一天一个数据结构之ArrayList
2015-11-26 23:17
330 查看
1.ArrayList追根溯源
ArrayList基本是我们在开发过程中最常用的一个类了。大家基本常用的方法有add(),addAll(),get(),remove(),size()或者有的还会用到iterator()。
这些方法的实现与内部原理究竟是什么,相信有很多开发者和我一样都没有去深入研究过。那么现在我们来深入研究一下ArrayList的实现原理吧。
首先我们先看一下ArrayList的类图

可以看到一个大概的关系图,了解ArrayList大概是怎么个实现。
我们进入源码:我们看到ArrayList属于java.util包下,java.util包提供了一系列工具类

然后可以看到ArrayList继承自AbstractList,并实现了Cloneable,Serializable,RandomAccess接口,而且ArrayList本身是支持泛型。

AbstractList继承自AbstractCollection,并实现了List接口。

先看AbstractCollection,可以看到它实现了Collection接口。

然后回头看,AbstractList在继承AbstractCollection抽象类的同时还实现了List接口,而我们平常使用ArrayList的时候,声明的又是List。
那我们就来看一看List接口是什么。

发现,List原来继承自Collection接口,然后AbstractCollection又实现了Collection接口。(java中接口可以继承接口,也可以继承多个接口,class不能继承接口,不能继承多个类,但是可以实现多个接口)。
看到这里,会有些奇怪。AbstractList为什么继承自一个实现了Collection接口的抽象类,然后又要实现一个继承了Collection接口的接口呢?是不是很绕口,哈哈,我自己都要晕了。
在这里就先卖个关子,留着这个疑问跟我们继续往下看吧。
从前面看来,Collection接口应该最顶层的了。那我们就来看Collection接口。

Collection接口还有个父接口Iterable
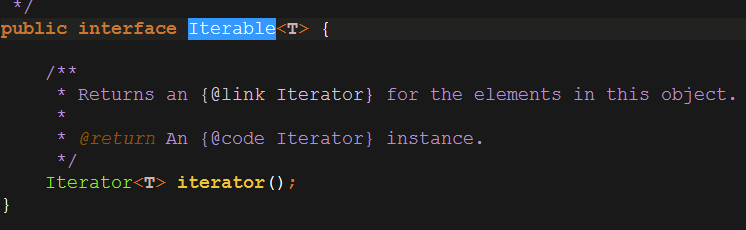
我们来看它的方法:
Iterator iterrator();
这个方法是不是很熟悉?迭代器啊!我们用这个方法来迭代ArrayList中的元素。
list list = new ArrayList();
l.add("aa");
l.add("bb");
l.add("cc");
for (Iterator iter = l.iterator(); iter.hasNext();) {
String str = (String)iter.next();
System.out.println(str);
}
/*迭代器用于while循环
Iterator iter = l.iterator();
while(iter.hasNext()){
String str = (String) iter.next();
System.out.println(str);
}可以看到,都是通过iterator方法返回了一个Iterator对象。
我们来看看Iterator对象到底是个什么?
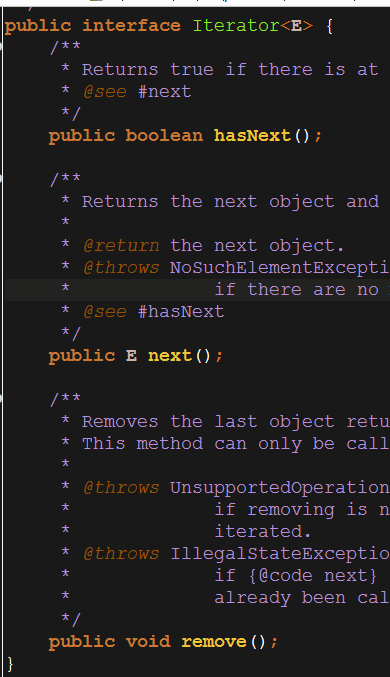
Iterator也是一个接口,含有hasNext(),next(),remove()方法。我们在前面看到的代码中看到调用ArrayList的iterator()方法,以及Iterator接口的具体实现,我们在后面会讲到。
2.ArrayList深度剖析
1.Collection
前面说到了Collection接口是继承自Iterable接口。那么我们看下Collection的具体实现。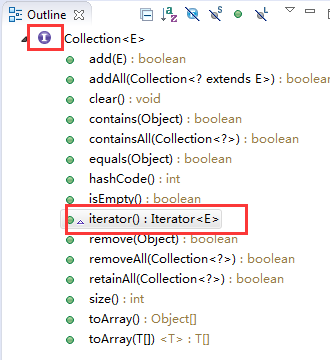
我们可以看到第一个红框中圆形的图标中间一个I。这表示Collection是一个接口。
然后在第二个红框中看到了我们在Iterable接口中看到的iterator()方法。因为Collection也是一个接口,并继承自Iterable,所有,继承的方法只能也是接口方法。
然后我们可以看看Collection接口中的方法,是不是有很多都是我们使用ArrayList的时候常用的。
比如: add()、addAll()、clear()、remove()等。基本也可以说明,我们ArrayList所使用的方法都是实现自Collection的了。
2.AbstractCollection
然后我们接着往下看,看实现了Collection接口的类AbstractCollection的具体实现。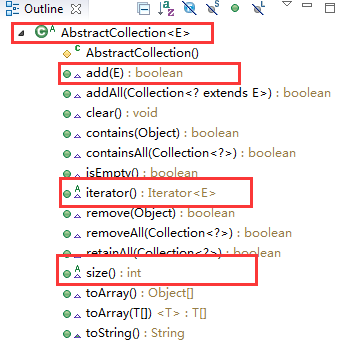
1.还是看左上角第一个红框中的小原标。里面是个C,表示这是一个类(class),然后小原标右上角有一个大写字母A。表示这个类是一个abstract方法。
2.我们主要关注下add()、iterator()、size()方法的实现。

