What are TCHAR, WCHAR, LPSTR, LPWSTR, LPCTSTR (etc.)?
2015-12-04 10:51
736 查看
Many C++ Windows programmers get confused over what bizarre identifiers like
In this article, I would attempt by best to clear out the fog.
In general, a character can be represented in 1 byte or 2 bytes. Let's say 1-byte character is ANSI character - all English characters are represented through this encoding. And let's say a 2-byte character
is Unicode, which can represent ALL languages in the world.
The Visual C++ compiler supports
native data-types for ANSI and Unicode characters, respectively. Though there is more concrete definition of Unicode, but for understanding assume it as two-byte character which Windows OS uses for multiple
language support.
There is more to Unicode than 2-bytes character representation Windows uses. Microsoft Windows use UTF-16 character encoding.
What if you want your C/C++ code to be independent of character encoding/mode used?
Suggestion: Use generic data-types and names to represent characters and string.
For example, instead of replacing:
Hide Copy Code
with
Hide Copy Code
In order to support multi-lingual (i.e., Unicode) in your language, you can simply code it in more generic manner:
Hide Copy Code
The following project setting in General page describes which Character Set is to be used for compilation: (General -> Character Set)
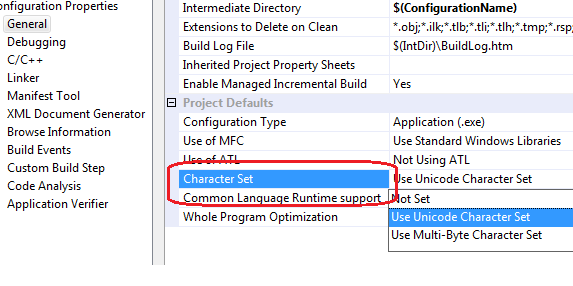
This way, when your project is being compiled as Unicode, the
If it is being compiled as ANSI/MBCS, it would be translated to
and project settings will not affect any direct use of these keywords.
defined as:
Hide Copy Code
The macro
Unicode Character Set", and therefore
When Character Set if set to "Use Multi-Byte Character Set", TCHAR would mean
Likewise, to support multiple character-set using single code base, and possibly supporting multi-language, use specific functions (macros). Instead of using
the secure versions suffixed with_s); or
secure), you should better use use
As you know
Hide Copy Code
And,
Hide Copy Code
You may better use
as:
Hide Copy Code
WC is for Wide Character. Therefore,
This way,
logically.
But, in reality,
are actually not functions, but macros. They are defined simply as:
Hide Copy Code
You should refer
like this.
You might ask why they are defined as macros, and not implemented as functions instead? The reason is simple: A library or DLL may export a single function, with same name and prototype (Ignore overloading concept of C++). For instance, when you export a function
as:
Hide Copy Code
How the client is supposed to call it as?
Hide Copy Code
Hide Copy Code
And a simple
1aa70
macro, as defined below, would hide the difference:
Hide Copy Code
The client would simply call it as:
Hide Copy Code
Note that both
map to either Unicode or ANSI, and therefore
argument to function would be either
Macros do avoid these complications, and allows us to use either ANSI or Unicode function for characters and strings. Most of the Windows functions, that take string or a character are implemented this way, and for programmers convenience, only one function
(a macro!) is good.
Hide Copy Code
There are very few functions that do not have macros, and are available only with suffixed W or A. One example is
which doesn't have ANSI equivalent.
You all know that we use double quotation marks to represent strings. The string represented in this manner is ANSI-string, having 1-byte each character. Example:
Hide Copy Code
The string text given above is not Unicode, and would be quantifiable for multi-language support. To represent Unicode string, you need to use prefix
An example:
Hide Copy Code
Note the L at the beginning of string, which makes it a Unicode string. All characters (I repeat all characters) would take two bytes, including
all English letters, spaces, digits, and the null character. Therefore, length of Unicode string would always be in multiple of 2-bytes. A Unicode string of length 7 characters would need 14 bytes, and so on. Unicode string taking 15 bytes, for example, would
not be valid in any context.
