oracle 11g RAC 的一些基本概念(二)
2015-11-14 11:52
411 查看
集群的相关概念
配置Active/active集群
在这种模式下,所有的节点都能提供服务(不会有用户请求在standby上被闲置的情况)。大部分案例中,集群成员的硬件配置都是相同的,避免可能的性能问题,也更容易实现负载均衡。Active/active集群需要更复杂的管理软件来管理所有资源,比如磁盘和内存需要在所有节点间进行同步。更常见的,一个私有网络被用做心跳连接。集群管理软件必须能够检测到节点问题,比如节点故障或者集群通讯问题脑裂(split-brain)是集群中的一个糟糕的情况:集群中的所有集群正在工作的时候,内部通讯被断开。这种情况下,集群被分成了几个部分,每个部分的集群软件都会尝试去接管其他节点的资源,因为在它看来,别的节点发生了故障。可能会出现以下问题:如果应用能够正常连接集群的这些部分,因为此时这些集群部分不同步,可能会有不同的数据会被写入到磁盘中。脑裂对集群的危害显而易见,集群软件的供应商必须提供方案来解决这个问题
oracle的集群软件(11g中的Grid Infrastructure),使用一个仲裁设备(quorum device),称作voting disk,来决定集群中的成员。集群中的所有节点共享一个voting disk,当一个节点不能向内部网络和voting disk发送心跳时,它就会被逐出集群。若一个节点不能和其他节点通讯,但依然能连接到voting disk,集群在这种情况下将进行投票,并发出指令将该节点剔除。这个投票使用的是STONITH方式,软件将发出一个请求,使被踢出的节点自动重启。当需要重启的节点hung住的时候,重启指令变得不可用,这种情况比较棘手。幸运的是,若硬件允许,Grid
Infrastructure可以支持IPMI(智能平台管理接口),可以向一个节点发出结束指令。当一个节点故障或被踢出集群,剩余的节点能够接管用户服务请求。
配置Active/passive集群
一个active/passive集群工作方式与active/active不同。一个active/passive集群中的成员硬件配置依然应该一致或基本一致,但同一时间两个节点中只有一个节点能处理用户请求。集群管理软件会不断地监控集群中资源的健康状况,当一个资源失败,集群管理软件会尝试将该资源重启数次,若还是无效,备用节点将进行接管。根据安装时的选项,集群的资源可以分配在共享存储或文件系统上,后者在资源failover的时候也会进行一次failover。使用共享文件系统比使用非共享的文件系统更有优势,后者在重新挂载到standby节点上以前可能需要进行fsck(8)检测。Veritas集群套件、Sun(Oracle)集群和IBM的HACMP就可用作安装active/passive集群的集群管理工具。
鲜为人知的是,使用Oracle Grid Infrastructure来安装一个active/passive集群非常简单,利用Grid Infrastructure的应用程序接口和作为集群逻辑卷管理器的Oracle ASM,可以轻松地不间断监控一个单实例oracle数据库。当一个节点发生故障,数据库会自动迁移到备用节点。根据初始化参数fast_start_mttr_target和恢复集的大小,这个故障切换可能非常迅速。不过,作为failover过程的一部分,用户的数据库连接将被断开。
Active/passive模式可以通过将active_instance_count参数设置为1来打开,但仅当节点数为2时才有效。
配置Shared-All架构
一个所有节点同时访问共享存储和数据的集群被称为shared-all或者shared-everything结构。Oracle RAC就是基于shared-everything架构:一个数据库位于共享存储中,通过集群各个节点上运行的实例来访问。在Oracle术语中,一个实例由内存结构和一些进程组成。对应的,数据库存储在磁盘中的数据文件里。在RAC中,实例的故障并不意味着该实例管理的数据的丢失。在一个节点发生故障后,集群中的另一个实例将会进行实例恢复,所有剩余节点都将继续服务。使用高可用技术,例如FCF或TAF,可以将实例失效对用户造成的影响降到最低。故障节点最后将重新加入集群并分担工作量。配置Shared-Nothing架构
