02.ZooKeeper的Java客户端使用
2015-10-30 16:42
495 查看
1.ZooKeeper常用客户端比较
1.ZooKeeper常用客户端 zookeeper的常用客户端有3种,分别是:zookeeper原生的、Apache Curator、开源的zkclient,下面分别对介绍它们:zookeeper自带的客户端是官方提供的,比较底层、使用起来写代码麻烦、不够直接。
Apache Curator是Apache的开源项目,封装了zookeeper自带的客户端,使用相对简便,易于使用。
zkclient是另一个开源的ZooKeeper客户端,其地址:https://github.com/adyliu/zkclient生产环境不推荐使用。
zookeeper原生客户端Maven地址:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>
[/code]Apache Curator的Maven地址:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.9.0</version>
</dependency>
[/code]zkclient的Maven地址:
<dependency>
<groupId>com.github.adyliu</groupId>
<artifactId>zkclient</artifactId>
<version>2.1.1</version>
</dependency>
[/code]2.三种ZooKeeper客户端比较
由于Apache Curator是其中比较完美的ZooKeeper客户端,所以主要介绍Curator的特性来进行比较!Curator几个组成部分1.Client: 是ZooKeeper客户端的一个替代品, 提供了一些底层处理和相关的工具方法2.Framework: 用来简化ZooKeeper高级功能的使用, 并增加了一些新的功能, 比如管理到ZooKeeper集群的连接, 重试处理3.Recipes: 实现了通用ZooKeeper的recipe, 该组件建立在Framework的基础之上4.Utilities:各种ZooKeeper的工具类5.Errors: 异常处理, 连接, 恢复等6.Extensions: recipe扩展
Curator主要解决了三类问题
1.封装ZooKeeper client与ZooKeeper server之间的连接处理2.提供了一套Fluent风格的操作API3.提供ZooKeeper各种应用场景(recipe, 比如共享锁服务, 集群领导选举机制)的抽象封装
Curator列举的ZooKeeper使用过程中的几个问题
初始化连接的问题: 在client与server之间握手建立连接的过程中,如果握手失败,执行所有的同步方法(比如create,getData等)将抛出异常
自动恢复(failover)的问题: 当client与一台server的连接丢失,并试图去连接另外一台server时, client将回到初始连接模式
session过期的问题: 在极端情况下,出现ZooKeeper session过期,客户端需要自己去监听该状态并重新创建ZooKeeper实例
对可恢复异常的处理:当在server端创建一个有序ZNode,而在将节点名返回给客户端时崩溃,此时client端抛出可恢复的异常,用户需要自己捕获这些异常并进行重试
使用场景的问题:Zookeeper提供了一些标准的使用场景支持,但是ZooKeeper对这些功能的使用说明文档很少,而且很容易用错.在一些极端场景下如何处理,zk并没有给出详细的文档说明.比如共享锁服务,当服务器端创建临时顺序节点成功,但是在客户端接收到节点名之前挂掉了,如果不能很好的处理这种情况,将导致死锁
Curator主要从以下几个方面降低了zk使用的复杂性
1.重试机制:提供可插拔的重试机制, 它将给捕获所有可恢复的异常配置一个重试策略,并且内部也提供了几种标准的重试策略(比如指数补偿)2.连接状态监控: Curator初始化之后会一直的对zk连接进行监听, 一旦发现连接状态发生变化, 将作出相应的处理3.zk客户端实例管理:Curator对zk客户端到server集群连接进行管理.并在需要的情况, 重建zk实例,保证与zk集群的可靠连接4.各种使用场景支持:Curator实现zk支持的大部分使用场景支持(甚至包括zk自身不支持的场景),这些实现都遵循了zk的最佳实践,并考虑了各种极端情况
Curator声称的一些亮点
1.日志工具
内部采用SLF4J 来输出日志
采用驱动器(driver)机制, 允许扩展和定制日志和跟踪处理