In general, string would be in multiple of
When you need to express hard-coded string, you can use:
Hide Copy Code
The non-prefixed string is ANSI string, the L prefixed string is Unicode, and string specified in
be either, depending on compilation. Again,
nothing but macros, and are defined as:
Hide Copy Code
The
pasting operator, which would turn
where the string passed is argument to macro - If
not defined,
The token pasting operator did exist even in C language, and is not specific about VC++ or character encoding.
Note that these macros can be used for strings as well as characters.
simple
No, you cannot use these macros to convert variables (string or character) into Unicode/non-Unicode text. Following is not valid:
Hide Copy Code
The bold lines would get successfully compiled in ANSI (Multi-Byte) build, since
and therefore
come out to be
respectively. But, when you build it with Unicode character set, it would fail to compile:
Hide Copy Code
I would not like to insult your intelligence by describing why and what those errors are.
There exist set of conversion routine to convert MBCS to Unicode and vice versa, which I would explain soon.
It is important to note that almost all functions that take string (or character), primarily in Windows API, would have generalized prototype in MSDN and elsewhere. The function
for instance, be classified as:
Hide Copy Code
But, as you know,
Hide Copy Code
Therefore, don't be puzzled if following call fails to get address of this function!
Hide Copy Code
From
exported, not the function with generalized name.
Interestingly, .NET Framework is smart enough to locate function from DLL with generalized name:
Hide Copy Code
No rocket science, just bunch of ifs and else around
All of the functions that have ANSI and Unicode versions, would have actual implementation only in Unicode version. That means, when you call
your code, passing an ANSI string - it would convert the ANSI string to Unicode text and then would call
The actual work (setting the window text/title/caption) will be performed by Unicode version only!
Take another example, which would retrieve the window text, using
passing ANSI buffer as target buffer.
probably allocating a Unicode string (a
into ANSI string.
This ANSI to Unicode and vice-versa conversion is not limited to GUI functions, but entire set of Windows API, which do take strings and have two variants. Few examples could be:
etc
It is therefore very much recommended to call the Unicode version directly. In turn, it means you should alwaystarget for Unicode builds, and not ANSI builds - just because you are accustomed to using
ANSI string for years. Yes, you may save and retrieve ANSI strings, for example in file, or send as chat message in your messenger application. The conversion routines do exist for such needs.
Note: There exists another typedef:
to
The
What if you would like to express a character-pointer, or a const-character-pointer - Which one of the following?
Hide Copy Code
After reading about
available to represent strings. For that, you just need to include Windows.h. Note: If
your project implicitly or explicitly includes Windows.h, you need not include
First, revisit old string functions for better understanding. You know
Hide Copy Code
Which may be represented as:
Hide Copy Code
Where symbol
as:
Hide Copy Code
The meaning goes like:
LP - Long Pointer
C - Constant
STR - String
Essentially,
Let's represent
Hide Copy Code
The type of szTarget is
without C in the type-name. It is defined as:
Hide Copy Code
Note that the szSource is
will not modify the source buffer, hence the
Alright, these
the same, the equivalent wide-character str-functions are provided. For example, to calculate length of wide-character (Unicode string), you would use
Hide Copy Code
The prototype of
Hide Copy Code
And that can be represented as:
Hide Copy Code
Where the symbol
Hide Copy Code
Which can be broken down as:
LP - Pointer
C - Constant
WSTR - Wide character String
Similarly,
for Unicode strings:
Hide Copy Code
Which can be represented as:
Hide Copy Code
Where the target is non-constant wide-string (
There exist set of equivalent
The
would be used for Unicode strings.
Though, I already advised to use Unicode native functions, instead of ANSI-only or TCHAR-synthesized functions. The reason was simple - your application must only be Unicode, and you should not even
care about code portability for ANSI builds. But for the sake of completeness, I am mentioning these generic mappings.
To calculate length of string, you may use
(a macro). In general, it is prototyped as:
Hide Copy Code
Or, as:
Hide Copy Code
Where the type-name
LP - Pointer
C - Constant
T = TCHAR
STR = String
Depending on the project settings,
to either
Note:
return number of characters in string, not the number of bytes.
The generalized string-copy routine
Hide Copy Code
Or, in more generalized form, as:
Hide Copy Code
You can deduce the meaning of
Usage Examples
First, a broken code:
Hide Copy Code
On ANSI build, this code will successfully compile since
and hence name would be an array of
would also work flawlessly.
Alright. Let's compile the same with with
(i.e. "Use Unicode Character Set" in project settings). Now, the compiler would report set of errors:
error C2440: 'initializing' : cannot convert from 'const char [7]' to 'TCHAR []'
error C2664: 'strlen' : cannot convert parameter 1 from 'TCHAR []' to 'const char *'
And the programmers would start committing mistakes by correcting it this way (first error):
Hide Copy Code
Which will not pacify the compiler, since the conversion is not possible from
The same error would also come when native ANSI string is passed to a Unicode function:
Hide Copy Code
Unfortunately (or fortunately), this error can be incorrectly corrected by simple C-style typecast:
Hide Copy Code
And you'd think you've attained one more experience level in pointers! You are wrong - the code would give incorrect result, and in most cases would simply cause Access Violation. Typecasting this way is like passing a
where a structure of 80 bytes is expected (logically).
The string
sequence of 7 bytes:
But when you pass same set of bytes to
[97, 83] would be treated as one character having value: 24915 (
And the next character is represented by [117, 116] and so on.
For sure, you didn't pass those set of Chinese characters, but improper typecasting has done it! Therefore it is very essential to know that type-casting will not work! So, for the first line of initialization,
you must do:
Hide Copy Code
Which would translate to 7-bytes or 14-bytes, depending on compilation. The call to
Hide Copy Code
In the sample program code given above, I used
solution is C-sytle typecast:
Hide Copy Code
On Unicode build, name would be of 14-bytes (7 Unicode characters, including null). Since string "Saturn"contains only English letters, which can be represented using original ASCII, the Unicode letter
be represented as [83, 0]. Other ASCII characters would be represented with a zero next to them. Note that
now represented as 2-byte value
be represented by two bytes having value
So, when you pass such string to
case of "Saturn"). But the second character/byte would indicate end of string. Therefore,
value
As you know, Unicode string may contain non-English characters, the result of strlen would be more undefined.
In short, typecasting will not work. You either need to represent strings in correct form itself, or use ANSI to Unicode, and vice-versa, routines for conversions.
(There is more to add from this location, stay tuned!)
Now, I hope you understand the following signatures:
Hide Copy Code
Continuing. You must have seen some functions/methods asking you to pass number of characters, or returning the number of characters. Well, like
you need to pass number of characters, and not number of bytes. For example:
Hide Copy Code
On the other side, if you need to allocate number or characters, you must allocate proper number of bytes. In C++, you can simply use
Hide Copy Code
But if you use memory allocation functions like
etc; you must specify the number of bytes!
Hide Copy Code
Typecasting the return value is required, as you know. The expression in
desired number of bytes - and makes up room for desired number of characters.
TCHAR,
LPCTSTRare.
In this article, I would attempt by best to clear out the fog.
In general, a character can be represented in 1 byte or 2 bytes. Let's say 1-byte character is ANSI character - all English characters are represented through this encoding. And let's say a 2-byte character
is Unicode, which can represent ALL languages in the world.
The Visual C++ compiler supports
charand
wchar_tas
native data-types for ANSI and Unicode characters, respectively. Though there is more concrete definition of Unicode, but for understanding assume it as two-byte character which Windows OS uses for multiple
language support.
There is more to Unicode than 2-bytes character representation Windows uses. Microsoft Windows use UTF-16 character encoding.
What if you want your C/C++ code to be independent of character encoding/mode used?
Suggestion: Use generic data-types and names to represent characters and string.
For example, instead of replacing:
Hide Copy Code
char cResponse; // 'Y' or 'N' char sUsername[64]; // str* functions
with
Hide Copy Code
wchar_t cResponse; // 'Y' or 'N' wchar_t sUsername[64]; // wcs* functions
In order to support multi-lingual (i.e., Unicode) in your language, you can simply code it in more generic manner:
Hide Copy Code
#include<TCHAR.H> // Implicit or explicit include TCHAR cResponse; // 'Y' or 'N' TCHAR sUsername[64]; // _tcs* functions
The following project setting in General page describes which Character Set is to be used for compilation: (General -> Character Set)
This way, when your project is being compiled as Unicode, the
TCHARwould translate to
wchar_t.
If it is being compiled as ANSI/MBCS, it would be translated to
char. You are free to use
charand
wchar_t,
and project settings will not affect any direct use of these keywords.
TCHAR isdefined as:
Hide Copy Code
#ifdef _UNICODE typedef wchar_t TCHAR; #else typedef char TCHAR; #endif
The macro
_UNICODEis defined when you set Character Set to "Use
Unicode Character Set", and therefore
TCHARwould mean
wchar_t.
When Character Set if set to "Use Multi-Byte Character Set", TCHAR would mean
char.
Likewise, to support multiple character-set using single code base, and possibly supporting multi-language, use specific functions (macros). Instead of using
strcpy,
strlen,
strcat(including
the secure versions suffixed with_s); or
wcscpy,
wcslen,
wcscat(including
secure), you should better use use
_tcscpy,
_tcslen,
_tcscatfunctions.
As you know
strlenis prototyped as:
Hide Copy Code
size_t strlen(const char*);
And,
wcslenis prototyped as:
Hide Copy Code
size_t wcslen(const wchar_t* );
You may better use
_tcslen, which is logically prototyped
as:
Hide Copy Code
size_t _tcslen(const TCHAR* );
WC is for Wide Character. Therefore,
wcsturns to be wide-character-string.
This way,
_tcswould mean _T Character String. And you know _T may be
charor
what_t,
logically.
But, in reality,
_tcslen(and other
_tcsfunctions)
are actually not functions, but macros. They are defined simply as:
Hide Copy Code
#ifdef _UNICODE #define _tcslen wcslen #else #define _tcslen strlen #endif
You should refer
TCHAR.Hto lookup more macro definitions
like this.
You might ask why they are defined as macros, and not implemented as functions instead? The reason is simple: A library or DLL may export a single function, with same name and prototype (Ignore overloading concept of C++). For instance, when you export a function
as:
Hide Copy Code
void _TPrintChar(char);
How the client is supposed to call it as?
Hide Copy Code
void _TPrintChar(wchar_t);
_TPrintCharcannot be magically converted into function taking 2-byte character. There has to be two separate functions:
Hide Copy Code
void PrintCharA(char); // A = ANSI void PrintCharW(wchar_t); // W = Wide character
And a simple
1aa70
macro, as defined below, would hide the difference:
Hide Copy Code
#ifdef _UNICODE void _TPrintChar(wchar_t); #else void _TPrintChar(char); #endif
The client would simply call it as:
Hide Copy Code
TCHAR cChar; _TPrintChar(cChar);
Note that both
TCHARand
_TPrintCharwould
map to either Unicode or ANSI, and therefore
cCharand the
argument to function would be either
charor
wchar_t.
Macros do avoid these complications, and allows us to use either ANSI or Unicode function for characters and strings. Most of the Windows functions, that take string or a character are implemented this way, and for programmers convenience, only one function
(a macro!) is good.
