java容器源码分析(二)——LinkedList
2015-12-16 00:00
513 查看
摘要: 本文分析了linkedList的实现。顺便也一块复习了Iterator、对象序列化,反序列化、深浅拷贝。
本文内容:
一、LinkedList概述
二、LinkedList源码实现
LinkedList概述
LinkedList底层是双向循环链表实现的。先看一下LinkedList的继承图:
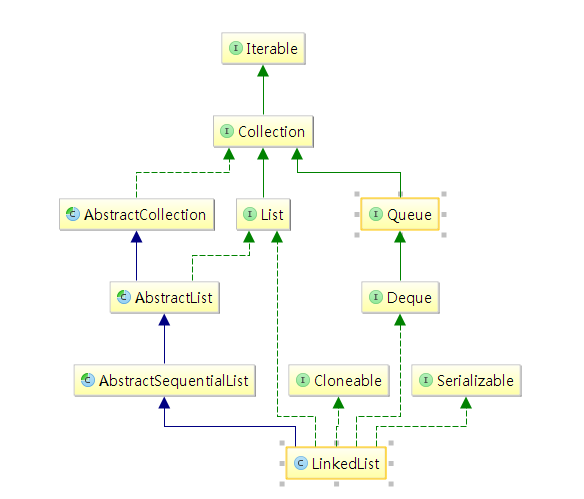
由继承关系图可以看到,LinkedList同时实现了List和Queue(Deque)的功能,也就是说LinkedList既可以做List,也可以当双端队列使用。
这里还有个很奇怪的继承:LinkedList同时继承了List,也继承了AbstractList。但AbstractList已经继承了List,为什么LinkedList还要直接继承List呢?stackoverflow有过讨论(Why does ArrayList have “implements List”?) 或许只有Josh Bloch才知道吧。或许他写的时候知道,但现在只有上帝知道了吧。
源码实现
LinkedList定义
linkedList类的定义如下:
LinkedList继承AbstractSequentialList,实现List,Deque,Cloneable,Serialiable接口。下面简要说明一下这几个类及接口的作用。
Cloneable接口
Cloneable有什么用呢?打开源码,发现里面只有一个空接口,没有具体的实现:
再看一下注释:
A class implements the Cloneable interface to indicate to the Object.clone() method that it is legal for that method to make a field-for-field copy of instances of that class
大意是说实现Cloneable接口就意味这个类将会会实现Object.clone()方法。LinkedList实现的是浅拷贝(clone方法详解可以看这里http://blog.csdn.net/zhangjg_blog/article/details/18369201)
等一下,Cloneable只是一个接口并没有具体的方法,如果我的类继承了Cloneable接口,但没实现clone()方法,会如何呢?
Invoking Object's clone method on an instance that does not implement the Cloneable interface results in the exception CloneNotSupportedException being thrown.
大意是说,如果没实现clone方法,在调用clone()方法时,会抛出CloneNotSupportedException异常。
由上分析可以看出,LinkedList是可以用clone方法的。LinkedList的clone实现后面再分析。
Serializable接口
serializable接口表明该类是可以序列化的,LinkedList的序列化后面分析。
List、Deque接口
链表和双端队列的实现
AbstractSequentialList类
这是一个抽象类,把线性List的可公用的类抽象到里面,主要是给顺序访问的list(如LinkedList)提供模拟随机访问的方法。这种方法在日常编写代码中也是经常用到的:用接口做规范,用抽象类实现大部分通用功能,然后继承抽象类实现各个不同的具体功能。
LinkedList构造函数
很好,什么都没有。
add方法
add方法通过调用linkLast将新元素添加到链表的尾部。
原来LinkedList的元素存放在Node中,这是一个定义在LinkedList中的静态内部类。定义如下:
linkLast是个很中规中矩的链表尾部添加元素方法,其实现添加一个方法如下:
获取指向尾部元素l,
2 . 创建一个新元素
3 .将新元素设成新的尾部元素
4 .如果l为空,证明链表为空,所以将这个元素也设置成头部元素,否则将l的next指向新的该node
5.size,modCount自增
By The Way!!!! modCount的作用是什么?
modCount定义在LinkedList的间接父类AbstractList中
The number of times this list has been structurally modified. Structural modifications are those that change the size of the list, or otherwise perturb it in such a fashion that iterations in progress may yield incorrect results.
