04 Python正则表达式 爬虫程序 变量的引用,浅拷贝,深拷贝 多线程 进程锁 数据库模块
2015-12-13 16:01
821 查看
python正则表达式
简单的爬虫程序
变量的引用,浅拷贝,深拷贝
多线程
进程锁
Python数据库模块安装及使用;
python正则表达式


导入re模块
同时匹配多个tip top

解决元字符在字符集中不起作用
例如
解决办法
重复出现的次数匹配
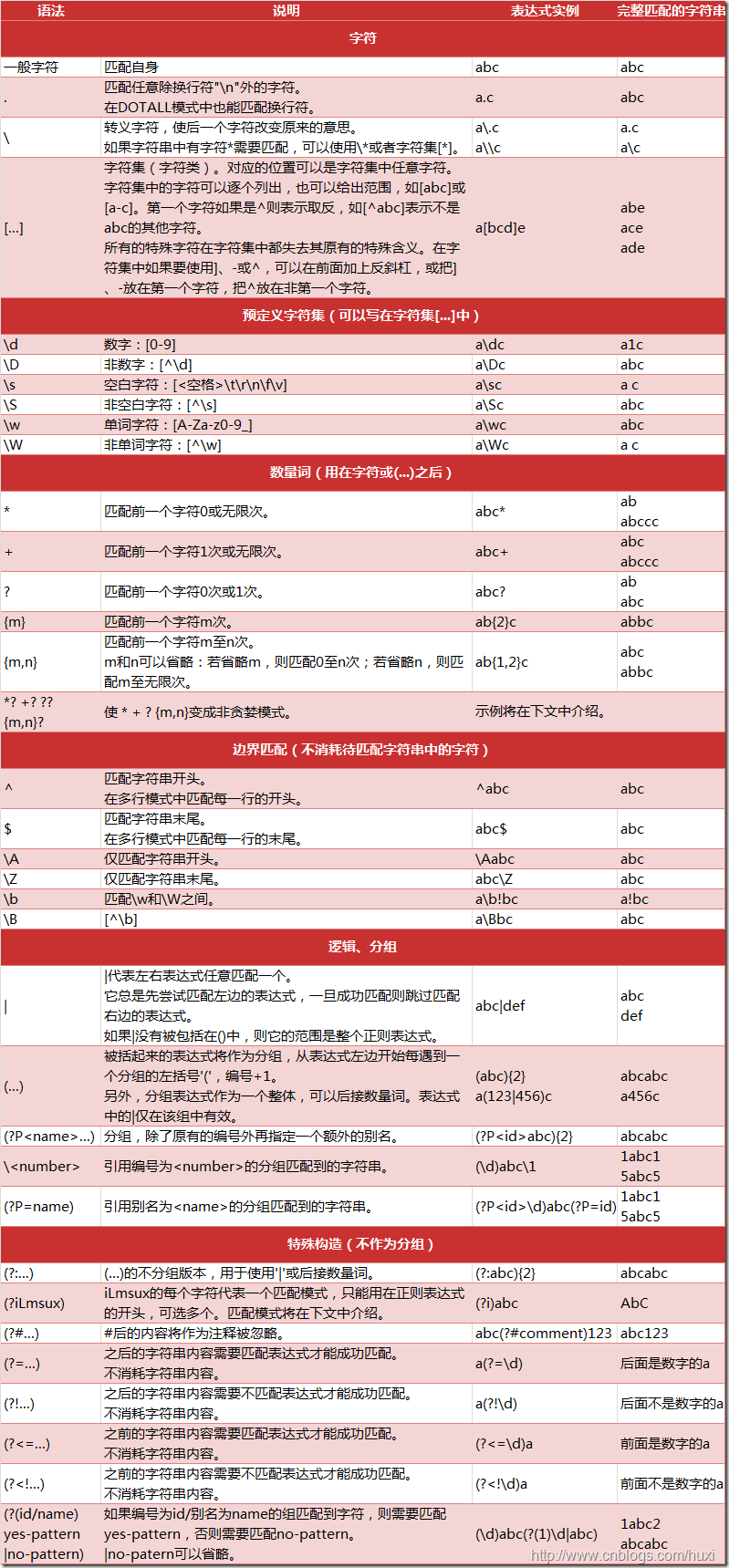
重复出现匹配任意次*
至少出现一次的匹配+ r1=r"ab+"
可有可无的匹配 ? r2=r"ab?"