SetWindowTextis one example:
Hide Copy Code
// WinUser.H #ifdef UNICODE #define SetWindowText SetWindowTextW #else #define SetWindowText SetWindowTextA #endif // !UNICODE
There are very few functions that do not have macros, and are available only with suffixed W or A. One example is
ReadDirectoryChangesW,
which doesn't have ANSI equivalent.
You all know that we use double quotation marks to represent strings. The string represented in this manner is ANSI-string, having 1-byte each character. Example:
Hide Copy Code
"This is ANSI String. Each letter takes 1 byte."
The string text given above is not Unicode, and would be quantifiable for multi-language support. To represent Unicode string, you need to use prefix
L.
An example:
Hide Copy Code
L"This is Unicode string. Each letter would take 2 bytes, including spaces."
Note the L at the beginning of string, which makes it a Unicode string. All characters (I repeat all characters) would take two bytes, including
all English letters, spaces, digits, and the null character. Therefore, length of Unicode string would always be in multiple of 2-bytes. A Unicode string of length 7 characters would need 14 bytes, and so on. Unicode string taking 15 bytes, for example, would
not be valid in any context.
In general, string would be in multiple of
sizeof(TCHAR)bytes!
When you need to express hard-coded string, you can use:
Hide Copy Code
"ANSI String"; // ANSI
L"Unicode String"; // Unicode
_T("Either string, depending on compilation"); // ANSI or Unicode
// or use TEXT macro, if you need more readabilityThe non-prefixed string is ANSI string, the L prefixed string is Unicode, and string specified in
_Tor
TEXTwould
be either, depending on compilation. Again,
_Tand
TEXTare
nothing but macros, and are defined as:
Hide Copy Code
// SIMPLIFIED #ifdef _UNICODE #define _T(c) L##c #define TEXT(c) L##c #else #define _T(c) c #define TEXT(c) c #endif
The
##symbol is token
pasting operator, which would turn
_T("Unicode") into L"Unicode",
where the string passed is argument to macro - If
_UNICODEis defined. If
_UNICODEis
not defined,
_T("Unicode") would simply mean "Unicode".
The token pasting operator did exist even in C language, and is not specific about VC++ or character encoding.
Note that these macros can be used for strings as well as characters.
_T('R') would turn into L'R'or
simple
'R'- former is Unicode character, latter is ANSI character.
No, you cannot use these macros to convert variables (string or character) into Unicode/non-Unicode text. Following is not valid:
Hide Copy Code
char c = 'C'; char str[16] = "CodeProject"; _T(c); _T(str);
The bold lines would get successfully compiled in ANSI (Multi-Byte) build, since
_T(x)would simply be
x,
and therefore
_T(c)and
_T(str)would
come out to be
cand
str,
respectively. But, when you build it with Unicode character set, it would fail to compile:
Hide Copy Code
error C2065: 'Lc' : undeclared identifier error C2065: 'Lstr' : undeclared identifier
I would not like to insult your intelligence by describing why and what those errors are.
There exist set of conversion routine to convert MBCS to Unicode and vice versa, which I would explain soon.
It is important to note that almost all functions that take string (or character), primarily in Windows API, would have generalized prototype in MSDN and elsewhere. The function
SetWindowTextA/W,
for instance, be classified as:
Hide Copy Code
BOOL SetWindowText(HWND, const TCHAR*);
But, as you know,
SetWindowTextis just a macro, and depending on your build settings, it would mean either of following:
Hide Copy Code
BOOL SetWindowTextA(HWND, const char*); BOOL SetWindowTextW(HWND, const wchar_t*);
Therefore, don't be puzzled if following call fails to get address of this function!
Hide Copy Code
HMODULE hDLLHandle; FARPROC pFuncPtr; hDLLHandle = LoadLibrary(L"user32.dll"); pFuncPtr = GetProcAddress(hDLLHandle, "SetWindowText"); //pFuncPtr will be null, since there doesn't exist any function with name SetWindowText !