This field is used by the iterator and list iterator implementation returned by the iterator and listIterator methods. If the value of this field changes unexpectedly, the iterator (or list iterator) will throw a ConcurrentModificationException in response to the next, remove, previous, set or add operations. This provides fail-fast behavior, rather than non-deterministic behavior in the face of concurrent modification during iteration.
Use of this field by subclasses is optional. If a subclass wishes to provide fail-fast iterators (and list iterators), then it merely has to increment this field in its add(int, E) and remove(int) methods (and any other methods that it overrides that result in structural modifications to the list). A single call to add(int, E) or remove(int) must add no more than one to this field, or the iterators (and list iterators) will throw bogus ConcurrentModificationExceptions. If an implementation does not wish to provide fail-fast iterators, this field may be ignored.
看一下源码中的注释,大意是说modCount是记录list大小改变的次数。主要提供给iterator来实现fail-fast。在分析Iterator的时候我们就会看到其做用了。
get方法
先检查index是否在满足要求的范围,不满足将抛出IndexOutOfBoundsException异常
调用node方法返回指定的元素。这里做了一点优化,如果index小于元素个数的一半,则从左到右查找,如果index大于元素个数的一半,则从右到左查找。
remove方法
看源码,remove方法移除的是第一个出现的元素。如果移除的元素存在,则返回true,否则返回false。移除的操作在unlink方法中。
这种删除链表元素的方法任何一本数据结构都差不多,不解释了。
Iterator及ListIterator接口分析
我们常见的容器都有iterator()方法,链表还有listIterator(),它们的继承关系如下:
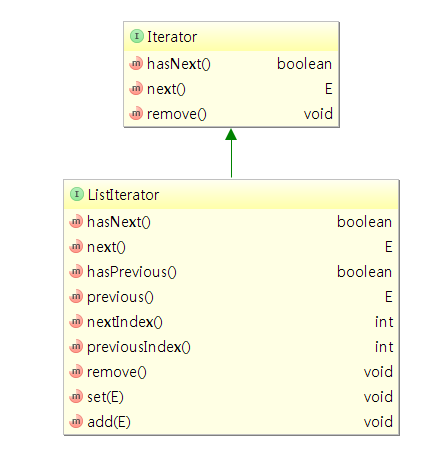
由以上继承图可以看出,Iterator接口没有往回遍历的方法,而ListIterator扩充了往回遍历的方法。下面说下ListIterator和Iteraotr在LinkedList的实现。
listIterator方法
这方法定义在AbstractList中,返回listIteraotr(0)作为默认的iterator。
!!!注意:在LinkedList的listIterator()调用的listIterator(0)并不是AbstractList中的实现,而是通过继承在LinkedList中的实现.
先检查index的范围,注意,合法范围是[0,size] (为什么不是[0,size)呢?看下面分析!)。然后创建一个ListItr对象返回。ListItr是LinkedList的一个内部类,其定义如下:
ListItr构造函数:
构造函数是next和nextIndex的赋值,继续看下去,hasNext判断下个元素是否存在
继续看next方法
看到这里,结合hasNext和Next终于知道为什么isPositionIndex的范围检查是[0,size]而不是[0,size)了。index=size表示着已经到元素最后,没发读取下个元素了。继续看代码
每次都要判断lastReturned,而lastReturned只有在next和previous中会被赋值,因此,要删除元素,要先next()/previous(),然后才能remove。否则抛异常。
这个方法,目测是modCount的主要用途,是的!看这个demo
这个demo将会抛出ConcurrentModificationException异常。好吧,为什么要抛异常?好吧,这里作者不想我们在用迭代器的时候还通过容器实例操作容器(我yy的),谁知道会发生什么事情呢?