最小匹配模式 +? r2=r"ab+?"
指定匹配次数
匹配电话号码
先编译在匹配,这样会快很多
匹配任意大小写 re.I

match只能匹配在前面
search 在前面 中间 后面 都有可以匹配的到


点能匹配任意的一个字符 .
不加re.S转义字符记忆匹配不出来,加上就可以了
匹配以\n转义字符为换行的文本
正则表达式 【分组】
优先返回分组的信息
爬虫的匹配
【一个小爬虫】
展示效果
变量的引用,浅拷贝,深拷贝
变量的引用
浅拷贝,父对象不会变,子对象随着变
子对象随着变
深拷贝
多线程
查进程ps -aux
进程锁
Python数据库模块安装及使用;

简单的爬虫程序
变量的引用,浅拷贝,深拷贝
多线程
进程锁
Python数据库模块安装及使用;
python正则表达式
导入re模块
import re In [40]: s=r"abc" 定义一个 In [42]:re.findall(s,"abcfdf") 在 "abcfdf" 里面查找abc Out[42]: ['abc']
同时匹配多个tip top
In [43]: s=r't[io]p' In [44]: a='tip top hahanihao' In [45]: re.findall(s,a) Out[45]: ['tip', 'top']
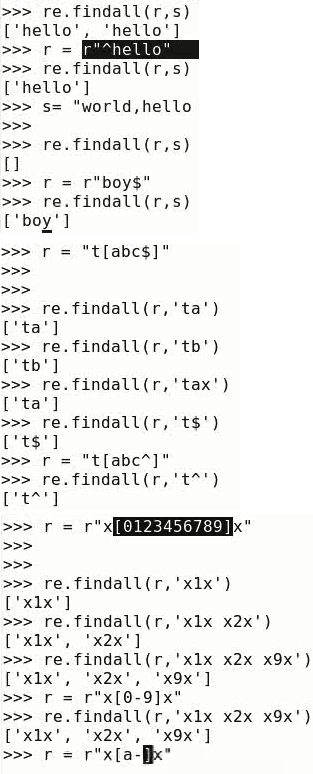
解决元字符在字符集中不起作用
例如
In [66]: r1=r'abc' In [67]:re.findall(r1,'d^abcf') Out[67]: ['abc'] In [68]: r1=r'^abc' In [69]:re.findall(r1,'d^abcf') Out[69]: []
解决办法
In [70]: r1=r'\^abc' In [71]:re.findall(r1,'d^abcf') Out[71]: ['^abc']
重复出现的次数匹配
In [72]: r2=r'010-\d\d\d\d'
In [73]: s2='010-123'
In [74]: re.findall(r2,s2)
Out[74]: [] 前面少一个 后面就匹配不到
In [75]: s2='010-1236'
In [76]: re.findall(r2,s2)
Out[76]: ['010-1236']
In [77]: r2=r'010-\d{4}' 重复出现的次数描述
In [78]: re.findall(r2,s2)
Out[78]: ['010-1236']重复出现匹配任意次*
In [79]: r2=r'010-\d*' In [81]: s2='010-12365345234' In [82]: re.findall(r2,s2) Out[82]: ['010-12365345234'] In [83]: r2=r'010-abc*'重复出现c,没有c也可以 In [84]: s2='010-abcc' In [85]: re.findall(r2,s2) Out[85]: ['010-abcc'] In [86]: s2='010-abcc23' In [87]: re.findall(r2,s2) Out[87]: ['010-abcc']
至少出现一次的匹配+ r1=r"ab+"
可有可无的匹配 ? r2=r"ab?"
最小匹配模式 +? r2=r"ab+?"