From
User32.DLL, the two functions
SetWindowTextAand
SetWindowTextWare
exported, not the function with generalized name.
Interestingly, .NET Framework is smart enough to locate function from DLL with generalized name:
Hide Copy Code
[DllImport("user32.dll")]
extern public static int SetWindowText(IntPtr hWnd, string lpString);No rocket science, just bunch of ifs and else around
GetProcAddress!
All of the functions that have ANSI and Unicode versions, would have actual implementation only in Unicode version. That means, when you call
SetWindowTextAfrom
your code, passing an ANSI string - it would convert the ANSI string to Unicode text and then would call
SetWindowTextW.
The actual work (setting the window text/title/caption) will be performed by Unicode version only!
Take another example, which would retrieve the window text, using
GetWindowText. You call
GetWindowTextA,
passing ANSI buffer as target buffer.
GetWindowTextAwould first call
GetWindowTextW,
probably allocating a Unicode string (a
wchar_tarray) for it. Then it would convert that Unicode stuff, for you,
into ANSI string.
This ANSI to Unicode and vice-versa conversion is not limited to GUI functions, but entire set of Windows API, which do take strings and have two variants. Few examples could be:
CreateProcess
GetUserName
OpenDesktop
DeleteFile
etc
It is therefore very much recommended to call the Unicode version directly. In turn, it means you should alwaystarget for Unicode builds, and not ANSI builds - just because you are accustomed to using
ANSI string for years. Yes, you may save and retrieve ANSI strings, for example in file, or send as chat message in your messenger application. The conversion routines do exist for such needs.
Note: There exists another typedef:
WCHAR, which is equivalent
to
wchar_t.
The
TCHARmacro is for a single character. You can definitely declare an array of
TCHAR.
What if you would like to express a character-pointer, or a const-character-pointer - Which one of the following?
Hide Copy Code
// ANSI characters foo_ansi(char*); foo_ansi(const char*); /*const*/ char* pString; // Unicode/wide-string foo_uni(WCHAR*); wchar_t* foo_uni(const WCHAR*); /*const*/ WCHAR* pString; // Independent foo_char(TCHAR*); foo_char(const TCHAR*); /*const*/ TCHAR* pString;
After reading about
TCHARstuff, you would definitely select the last one as your choice. There are better alternatives
available to represent strings. For that, you just need to include Windows.h. Note: If
your project implicitly or explicitly includes Windows.h, you need not include
TCHAR.H
First, revisit old string functions for better understanding. You know
strlen:
Hide Copy Code
size_t strlen(const char*);
Which may be represented as:
Hide Copy Code
size_t strlen(LPCSTR);
Where symbol
LPCSTRis
typedef'ed
as:
Hide Copy Code
// Simplified typedef const char* LPCSTR;
The meaning goes like:
LP - Long Pointer
C - Constant
STR - String
Essentially,
LPCSTRwould mean (Long) Pointer to a Constant String.
Let's represent
strcpyusing new style type-names:
Hide Copy Code
LPSTR strcpy(LPSTR szTarget, LPCSTR szSource);
The type of szTarget is
LPSTR,
without C in the type-name. It is defined as:
Hide Copy Code
typedef char* LPSTR;
Note that the szSource is
LPCSTR, since
strcpyfunction
will not modify the source buffer, hence the
constattribute. The return type is non-constant-string:
LPSTR.