提供了一个TracerDriver接口, 通过实现addTrace()和addCount()接口来集成用户自己的跟踪框架
2.和Curator相比, 另一个ZooKeeper客户端——zkClient的不足之处
文档几乎没有
异常处理弱爆了(简单的抛出RuntimeException)
重试处理太难用了
没有提供各种使用场景的实现
3.对ZooKeeper自带客户端(ZooKeeper类)的"抱怨"只是一个底层实现
要用需要自己写大量的代码
很容易误用
需要自己处理连接丢失, 重试等
2.ZooKeeper原生客户端基本使用
1.ZooKeeper自带客户端API介绍 ZooKeeper自带客户端的主要类是ZooKeeper类,下面介绍ZooKeeper API的使用:ZooKeeper类的构造方法如下:

从上图可知创建ZooKeeper类对象除了需要ZooKeeper服务端连接字符串(IP地址:端口),还必须提供一个Watcher对象。Watcher是一个接口,当服务器节点花发生变化就会以事件的形式通知Watcher对象。所以Watcher常用来监听节点,当节点发生变化时客户端就会知道。
ZooKeeper类还有对节点进行增删改的操作方法,主要方法如下:
create:用于创建节点,可以指定节点路径、节点数据、节点的访问权限、节点类型 delete:删除节点,每个节点都有一个版本,删除时可指定删除的版本,类似乐观锁。设置-1,则就直接删除节点。 exists:节点存不存在,若存在返回节点Stat信息,否则返回null getChildren:获取子节点 getData/setData:获取节点数据 getACL/setACL:获取节点访问权限列表,每个节点都可以设置访问权限,指定只有特定的客户端才能访问和操作节点。在这些方法中的boolean watch参数表示是否监听当前节点(使用的监听Watcher就是构造ZooKeeper对象时的watcher),而方法中的Watcher watcher参数则是使用指定的watcher来监听当前节点。ZooKeeper类所有的方法如下图:
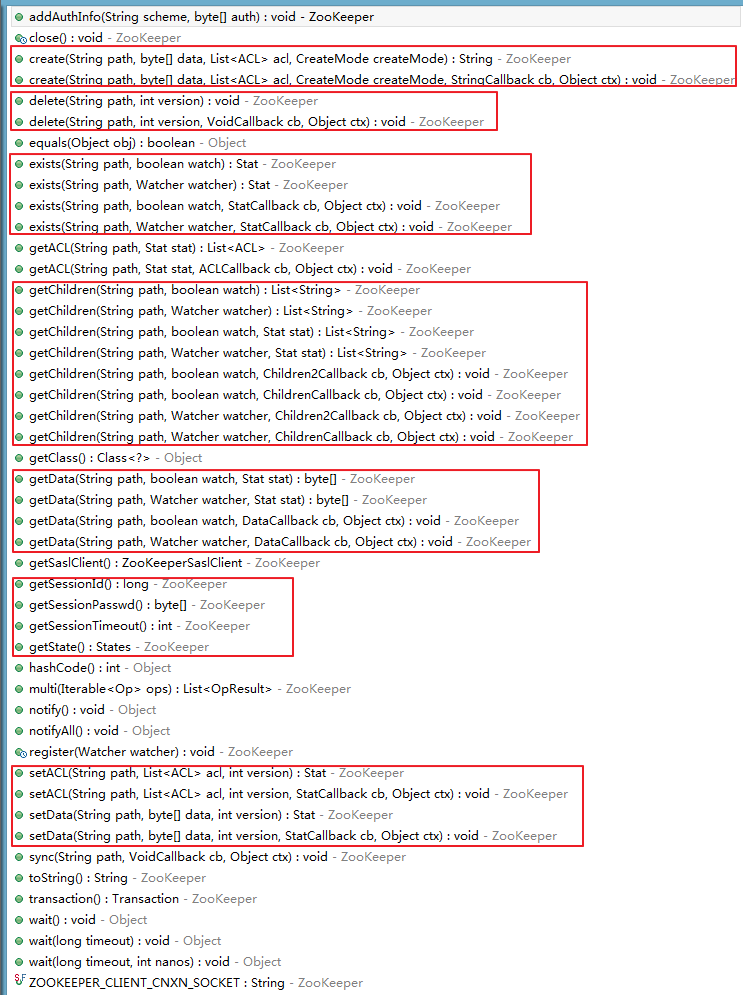
2.ZooKeeper自带客户端的简单操作示例
public static void main(String[] args) throws IOException, KeeperException, InterruptedException
{// 创建一个与服务器的连接 需要(服务端的 ip+端口号)(session过期时间)(Watcher监听注册)
ZooKeeper zk = new ZooKeeper("192.168.110.100:2181", 3000, new Watcher(){// 监控所有被触发的事件
public void process(WatchedEvent event)
{System.out.println(event.toString());
}
});
System.out.println("OK!");// 创建一个目录节点
/**
* CreateMode:
* PERSISTENT (持续的,相对于EPHEMERAL,不会随着client的断开而消失)
* PERSISTENT_SEQUENTIAL(持久的且带顺序的)
* EPHEMERAL (短暂的,生命周期依赖于client session)
* EPHEMERAL_SEQUENTIAL (短暂的,带顺序的)
*/
zk.create("/path01", "data01".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);// 创建一个子目录节点
zk.create("/path01/path01", "data01/data01".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);System.out.println(new String(zk.getData("/path01", false, null)));// 取出子目录节点列表
System.out.println(zk.getChildren("/path01", true));// 创建另外一个子目录节点
zk.create("/path01/path02", "data01/data02".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);System.out.println(zk.getChildren("/path01", true));// 修改子目录节点数据
zk.setData("/path01/path01", "data01/data01-01".getBytes(), -1);byte[] datas = zk.getData("/path01/path01", true, null);String str = new String(datas, "utf-8");
System.out.println(str);
// 删除整个子目录 -1代表version版本号,-1是删除所有版本
zk.delete("/path01/path01", -1);zk.delete("/path01/path02", -1);zk.delete("/path01", -1);System.out.println(str);
Thread.sleep(15000);
zk.close();
System.out.println("OK");}
[/code]节点类型说明:节点类型有4种:“PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、EPHEMERAL_SEQUENTIAL”其中“EPHEMERAL、EPHEMERAL_SEQUENTIAL”两种是客户端断开连接(Session无效时)节点会被自动删除;“PERSISTENT_SEQUENTIAL、EPHEMERAL_SEQUENTIAL”两种是节点名后缀是一个自动增长序号。节点访问权限说明:节点访问权限由List<ACL>确定,但是有几个便捷的静态属性可以选择: Ids.CREATOR_ALL_ACL:只有创建节点的客户端才有所有权限 Ids.OPEN_ACL_UNSAFE:这是一个完全开放的权限,所有客户端都有权限 Ids.READ_ACL_UNSAFE:所有客户端只有读取的3.节点监听注意点
使用Watcher监听时需要注意:所有的节点监听触发一次之后就不会再触发,需要重新再设置监听。但是当多个客户端同时监听某个节点时,要是这个节点发生变化,所有的客户端都会被触发!
3.Apache Curator基本使用
此处只是简单的介绍Apache Curator,是能作为入门使用,后面的章节会深入介绍基于Apache Curator实现Zookeeper的各种应用场景。在实际的工作中建议使用Apache Curator。1.Curator使用示例public static void main(String[] args) throws Exception
{CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181", new RetryNTimes(10, 5000));client.start();// 连接
// 获取子节点,顺便监控子节点
List<String> children = client.getChildren().usingWatcher(new CuratorWatcher()
{@Override
public void process(WatchedEvent event) throws Exception
{System.out.println("监控: " + event);}
}).forPath("/");System.out.println(children);
// 创建节点
String result = client.create().withMode(CreateMode.PERSISTENT).withACL(Ids.OPEN_ACL_UNSAFE).forPath("/test", "Data".getBytes());System.out.println(result);
// 设置节点数据
client.setData().forPath("/test", "111".getBytes());client.setData().forPath("/test", "222".getBytes());// 删除节点
System.out.println(client.checkExists().forPath("/test"));client.delete().withVersion(-1).forPath("/test");System.out.println(client.checkExists().forPath("/test"));client.close();
System.out.println("OK!");}
[/code]CuratorFrameworkFactory工厂方法newClient()提供了一个简单方式创建实例。 而Builder提供了更多的参数控制。一旦你创建了一个CuratorFramework实例,你必须调用它的start()启动,在应用退出时调用close()方法关闭.