咦,add方法直接抛出一个UnsupportedOperationException异常。看到这里一下子懵逼了。那这样我们每次调用arraylist的的时候,不就都会抛出异常了吗?但是我们每次调用又都是好使的。好吧,这里再卖一个关子,你可以记录一下我们卖的关子,到后面的point自然会有答案的噢。
然后看一下iterator()方法。

还是没有实现,然后变成一个abstract方法了,这也说明了在AbstractCollection的子类,如果不是抽象类,那就必须的实现这个方法了。
最后看一下size()方法。

好吧,还是抽象方法。
基于篇幅原因,我们不能每个接口都介绍到,只能大概介绍一些常用的。如果有兴趣可以按照我的分析思路,选择自己感兴趣的去研究。
3.AbstractList
我们继续,前面讲了,AbstractList不仅继承了AbstractCollecttion抽象类,还同时实现了List接口,而且List接口还是Collection接口的子接口。还记得我们在前面留的第一个疑问吗?
为什么AbstractList为什么要实现List接口呢?
我们可以看看List接口。

是不是比它的父接口Collection多了很多方法?而且很多方法都是我们在ArraryList集合中常用的。
比如:
add(int,E),指定插入元素的位置。
get(int),获取指定位置的元素。
remove(int),删除指定位置的元素。
等等。。
到这里,有种豁然开朗的感觉,为什么AbstractList在继承了AbstractCollection抽象类之后,还要实现List接口呢?
恩,因为Collection只是最基础的集合接口。List接口继承Collection接口的同时,又扩展了方法,形成我们常用的List接口,然后List接口也就是我们平常用的List集合类框架的顶层接口。
所以在我们平常使用时,基于多态、动态版定、里氏代换等原理原则。在声明变量时,声明的是List,然后实例化ArrayList。
接下来我们来看AbstractList的具体实现,然后重点关注一下List接口的方法实现。
对于List接口的实现,我们就暂时先只关注:add(int,E),get(int),remove(int)这三个方法和add(E)这个List接口和AbstractCollection都有的方法。
1.add(int,E)

可以看到,方法里面又是直接抛出了一个UnsupprtedOperationException异常。又?我为什么要说又?
原来是前面在看AbstractCollection抽象类的add(E)方法的时候,这个方法也是直接抛出了这个异常。在这里,我还是不能告诉你为什么,不要打我,带着疑问继续往下看吧。嘿嘿。
2.get(int)

好嘛,又是一个抽象方法,说明在非抽象类的子类中必须要实现此方法,从前面我们对ArrayList追根溯源的时候可以看到,AbstractList的子类就是ArrayList了,所以ArrayList中,一定存在了很多不可告人的秘密!
3.remove(int)

看到这里,请让我去哭一会儿。。 我就什么都不说了,只能央求你继续带着悬念看下去了。
4.add(E)

先看注释,表示这个方法是添加个指定对象到集合的尾部。
然后我们看方法内部,调用了List接口的方法add(int,E)。
在前面,我们看到了add(int,E)方法是直接抛出了异常,看到这里,悬念更深了,为什么都是直接抛出异常呢?我们平常调用也是没有问题呀。恩,悬念即将揭晓,请看下一部分。
4.ArrayList
终于走到了我们的目标ArrayList。带着前面的疑问,我们来看ArrayList源码。
对ArrayList构造函数里的代码,基于篇幅原因,这里就不详细讲了,3个构造函数都是做的创建array数组。
1.add(E)

还记得我们在前面ArrayList的父类AbstractList中看到的add(E)方法吗?AbstractList中的add(E)方法是调用了它的add(int,E)方法,而add(int,E)方法是直接抛出了一个UnsupprtedOperationException异常。
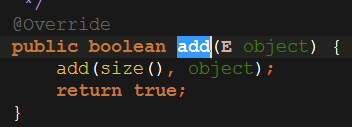

这里有个比较重要的思想就是方法的重写(override),是java面向对象编程中多态的表现,子类可以重写父类的方法以达到子类的目的,然后我们来看ArrayList的add(E)方法。
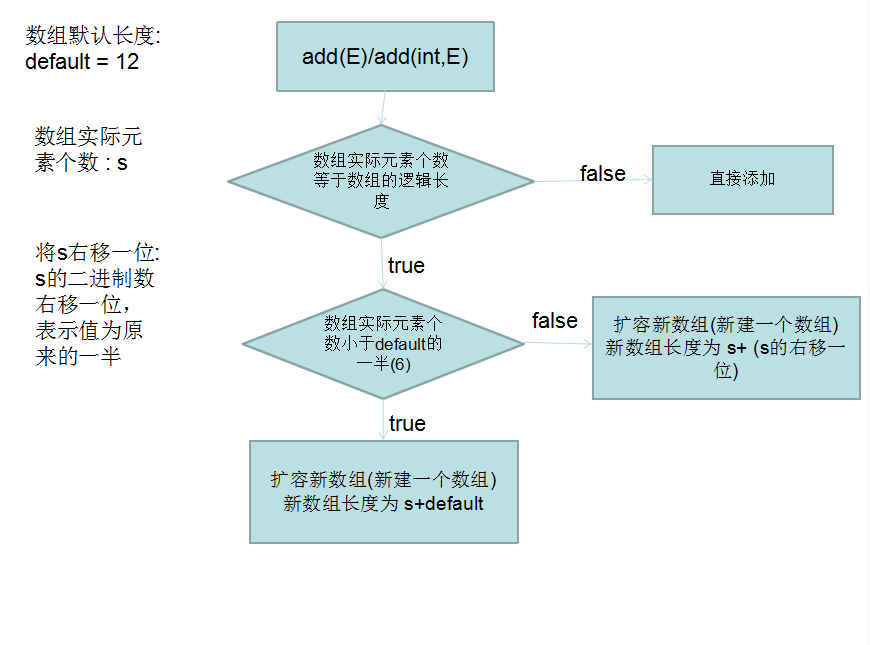
解析这个方法的内容有点长,这里放一个流程图,如果流程图能看懂,就可以直接略过下面的文字解析。
文字解析:
我们看方法内部首先声明了一个局部Object数组变量,然后将一个全局的array变量赋值给它,我们看看array变量是在哪里声明的。

我们看到,是在代码第62行声明的一个用transient关键字修饰的Object数组。
继续看方法的代码,声明了一个int 变量s,并将size赋值给它,由字面来看,size应该是我们list的长度了,口说无凭,继续看代码。

果然size是list的长度,接着往下看,判断当前记录的集合的size是不是等于array数组对象的length实际长度。
然后我们会看到下面这段代码,

当记录的size等于数组对象a的实际length,表示数组已满,此时新建一个数组对象newArray。
然后指定newArray数组的长度,长度是由一个3元运算符计算出来的。
s + (s < MIN_CAPACITY_INCREMENT) / 2 ? MIN_CAPACIT_INCREMENT : s >> 1)。
其中,MIN_CAPACITY_INCREAMENT是ArrayList默认的初始长度,长度为12。