所以,在使用迭代器时,要我的经验是:不要在迭代器里面再通过该容器实例操作容器
到这里,Iterator/ListIterator方法告一段落
clone方法
由注释知道了,这个clone方法是浅拷贝(shallow copy)。先通过superClone拷贝,然后将first,last,size,modCount都给初始化成默认状态,然后调用链表的add方法添加各个元素。
序列化,反序列化
LinkedList没有用默认的序列化,而是自己实现的自定义序列化反序列化方法。
注意:writeObject()与readObject()都是private方法,那么它们是如何被调用的呢?毫无疑问,是使用反射。
总结:
在写本文时,没有完全分析LinkedList的增删改,我觉得这部分都是上大学时数据结构学过的内容。相反,一些其他内容,比如clone深浅拷贝,序列化却是我们经常忽略的内容。还有iterator的用法,说真的,平时也不怎么用,有时在iterator上踩几个坑也是有可能的。
本文内容:
一、LinkedList概述
二、LinkedList源码实现
LinkedList概述
LinkedList底层是双向循环链表实现的。先看一下LinkedList的继承图:
由继承关系图可以看到,LinkedList同时实现了List和Queue(Deque)的功能,也就是说LinkedList既可以做List,也可以当双端队列使用。
这里还有个很奇怪的继承:LinkedList同时继承了List,也继承了AbstractList。但AbstractList已经继承了List,为什么LinkedList还要直接继承List呢?stackoverflow有过讨论(Why does ArrayList have “implements List”?) 或许只有Josh Bloch才知道吧。或许他写的时候知道,但现在只有上帝知道了吧。
源码实现
LinkedList定义
linkedList类的定义如下:
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
LinkedList继承AbstractSequentialList,实现List,Deque,Cloneable,Serialiable接口。下面简要说明一下这几个类及接口的作用。
Cloneable接口
Cloneable有什么用呢?打开源码,发现里面只有一个空接口,没有具体的实现:
public interface Cloneable {
}再看一下注释:
A class implements the Cloneable interface to indicate to the Object.clone() method that it is legal for that method to make a field-for-field copy of instances of that class
大意是说实现Cloneable接口就意味这个类将会会实现Object.clone()方法。LinkedList实现的是浅拷贝(clone方法详解可以看这里http://blog.csdn.net/zhangjg_blog/article/details/18369201)
等一下,Cloneable只是一个接口并没有具体的方法,如果我的类继承了Cloneable接口,但没实现clone()方法,会如何呢?
Invoking Object's clone method on an instance that does not implement the Cloneable interface results in the exception CloneNotSupportedException being thrown.
大意是说,如果没实现clone方法,在调用clone()方法时,会抛出CloneNotSupportedException异常。
由上分析可以看出,LinkedList是可以用clone方法的。LinkedList的clone实现后面再分析。
Serializable接口
serializable接口表明该类是可以序列化的,LinkedList的序列化后面分析。
List、Deque接口
链表和双端队列的实现
AbstractSequentialList类
这是一个抽象类,把线性List的可公用的类抽象到里面,主要是给顺序访问的list(如LinkedList)提供模拟随机访问的方法。这种方法在日常编写代码中也是经常用到的:用接口做规范,用抽象类实现大部分通用功能,然后继承抽象类实现各个不同的具体功能。
LinkedList构造函数
public LinkedList() {
}很好,什么都没有。
add方法
public boolean add(E e) {
linkLast(e);
return true;
}add方法通过调用linkLast将新元素添加到链表的尾部。
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last; //1
final Node<E> newNode = new Node<>(l, e, null);//2
last = newNode;//3
if (l == null)//4
first = newNode;
else
l.next = newNode;
//5
size++;
modCount++;
}原来LinkedList的元素存放在Node中,这是一个定义在LinkedList中的静态内部类。定义如下:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}linkLast是个很中规中矩的链表尾部添加元素方法,其实现添加一个方法如下:
获取指向尾部元素l,
2 . 创建一个新元素
3 .将新元素设成新的尾部元素
4 .如果l为空,证明链表为空,所以将这个元素也设置成头部元素,否则将l的next指向新的该node
5.size,modCount自增
By The Way!!!! modCount的作用是什么?
modCount定义在LinkedList的间接父类AbstractList中
protected transient int modCount = 0;
The number of times this list has been structurally modified. Structural modifications are those that change the size of the list, or otherwise perturb it in such a fashion that iterations in progress may yield incorrect results.
This field is used by the iterator and list iterator implementation returned by the iterator and listIterator methods. If the value of this field changes unexpectedly, the iterator (or list iterator) will throw a ConcurrentModificationException in response to the next, remove, previous, set or add operations. This provides fail-fast behavior, rather than non-deterministic behavior in the face of concurrent modification during iteration.
Use of this field by subclasses is optional. If a subclass wishes to provide fail-fast iterators (and list iterators), then it merely has to increment this field in its add(int, E) and remove(int) methods (and any other methods that it overrides that result in structural modifications to the list). A single call to add(int, E) or remove(int) must add no more than one to this field, or the iterators (and list iterators) will throw bogus ConcurrentModificationExceptions. If an implementation does not wish to provide fail-fast iterators, this field may be ignored.
看一下源码中的注释,大意是说modCount是记录list大小改变的次数。主要提供给iterator来实现fail-fast。在分析Iterator的时候我们就会看到其做用了。
get方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}先检查index是否在满足要求的范围,不满足将抛出IndexOutOfBoundsException异常
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* Tells if the argument is the index of an existing element.