指定匹配次数
In [91]:r2=r"ab{8}" 只是匹配到有8次的
In [92]:r2=r"ab{2,9}" 匹配2到9次的
{0,}等同于*
{1,}等同于+
{0,1} 等同于?
{0,2}匹配电话号码
In [94]:re.findall(r4,"0376-12345678") Out[94]: ['0376-12345678'] In [95]:re.findall(r4,"037612345678") Out[95]: ['037612345678']
先编译在匹配,这样会快很多
In [93]:r4=r"\d{3,4}-?\d{8}"
In [96]: p_tel=re.compile(r4) 任何表达式都可以
In [98]: p_tel.findall('037612345678') 再来匹配
Out[98]: ['037612345678']匹配任意大小写 re.I
In [99]:r5=re.compile(r'welcome',re.I)
In [100]:r5.findall("WeLcoMe")
Out[100]: ['WeLcoMe']match只能匹配在前面
In [105]:r5=re.compile(r'welcome',re.I)
In [106]: r5.match('welcomehaha')
Out[106]: <_sre.SRE_Matchat 0x7f7a67b2e5e0> welcome在前面可以匹配到
In [107]: r5.match('hahwelcome haha') 不在前面就匹配不到search 在前面 中间 后面 都有可以匹配的到
In [108]: r5.search('hahwelcome haha')
Out[108]: <_sre.SRE_Matchat 0x7f7a67b2e648>
In [109]: r5.search('welcomehaha')
Out[109]: <_sre.SRE_Matchat 0x7f7a67b2e440>
In [110]: r5.search('hahwelcome')
Out[110]: <_sre.SRE_Matchat 0x7f7a67b2e6b0>点能匹配任意的一个字符 .
In [1]: import re In [2]: r1=r'qwe.com' In [3]:re.findall(r1,"qwe.com") Out[3]: ['qwe.com'] In [4]:re.findall(r1,"qwe5com") Out[4]: ['qwe5com']
不加re.S转义字符记忆匹配不出来,加上就可以了
In [6]:re.findall(r1,"qwe\ncom") Out[6]: [] In [7]:re.findall(r1,"qwe\ncom",re.S) Out[7]: ['qwe\ncom']
匹配以\n转义字符为换行的文本
In [8]: s=''' 定义s
...: hello
...: haha
...: nihao
...: haha123
...: welcome
...: '''
s的储存方式
In [12]: s
Out[12]:'\nhello\nhaha\nnihao\nhaha123\nwelcome\n'
In [9]: r=r'^haha'
In [10]: re.findall(r,s) 默认匹配不出来
Out[10]: []
In [11]: re.findall(r,s,re.M) 这样就可以了
Out[11]: ['haha', 'haha']
当正则表达式是r2的这样的时候,默认匹配不到
In [13]: r2='''
....: \d{3,4}
....: -?
....: \d{8}
....: '''
n [16]: r2 r2的实际存储
Out[16]:'\n\\d{3,4}\n-?\n\\d{8}\n'
In [14]:
In [14]:re.findall(r2,"010-12345678") 默认匹配不到
Out[14]: []
In [15]: re.findall(r2,"010-12345678",re.X) re.X 就好了
Out[15]: ['010-12345678']正则表达式 【分组】
优先返回分组的信息
In [17]:email=r'\w{3}@\w+(\.com|\.cn)'
In [18]:re.findall(email,"hhh@hello.com")
Out[18]: ['.com']爬虫的匹配
In [29]: s=''' 定义字符串 ....: fdsf hello scr=csvt yes jdskd ....: mjhsjk src=123 yes jdsa ....: nscr=234 yes ....: nhello scr=python yes ksa ....: ''' In [31]: print s 先来看一看 fdsf hello scr=csvt yes jdskd mjhsjk src=123 yes jdsa nscr=234 yes nhello scr=python yes ksa In [24]: r1=r"helloscr=.+ yes" 定义正则表达式 In [32]: re.findall(r1,s) 匹配效果 Out[32]: ['hello scr=csvtyes', 'hello scr=python yes']
【一个小爬虫】
展示效果
vim img.py 我的小爬虫
#!/usr/local/python27
import re
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return(html)
def getImg(html):
reg = r'src="(.*?\.jpg)" pic' 这个pic困惑我好久
