索引的本质
2015-12-21 13:51
162 查看
如有不正确的或者理解不到位的地方,欢迎斧正。
信息检索问题
首先我们来看问题域。每一种技术产物都是为解决某类问题。不从问题域出发,我们就很难理解为什么它是这样的。就像那些没学过“程序语言”设计的人,只能被程序语言牵着走。
信息检索背后的模型其实很简单:就是从大量的信息中找出需要的信息。这类问题有个更专业的名字:信息检索(Information Retrieval)。生活中,这样的问题数不胜数:
我们怎么能快速地找出某个单词在书中第几页呢?
如果没有搜索引擎和目录,在大型图书馆如何找到我们要的书?
找房人通过浏览每一份房产信息来找到自己期望的房子,这样的效率是不是有些低?
怎么方便地找出附近所有的中餐厅呢?

解决信息检索问题
上面只是介绍信息检索的背后最简单的一面。它的背后存在更复杂的问题。
想象一下你需要在以下一串数字中找最大的那个数字:
1, 23, 56 , 3, 40, 41.1, 900, 12
这很简单,你一眼看过去就可以得出答案,但如果存在100亿个数字呢?假如一个人一秒能辨认出10个数中最大的数字,那么他365x24小时不停地看,也要31.6887646 年才能得到答案。
这样无聊而且不人道的事情,我们交给机器做。这引出我们信息检索的第一个问题:信息量太大了,以至于我们人在有限的时间找不到我们真正想要的,需要机器来帮助我们。
可是,机器怎么知道我们要找什么样的东西呢?这时,引出我们信息检索的第二个问题:如何让机器理解我们要找什么样的东西呢?答案很简单:我们人告诉它不就可以。这个思路是正确的,在我看来。沿着这个思路去实现时,我想我们大概会遇到如下问题:
1. 我们人类如何表达“我们要找啥”这个问题?
我们通常的做法是给出我们要找的信息的一部分特征。在搜索领域中,这“一部分特征”的术语称为关键字。事实上,“关键字”就是我们大脑中要找的信息的“特征”。
2. 如何让机器理解“我们要找啥”这个问题?
这个问题就很复杂了。当我们在谷歌里搜索“IR”时,它怎么知道我要搜索是“Information Retrieval”,还是“Ingersoll Rand”?
3. 机器怎么知道哪些信息就是我们要找的?
本文重点是要回答第3个问题。虽然本质上,这3个问题应该放在一起讨论。
索引的本质
面对“机器怎么知道哪些信息是我们要找的”这个问题,我所见到的解决域模型是:告诉机器如何抽取(或逐个地)信息的特征(索引),然后机器拿这些“索引”与搜索者大脑中信息的特征(关键字)对比,就可以知道哪些信息是用户想找的了。
这里,我们就已经得出了索引的本质:信息的特征。
回到一开始举的例子:
字典的都会有按字母顺序排的目录和按笔画排的目录,字母和笔画是字的特征,所以,可以拿它来做索引
图书馆中每一本书都会有一个编号,编号可由有意义的字母表示,比如T2300004可代表科技类2楼3排等等。我们可以很容易的根据这个编号找出这本书。这里给我们一个提示,当被搜索的信息的自有特征不明显时,我们可以人工为其加上。比如一部电影,我们可以人工的为其加上标签如动作片、简爱,以便搜索。因为有些人不一定只根据电影名搜索,他还可能搜索“爱情片”
附近的餐厅的特征可以有:地理坐标、是否好吃、价格是否优惠等。
既然索引就是信息的特征,那么我们如何组织索引才能方便我们使用索引呢?目前有两种方式组织索引:
信息后关联一批特征
每一种特征后关联一批信息
正向索引:信息后关联一批特征
以我的经验,先讲正向索引,比先讲反向索引能让读者更好的理解索引的本质。
其实正向索引的结构很简单:
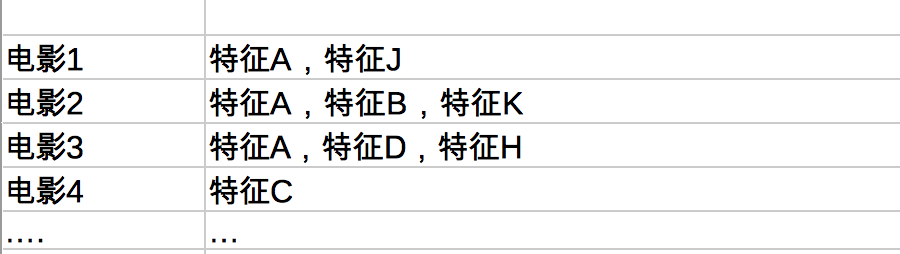
反向索引:每一种特征后关联一批信息
在信息检索领域,反向索引实际上称为:Inverted index。国内经常翻译成倒排索引。和大多数人一样,一开始对这个名词一头雾水。所以,我更喜欢将它翻译成反向索引。之所以称为inverted,应该就是因为正向的存在吧。
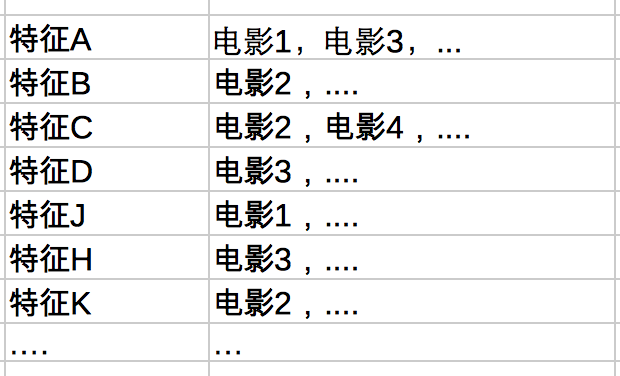
