Zookeeper你应该了解基础知识
2015-11-26 15:36
260 查看
简介
Apache ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,由Client和Server构成,Server提供了一致性复制和存储服务,Client包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。ZooKeeper的设计非常易于编程,ZooKeeper维护着一个hierarchal(层次)的名字空间,它采用树形的数据结构,类似于标准文件系统。因为想要从零实现一个分布式协作服务是非常难的。最常见的问题就是竞争条件和死锁。Apache ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。Zookeepr的数据都存放在内存中(更新数据也会持久化到磁盘),所以它的吞吐量会非常高,同时延迟会很低。ZooKeeper的实现更重视high performance(高性能), highly available(高可用性), strictly ordered access(严格有序访问)。Zookeeper性能方面的表现让它能够用于大型分布式系统,高可用性可以避免出现单点故障,严格有序访问可以让Client实现复杂的同步原语。
Zookeeper系统模型
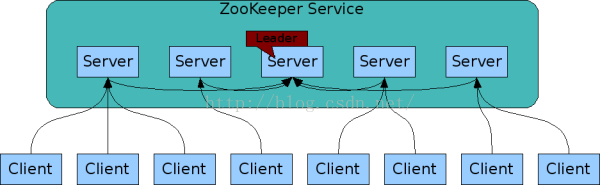
上图的哪些Server组成了Zookeeper服务,每个Server都知道彼此的存在。这些server在内存中保持着状态的镜像,还通过transaction logs和快照持久到硬盘中。只要集群中多数Server可访问,那么ZooKeeper服务就可用。
Clients会连接到某一个ZooKeeper Server上。Client和Server保持一个TCP长连接,通过该TCP长连接,Client可以发送请求,得到response,得到watch event,还有发送心跳(客户端和服务端通过心跳来保持连接,即session)。如果和Server的TCP长连接断了,那么Client就会连接到另外一个Server上。
Zookeeper是有序的:Zookeeper用stamps(数字)作为所有事务的顺序。
Zookeeper是非常快的:特别是以读为主的情况下,Zookeeper应用程序可以运行在数千台机器上,它性能表现最佳的是在读写比率为10:1的情况下。
Zookeeper数据模型
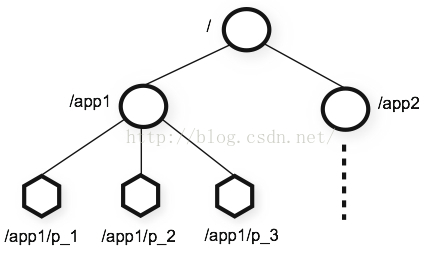
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每个ZNode上可存储少量数据(默认是1M, 可以通过配置修改, 通常不建议在ZNode上存储大量的数据),下面说说Zookeeper几个比较重要的概念:
一,Znode
1,Zookeeper节点称为Znode,每个节点都有唯一的路径标示。Znode分类两类:1,普通的Znode;2,ephemeral(临时)Znode
2,Znode维护了stat结构,里面包含数据,ACL变更的版本号,还有时间戳去允许缓存验证和协调更新。当znode的data改变了,版本号就会增加
3,Znode可以有子节点,并且Znode可以存放数据,但是ephemeral(临时)Znode不能有子节点。
4,Znode数据可以有多个版本,客户端可以根据版本获取该节点的数据。
5,如果创建ephemeral(临时)Znode的客户端和服务端失去连接的话,那么该零时节点也自动删除。
6,Znode可以自动编号。
7,Znode中可以添加watch,该watch用于监控该节点存储的数据是否有修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端。
8,Znode的读写操作都具备原子性,每个Znode都有一个访问控制列表(ACL)来控制谁能做什么操作。
二,Session
Client与ZooKeeper之间的通信,需要创建一个Session,这个Session会有一个超时时间。因为ZooKeeper集群会把Client的Session信息持久化,所以在Session没超时之前,Client与ZooKeeper Server的连接可以在各个ZooKeeper Server之间透明地移动。
在实际的应用中,如果Client与Server之间的通信足够频繁,Session的维护就不需要其它额外的消息了。否则,ZooKeeper Client会每T/3 ms发一次心跳给Server,如果Client 2T/3 ms没收到来自Server的心跳回应,就会换到一个新的ZooKeeper Server上。这里T是用户配置的Session的超时时间。
三,Watcher
ZooKeeper支持一种Watch操作,Client可以在某个ZNode上设置一个Watcher,来Watch该ZNode上的变化。如果该ZNode上有相应的变化,就会触发这个Watcher,把相应的事件通知给设置Watcher的Client。需要注意的是,ZooKeeper中的Watcher是一次性的,即触发一次就会被取消,如果想继续Watch的话,需要客户端重新设置Watcher。
四,事务日志和快照
dataDir目录指定了Zookeeper的数据目录,用于存储Zookeeper的快照文件(snapshot)。
dataLogDir定义了Zookeeper的事务日志目录,目录存放Zookeeper的事务日志,正常情况下,所有的更新操作在返回客户端更新成功前,Zookeeper肯定已经将本次更新操作写入到事务日志了(即磁盘中)。事务日志的文件名是log.,zxid是写入这个文件的第一个事务id。在完成若干次事务后会一次数据快照,将当前Server上所有节点的状态以快照文件的形式dump到磁盘上去,即snapshot文件。
Zookeeper角色
Zookeepr角色分可以分为四类:| 角色 | 描述 |
| Leader | 领导者负责进行投票的发起和决议,更新系统状态 |
| Follower | 1,Follower负责接收Client请求,并向客户端返回结果 2,在选Leader的过程中参与投票 |
| Observer | ObServer可以接收客户端的连接,将写请求转发到Leader节点,但是ObServer不参与投票和选举,仅仅接收投票和选举的结果。它的作用主要是用来扩展系统,提高读取的速度。ObServer是zookeeper-3.3.0新加的角色。 |