*/
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}调用node方法返回指定的元素。这里做了一点优化,如果index小于元素个数的一半,则从左到右查找,如果index大于元素个数的一半,则从右到左查找。
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}remove方法
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}看源码,remove方法移除的是第一个出现的元素。如果移除的元素存在,则返回true,否则返回false。移除的操作在unlink方法中。
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}这种删除链表元素的方法任何一本数据结构都差不多,不解释了。
Iterator及ListIterator接口分析
我们常见的容器都有iterator()方法,链表还有listIterator(),它们的继承关系如下:
由以上继承图可以看出,Iterator接口没有往回遍历的方法,而ListIterator扩充了往回遍历的方法。下面说下ListIterator和Iteraotr在LinkedList的实现。
listIterator方法
public ListIterator<E> listIterator() {
return listIterator(0);
}这方法定义在AbstractList中,返回listIteraotr(0)作为默认的iterator。
!!!注意:在LinkedList的listIterator()调用的listIterator(0)并不是AbstractList中的实现,而是通过继承在LinkedList中的实现.
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* Tells if the argument is the index of a valid position for an
* iterator or an add operation.
*/
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}先检查index的范围,注意,合法范围是[0,size] (为什么不是[0,size)呢?看下面分析!)。然后创建一个ListItr对象返回。ListItr是LinkedList的一个内部类,其定义如下:
private class ListItr implements ListIterator<E>
ListItr构造函数:
private Node<E> lastReturned = null;
private Node<E> next;
private int nextIndex;
private int expectedModCount = modCount;
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}构造函数是next和nextIndex的赋值,继续看下去,hasNext判断下个元素是否存在
public boolean hasNext() {
return nextIndex < size;
}继续看next方法
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}看到这里,结合hasNext和Next终于知道为什么isPositionIndex的范围检查是[0,size]而不是[0,size)了。index=size表示着已经到元素最后,没发读取下个元素了。继续看代码
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}每次都要判断lastReturned,而lastReturned只有在next和previous中会被赋值,因此,要删除元素,要先next()/previous(),然后才能remove。否则抛异常。
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}这个方法,目测是modCount的主要用途,是的!看这个demo
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<Integer>();
list.add(2);
ListIterator<Integer> iterator = list.listIterator();
while (iterator.hasNext()) {
list.add(33);
Integer integer = iterator.next();
}
}
}这个demo将会抛出ConcurrentModificationException异常。好吧,为什么要抛异常?好吧,这里作者不想我们在用迭代器的时候还通过容器实例操作容器(我yy的),谁知道会发生什么事情呢?
所以,在使用迭代器时,要我的经验是:不要在迭代器里面再通过该容器实例操作容器
到这里,Iterator/ListIterator方法告一段落
clone方法
/**
* Returns a shallow copy of this {@code LinkedList}. (The elements
* themselves are not cloned.)
*
* @return a shallow copy of this {@code LinkedList} instance
*/
public Object clone() {
LinkedList<E> clone = superClone();
// Put clone into "virgin" state
clone.first = clone.last = null;
clone.size = 0;
clone.modCount = 0;
// Initialize clone with our elements
for (Node<E> x = first; x != null; x = x.next)
clone.add(x.item);
return clone;
}
@SuppressWarnings("unchecked")
private LinkedList<E> superClone() {
try {
return (LinkedList<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}由注释知道了,这个clone方法是浅拷贝(shallow copy)。先通过superClone拷贝,然后将first,last,size,modCount都给初始化成默认状态,然后调用链表的add方法添加各个元素。
序列化,反序列化
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out size
s.writeInt(size);
// Write out all elements in the proper order.
for (Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item);
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in size
int size = s.readInt();
// Read in all elements in the proper order.
for (int i = 0; i < size; i++)
linkLast((E)s.readObject());
}LinkedList没有用默认的序列化,而是自己实现的自定义序列化反序列化方法。
注意:writeObject()与readObject()都是private方法,那么它们是如何被调用的呢?毫无疑问,是使用反射。
总结:
在写本文时,没有完全分析LinkedList的增删改,我觉得这部分都是上大学时数据结构学过的内容。相反,一些其他内容,比如clone深浅拷贝,序列化却是我们经常忽略的内容。还有iterator的用法,说真的,平时也不怎么用,有时在iterator上踩几个坑也是有可能的。

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树
- [原创]java局域网聊天系统