然而,解决域模型决定了我们会使用反向索引结构,而不会使用正向的。也许这就是为了什么大多信息检索类的书籍对正向索引只字不提。
实现反向索引
不论实现正向还是反向的索引,都需要从信息抽取出其特征。不同类型的信息表现出来的特征不同。
对于文本信息,我们认为“一个词的重要性取决于它在文档中出现的频率”(Luhn于1958年提出)。也就是说你在查询时,查询词在文档中出现的频率,决定文档的重要性。
基于这一点,实现对文本信息的特征抽取,我们似乎只需要简单的将文本所有的词都作为索引项(术语称为term)就好了。但实际情况并没有这么简单。这个过程称为分词(tokenizing)。只是这个处理过程,不同的人或框架又分为几个环节。
我们可以理解它是这样一个过程,比如存在两份信息:
1. The quick brown fox jumped over the lazy dog
2. Quick brown foxes leap over lazy dogs in summer
使用分词器处理后得到的结果是:

当我们搜索“quick brown”时,会得到结果:

然而使用不同的分词器,会得到不同的索引,最终影响到搜索结果。仔细的同学就会看出上面的反向索引有什么地方不对了。所以,建立索引时,一定要选择合适的分词器。
本小节的例子来自《Elasticsearch: The Definitive Guide》
小结
我们从了解问题域开始,一步步推导出索引的本质——信息的特征。有了这样的认识,我们就可以很容易的理解为什么现在的搜索引擎是这样子的,而不至迷失在错综复杂知识迷宫中。
但是,对于信息检索,除了索引这种解决域模型,我们就没有别的出路了吗?这是一个值得思考的问题。
本文说是信息检索,实际上更准确的应该说是文本信息检索。对于图片检索和语音检索,我们无法用分词器进行处理了,那怎么办呢?不要忘了我们的解决域模型:告诉机器如何抽取(或逐个地)信息的特征(索引),然后机器拿这些“索引”与搜索者大脑中信息的特征(关键字)对比,就可以知道哪些信息是用户想找的了。对于图片检索和语音检索,我们要做的就是想办法从图片和语音中抽取出它们自有信息特征。
信息检索问题
首先我们来看问题域。每一种技术产物都是为解决某类问题。不从问题域出发,我们就很难理解为什么它是这样的。就像那些没学过“程序语言”设计的人,只能被程序语言牵着走。
信息检索背后的模型其实很简单:就是从大量的信息中找出需要的信息。这类问题有个更专业的名字:信息检索(Information Retrieval)。生活中,这样的问题数不胜数:
我们怎么能快速地找出某个单词在书中第几页呢?
如果没有搜索引擎和目录,在大型图书馆如何找到我们要的书?
找房人通过浏览每一份房产信息来找到自己期望的房子,这样的效率是不是有些低?
怎么方便地找出附近所有的中餐厅呢?
解决信息检索问题
上面只是介绍信息检索的背后最简单的一面。它的背后存在更复杂的问题。
想象一下你需要在以下一串数字中找最大的那个数字:
1, 23, 56 , 3, 40, 41.1, 900, 12
这很简单,你一眼看过去就可以得出答案,但如果存在100亿个数字呢?假如一个人一秒能辨认出10个数中最大的数字,那么他365x24小时不停地看,也要31.6887646 年才能得到答案。
这样无聊而且不人道的事情,我们交给机器做。这引出我们信息检索的第一个问题:信息量太大了,以至于我们人在有限的时间找不到我们真正想要的,需要机器来帮助我们。
可是,机器怎么知道我们要找什么样的东西呢?这时,引出我们信息检索的第二个问题:如何让机器理解我们要找什么样的东西呢?答案很简单:我们人告诉它不就可以。这个思路是正确的,在我看来。沿着这个思路去实现时,我想我们大概会遇到如下问题:
1. 我们人类如何表达“我们要找啥”这个问题?
我们通常的做法是给出我们要找的信息的一部分特征。在搜索领域中,这“一部分特征”的术语称为关键字。事实上,“关键字”就是我们大脑中要找的信息的“特征”。
2. 如何让机器理解“我们要找啥”这个问题?
