Hashtable 与HashMap的区别
2015-10-09 15:18
302 查看
哈希表的数据结构
哈希表是一个数组和链表的结合体(在数据结构称“链表散列“),如下图示:
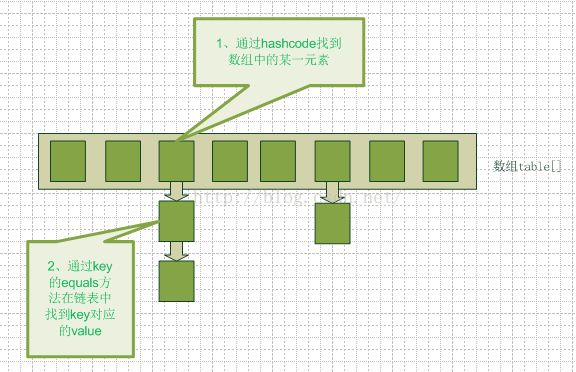
当我们往哈希表中插入元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中 了。如果这个元素所在的位子上已经存放其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。
HashMap 和Hashtable是哈希表的具体实现。
HashMap中put方法的实现:
hashMap中put方法的实现:
HashTable和HashMap区别
第一,继承不同。
public class Hashtable extends Dictionary implements Map
public class HashMap extends AbstractMap implements Map
第二
Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
第三
Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
第四,两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
第五
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
第六
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
HashMap的使用:
输出结果:
语文=80
英语=90
数学=85
哈希表是一个数组和链表的结合体(在数据结构称“链表散列“),如下图示:
当我们往哈希表中插入元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中 了。如果这个元素所在的位子上已经存放其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。
HashMap 和Hashtable是哈希表的具体实现。
HashMap中put方法的实现:
<span style="font-family:FangSong_GB2312;font-size:18px;"><span style="font-family:FangSong_GB2312;font-size:18px;">public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table; //把哈希表中数组地址赋值给tab
int hash = key.hashCode(); //获得哈希码
int index = (hash & 0x7FFFFFFF) % tab.length; //通过哈希码对数组长
//度取余的方法获得数组中的下标
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { //元素变量指向数组中第index个变量
//如果不空,说明已经有元素存在,判断是否要找的元素,直到最后。
if ((e.hash == hash) && e.key.equals(key)) {//如果该元素已经存在, 则修改成新值,并返回旧值
V old = e.value;
e.value = value;
return old;
}
}
modCount++; //改良次数加一
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.如果元素不存在则添加新元素
Entry<K,V> e = tab[index];
tab[index] = new Entry<K,V>(hash, key, value, e);
count++;
return null;
}</span></span>hashMap中put方法的实现:
<span style="font-family:FangSong_GB2312;font-size:18px;"><span style="font-family:FangSong_GB2312;font-size:18px;"><pre name="code" class="java">public V put(K key, V value) {
if (key == null) //如果是空key则不允许插入
return putForNullKey(value);
int hash = hash(key.hashCode()); //获得哈希码
int i = indexFor(hash, table.length); //获得数组下标
for (Entry<K,V> e = table[i]; e != null; e = e.next) { //通过hash和key判断此元素是否在hashMap中存在,
//存在修改新值返回旧值
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//如果hashMap中不存在此元素,则添加
addEntry(hash, key, value, i);
return null;
}</span></span>HashTable和HashMap区别
第一,继承不同。
public class Hashtable extends Dictionary implements Map
public class HashMap extends AbstractMap implements Map
第二
Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
第三
Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
第四,两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
第五
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
第六
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
HashMap的使用:
<span style="font-family:FangSong_GB2312;font-size:18px;">import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.junit.Test;
public class Test3 {
@Test
public void test3() {
Map map = new HashMap();
map.put("语文", "90");
map.put("语文", "80");//value 80 将替代 90
map.put("数学", "85");
map.put("英语", "90");
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
System.out.println(entry);
}
}
}</span>输出结果:
语文=80
英语=90
数学=85

相关文章推荐
- c语言实现hashmap(转载)
- Ruby中require、load、include、extend的区别介绍
- Ruby中的p和puts的使用区别浅析
- Ruby中的block、proc、lambda区别总结
- Redis和Memcached的区别详解
- Lua中调用函数使用点号和冒号的区别
- Lua中关于求模与求余的区别介绍
- TMP、TEMP和TMP文件区别解析
- C#基础语法:结构和类区别详解
- 深入c# 类和结构的区别总结详解
- C#中string.Empty和null的区别详解
- C#中遍历Hashtable的4种方法
- sqlserver和oracle中对datetime进行条件查询的一点区别小结
- 网页中Span和Div的区别
- 大家看了就明白了css样式中类class与标识id选择符的区别小结
- C#中类与结构的区别实例分析
- SQL 中having 和where的区别分析
- c#中(int)、int.Parse()、int.TryParse、Convert.ToInt32的区别详解
- MySQL Antelope和Barracuda的区别分析
- Rails Routes中new、collection、member的区别浅析