SQL Server 2008 R2——当前日期下,一年前数据的统计值
2015-12-01 16:02
387 查看
=================================版权声明=================================
[b]版权声明:原创文章 谢绝转载
[/b]
请通过右侧公告中的“联系邮箱(wlsandwho@foxmail.com)”联系我
勿用于学术性引用。
勿用于商业出版、商业印刷、商业引用以及其他商业用途。
本文不定期修正完善。
本文链接:/article/5266613.html
耻辱墙:/article/5266550.html
=======================================================================
没啥说的,鄙视那些无视版权随意抓取博文的爬虫小网站,祝你们早升极乐。
=======================================================================
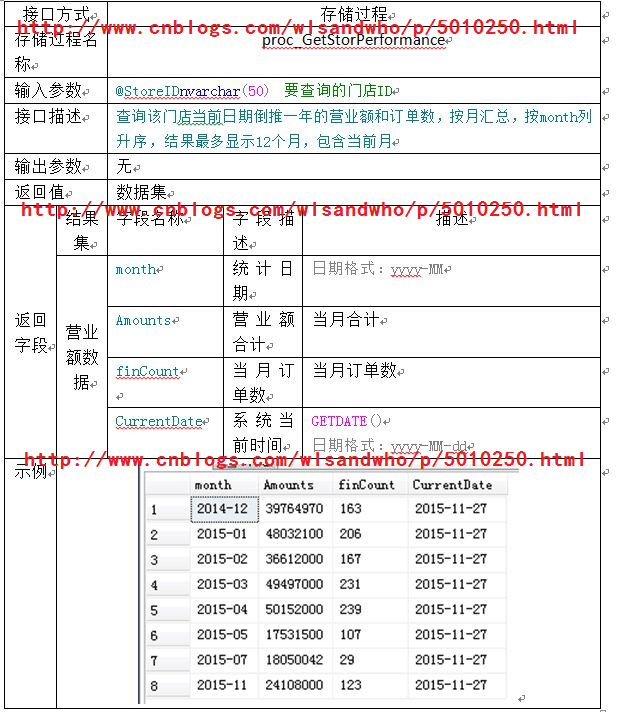
这是企鹅群里一群友的问题。早晨9:13入群问问题,然后可以等一天,真佩服。
当然本着拒绝伸手党的原则,我给的代码只是大致的一个解决方案,并不使用给出的字段、数据以及边界范围。
=======================================================================
完整代码如下
=======================================================================
CTE分了三个部分:
第一部分增加YYYYMM,因为直接用DATETIME类型进行操作感觉不方便。
投机取巧的地方是把DATETIME转作整数类型的“年+月”处理,“年+月”是YYYYMM的样式,不包含DD。年月的大小跟数字的大小自然契合,方便比较。
第二部分按YYYYMM分组进行了数据统计。
第三部分只是我不想写成存储过程,就顺便写了个选择语句,用途是生成“当前日期的一年前”这个概念涉及到的边界值。很显然可以方便的对边界进行包含和不包含的处理。
=======================================================================
下面是执行计划,看起来还不错,当然我的数据很少。

=======================================================================
非专业SQL 不求高效 但求能跑