在一个shared-nothing数据库集群中,每个节点有它私有的独立存储,其他节点不能访问。数据库被集群中的节点分割成几个部分,返回的查询结构集是各个节点结果集的结合。丢失一个节点会导致对应的数据无法访问。因此,一个shared-noting集群经常被实施成一些单独的active/passive或者active/active集群来增强可用性。MySQL的集群就是基于shared-nothing架构。RAC的主要概念
集群节点
集群由单独的节点组成,在Oracle RAC中,允许的节点数和集群版本有关,公开文档中说明Oracle 10.2集群软件支持100个节点,而10.1支持63个实例。即使当个节点发生故障后,基于RAC上的应用能继续运行,还是应该花点精力来确认数据库服务器中的单个组件不会出现单点故障(SPOF)。采购新的硬件时应该采用可热插拔的组件,比如内置磁盘和风扇,另外,服务器的电力供给、主机总线适配器、网卡和硬盘都应该做了冗余。可能的话,最好做一个逻辑绑定,比如硬盘硬件RAID或软件RAID、网卡绑定、存储网络的多路径。在数据中心也应该注意:要使用不间断的电源供应、足够的散热措施、服务器的专业上架。最好还能有个远程的lights-out管理控制台,当一个节点不知道由什么原因挂起,可能迫切需要进行故障排除或者重启。
内部互联
集群内部互联是Oracle RAC的特征之一。它不仅使得集群在不同实例间传递数据块时突破block pinging算法的限制,它还可用作心跳和常规通讯。连接失败将导致集群的重组来避免脑裂发生,Grid Infrastructure将使一个或多个节点重启。可以为RAC和Grid Infrastructure配置一个单独的连接,这种情况下你需要配置RAC来使用正确的连接。这个连接始终应该是私有的,不应该受到其他网络的干扰。RAC用户可以使用两种技术来实现内部互联:以太网和Infiniband。使用基于以太网的内部互联
使用10G以太网作为集群内部互联可能是目前使用最多的,集群的后台进程使用TCP/IP进行通信。Cache Fusion(用来保持缓存的一致性)使用另一种通信方式:UDP(UserData该ramProtocol)。UPD和TCP同属于传输层,后者面向连接,使用显式的通讯握手来保证网络数据包按顺序到达,并转发失败的数据包。UDP则不包含状态,它是一个发完就忘(fire-and-forget)协议。UDP只是简单发送一个数据包到目的地。UDP比起TCP而言主要的好处是它比较轻便。注意:两节点集群间应该避免使用交叉线来直连,集群的内部通讯必须经过交换,交叉电缆的使用应该被明确禁止!
使用jumbo frames可以使集群内部通信的效率和性能得到提升。Ethernet Frames可以使用不同的大小,一般被限制在1500byte字节(MTU值)。框架大小决定了单个以太网框架能够传送多少数据,一个框架承受越大的数据负荷,服务器和交换机需要做的工作就越少,提供了更高的通讯效率。许多交换机允许在一个框架中容纳比标准MTU值更大的字节数(1500-9000),也叫jumbo
frame。注意jumbo frames是不能路由的,因此它不能被使用在公共网络上。当决定使用jumbo frames时,一定要确定集群中的所有节点使用同样的MTU。
刚才说过数据库服务器的相关组件应该有一个容易,网卡也是其中之一。多个网络端口可以在linux中使用bonding技术绑成一个逻辑单位,和很多其他操作系统不同,linux中网卡的绑定不需要购买其他软件就能实现。
使用基于Infiniband的内部互联
Infiniband常被用来实现远程内存直接访问(RDMA remote direct memory access architecture)。这是一个高速互联,常与高性能计算(HPC)环境联系在一起。RDMA可以在集群的节点间使用并行、直接、内存到内存的传输,它需要专门的RDMA适配器、交换机和软件。它还能避免基于以太网的实现中的CPU处理和环境转换的开支。在linux中有两种途径来实现Infiniband互联。第一种叫做IP over Infiniband(IPoIB),它采用IB架构作为链路控制层,使用封装的方法实现IP和IB报文的转换,从而使在以太网运行的程序可以直接运行在Infiniband上。另一个方法就是使用基于Infiniband的 ReliableDatagram Sockets,oracle 1.2.0.3开始支持这个方法。RDS可以通过Open Fabric Enterprise Distribution(OFED)在linux和windows上实现。RDS的重要特征是低延迟、低开销和高带宽。Oracle数据库服务器和Exadata存储服务器使用了Infiniband,为集群内的通讯提供高达40Gb/s的带宽,这是以太网所不可能做到的。Infiniband为高性能展现了巨大的优势,但它的成本同样非常高昂。
