网络爬虫:爬取动态网页(例如javascript)
2015-12-14 20:22
615 查看
经过一段时间的摸索,终于有了一套爬取动态网页的方法,此方法适合大多数的动态网页爬取,至于另外少数的动态网页爬取,还必须利用其它的办法。在此分享给大家。
举例:例如在百度中搜索成语词典,显示如下,需要爬取所有的成语词汇。我们可以点击下一页查看,有经验的同学一眼就可以看出这里是使用javascript异步加载的。在网页源码上是找不到的。下面就介绍爬取所有词典的方法
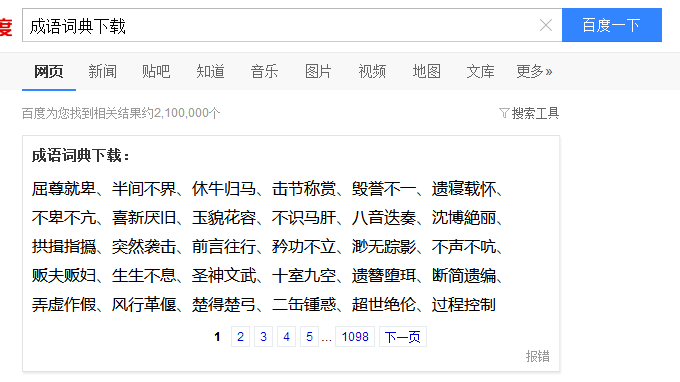
1.点击鼠标右键–>审查元素
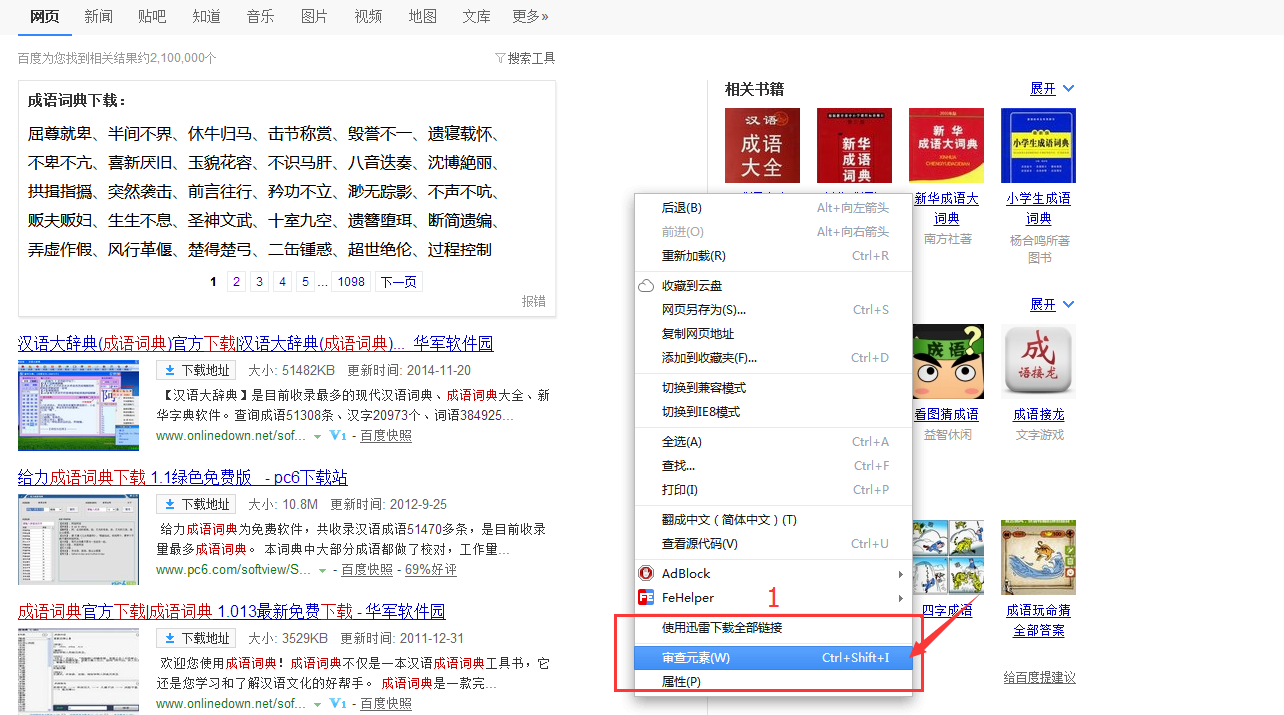
2.选择Network按钮
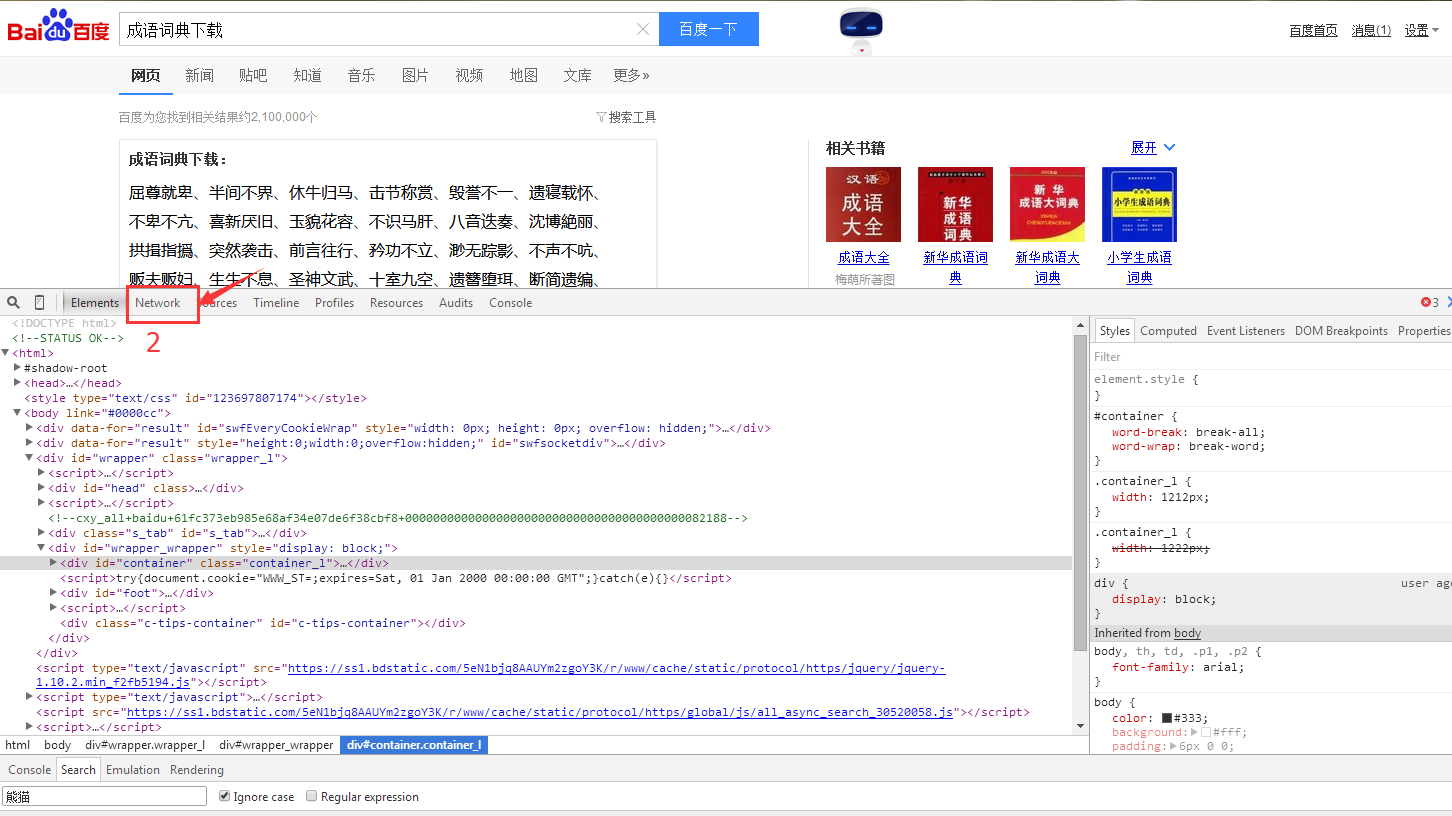
3.选择下一页按钮 得到的效果是如下图,我们可以发现出现两个网址,
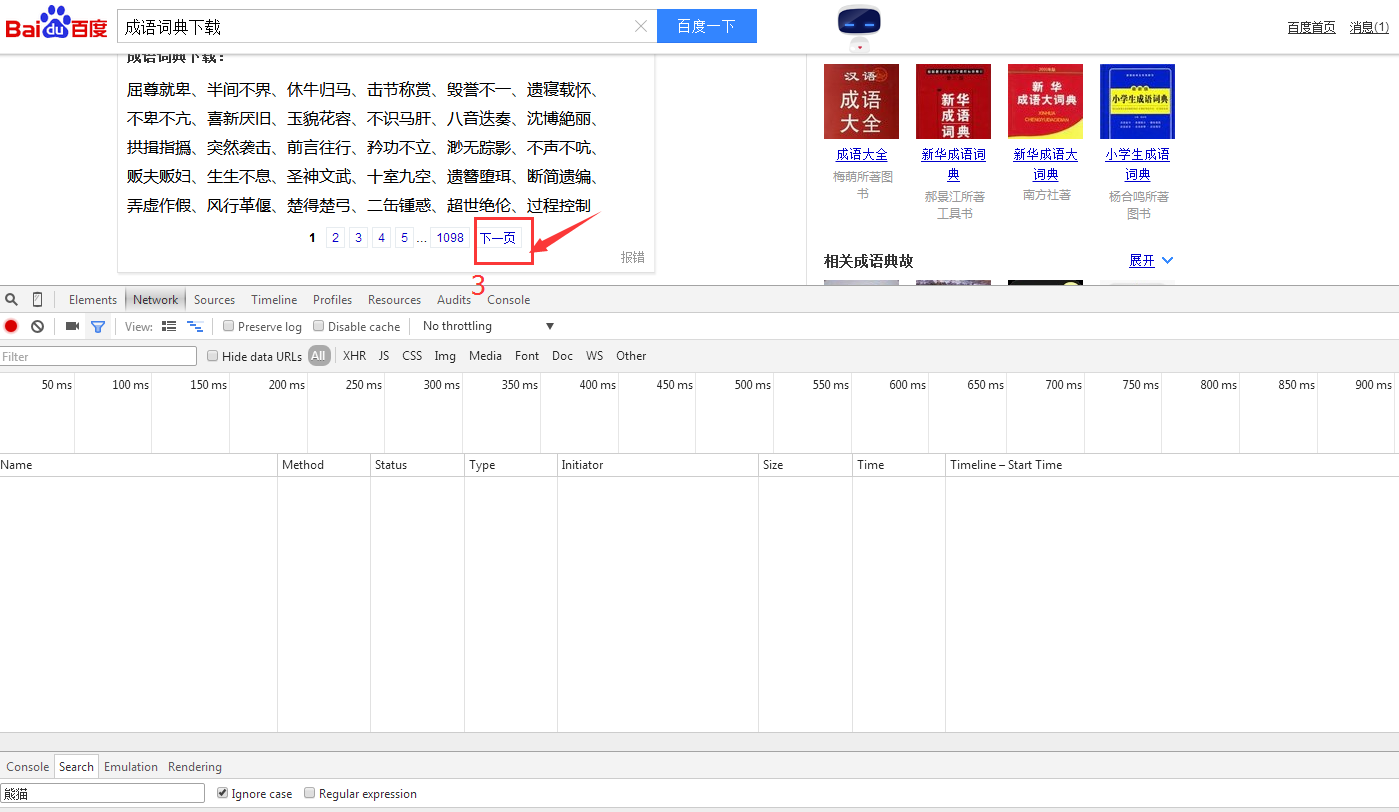