(友情支持请扫描这个)
微信扫描上方二维码捐赠
[b]版权声明:原创文章 谢绝转载
[/b]
请通过右侧公告中的“联系邮箱(wlsandwho@foxmail.com)”联系我
勿用于学术性引用。
勿用于商业出版、商业印刷、商业引用以及其他商业用途。
本文不定期修正完善。
本文链接:/article/5266613.html
耻辱墙:/article/5266550.html
=======================================================================
没啥说的,鄙视那些无视版权随意抓取博文的爬虫小网站,祝你们早升极乐。
=======================================================================
这是企鹅群里一群友的问题。早晨9:13入群问问题,然后可以等一天,真佩服。
当然本着拒绝伸手党的原则,我给的代码只是大致的一个解决方案,并不使用给出的字段、数据以及边界范围。
=======================================================================
完整代码如下
--by wls 20151201 --网络代码有风险 --复制粘贴须谨慎 USE tempdb GO IF OBJECT_ID (N't_TestbyWLS', N'U') IS NOT NULL DROP TABLE t_TestbyWLS; GO CREATE TABLE t_TestbyWLS(SN INTEGER PRIMARY KEY,OccurTime DATETIME,OccurQty INTEGER) GO INSERT INTO t_TestbyWLS SELECT 1,'2015-12-01 11:11:11.111',11 UNION SELECT 111,'2015-12-01 10:11:11.111',22 UNION SELECT 2,'2015-11-11 11:11:11.111',33 UNION SELECT 3,'2015-11-01 11:11:11.111',44 UNION SELECT 4,'2015-09-11 11:11:11.111',55 UNION SELECT 6,'2015-09-11 11:11:11.111',66 UNION SELECT 7,'2015-08-11 11:11:11.111',111 UNION SELECT 8,'2015-08-01 11:11:11.111',11 UNION SELECT 9,'2015-07-11 11:11:11.111',11 UNION SELECT 10,'2015-07-11 11:11:10.111',111 UNION SELECT 11,'2015-06-11 11:11:11.111',11 UNION SELECT 12,'2015-06-11 11:11:11.111',111 UNION SELECT 13,'2015-05-11 11:11:11.111',11 UNION SELECT 14,'2015-05-11 11:11:11.111',111 UNION SELECT 15,'2015-04-11 11:11:11.111',11 UNION SELECT 16,'2015-04-11 11:11:11.111',111 UNION SELECT 17,'2015-03-11 11:11:11.111',11 UNION SELECT 18,'2015-03-11 11:11:11.111',111 UNION SELECT 19,'2015-02-11 11:11:11.111',11 UNION SELECT 20,'2015-02-01 11:11:11.111',10 UNION SELECT 21,'2015-01-11 11:11:11.111',11 UNION SELECT 22,'2015-01-01 11:11:11.111',10 UNION SELECT 23,'2014-11-11 11:11:11.111',11 UNION SELECT 24,'2013-11-11 11:11:11.111',11 UNION SELECT 25,'2014-12-11 11:11:11.111',11 GO --SELECT * FROM t_TestbyWLS --GO WITH TempYYYYMM AS ( SELECT SN,OccurQty,OccurTime,CAST(CONVERT (NVARCHAR(12),occurtime,112) AS INTEGER)/100 AS YYYYMM FROM t_TestbyWLS ), TempSumMM AS ( SELECT YYYYMM,SUM(OccurQty) AS MMqty FROM TempYYYYMM GROUP BY YYYYMM ), TempRangeYYYYMM as ( SELECT CAST(CONVERT (NVARCHAR(12),DATEADD(YEAR,-1,GETDATE()),112) AS INTEGER)/100 AS LYYYYMM, CAST(CONVERT (NVARCHAR(12),GETDATE(),112) AS INTEGER)/100 AS RYYYYMM ) SELECT DISTINCT b.MMqty,b.yyyymm from TempSumMM b LEFT JOIN TempYYYYMM a ON b.YYYYMM=a.YYYYMM LEFT JOIN TempRangeYYYYMM c ON b.YYYYMM>=c.LYYYYMM AND b.YYYYMM<c.RYYYYMM ORDER BY b.YYYYMM GO
=======================================================================
CTE分了三个部分:
第一部分增加YYYYMM,因为直接用DATETIME类型进行操作感觉不方便。
投机取巧的地方是把DATETIME转作整数类型的“年+月”处理,“年+月”是YYYYMM的样式,不包含DD。年月的大小跟数字的大小自然契合,方便比较。
第二部分按YYYYMM分组进行了数据统计。
第三部分只是我不想写成存储过程,就顺便写了个选择语句,用途是生成“当前日期的一年前”这个概念涉及到的边界值。很显然可以方便的对边界进行包含和不包含的处理。
=======================================================================
下面是执行计划,看起来还不错,当然我的数据很少。
=======================================================================
非专业SQL 不求高效 但求能跑
(友情支持请扫描这个)
微信扫描上方二维码捐赠

相关文章推荐
- Redis Cluster搭建方法简介
- oracle之类型转换
- spring结合redis如何实现数据的缓存
- 数据库设计细节问题
- 数据库分库分表(sharding)系列(五) 一种支持自由规划无须数据迁移和修改路由代码的Sharding扩容方案
- 数据库分库分表(sharding)系列(四) 多数据源的事务处理
- 数据库分库分表(sharding)系列(三) 关于使用框架还是自主开发以及sharding实现层面的考量
- Oracle存储过程和程序包
- 数据库分库分表(sharding)系列(二) 全局主键生成策略
- Mongodb3.0.6副本集+分片学习笔记
- redis conf配置文件详解
- 数据库Sharding的基本思想和切分策略
- oracle rman catalog备份和恢复
- mysql中的SQL优化与执行计划
- Oracle协议适配器错误解决办法
- Oracle TOAD乱码
- mysql 操作日期函数【增加,减少时间】
- Windows7 64位压缩包安装MySQL5.7.9
- MySQL数据库引擎介绍、区别、创建和性能测试的深入分析
- 命名空间“System.Data”中不存在类型或命名空间名称“SQLite”。是否缺少程序集引用。解决办法如下: