hadoop2.6.2启动 发现DataNode没有启动启来
2015-11-24 22:02
429 查看
hadoop2.5.2 启动成功后,用jps查看:感觉少了DataNode

确实少了DataNode。
查看日志:

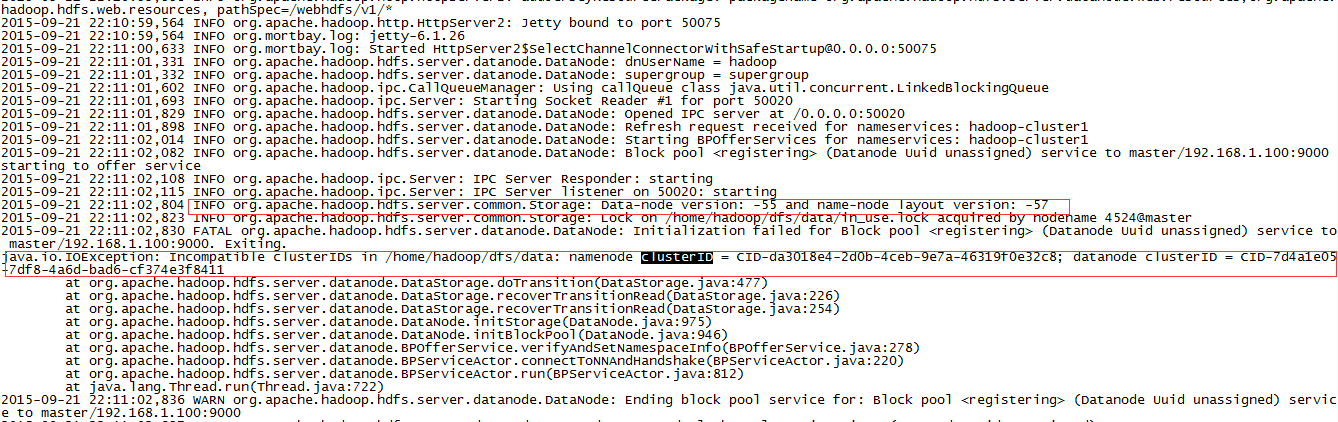
从日志上看,画线的部分说明了问题
datanode的clusterID 和 namenode的clusterID 不匹配。
解决办法:
根据日志中的路径,cd /home/hadoop/dfs
能看到 data和name两个文件夹,
将name/current下的VERSION中的clusterID复制到data/current下的VERSION中,覆盖掉原来的clusterID
让两个保持一致
->name/current/VERSION 中的 clusterID :CID-da3018e4-2d0b-4ceb-9e7a-46319f0e32c8
替换data/current/VERSION 中的 clusterID .
然后重启,启动后执行jps,查看进程
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID
保持不变。
确实少了DataNode。
查看日志:
从日志上看,画线的部分说明了问题
datanode的clusterID 和 namenode的clusterID 不匹配。
解决办法:
根据日志中的路径,cd /home/hadoop/dfs
能看到 data和name两个文件夹,
将name/current下的VERSION中的clusterID复制到data/current下的VERSION中,覆盖掉原来的clusterID
让两个保持一致
->name/current/VERSION 中的 clusterID :CID-da3018e4-2d0b-4ceb-9e7a-46319f0e32c8
替换data/current/VERSION 中的 clusterID .
然后重启,启动后执行jps,查看进程
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID
保持不变。

相关文章推荐
- Node.js(4) -- 七天学会node.js(2)
- node中的session和cookie备忘
- Node.js(3) -- 七天学会node.js
- node npm 安装时报错解决
- node笔记
- NodeJs概述
- 简单谈谈node.js 版本控制 nvm和 n
- 记一次hadoop datanode进程问题分析
- android编译分析之5—node_fns.mk
- 【LEETCODE】237-Delete Node in a Linked List
- 【Leetcode】Count Complete Tree Nodes
- Node.js 安装
- nodejs创建服务
- nodejs npm常用命令
- Node学习笔记
- Node.js开发框架Express4.x
- leetcode 19 :Remove Nth Node From End of List
- 浅谈Hadoop NameNode、SecondaryNameNode、CheckPoint Node和BackupNode
- 浅析Hadoop Secondary NameNode,CheckPoint Node,Backup Node
- nodejs-日常练习记录-使用express搭建static服务器.