ClustLib——A C++ Data Clustering Framework(一):数据集相关类设计
2015-11-18 23:35
218 查看
数据(Data)是一个聚类算法(a clustering algorithm)的重要组成部分,不然所聚为何物呀,也是聚类算法的处理对象和意图。因此在设计和实现聚类算法之前,我们需要进行数据的设计与实现(存储数据的结构及相关类的关系)。
本文作为 C++ 数据聚类框架的 ClustLib 系列的第一篇文章,我们首先进行基础类(Foundation Classes),也即数据集(datasets)的设计与实现。在数据聚类的相关文献中,一个数据集(dataset)是记录(record)的集合(a collection of records),而一个记录又被属性(attributes)所描述(characterized by a set of attributes),正如本文的第一幅图表所示。
从一张最终呈现出来的表(table,代表数据集),来建立起表中元素与代码中不同类的对应关系(采用面向对象的方式)。

我们先来看客户端程序,进一步思考如何进行类和接口的设计。我们来对如下形式的数据集进行数据结构(也即面向对象中的类)的设计:
为了实现对属性(Attributes)的抽象,我们设计了四个基础类(Foundation Classes),分别为:AttrValue,AttrInfo,CAttrInfo 以及 DAttrInfo。其UML类图如下所示:
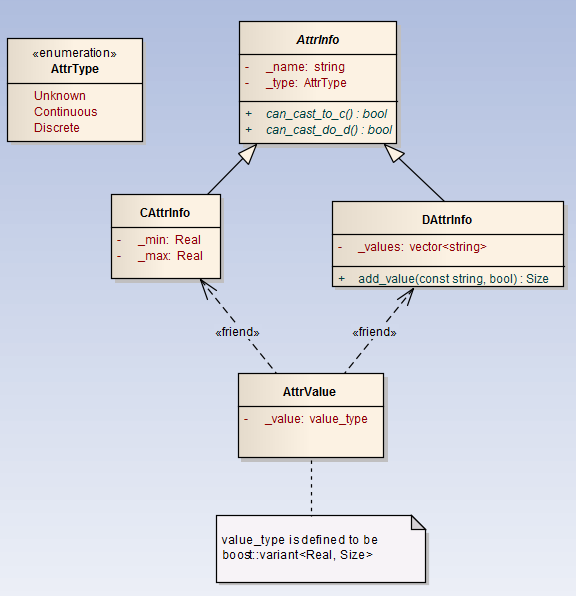
AttrInfo 类的说明:
用来操作属性值
属于操纵类;
该类代表属性信息,而非属性本身
也即本身不持有值内容
所以当涉及 AttrInfo 的比较(乃至CAttrInfo/DAttrInfo 的比较时)
并不涉及值的(内容的)比较,更多的是比如属性名,属性类型,此类的抽象层面的比较;
真正的保存值的类在 AttrValue
本文作为 C++ 数据聚类框架的 ClustLib 系列的第一篇文章,我们首先进行基础类(Foundation Classes),也即数据集(datasets)的设计与实现。在数据聚类的相关文献中,一个数据集(dataset)是记录(record)的集合(a collection of records),而一个记录又被属性(attributes)所描述(characterized by a set of attributes),正如本文的第一幅图表所示。
从一张最终呈现出来的表(table,代表数据集),来建立起表中元素与代码中不同类的对应关系(采用面向对象的方式)。
客户端程序
我们先来看客户端程序,进一步思考如何进行类和接口的设计。我们来对如下形式的数据集进行数据结构(也即面向对象中的类)的设计:
#include <boost/shared_ptr.hpp>
#include "./datasets/dataset.hpp"
using namespace std;
using namespace ClusLib;
int main(int, char**)
{
// 首先创建所谓的模式Schema
// 如同我们在word中建一张表,先建的是表头,
// Schema类继承自Container<boost::shared_ptr<AttrInfo>>
// 为显示提供其构造函数
boost::shared_ptr<Schema> schema(new Schema);
boost::shared_ptr<DAttrInfo> labelInfo(new DAttrInfo("Label")); // 标签列,也即上例中的最后一列
boost::shared_ptr<DAttrInfo> idInfo(new DAttrInfo("Identifier"));
return 0;
}属性(Attributes)
一个属性(Attribute)标识一条记录中的一个独立的成分。我们可将属性分为四类(four categories):ratio,interval,ordinal 以及 nominal。我们可以使用一个实数(a real number)存储一个 ratio 或者 interval 型属性,使用一个整数(integer)来存储一个 ordinal 或者 nominal 型属性。为了实现对属性(Attributes)的抽象,我们设计了四个基础类(Foundation Classes),分别为:AttrValue,AttrInfo,CAttrInfo 以及 DAttrInfo。其UML类图如下所示:
AttrInfo 类的说明:
用来操作属性值
属于操纵类;
该类代表属性信息,而非属性本身
也即本身不持有值内容
所以当涉及 AttrInfo 的比较(乃至CAttrInfo/DAttrInfo 的比较时)
并不涉及值的(内容的)比较,更多的是比如属性名,属性类型,此类的抽象层面的比较;
bool AttrInfo::equal_shallow(const AttrInfo& ai) const
{
return _name == ai.name() && _type == ai.type();
}
bool CAttrInfo::euqal(const AttrInfo& ai) const
{
return equal_shallow(ai) && ai.can_cast_to_c();
}真正的保存值的类在 AttrValue
记录(Record)
需要依靠Schema才能建立。
数据集(Dataset)
也是需要Schema才能建立。

相关文章推荐
- 使用C++实现JNI接口需要注意的事项
- 关于指针的一些事情
- c++ primer 第五版 笔记前言
- share_ptr的几个注意点
- Lua中调用C++函数示例
- Lua教程(一):在C++中嵌入Lua脚本
- Lua教程(二):C++和Lua相互传递数据示例
- C++联合体转换成C#结构的实现方法
- C++编写简单的打靶游戏
- C++ 自定义控件的移植问题
- C++变位词问题分析
- C/C++数据对齐详细解析
- C++基于栈实现铁轨问题
- C++中引用的使用总结
- 使用Lua来扩展C++程序的方法
- C++中调用Lua函数实例
- Lua和C++的通信流程代码实例
- C与C++之间相互调用实例方法讲解
- 解析C++中派生的概念以及派生类成员的访问属性
- C++ Custom Control控件向父窗体发送对应的消息