Alright, these
str-functions are for ANSI string manipulation. But we want routines for 2-byte Unicode strings. For
the same, the equivalent wide-character str-functions are provided. For example, to calculate length of wide-character (Unicode string), you would use
wcslen:
Hide Copy Code
size_t nLength; nLength = wcslen(L"Unicode");
The prototype of
wcslenis:
Hide Copy Code
size_t wcslen(const wchar_t* szString); // Or WCHAR*
And that can be represented as:
Hide Copy Code
size_t wcslen(LPCWSTR szString);
Where the symbol
LPCWSTRis defined as:
Hide Copy Code
typedef const WCHAR* LPCWSTR; // const wchar_t*
Which can be broken down as:
LP - Pointer
C - Constant
WSTR - Wide character String
Similarly,
strcpyequivalent is
wcscpy,
for Unicode strings:
Hide Copy Code
wchar_t* wcscpy(wchar_t* szTarget, const wchar_t* szSource)
Which can be represented as:
Hide Copy Code
LPWSTR wcscpy(LPWSTR szTarget, LPWCSTR szSource);
Where the target is non-constant wide-string (
LPWSTR), and source is constant-wide-string.
There exist set of equivalent
wcs-functions for
str-functions.
The
str-functions would be used for plain ANSI strings, and
wcs-functions
would be used for Unicode strings.
Though, I already advised to use Unicode native functions, instead of ANSI-only or TCHAR-synthesized functions. The reason was simple - your application must only be Unicode, and you should not even
care about code portability for ANSI builds. But for the sake of completeness, I am mentioning these generic mappings.
To calculate length of string, you may use
_tcslenfunction
(a macro). In general, it is prototyped as:
Hide Copy Code
size_t _tcslen(const TCHAR* szString);
Or, as:
Hide Copy Code
size_t _tcslen(LPCTSTR szString);
Where the type-name
LPCTSTRcan be classified as:
LP - Pointer
C - Constant
T = TCHAR
STR = String
Depending on the project settings,
LPCTSTRwould be mapped
to either
LPCSTR(ANSI) or
LPCWSTR(Unicode).
Note:
strlen,
wcslenor
_tcslenwill
return number of characters in string, not the number of bytes.
The generalized string-copy routine
_tcscpyis defined as:
Hide Copy Code
size_t _tcscpy(TCHAR* pTarget, const TCHAR* pSource);
Or, in more generalized form, as:
Hide Copy Code
size_t _tcscpy(LPTSTR pTarget, LPCTSTR pSource);
You can deduce the meaning of
LPTSTR!
Usage Examples
First, a broken code:
Hide Copy Code
int main()
{
TCHAR name[] = "Saturn";
int nLen; // Or size_t
lLen = strlen(name);
}On ANSI build, this code will successfully compile since
TCHARwould be
char,
and hence name would be an array of
char. Calling
strlenagainst
namevariable
would also work flawlessly.
Alright. Let's compile the same with with
UNICODE/
_UNICODEdefined
(i.e. "Use Unicode Character Set" in project settings). Now, the compiler would report set of errors:
error C2440: 'initializing' : cannot convert from 'const char [7]' to 'TCHAR []'
error C2664: 'strlen' : cannot convert parameter 1 from 'TCHAR []' to 'const char *'
And the programmers would start committing mistakes by correcting it this way (first error):
Hide Copy Code
TCHAR name[] = (TCHAR*)"Saturn";
Which will not pacify the compiler, since the conversion is not possible from
TCHAR*to
TCHAR[7].
The same error would also come when native ANSI string is passed to a Unicode function:
Hide Copy Code
nLen = wcslen("Saturn");
// ERROR: cannot convert parameter 1 from 'const char [7]' to 'const wchar_t *'Unfortunately (or fortunately), this error can be incorrectly corrected by simple C-style typecast:
Hide Copy Code
nLen = wcslen((const wchar_t*)"Saturn");
And you'd think you've attained one more experience level in pointers! You are wrong - the code would give incorrect result, and in most cases would simply cause Access Violation. Typecasting this way is like passing a
floatvariable
where a structure of 80 bytes is expected (logically).
The string
"Saturn"is
sequence of 7 bytes:
| 'S' (83) | 'a' (97) | 't' (116) | 'u' (117) | 'r' (114) | 'n' (110) | '\0' (0) |
wcslen, it treats each 2-byte as a single character. Therefore first two bytes
[97, 83] would be treated as one character having value: 24915 (
97<<8 | 83). It is Unicode character:
?.