所以,这里的增加容量的具体含义是:
每次需要增加容量的时候,如果当前数组记录的长度小于12的一半(也就是6),那么新的对象数组长度为原本数组的元素个数s加上12,整个新对象数组的长度约为原先长度的1.5倍。
如果当前数组记录的长度s大于12的一半,则扩容后的数组长度为原本记录数组长度s加上s右移一位的值,而每当一个数的值右移一位,右移之后的值就为原先值的一半。也就是s + s/2 = 1.5s,新对象数组的长度也是原对象长度的1.5倍。
可以得出结论,每次只要是数组需要扩容,扩容的容量都是原容量的1.5倍。这样既不会因为容量扩容的太小导致频繁扩容,频繁进行后一步的数组的复制操作,也不会因为扩容的太多,导致有很多的空闲内存被占用。
然后调用System.arraycopy()方法,将旧的数组的全部数据复制到newArray数组中去并将新的数组对象newArray的引用指向全局array和局部数组对象a。
最后,将要被添加的参数object添加进数组中的最后一位,然后将size的值加一,最后将modCount值加一。
但是在ArrayList中并没有找到modCount的值,ctrl 加 左键点击modCount,发现是ArrayList的父类AbastractList中声明的。
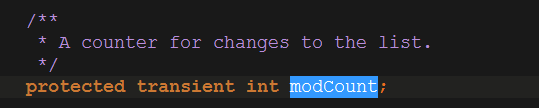
注释表示,这是记录list修改次数的一个变量。至于为什么要记录,暂时先将它放到一边,暂时不考虑(其实是我还没有注意到。。。)。
2.add(int,E)
然后我们来看add(int,E)方法。
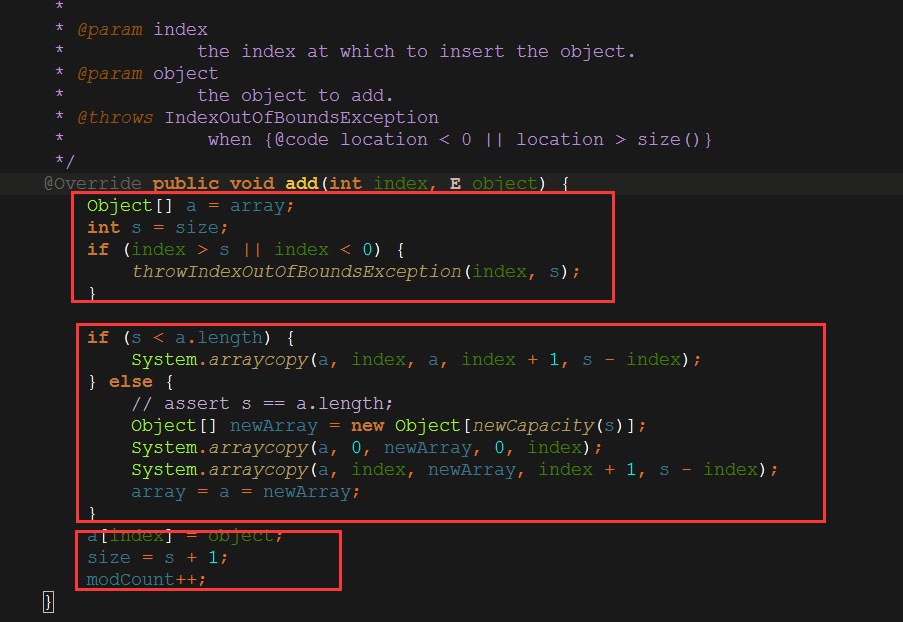
从注释可以看到,第一个参数 index是要被插入的对象的索引位置,也就是这个对象要插入到数组中的位置。
首先,还是在方法内部声明了一个数组对象 a,并将全局的数组对象array的引用指向a。
然后将全局的数组长度size赋值给局部int变量s。
判断要插入的位置是否超出了当前数组的长度,或者要插入的位置是否小于0(最小的位置就是0,不能为负数)。
然后判断当前记录的数组长度s是否小于当前数组的实际长度,如果小于,则表示当前记录的数组的长度可能是有错误的。
那么执行一次数组拷贝,将数组a从index开始的内容,拷贝到a从index + 1开始的内容,拷贝长度为 s - index。
看到这里是不是有点蒙?
我们画个图来捋一捋思路。
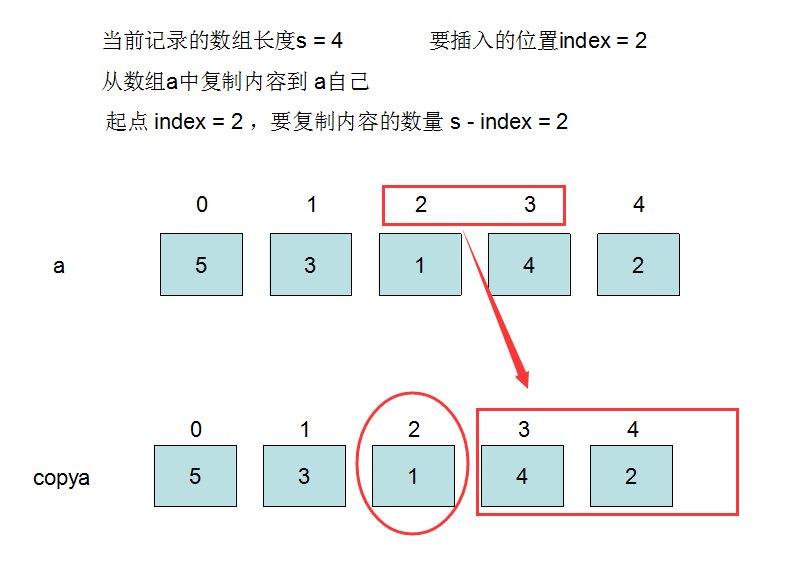
可以看到,这行代码是数组a复制内容到数组a自己。
我们假设数组当前有5条记录5,3,1,4,2。然后size记录的数组的长度却是4。当前插入数据的索引值index为2。
从图中可以看到,我们是把从index开始的a[2],a[3]复制到 index+1的 a[3],a[4]处。
最后,数组的实际值应该为{5,3,1,1,4}。
看到这里是不是有点疑问,多了一个1,然后少了1个2,我们这么想,当数组a的实际长度为5的时候,当前缓存的长度却比实际的要小。说明缓存记录是有问题,然后此时又要进行一次add操作,那么为了不影响缓存记录和实际数组长度的冲突,只能将当前数组的最后一位放弃。然后中间圆圈中的多出来的一个1,刚好为后面要执行的add操作留出一个位置。
从代码可以看到,当执行完arraycopy方法后,是直接设置a[index]=object。是直接指定了数组下标的index索引进行赋值,而不是前面add(int)方法中赋值的是数组实际长度的索引值(索引值总是比实际长度小一位,所以设置数组实际长度的值,也就是添加一个新值)。然后再给s加一位,现在s就是5了,就和数组a的实际长度一致了。按照这个思路,只要当前缓存的size小于实际数组的长度,每次都会将数组的最后一位给抛弃,然后当新添加一个值后将size加一,来不断地追加size的值直到size等于数组的实际长度。
3.get(int)方法