| Client | 请求发起方 |
leading:当前Server为Leader。
following:当前Server为Follower。
observing:当前Server为Observer。
looking:当前Server不知道leader是谁,正在搜寻。
Zookeeper特性
顺序一致性:按照客户端发送请求的顺序更新数据。Zookeeper是不属于强一致性,因为watcher没办法扑捉到每次的变化。原子性:更新要么成功,要么失败,不会出现部分更新。
单一系统映像 :无论客户端连接哪个server,都会看到同一个视图。
可靠性:具有简单、健壮、良好的性能,如果消息被到一台服务器接受,那么它将被所有的服务器接受。
时效性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新数据,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
ZooKeeper原理
Zookeeper的核心是原子广播,通过Zab协议保证各个Server之间数据的同步。Zab协议有两种模式,分别是恢复模式(选举Leader)和广播模式(同步)。服务启动或者Leader崩溃后,Zab就会进入了恢复模式,当Leader被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了Leader和Server具有相同的系统状态。为了保证事务的顺序一致性,Zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有四种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻。
LEADING:当前Server即为选举出来的leader。
FOLLOWING:leader已经选举出来,当前Server与之同步。
OBSERVING:不选举,只从Leader同步状态。
Zookeeper API
Zookeeper的一个设计目标是提供简单的编程接口,仅仅支持如下操作:create:创建一个Znode。path是其路径,data是要存储在该Znode上的数据,createMode包括:PERSISTEN,PERSISTENT_SEQUENTAIL,EPHEMERAL,EPHEMERAL_SEQUENTAIL。
delete:删除一个Znode。可以删除指定版本的Znode,如果version设置为-1的话,就删除所有的版本。
exists:判断Znode是否存在,设置是否Watch这个Znode。
get data:读取指定Znode上的数据,并设置是否watch这个Znode。
set data:更新指定Znode的数据,并设置是否Watch这个Znode。
get children:更新指定ZNode的数据,并设置是否Watch这个Znode。
sync:把sync之前的更新操作都同步过来。
set acl:设置指定ZNode的Acl信息
get acl:获取指定ZNode的Acl信息
其他
读、写(更新)模式:Zookeeper集群中,客户端可以从任意一个ZooKeeper服务器读取,这一特点保证了ZooKeeper有比较好的读性能;
写的请求会先Forwarder到Leader,然后由Leader来通过ZooKeeper中的原子广播协议,将请求广播给所有的Follower,Leader收到一半以上的写成功的Ack后,就认为该写成功了,就会将该写进行持久化,并告诉客户端写成功了。
WAL(Write-Ahead-Log)和Snapshot:
ZooKeeper也有WAL,每一个更新操作,ZooKeeper都会先写WAL,然后再对内存中的数据做更新,最后向Client通知更新结果。
ZooKeeper还会定期将内存中的目录树进行Snapshot,落地到磁盘上。其实跟HDFS中的fsimage和edits log是类似的。这么做的主要目的,一当然是数据的持久化,二是加快重启之后的恢复速度,如果全部通过Replay WAL的形式恢复的话,会比较慢。
FIFO:
对于每一个ZooKeeper客户端而言,所有的操作都是遵循FIFO顺序的,这一特性是由下面两个基本特性来保证的:
一是ZooKeeper Client与Server之间的网络通信是基于TCP,TCP保证了Client/Server之间传输包的顺序;
二是ZooKeeper Server执行客户端请求也是严格按照FIFO顺序的。
线性化:
ZooKeeper包括全局有序和偏序两种:
全局有序是针对服务器端。例如:在一台服务器上消息A在消息B前发布,那么所有服务器上的消息A都将在消息B前被发布;
偏序是针对客户端。例如:在同一个客户端发送消息B在消息A后发布,那么执行的顺序必将是先执行消息A然后在是消息B;
所有的更新操作都有严格的偏序关系,更新操作都是串行执行的,这一点是保证ZooKeeper功能正确性的关键。
使用场景
1,数据发布与订阅2,名空间服务
3,分布式通知/协调
4,分布式锁
5,集群管理
等等。。。
参考:
http://zookeeper.apache.org/doc/trunk/zookeeperOver.html

相关文章推荐
- SQL实现循环每一行做一定操作。
- 2014.7.23 内存分析_栈_堆_栈帧
- 更新Debian内核e1000e驱动模块
- [LeetCode]Edit Distance
- Geometry类详解
- 【技♂巧】bzoj1257余数之和
- 实现多国语言的几个小知识
- swift可选链和类型转换
- 【学习笔记】分区表和分区索引——概念部分(一)
- [python]python子字符串的提取、字符串连接、字符串重复
- oracle function学习1
- 模拟迁途箭头圆圈
- ubuntu下创建、删除文件、文件夹,移动文件
- css层叠样式详解
- android View各属性详解
- 二叉搜索树-BST-查找算法-插入算法-删除算法 http://www.cnblogs.com/pangxiaodong/archive/2011/08/24/2151060.html
- 模拟迁途.html
- windows server做NTP时间服务器 及时间设置internet时间同步的方法
- 【实战Java高并发程序设计 2】无锁的对象引用:AtomicReference
- OSSIM下安装phpadmin全过程