【数据结构与算法】——交换排序
2015-10-20 23:12
239 查看
交换排序分为:冒泡排序和快速排序

2)通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小。另一部分记录的 元素值比基准值大。
3)此时基准元素在其排好序后的正确位置
4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
n)。但是在同一阶层的两个程序调用中,不会处理到原来数列的相同部份;因此,程序调用的每一阶层总共全部仅需要O(n)的时间(每个调用有某些共同的额外耗费,但是因为在每一阶层仅仅只有O(n)个调用,这些被归纳在O(n)系数中)。结果是这个算法仅需使用O(n logn)时间。
最坏的情况:若初始记录序列按关键字有序或基本有序,算法的时间复杂度退化为O(n*n)
> j。 交换a[j]和a[center_index],完成一趟快速排序。在中枢元素和a[j]交换的时候,很有可能把前面的元素的稳定性打乱,比如序列为5 3 3 4 3 8 9 10 11,现在中枢元素5和3(第5个元素,下标从1开始计)交换就会把元素3的稳定性打乱,所以快速排序是一个不稳定的排序算法,不稳定发生在中枢元素和a[j] 交换的时刻。
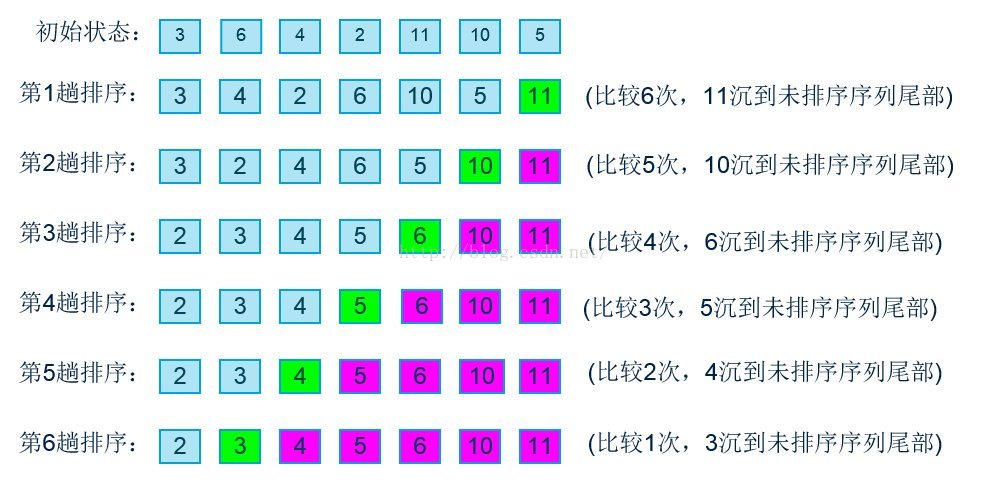
冒泡排序
基本思想:在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。
时间复杂度:
其中若记录序列的初始状态为"正序",则冒泡排序过程只需进行一趟排序,在排序过程中只需进行n-1次比较,且不移动记录;反之,若记录序列的初始状态为"逆序",则需进行n(n-1)/2次比较和记录移动。因此冒泡排序总的时间复杂度为O(n*n)。空间复杂度:
在排序过程中仅需要一个元素的辅助空间用于元素的交换,空间复杂度为O(1)。稳定性:
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。所以,如果两个元素相等,我想你是不会再无聊地把他们俩交换一下的;如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改变,所以冒泡排序是一种稳定排序算法。快速排序
基本思想:
1)选择一个基准元素,通常选择第一个元素或者最后一个元素,2)通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小。另一部分记录的 元素值比基准值大。
3)此时基准元素在其排好序后的正确位置
4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
时间复杂度
最好的情况:在最好的情况,每次我们执行一次分割,我们会把一个数列分为两个几近相等的片段。这个意思就是每次递回调用处理一半大小的数列。因此,在到达大小为一的数列前,我们只要作 logn 次巢状的调用。这个意思就是调用树的深度是O(logn)。但是在同一阶层的两个程序调用中,不会处理到原来数列的相同部份;因此,程序调用的每一阶层总共全部仅需要O(n)的时间(每个调用有某些共同的额外耗费,但是因为在每一阶层仅仅只有O(n)个调用,这些被归纳在O(n)系数中)。结果是这个算法仅需使用O(n logn)时间。
最坏的情况:若初始记录序列按关键字有序或基本有序,算法的时间复杂度退化为O(n*n)
空间复杂度:
O(logn)稳定性:
快速排序有两个方向,左边的i下标一直往右走,当a[i] <= a[center_index],其中center_index是中枢元素的数组下标,一般取为数组第0个元素。而右边的j下标一直往左走,当a[j] > a[center_index]。如果i和j都走不动了,i <= j,交换a[i]和a[j],重复上面的过程,直到i> j。 交换a[j]和a[center_index],完成一趟快速排序。在中枢元素和a[j]交换的时候,很有可能把前面的元素的稳定性打乱,比如序列为5 3 3 4 3 8 9 10 11,现在中枢元素5和3(第5个元素,下标从1开始计)交换就会把元素3的稳定性打乱,所以快速排序是一个不稳定的排序算法,不稳定发生在中枢元素和a[j] 交换的时刻。