从代码可以看到,先判断index的值是否大于等于当前数组记录的size,如果大于等于,那么就抛出一个数组越界的异常。
如果index正常,则从数组中获取下标为index的结果返回。
4.iterator()

我们可以看到,ArrayList重写了AbstractList的iterator方法,在方法内部创建了一个匿名内部类 ArrayListIterator对象并返回,从截图中也可以看到ArrayListIterator实现了Iterator接口。
然后我们来看ArrayListIterator是怎么实现Iterator接口的,先看ArrayListIterator的一些内部属性。
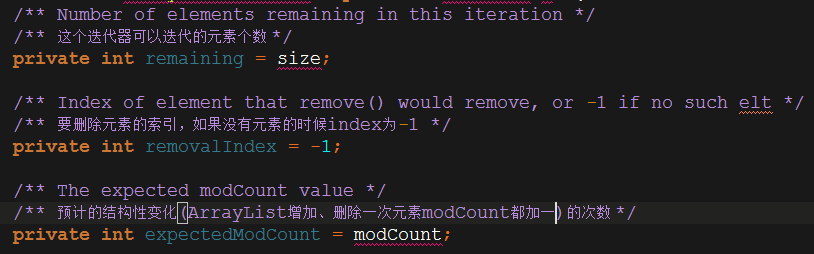
声明了remaining,removalIndex,ecpectedModCount。
hasNext()方法。