这个问题就很复杂了。当我们在谷歌里搜索“IR”时,它怎么知道我要搜索是“Information Retrieval”,还是“Ingersoll Rand”?
3. 机器怎么知道哪些信息就是我们要找的?
本文重点是要回答第3个问题。虽然本质上,这3个问题应该放在一起讨论。
索引的本质
面对“机器怎么知道哪些信息是我们要找的”这个问题,我所见到的解决域模型是:告诉机器如何抽取(或逐个地)信息的特征(索引),然后机器拿这些“索引”与搜索者大脑中信息的特征(关键字)对比,就可以知道哪些信息是用户想找的了。
这里,我们就已经得出了索引的本质:信息的特征。
回到一开始举的例子:
字典的都会有按字母顺序排的目录和按笔画排的目录,字母和笔画是字的特征,所以,可以拿它来做索引
图书馆中每一本书都会有一个编号,编号可由有意义的字母表示,比如T2300004可代表科技类2楼3排等等。我们可以很容易的根据这个编号找出这本书。这里给我们一个提示,当被搜索的信息的自有特征不明显时,我们可以人工为其加上。比如一部电影,我们可以人工的为其加上标签如动作片、简爱,以便搜索。因为有些人不一定只根据电影名搜索,他还可能搜索“爱情片”
附近的餐厅的特征可以有:地理坐标、是否好吃、价格是否优惠等。
既然索引就是信息的特征,那么我们如何组织索引才能方便我们使用索引呢?目前有两种方式组织索引:
信息后关联一批特征
每一种特征后关联一批信息
正向索引:信息后关联一批特征
以我的经验,先讲正向索引,比先讲反向索引能让读者更好的理解索引的本质。
其实正向索引的结构很简单:
反向索引:每一种特征后关联一批信息
在信息检索领域,反向索引实际上称为:Inverted index。国内经常翻译成倒排索引。和大多数人一样,一开始对这个名词一头雾水。所以,我更喜欢将它翻译成反向索引。之所以称为inverted,应该就是因为正向的存在吧。
然而,解决域模型决定了我们会使用反向索引结构,而不会使用正向的。也许这就是为了什么大多信息检索类的书籍对正向索引只字不提。
实现反向索引
不论实现正向还是反向的索引,都需要从信息抽取出其特征。不同类型的信息表现出来的特征不同。
对于文本信息,我们认为“一个词的重要性取决于它在文档中出现的频率”(Luhn于1958年提出)。也就是说你在查询时,查询词在文档中出现的频率,决定文档的重要性。
基于这一点,实现对文本信息的特征抽取,我们似乎只需要简单的将文本所有的词都作为索引项(术语称为term)就好了。但实际情况并没有这么简单。这个过程称为分词(tokenizing)。只是这个处理过程,不同的人或框架又分为几个环节。
我们可以理解它是这样一个过程,比如存在两份信息:
1. The quick brown fox jumped over the lazy dog
2. Quick brown foxes leap over lazy dogs in summer
使用分词器处理后得到的结果是:
当我们搜索“quick brown”时,会得到结果:
然而使用不同的分词器,会得到不同的索引,最终影响到搜索结果。仔细的同学就会看出上面的反向索引有什么地方不对了。所以,建立索引时,一定要选择合适的分词器。
本小节的例子来自《Elasticsearch: The Definitive Guide》
小结
我们从了解问题域开始,一步步推导出索引的本质——信息的特征。有了这样的认识,我们就可以很容易的理解为什么现在的搜索引擎是这样子的,而不至迷失在错综复杂知识迷宫中。
但是,对于信息检索,除了索引这种解决域模型,我们就没有别的出路了吗?这是一个值得思考的问题。
本文说是信息检索,实际上更准确的应该说是文本信息检索。对于图片检索和语音检索,我们无法用分词器进行处理了,那怎么办呢?不要忘了我们的解决域模型:告诉机器如何抽取(或逐个地)信息的特征(索引),然后机器拿这些“索引”与搜索者大脑中信息的特征(关键字)对比,就可以知道哪些信息是用户想找的了。对于图片检索和语音检索,我们要做的就是想办法从图片和语音中抽取出它们自有信息特征。

相关文章推荐
- Virtual Friend Function
- IdHttp 资料
- Kettle使用资源库日志信息配置
- 自己指定的学习路线
- 了解负载均衡 会话保持 session同步(转)
- DT大数据梦工厂免费实战大数据视频全集
- Builder设计模式设置自定义Dialog
- SATA硬盘的数据和电源接口定义
- Kafka设计解析(三):Kafka High Availability (下)
- 微信支付-小小工程狮的成长之路
- 日经春秋 20151221
- 文件缓存
- BZOJ 1509: [NOI2003]逃学的小孩( 树形dp )
- oracle 查看后台正在执行的脚本
- jsp的三种自定义标签 写法示例
- swfobject简单封装
- 关于android:clickable="false"失效的问题
- 关于Android中工作者线程的思考
- 顺序右移数组元素(第0届第5题)
- 天声人語 20151221 立憲か、非立憲か