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x=0
for imgurl in imglist:
urllib.urlretrieve (imgurl,'%s.jpg' %x)
x+=1
html = getHtml("http://tieba.baidu.com/p/3054941358?pid=50862060666#50862060666")
getImg(html)
#print html变量的引用,浅拷贝,深拷贝
变量的引用
In [1]:a=[1,2,3,['a','b'],'hello'] In [2]: b=a In [3]: id(a) Out[3]: 140690669992272 In [4]: id(b) Out[4]: 140690669992272
浅拷贝,父对象不会变,子对象随着变
In [5]: import copy In [6]: c=copy.copy(a) In [7]: id(c) Out[7]: 140690670078720
子对象随着变
In [9]: a[3].append('c')
In [10]: a
Out[10]: [1, 2, 3, ['a', 'b','c'], 'hello']
In [11]: c
Out[11]: [1, 2, 3, ['a', 'b','c'], 'hello']深拷贝
In [12]: d=copy.deepcopy(a)
In [13]: id(a)
Out[13]: 140690669992272
In [14]: id(d)
Out[14]: 140690670200736 不一样
In [15]: a[3].append('f')
In [16]: a
Out[16]: [1, 2, 3, ['a', 'b','c', 'f'], 'hello'] 不一样
In [17]: d
Out[17]: [1, 2, 3, ['a', 'b','c'], 'hello']
In [22]: id(a[3])
Out[22]: 140690669992416 不一样
In [23]: id(d[3])
Out[23]: 140690672885704多线程
查进程ps -aux
In [27]: import time In [28]: for i in range(5): print i time.sleep(1) ....: 0 1 2 3 4 #!/usr/local/python27 import time import thread def t(x,y): for i in range(y): print x,i,"\n" time.sleep(1) thread.start_new_thread(t,(990487026,10)) thread.start_new_thread(t,(123456789,10)) time.sleep(10) 要大于线程生命周期 [root@localhost python]#python27 thred.py 123456789 0 990487026 0 123456789 1 990487026 1 123456789 2 990487026 2 990487026 3
进程锁
#!/usr/local/python27 import time import thread def t(x,y,l): for i in range(y): print x,i,"\n" time.sleep(1) l.release() 执行完毕,释放锁 lock = thread.allocate_lock()生成一个锁 lock.acquire() 把锁锁上 thread.start_new_thread(t,(990487026,10,lock)) 把锁传进去 while lock.locked(): 直到锁释放才结束进程 pass
Python数据库模块安装及使用;
yum install MySQL-python
yum install python-devel
yum install mysql-server
yum install python-setuptools
>>> import MySQLdb 载入模块
service mysqld start 启动
>>> conn = MySQLdb.connect(user='root',passwd='',host='127.0.0.1')保存连接状态
>>> conn =MySQLdb.connect() 或者是这个,默认mysql
>>> cur =conn.cursor() 用conn对象保存游标
>>>conn.select_db('test') 选择默认的user这个库
相关文章推荐
- Python动态类型的学习---引用的理解
- 简单谈谈C#中深拷贝、浅拷贝
- 浅拷贝和深拷贝深入理解(shallow copy VS deep copy)
- C#浅拷贝和深拷贝实例解析
- Javascript 浅拷贝、深拷贝的实现代码
- C++拷贝构造函数(深拷贝与浅拷贝)详解
- 浅谈.net平台下深拷贝和浅拷贝
- JavaScript数组深拷贝和浅拷贝的两种方法
- Java中的深拷贝(深复制)和浅拷贝(浅复制)介绍
- Python中的赋值、浅拷贝、深拷贝介绍
- Python对象的深拷贝和浅拷贝详解
- Python中的深拷贝和浅拷贝详解
- Python浅拷贝与深拷贝用法实例
- js中深、浅copy之我见
- python学习之拷贝
- python 浅拷贝和深拷贝
- ShallowCopy与DeepCopy
- 【Java核心技术——对象克隆】
- JavaScript 继承
- python 可变对象与不可变对象