Curator框架提供了一种流式接口。 操作通过builder串联起来, 这样方法调用类似语句一样。2. CuratorFramework类重要方法说明create() 开始创建操作, 可以调用额外的方法(比如方式mode 或者后台执行background) 并在最后调用forPath()指定要操作的ZNode
delete() 开始删除操作. 可以调用额外的方法(版本或者后台处理version or background)并在最后调用forPath()指定要操作的ZNode
checkExists() 开始检查ZNode是否存在的操作. 可以调用额外的方法(监控或者后台处理)并在最后调用forPath()指定要操作的ZNode
getData() 开始获得ZNode节点数据的操作. 可以调用额外的方法(监控、后台处理或者获取状态watch, background or get stat) 并在最后调用forPath()指定要操作的ZNode
setData() 开始设置ZNode节点数据的操作. 可以调用额外的方法(版本或者后台处理) 并在最后调用forPath()指定要操作的ZNode
getChildren() 开始获得ZNode的子节点列表。 以调用额外的方法(监控、后台处理或者获取状态watch, background or get stat) 并在最后调用forPath()指定要操作的ZNode
inTransaction() 开始是原子ZooKeeper事务. 可以复合create, setData, check, and/or delete 等操作然后调用commit()作为一个原子操作提交
3.Curator事件监听后台操作的通知和监控可以通过ClientListener接口发布。你可以在CuratorFramework实例上通过addListener()注册listener。
client.getCuratorListenable().addListener(new CuratorListener()
{@Override
public void eventReceived(CuratorFramework client, CuratorEvent event) throws Exception
{System.out.println("事件: " + event);}
});
client.getConnectionStateListenable().addListener(new ConnectionStateListener()
{@Override
public void stateChanged(CuratorFramework client, ConnectionState newState)
{System.out.println("连接状态事件: " + newState);}
});
client.getUnhandledErrorListenable().addListener(new UnhandledErrorListener()
{@Override
public void unhandledError(String message, Throwable e)
{System.out.println("错误事件:" + message);}
});
[/code]其事件触发时间说明:CuratorListenable:当使用后台线程操作时,后台线程执行完成就会触发,例如:client.getData().inBackground().forPath("/test");后台获取节点数据,获取完成之后触发。
ConnectionStateListenable:当连接状态变化时触发。
UnhandledErrorListenable:当后台操作发生异常时触发。
CuratorListenable事件触发返回的数据如下:
事件类型 事件返回数据
CREATE getResultCode() and getPath()
DELETE getResultCode() and getPath()
EXISTS getResultCode(), getPath() and getStat()
GET_DATA getResultCode(), getPath(), getStat() and getData()
SET_DATA getResultCode(), getPath() and getStat()
CHILDREN getResultCode(), getPath(), getStat(), getChildren()
SYNC getResultCode(), getStat()
GET_ACL getResultCode(), getACLList()
SET_ACL getResultCode()
TRANSACTION getResultCode(), getOpResults()
WATCHED getWatchedEvent()
GET_CONFIG getResultCode(), getData()
RECONFIG getResultCode(), getData()
[/code]4.Curator其他功能介绍(1)命名空间 你可以使用命名空间Namespace避免多个应用的节点的名称冲突。 CuratorFramework提供了命名空间的概念,这样CuratorFramework会为它的API调用的path加上命名空间:
CuratorFramework client = CuratorFrameworkFactory.builder().namespace("MyApp") ... build();[/code](2)临时客户端 Curator还提供了临时的CuratorFramework:CuratorTempFramework,一定时间不活动后连接会被关闭。创建builder时不是调用build()而是调用buildTemp()。3分钟不活动连接就被关闭,你也可以指定不活动的时间。
CuratorTempFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")// 连接串.retryPolicy(new RetryNTimes(10, 5000))// 重试策略
.connectionTimeoutMs(100) // 连接超时
.sessionTimeoutMs(100) // 会话超时
.buildTemp(100, TimeUnit.MINUTES); // 临时客户端并设置连接时间
[/code]它只提供了下面几个方法:
public void close();
public CuratorTransaction inTransaction() throws Exception;
public TempGetDataBuilder getData() throws Exception;
[/code](3)Retry策略 retry策略可以改变retry的行为。 它抽象出RetryPolicy接口, 包含一个方法public boolean allowRetry(int retryCount, long elapsedTimeMs);。 在retry被尝试执行前, allowRetry()被调用,并且将当前的重试次数和操作已用时间作为参数. 如果返回true, retry被执行。否则异常被抛出。Curator本身提供了几个策略:ExponentialBackoffRetry:重试一定次数,每次重试sleep更多的时间
RetryNTimes:重试N次
RetryOneTime:重试一次
RetryUntilElapsed:重试一定的时间
-------------------------------------------------------------------------------------------------------------------------------
来自为知笔记(Wiz)

相关文章推荐
- The Maven Integration requires that Eclipse be running in a JDK
- java中求2+22+222+2222+22222.........
- 计算n月(天)的时间
- java数组
- java中的压缩流
- Java Sax解析xml
- 动态规划排线算法问题java语言实现 在一块电路板的上、下2端分别有n个接线柱。根据电路设计,要求用导线(i,π(i))将上端接线柱与下端接线柱相连
- Java解析XML汇总(DOM/SAX/JDOM/DOM4j/XPath)
- Java类中字段和方法的初始化顺序(包含static)
- 分配模块、通配符和动态方法调用
- Java 抽奖
- 递归算法(java)
- java io 写文件,包括追加写文件
- java serializable深入了解
- java this
- Java的clone方法 prototype
- Eclipsez安装GEF
- java接口
- Java抽象类和接口
- eclipse个版本的比较