And the next character is represented by [117, 116] and so on.
For sure, you didn't pass those set of Chinese characters, but improper typecasting has done it! Therefore it is very essential to know that type-casting will not work! So, for the first line of initialization,
you must do:
Hide Copy Code
TCHAR name[] = _T("Saturn");Which would translate to 7-bytes or 14-bytes, depending on compilation. The call to
wcslenshould be:
Hide Copy Code
wcslen(L"Saturn");
In the sample program code given above, I used
strlen, which causes error when building in Unicode. The non-working
solution is C-sytle typecast:
Hide Copy Code
lLen = strlen ((const char*)name);
On Unicode build, name would be of 14-bytes (7 Unicode characters, including null). Since string "Saturn"contains only English letters, which can be represented using original ASCII, the Unicode letter
'S'would
be represented as [83, 0]. Other ASCII characters would be represented with a zero next to them. Note that
'S'is
now represented as 2-byte value
83. The end of string would
be represented by two bytes having value
0.
So, when you pass such string to
strlen, the first character (i.e. first byte) would be correct (
'S'in
case of "Saturn"). But the second character/byte would indicate end of string. Therefore,
strlenwould return incorrect
value
1as the length of string.
As you know, Unicode string may contain non-English characters, the result of strlen would be more undefined.
In short, typecasting will not work. You either need to represent strings in correct form itself, or use ANSI to Unicode, and vice-versa, routines for conversions.
(There is more to add from this location, stay tuned!)
Now, I hope you understand the following signatures:
Hide Copy Code
BOOL SetCurrentDirectory( LPCTSTR lpPathName ); DWORD GetCurrentDirectory(DWORD nBufferLength,LPTSTR lpBuffer);
Continuing. You must have seen some functions/methods asking you to pass number of characters, or returning the number of characters. Well, like
GetCurrentDirectory,
you need to pass number of characters, and not number of bytes. For example:
Hide Copy Code
TCHAR sCurrentDir[255]; // Pass 255 and not 255*2 GetCurrentDirectory(sCurrentDir, 255);
On the other side, if you need to allocate number or characters, you must allocate proper number of bytes. In C++, you can simply use
new:
Hide Copy Code
LPTSTR pBuffer; // TCHAR* pBuffer = new TCHAR[128]; // Allocates 128 or 256 BYTES, depending on compilation.
But if you use memory allocation functions like
malloc,
LocalAlloc,
GlobalAlloc,
etc; you must specify the number of bytes!
Hide Copy Code
pBuffer = (TCHAR*) malloc (128 * sizeof(TCHAR) );
Typecasting the return value is required, as you know. The expression in
malloc's argument ensures that it allocates
desired number of bytes - and makes up room for desired number of characters.

相关文章推荐
- 使用C++实现JNI接口需要注意的事项
- 如何重装TCP/IP协议
- 关于指针的一些事情
- Windows 8 官方高清壁纸欣赏与下载
- 谁是桌面王者?Win PK Linux三大镇山之宝
- 对《大家都在点赞 Windows Terminal,我决定给你泼一盆冷水》一文的商榷
- Windows Clang开发环境备忘
- 从Windows系统下访问Linux分区相关软件
- 对《大家都在点赞 Windows Terminal,我决定给你泼一盆冷水》一文的商榷
- Windows下搭建本地SVN服务器
- c++ primer 第五版 笔记前言
- Visual Studio 2012 示例代码浏览器 - 数以千计的开发示例近在手边,唾手可得
- Visual Studio 2012 示例代码浏览器 - 数以千计的开发示例近在手边,唾手可得
- share_ptr的几个注意点
- Linux C函数参考手册(PDF版)
- 微软镜像下载
- windows server域用户提升到本地更高权限组中的方法