Clusterware/Grid Infrastructure
Grid Infrastructure与操作系统紧密结合,并提供以下服务:节点间连接;维护集群成员;消息传送;集群逻辑卷管理;隔离(fencing)************************************************************************************************************************************************************************************************
I/O隔离:
当集群系统出现"脑裂"问题的时候,我们可以通过"投票算法"来解决谁获得集群控制权的问题。 但是这样是不够的,我们还必须保证被赶出去的结点不能操作共享数据。 这就是IO Fencing 要解决的问题。
IO Fencing实现有硬件和软件2种方式:
软件方式:对于支持SCSI Reserve/Release 命令的存储设备, 可以用SG命令来实现。 正常的节点使用SCSI Reserve命令"锁住"存储设备, 故障节点发现存储设备被锁住后,就知道自己被赶出了集群,也就是说自己出现了异常情况, 就要自己进行重启,以恢复到正常状态。 这个机制也叫作 Sicide(自杀). Sun 和Veritas 使用的就是这种机制。
硬件方式:STONITH(Shoot The Other Node in the Head), 这种方式直接操作电源开关,当一个节点发生故障时,另一个节点如果能侦测到,就会通过串口发出命令,控制故障节点的电源开关,通过暂时断电,而又上电的方式使故障节点被重启动, 这种方式需要硬件支持。
************************************************************************************************************************************************************************************************
各个版本的Oracle集群软件的命名如下:
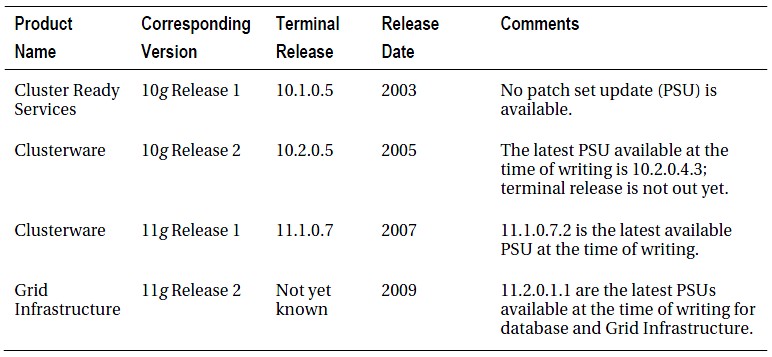
进程结构
安装结束后,会产生一些后台进程来确保集群正常工作并能够与外部通讯。其中的一些有序linux平台的要求需要以root用户权限来启动。比如,网络配置的改动就需要更高的权限。其他后台进程将以grid软件所在系统用户的权限来运行。下面的表格介绍主要的一些后台进程| 后台进程 | 说明 |
| Oracle高可用服务 (OHAS) | OHAS是服务器启动后打开的第一个Grid Infrastructure组件。它被配置为以init(1)打开,并负责生成agent进程。 |
| Oracle Agent | Grid Infrastructure使用两个oracle代理进程。第一个,概括起来说,负责打开一些需要访问OCR和VOTING文件的资源。它由OHAS创建。 第二个代理进程由CRSD创建,负责打开所有不需要root权限来访问的资源。这个进程以Grid Infrastructure所属用户的权限运行,并且负责在RAC11.1中racg所做的工作。 |
| Oracle Root Agent | 和 Oracle 代理进程类似,有两个Root 代理进程被创建。 最初的代理进程由OHAS引发,它为linux系统中需要更高权限的资源提供初始化。创建的主要后台进程是CSSD和CRSD。反过来,CRSD将触发另一个root代理。这个代理将打开需要root权限、主要和网络相关的资源 |