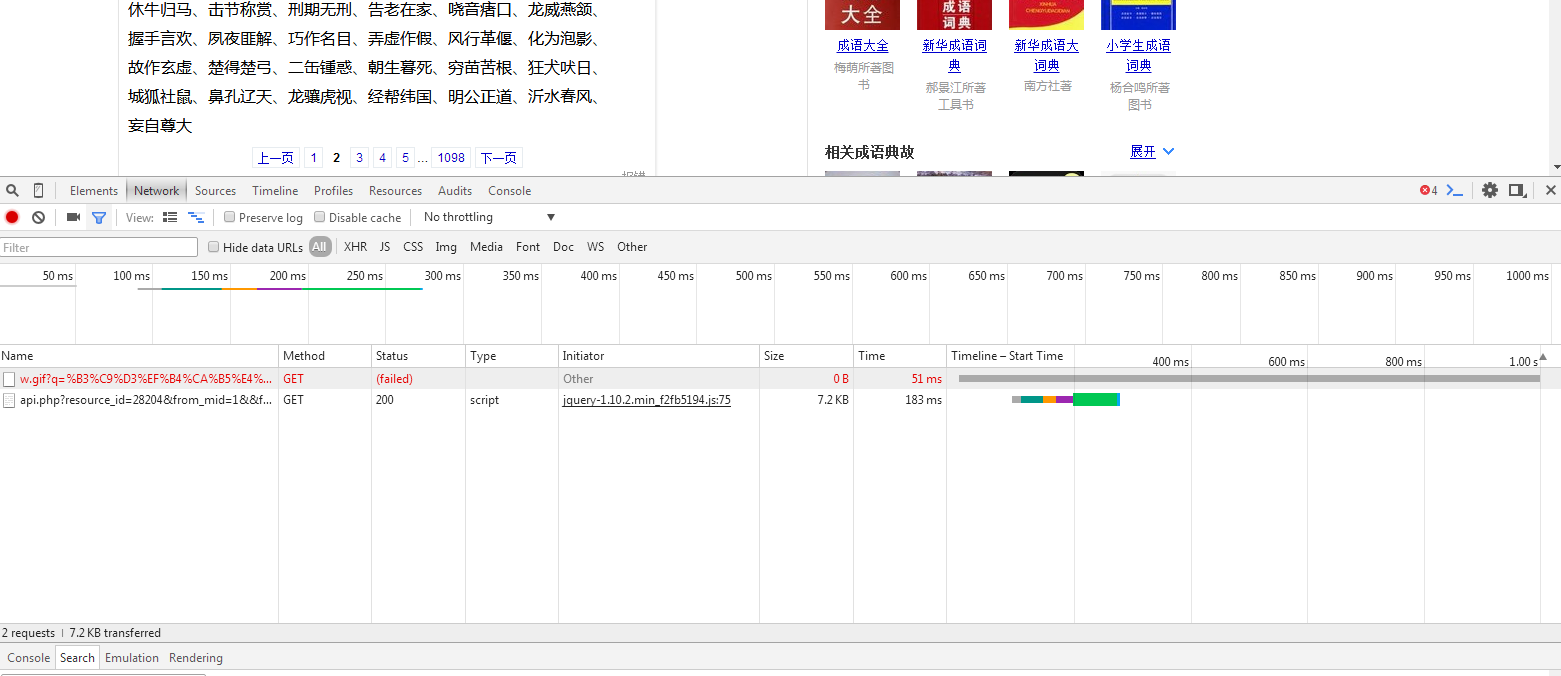
为了清楚显示我们想要的东西,我们选择js按钮
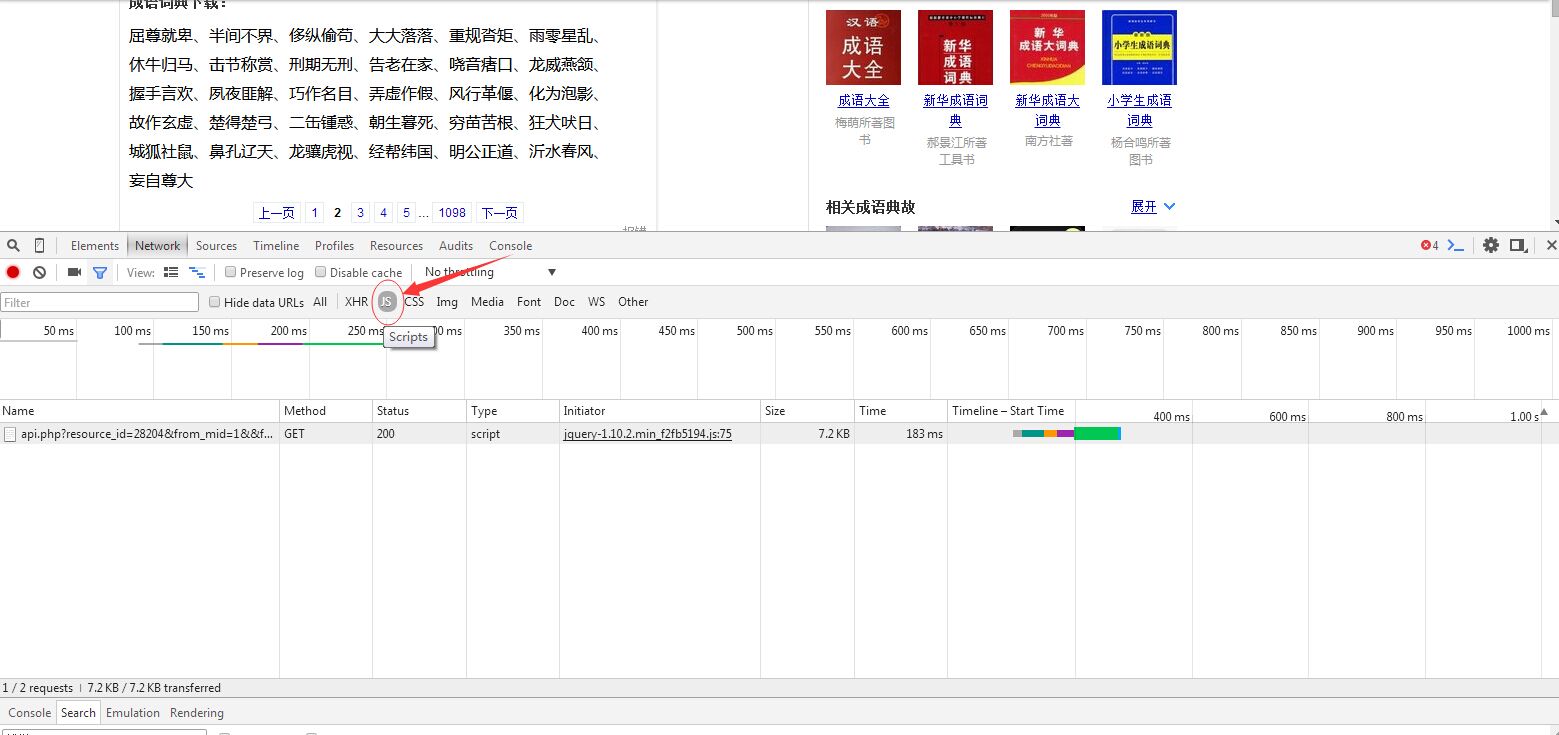
4.将鼠标放在网址那,点击右键选择open link in new tab

5.以上四部便可以得到大致是一个json格式的内容,做到这一步,算是完成了一大部分的工作,由于为了方便解析内容,需要将网站稍作修改,这一步大家需要去尝试在此我将这部分(&cb=jQuery1102011321965302340686_1450094493974)去掉后,内容变成纯的json格式文档。接下来的和爬取静态网页的方法一样了
6. 第五步可以得到这样的网址:=1450094493985”>https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28204&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E6%88%90%E8%AF%AD%E8%AF%8D%E5%85%B8%E4%B8%8B%E8%BD%BD&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn=30&rn=30&=1450094493985,pn=30,表示每页显示30个,我们需要改变pn的值来爬取所有的成语,具体操作是pn+=30。
所有的步骤说完了,接下来上代码:
大功告成,大家有问题请留言!!!
