风险也有办法尽量降低,那就是尽量使用无状态的微服务,因为无状态的服务能够自动快速的迁移到可用的节点上,从而把宕机的危害减到最小。
但是,如果你现在正使用着binpack,你需要特别小心的是容器间的协调关系,确保某些必须运行在同一个节点上的容器总能在相同的节点上运行着。
考虑一下这个场景,假如我们有两个有空闲资源的节点,其中一个几乎占用满了,而另一个几乎是没被占用,我们可以用两个装有[Docker的虚拟机]来模拟这个场景:
```sh
$ docker run swarm create
7a6441b8b92448475fb3f8e166ed2170
$ docker-machine create -d virtualbox --swarm --swarm-master --swarm-strategy binpack --swarm-discovery token://7a6441b8b92448475fb3f8e166ed2170 swarm-1
...
$ docker-machine create -d virtualbox --swarm --swarm-strategy binpack --swarm-discovery token://7a6441b8b92448475fb3f8e166ed2170 swarm-2
...
$ eval $(docker-machine env --swarm swarm-1)
$ docker info
Containers: 3
Images: 8
Role: primary
Strategy: binpack
Filters: health, port, dependency, affinity, constraint
Nodes: 2
swarm-1: 192.168.99.103:2376
└ Containers: 2
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 0 B / 1.021 GiB
└ Labels: executiondriver=native-0.2, kernelversion=4.1.12-boot2docker, operatingsystem=Boot2Docker 1.9.0 (TCL 6.4); master : 16e4a2a - Tue Nov 3 19:49:22 UTC 2015, provider=virtualbox, storagedriver=aufs
swarm-2: 192.168.99.104:2376
└ Containers: 1
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 0 B / 1.021 GiB
└ Labels: executiondriver=native-0.2, kernelversion=4.1.12-boot2docker, operatingsystem=Boot2Docker 1.9.0 (TCL 6.4); master : 16e4a2a - Tue Nov 3 19:49:22 UTC 2015, provider=virtualbox, storagedriver=aufs
CPUs: 2
Total Memory: 2.043 GiB
Name: 4da00a74a9b1
```
然后启动一个容器,而且这个容器占用了整个节点的一半内存(注意,当使用binpack策略时,必须指定资源的占用大小):
```sh
$ docker run -d --name web -m 512MB nginx
55c099f324e7a95aff47539231fdad3431077ee80200d418c49c10f30d5c8d52
$ docker info
Containers: 4
Images: 8
Role: primary
Strategy: binpack
Filters: health, port, dependency, affinity, constraint
Nodes: 2
swarm-1: 192.168.99.103:2376
└ Containers: 3
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 512 MiB / 1.021 GiB
└ Labels: executiondriver=native-0.2, kernelversion=4.1.12-boot2docker, operatingsystem=Boot2Docker 1.9.0 (TCL 6.4); master : 16e4a2a - Tue Nov 3 19:49:22 UTC 2015, provider=virtualbox, storagedriver=aufs
swarm-2: 192.168.99.104:2376
└ Containers: 1
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 0 B / 1.021 GiB
└ Labels: executiondriver=native-0.2, kernelversion=4.1.12-boot2docker, operatingsystem=Boot2Docker 1.9.0 (TCL 6.4); master : 16e4a2a - Tue Nov 3 19:49:22 UTC 2015, provider=virtualbox, storagedriver=aufs
CPUs: 2
Total Memory: 2.043 GiB
Name: 4da00a74a9b1
```
现在假如我们要再启动两个容器,一个web应用和一个与之关联的redis缓存。我们需要把缓存运行在与web应用相同的节点上,那我们就得在启动容器时使用<code>affinity</code>这个限制参数(使用<code>--link</code> 或 <code>--volumes-from</code>同样能起到限制作用)。我们以下边的命令实现:
```sh
$ docker run -d --name cache -m 512MB redis
abec45a34912397e1f335714c856d47472855e61d0a4787be70f1088cfd30a64
$ docker run -d --name app -m 512MB -e affinity:container==cache nginx
Error response from daemon: no resources available to schedule container
```
为什么出错了呢?Swarm通过binpack策略把第一个容器调配到那个资源快被占满的节点上,所以当应用容器要启动时,那个节点已经没有资源能分配给这个新的容器,所以Swarm被迫中止了启动并返回一个报错。
(binpack模式下尝试启动两个相互依赖的容器)
要避免这个情况并不简单,我们不能把这个缓存容器删掉再重新启动,因为Swarm还是会把它在同一个节点上启动,然后我们最终还是会遇到同样的问题。我们可以先启动另一个缓存容器和应用容器,然后才删除最初那个缓存容器,但是这样做又笨又浪费资源(而且第一个容器已经占用了<code>cache</code>这个名字)。另一个方案是在启动第一个容器时,强制它只能在满足两个容器所需资源的节点上运行:
```sh
$ docker run -d --name cache -m 512MB -e constraint:node==swarm-2 redis
95b66cb5c7a01b641a33d6cd20e32b33659e218fb9d6ba2ff352048901af2b57
$ docker run -d --name app -m 512MB -e affinity:container==cache nginx
d67a815a064f2e69492ab882f5c3b04dc788b756cb3a7753a26cb94c00417b77
```
这次成功了,但是还并不完美。我们现在只有手动去管理节点了,而这个工作正是我们最初希望Swarm能自动化实现的。另外,还有个可能是我们还没启动第二个容器前,就被系统或者其他用户占用掉了第二个节点的资源,那样的话,这个方案还是会失败。还有个方法是在同一个容器里一起运行着应用与缓存,这可能是目前最好的方案了,但这样不大灵活而且还得额外的工夫去重做镜像。
这种需要多个容器协调的情况不一定会经常出现,某种程度上来说,甚至可以认为是一种反模式,因为服务之间不应该有这种紧耦合。不过,假定这种多个容器的绑定就是我们想要的,我们实际想要的是让Swarm同时调度两个容器。这是Kubernetes中的pods概念,github上的issue 8781已经有很大的篇幅讨论在Docker中实现类似的概念,但是目前Docker的核心团队还没开始支持这个特性,这种情况下,还有其他方案可以解决吗?我们能想到仅有(可能这些突发奇想还有瑕疵):
使用”保持“状态,类似于Docker的创建,使容器能在节点上定义,但并不会运行。两个容器能被同时创建并运行,这时<code>Docker create</code>不满足这个需求,Swarm在创建期间会创建容器,但不会运行,类似这样:
```sh
$ docker hold -d --name cache -m 512MB redis
$ docker hold -d --name app -m 512MB -e affinity:container==cache nginx
$ docker unhold redis cache
...
```
"forward"限制了容器在依赖被满足之间都不会运行,类似这样:
```sh
$ docker run -d --name cache -m 512MB -e forward-affinity:container==nginx redis
Delaying container start until nginx container is scheduled
$ docker run -d --name app -m 512MB -e affinity:container==cache nginx
95b66cb5c7a01b641a33d6cd20e32b33659e218fb9d6ba2ff352048901af2b57
d67a815a064f2e69492ab882f5c3b04dc788b756cb3a7753a26cb94c00417b77
```
这样的话,当第二个容器启动时,Swarm能自动把第一个容器迁移到资源满足两个容器的节点上,这样系统会被中断并迁移,还有目前Swarm还没支持节点间的重新负载均衡,不过这已经在着手开发中了,有望在下一版本用到。
如了解更多docker相关知识,请观看培训视频:https://csphere.cn/training!

相关文章推荐
- docker容器的网络信息查看
- 在windows下的安装Docker的教程
- 8个你可能不知道的Docker知识
- 在Docker中自动化部署Ruby on Rails的教程
- 搭建基于Docker的PHP开发环境的详细教程
- 利用OpenVSwitch在多台主机上部署Docker的教程
- ubuntu14.04+docker的安装及使用
- Docker 清理命令集锦
- 再Docker中架设完整的WordPress站点全攻略
- 基于 Docker 开发 NodeJS 应用
- 在Docker上部署Python的Flask框架的教程
- 在Docker上开始部署Python应用的教程
- 详解在Python和IPython中使用Docker
- 使用IPython来操作Docker容器的入门指引
- OSX下brew安装docker(boot2docker)
- docker 设置TLS远程访问
- mesos + marathon + docker部署
- docker-registry server部署
- python3操作Docker Remote API
- Docker使用supervisor启动Mysql