| 集群就绪服务进程 (CRSD) | 集群软件的后台主要进程,使用oracle集群注册信息来管理集群中的资源 |
| 集群同步服务进程 (CSSD) | 管理集群的配置和节点成员 |
| Oracle进程监控 (OPROCD) | oprocd在11.1版本中负责 I/O 隔离。它是在10.2.0.4补丁集中为linux系统引入的。在这个补丁集以前,内核hangcheck-timer 模块来做类似的任务。有趣的是,oprocd以前常被用在非linux平台中。Grid Infrastructure用cssdagent进程来替换了oprocd进程。 |
| 事件管理器(EVM) | EVM负责发布Grid Infrastructure创建的事件 |
| 集群时间同步服务(CTSS) | CTSS服务是一个可选项,通过网络时间协定服务器为集群提供时间同步,这个时间同步对RAC很重要。它可以运行在两种模式下:观望或者活动。当NTP被激活的时候,它运行在观察模式,若没有启动NTP,它将根据主节点同步所有节点的时间。 |
| Oracle警告服务(ONS) | 负责通过快速应用框架发布事件的主要后台进程。 |
以下是11.2中Grid Infrastructure的一些主要后台进程:
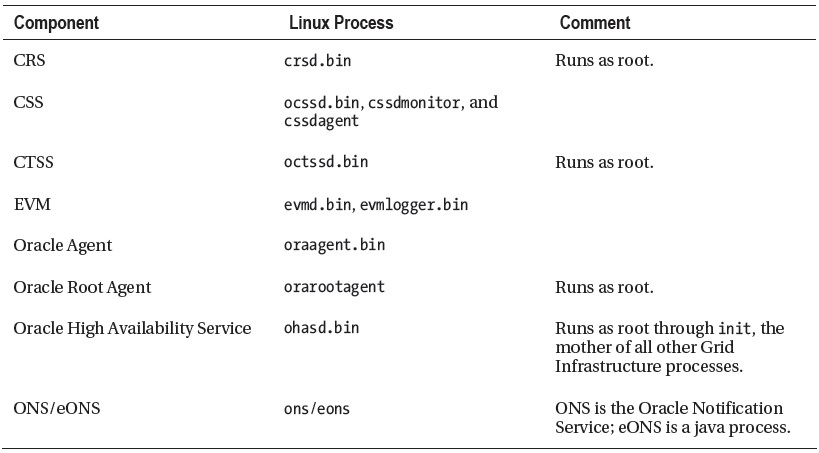
配置网络组件
Grid Infrastructure需要一些IP地址来正常工作:每个主机配备一个公共网络地址;每个主机有一个私有网络地址;每个主机一个虚拟IP地址(未被指派);1-3个未指派的IP地址用于Single Client Access Name特性;若使用了Grid即插即用,还需要一个未使用的虚拟IP分配给Grid命名服务。节点虚拟IP是Oracle集群的最有用的功能之一。它们需要和公共IP配置在一个网段内,并作为Grid Infrastructure中的集群资源来维护。在9i中的时候,当一个节点发生故障,该公共IP无法响应连接请求。当一个客户端会话尝试连接到这个故障节点时,它必须等待到连接超时,这可能是一个漫长的过程。有了虚拟IP,那就快多了:当一个节点故障,Grid Infrastructure将该节点的虚拟IP地址failover到集群中的另一个节点上。当一个客户端会话连接到故障节点的虚拟IP,Grid
Infrastructure知道这个节点不能正常工作,会让它连接到集群中的下一个节点。另一个需求是1-3个IP地址,不管集群有多大,这个要求是Grid Infrastructure中新增的,这种地址类型称为SCAN(single client access name)。SCAN在Grid Infrastructure升级或安装时创建并配置,在执行安装以前,你需要将这些SCAN IP地址添加到DNS中来循环解析。如果你使用Grid命名服务(GNS),你需要在公共网络上为它分配一个虚拟IP地址。
摘自Pro Oracle database 11g RAC on linux

相关文章推荐
- 1. Oracle概念笔记一序言
- 关于oracle upgrade与migration的文档
- 初学者Oracle 11g安装常见错误
- oracle 行转列
- Oracle EBS Form Builder使用Java beans创建窗体
- java下实现调用oracle的存储过程和函数
- Oracle 11g R2通过透明网关连接DB2 详细步骤
- MySQL、SqlServer、Oracle三大主流数据库分页查询
- Oracle常见的几种等待事件
- oracle scn和headroom
- oracle 9i windows 客户端连接报ora-12535问题小结
- oracle 11.2.0.3 rac hanganalyze 案例
- oracle sql与调优
- oracle不用tsname文件的时候着怎么办
- Oracle使用触发器实例
- oracle 拆分输出dbms_output.put_line longValue解决
- ORACLE修改表空间方法
- 记录一次rolling mode给oracle打补丁
- 自己动手 CentOS-6.5 安装Oracle11g R2
- ORACLE 多表连接与子查询