举例:例如在百度中搜索成语词典,显示如下,需要爬取所有的成语词汇。我们可以点击下一页查看,有经验的同学一眼就可以看出这里是使用javascript异步加载的。在网页源码上是找不到的。下面就介绍爬取所有词典的方法
1.点击鼠标右键–>审查元素
2.选择Network按钮
3.选择下一页按钮 得到的效果是如下图,我们可以发现出现两个网址,
为了清楚显示我们想要的东西,我们选择js按钮
4.将鼠标放在网址那,点击右键选择open link in new tab
5.以上四部便可以得到大致是一个json格式的内容,做到这一步,算是完成了一大部分的工作,由于为了方便解析内容,需要将网站稍作修改,这一步大家需要去尝试在此我将这部分(&cb=jQuery1102011321965302340686_1450094493974)去掉后,内容变成纯的json格式文档。接下来的和爬取静态网页的方法一样了
6. 第五步可以得到这样的网址:=1450094493985”>https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28204&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E6%88%90%E8%AF%AD%E8%AF%8D%E5%85%B8%E4%B8%8B%E8%BD%BD&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn=30&rn=30&=1450094493985,pn=30,表示每页显示30个,我们需要改变pn的值来爬取所有的成语,具体操作是pn+=30。
所有的步骤说完了,接下来上代码:
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.UnsupportedEncodingException;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import org.json.JSONArray;
import org.json.JSONObject;
public class BaiduIdiomCrawer {
public static void main(String[] args) {
//BaiduIdiomCrawer test=new BaiduIdiomCrawer();
new BaiduIdiomCrawer().test01();
}
public void test01() {
//String myurl = "https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=6848&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E6%88%90%E8%AF%AD&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn=30&rn=30&cb=jQuery110206992364453617483_1449371069677&_=1449371069681";
//String myurl="https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=6848&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E6%88%90%E8%AF%AD&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn=30&rn=30&_=1449371069681";
String myurl;
String content = new String();
StringBuffer sb = new StringBuffer();
try {
String url2="https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id="
+ "28204&from_mid=1&&format=json&ie=utf-8&oe=utf-8&"
+ "query=%E6%88%90%E8%AF%AD%E8%AF%8D%E5%85%B8%E4%B8%8B%E8%BD%BD&sort_key=&"
+ "sort_type=1&stat0=&stat1=&stat2=&stat3=&pn=";
String url1="&rn=30&_=1449376371822";
//String url2="https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=6848&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E6%88%90%E8%AF%AD&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn=";
//String url1="&rn=30&_=1449371069681";
for (int j = 0; j < 1098; j++) {
myurl = url2 + j * 30 + url1;
System.out.println(j);
//content=this.downloadToString(myurl, "utf-8");
content=this.downloadToString(myurl);
JSONObject jo = new JSONObject(content.toString());
JSONArray jsonarray = jo.getJSONArray("data");
if(j==690){
System.out.println(j);
}
JSONObject jo1 = jsonarray.getJSONObject(0);
JSONArray jsonarray1 = jo1.getJSONArray("result");
for (int i = 0; i < jsonarray1.length(); i++) {
JSONObject user = (JSONObject) jsonarray1.get(i);
String userName = (String) user.get("ename");
//System.out.println(userName);
sb.append(userName + "\n");
}
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
PrintStream ps=new PrintStream(new File("result.txt"),"utf-8");
ps.print(sb.toString());
ps.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(sb.toString());
}
public String downloadToString(String url, String charset) throws Exception {
ByteArrayOutputStream output = new ByteArrayOutputStream();
try {
HttpURLConnection http = (HttpURLConnection) (new URL(url)).openConnection();
http.setReadTimeout(5 * 60 * 1000);
//http.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)");
http.setRequestProperty("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.1.141.64 Safari/537.31");
http.setRequestMethod("GET");
http.setUseCaches(false);
InputStream input = http.getInputStream();
int ch = -1;
while((ch = input.read()) != -1)
output.write(ch);
input.close();
} catch(Exception ex) {
ex.printStackTrace(System.out);
}
return output.toString(charset);
}
public String downloadToString(String u){
StringBuffer sb = new StringBuffer();
try {
URL url = new URL(u);
URLConnection connection = url.openConnection();
InputStream is = connection.getInputStream();
InputStreamReader isr = new InputStreamReader(is,"UTF-8");
BufferedReader br = new BufferedReader(isr);
String line;
while((line=br.readLine())!=null){
sb.append(line);
}
br.close();
isr.close();
is.close();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return sb.toString();
}
}大功告成,大家有问题请留言!!!

相关文章推荐
- JQuery1——基础($对象,选择器,对象转换)
- Android学习笔记(二九):嵌入浏览器
- Android java 与 javascript互访(相互调用)的方法例子
- JavaScript演示排序算法
- javascript实现10进制转为N进制数
- 房产界已上市和IPO路上的难兄难弟:房天下与房多多
- 利用百度地图提供的API做的应用
- 搜狗百度360市值齐跌:搜索引擎们陷入集体焦虑?
- 百度20年:搜索帝国的崛起、式微与重生
- 小白观察:Google 开始清除百度旗下公司开发的 46 款应用程序
- 我投了份简历,接到了十八个骚扰电话
- 2019年开发人员应该学习的8个JavaScript框架
- HTML中的script标签研究
- 对一个分号引发的错误研究
- 异步流程控制:7 行代码学会 co 模块
- ES6 走马观花(ECMAScript2015 新特性)
- JavaScript拆分字符串时产生空字符的原因
- Canvas 在高清屏下绘制图片变模糊的解决方法