C语言函数堆栈的思考
2015-11-24 19:08
369 查看
源于一段课程案例的代码,拿编译器编译一下,结果不对,反复查了一下,无意中把结果改出来了,于是修改代码探索原因。虽然还有一些地方不太明确的,先总结一笔。
源码是这样的:
粗看一下,会以为pass函数是多余的,结果不就是打印出来个1吗?其实不然,结果是0。
要理解这段代码,不得不从汇编的层面入手,先贴汇编上面两个函数的代码。
Linux下采用gcc进行编译,汇编代码如下:
补充说明一下,内存结构:
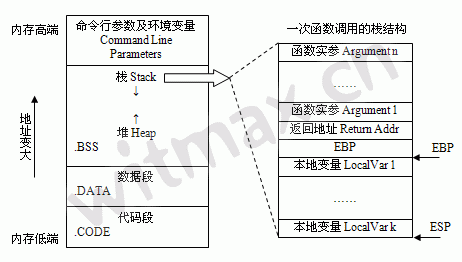
内存中的堆栈结构
BSS段:BSS段(bss segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
数据段:数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
代码段:代码段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
栈(stack):栈又称堆栈, 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
main函数调用pass函数后,内存栈如下:
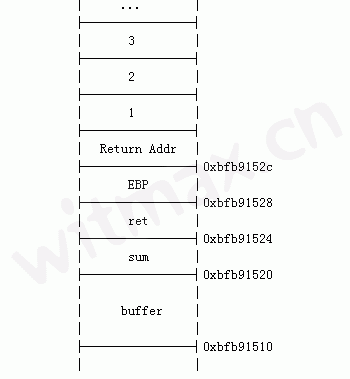
pass函数被调用后的栈结构
上图中的地址通过gdb调试获得。其中返回地址Return Addr的值为0x080483f8,即指向调用pass()函数命令的后一行命令x=1;
在pass()函数中,ret = (int*)(buffer+28);获取了存放返回地址的内存空间地址,通过(*ret) += 7;使得pass()函数返回地址加了7,这样pass()函数返回后程序正好跳过了x=1; 命令,接着运行printf命令,所以结果最后显示为0。
以上将(*ret) += 7;改为(*ret) += 8;或(*ret) += 9;或(*ret) += 10;,结果都显示6,即pass()函数的返回结果。猜测是程序运行时有命令检查,+8和+9时返回后的命令皆不完整,直接跳到下一个可执行的命令,所以结果同+10的情况。(*ret) += 10;跳过了将变量x的值赋给寄存器%eax的命令,这样%eax寄存器中保留着之前pass()函数的运算结果6,后面两行命令是将寄存器%eax的结果显示出来,于是printf显示6;于是,(*ret) += 10;相当于跳过了给printf传递参数的命令。
对于栈中变量的存放顺序,通过实验做了研究,通过调整sum、ret和buffer的定义代码顺序即可,发现buffer地址总是低于sum和ret的地址,而sum和ret的地址是定义的早的位于低地址。可能与类型有关,有待查证。
另外在Windows XP上用MinGW进行了编译,结果差异较大,留待以后再去研究。
源码是这样的:
要理解这段代码,不得不从汇编的层面入手,先贴汇编上面两个函数的代码。
Linux下采用gcc进行编译,汇编代码如下:
内存中的堆栈结构
BSS段:BSS段(bss segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
数据段:数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
代码段:代码段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
栈(stack):栈又称堆栈, 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
main函数调用pass函数后,内存栈如下:
pass函数被调用后的栈结构
上图中的地址通过gdb调试获得。其中返回地址Return Addr的值为0x080483f8,即指向调用pass()函数命令的后一行命令x=1;
在pass()函数中,ret = (int*)(buffer+28);获取了存放返回地址的内存空间地址,通过(*ret) += 7;使得pass()函数返回地址加了7,这样pass()函数返回后程序正好跳过了x=1; 命令,接着运行printf命令,所以结果最后显示为0。
以上将(*ret) += 7;改为(*ret) += 8;或(*ret) += 9;或(*ret) += 10;,结果都显示6,即pass()函数的返回结果。猜测是程序运行时有命令检查,+8和+9时返回后的命令皆不完整,直接跳到下一个可执行的命令,所以结果同+10的情况。(*ret) += 10;跳过了将变量x的值赋给寄存器%eax的命令,这样%eax寄存器中保留着之前pass()函数的运算结果6,后面两行命令是将寄存器%eax的结果显示出来,于是printf显示6;于是,(*ret) += 10;相当于跳过了给printf传递参数的命令。
对于栈中变量的存放顺序,通过实验做了研究,通过调整sum、ret和buffer的定义代码顺序即可,发现buffer地址总是低于sum和ret的地址,而sum和ret的地址是定义的早的位于低地址。可能与类型有关,有待查证。
另外在Windows XP上用MinGW进行了编译,结果差异较大,留待以后再去研究。

相关文章推荐
- C++静态分析工具
- C++ 文件里面调用C文件里面的函数——extern "C" 用法解析
- C++标准库Vector & Iterator
- C语言中快速排序和插入排序优化的实现
- 【C语言】【指针相关知识小结】
- C++primer plus第六版课后编程练习答案3.7
- C语言实现链表之双向链表(十五)测试用例
- C语言实现链表之双向链表(十四)链表打印
- C语言实现链表之双向链表(十三)获取数据对应的结点
- C语言实现链表之双向链表(十二)判断链表是否为空和获取链表长度
- C++屏蔽Windows中文输入法
- C++primer plus第六版课后编程练习答案3.5
- C语言实现链表之双向链表(十一)设置结点数据与获取结点数据
- C语言实现链表之双向链表(十)删除任意结点
- C语言两个int量相除,怎么能输出一个两个小数点的数字?
- C语言实现链表之双向链表(九)在任意位置插入结点
- C语言实现链表之双向链表(八)删除尾结点
- C语言实现链表之双向链表(七)尾结点后插入结点
- c和C++main函数中参数的意义和用法
- C语言实现链表之双向链表(六)删除头结点