【算法拾遗(java描述)】--- 排序算法概述
2015-12-13 16:07
351 查看
概念
假设含有n个记录的序列为{r1,r2,……,rn},需要确定1,2,……,n的一种排列p1,p2,……,pn,使其相应的关键字满足kp1<=kp2<=……<=kpns非递减(或非递增)关系,即使得序列成为一个按关键字有序的序列{rp1,rp2,……,rpn},这样的操作就称为排序。这个定义说的很清楚,所谓排序就是对关键字的操作,对于同一个记录集合而言,可能会存在很多关键字,可能会存在主关键字和次关键字之分。那么对同一个记录集合,针对不同的关键字进行排列,可以得到不同序列。
分类
稳定排序与非稳定排序
由于排序不仅是针对主关键字,对于次关键字,因为待排序的记录序列中可能存在两个或两个以上的关键字相等的记录,排序结果可能会存在不唯一的情况,所以排序又有稳定排序与非稳定排序之分。假设ki = kj(1<=i<=n,1<=j<=n,i!=j),且在排序前的序列中ri领先于rj(即i
内排序与外排序
根据在排序过程中待排序的记录是否全部被放置在内存中,排序分为:内排序和外排序。内排序:是指在排序整个过程中,待排序的所有记录全部被放置在内存中。主要分为:
交换排序
插入排序
选择排序
归并排序
分配排序
外排序:是指由于排序的记录个数太多,不能同时放置在内存,整个排序过程需要在内外村之间多次交换数据才能进行。主要分为:
合并排序
直接合并排序
本篇博客只讨论内排序的几种算法。
排序算法性能分析
比较两个排序算法,不能直接通过它们的运行时间进行比较,因为有些算法的运行时间依赖于原始输入记录的情况,特别是记录的数量、记录的大小、关键字的可操作区域以及输入记录的原始有序程度等,这些都会大大影响到排序算法的相对运行时间。因此,这种比较方法也就失去了意义。分析排序算法,应该考虑的是比较的次数和数据移动的次数。
有时并不能确定比较的准确次数,因此只能计算一个近似值。比较和移动的次数都用大O表示法,通过给定这些数的数量级来近似。
比较次数的数量级因数据的初始顺序的不同而不同,因此,我们需要计算一下三种情况下的比较和移动次数:
最好情况(即数据已经排好序)
最坏情况(数据反序存放)
平均情况(数据随机顺序存放)
注意:每一种排序方法基本上都有简单算法与改进算法之分,通常改进算法的复杂度更高,效率也会更高。
具体方法
本篇博客只写出算法的名称,具体思想和代码描述将在后序博文中讲解。交换排序
冒泡排序法
快速排序法
插入排序
直接插入排序
希尔排序
选择排序
直接选择排序
堆排序
归并排序
外部排序
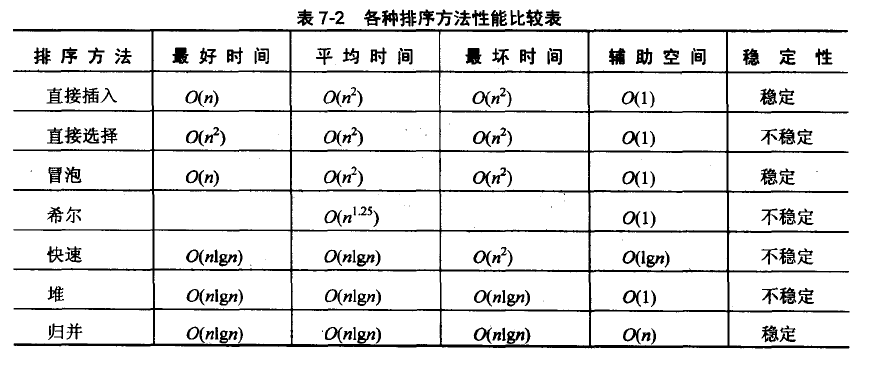
参考资料:《大话数据结构》、《数据结构与算法分析——java语言描述》

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- JavaScript演示排序算法
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树