判断remaining是否为0,如果为0说明是没有可迭代的元素了,就返回false表示没有下一个元素。反之为true。
然后next()方法。
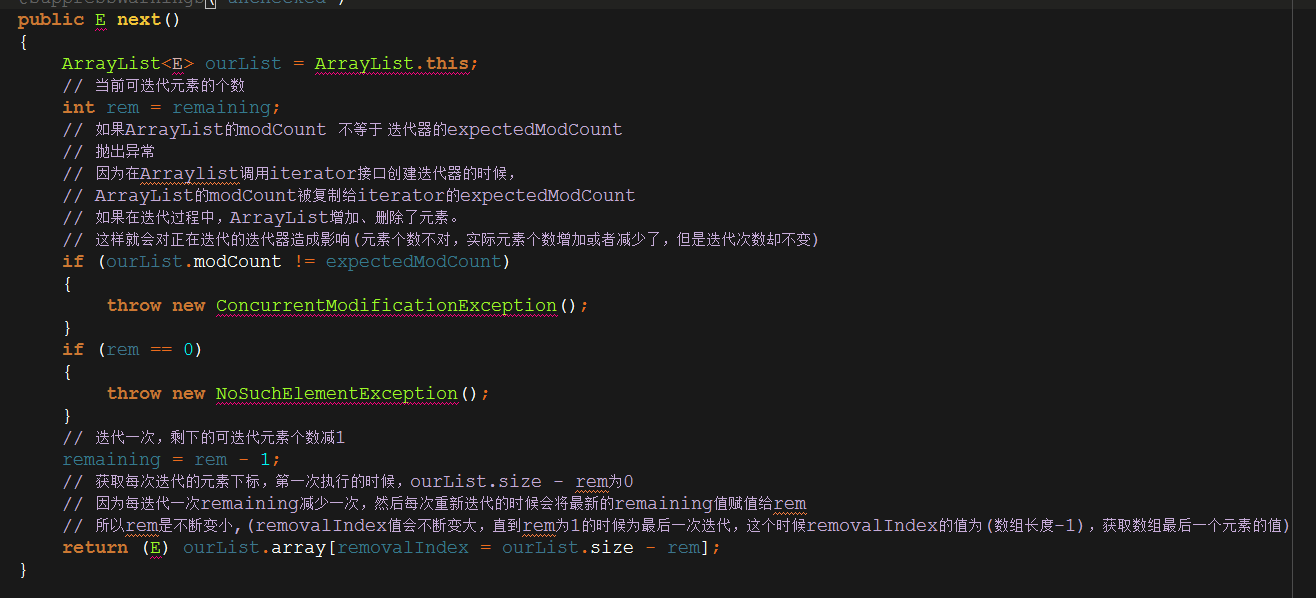
从我们看的这几个常用方法,可以知道ArrayList的内部其实是由一个数组来控制的,我们的增加、删除都是操作的数组,所以才叫Array的List。
后记:
从这篇分析我们知道了ArrayList是基于内部的Object数组来实现的,也通过分析内部实现,了解了ArrayList的优缺点。
优点:
1.查询速度快,基于数组下标。
缺点:
1.因为是基于数组的,数组又是不能动态增加的。所以,每次增加元素到一定层度,
就必须要进行一次扩容,而且基本上当前数组的长度默认为元素实际长度的1.5倍。这都会造成内存的开销。
2.add数据或者remove数据,都是执行了复制数组的操作,如果频繁执行,也会有性能的影响。

相关文章推荐
- C#.Net ArrayList的使用方法
- Lua教程(七):数据结构详解
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- C#数据结构揭秘一
- VBS ArrayList Class vbs中的数组类
- 数据结构之Treap详解
- C#中Arraylist的sort函数用法实例分析
- JavaScript数据结构和算法之图和图算法
- C#中ArrayList的使用方法
- C#中Array与ArrayList用法及转换的方法
- Java数据结构及算法实例:冒泡排序 Bubble Sort
- Java数据结构及算法实例:插入排序 Insertion Sort
- Java数据结构及算法实例:考拉兹猜想 Collatz Conjecture
- java数据结构之java实现栈
- java数据结构之实现双向链表的示例
- Java数据结构及算法实例:选择排序 Selection Sort
- Java数据结构及算法实例:朴素字符匹配 Brute Force
- Java数据结构及算法实例:汉诺塔问题 Hanoi
- Java数据结构及算法实例:快速计算二进制数中1的个数(Fast Bit Counting)
- java数据结构和算法学习之汉诺塔示例