深入浅出 Java Concurrency : 并发容器ConcurrentMap
2015-10-02 18:41
639 查看
在JDK 1.4以下只有Vector和Hashtable是线程安全的集合(也称并发容器,Collections.synchronized*系列也可以看作是线程安全的实现)。从JDK 5开始增加了线程安全的Map接口ConcurrentMap和线程安全的队列BlockingQueue(尽管Queue也是同时期引入的新的集合,但是规范并没有规定一定是线程安全的,事实上一些实现也不是线程安全的,比如PriorityQueue、ArrayDeque、LinkedList等,在Queue章节中会具体讨论这些队列的结构图和实现)。
在介绍ConcurrencyMap之前先来回顾下Map的体系结构。下图描述了Map的体系结构,其中蓝色字体的是JDK 5以后新增的并发容器。
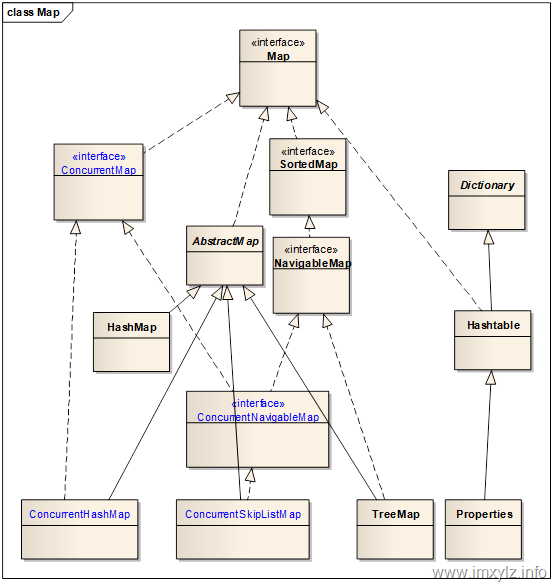
针对上图有以下几点说明:
Hashtable是JDK 5之前Map唯一线程安全的内置实现(Collections.synchronizedMap不算)。特别说明的是Hashtable的t是小写的(不知道为啥),Hashtable继承的是Dictionary(Hashtable是其唯一公开的子类),并不继承AbstractMap或者HashMap。尽管Hashtable和HashMap的结构非常类似,但是他们之间并没有多大联系。
ConcurrentHashMap是HashMap的线程安全版本,ConcurrentSkipListMap是TreeMap的线程安全版本。
最终可用的线程安全版本Map实现是ConcurrentHashMap/ConcurrentSkipListMap/Hashtable/Properties四个,但是Hashtable是过时的类库,因此如果可以的应该尽可能的使用ConcurrentHashMap和ConcurrentSkipListMap。
用java实现的一个哈希表(散列表)。只是简单实现了一些功能,想借此深入了解哈希表的具体实现。最好的学习方法还是看java源码。public class Table{
private int manyItems;
private Object[] keys;
private Object[] values;
private boolean[] hasBeenUsed;
public Table(int capacity){
if(capacity <= 0){
throw new IllegalArgumentException("Capacity is negative.");
}
keys = new Object[capacity];
values =new Object[capacity];
hasBeenUsed = new boolean[capacity];
}
/**
* 判断表是否为空
* @return
*/
public boolean isEmpty(){
return manyItems == 0;
}
/**
* 清空表
*/
public synchronized void clear() {
if(manyItems !=0){
for(int i = 0;i < values.length;i++){
keys[i]=null;
values[i]=null;
hasBeenUsed[i]=false;
}
manyItems = 0;
}
}
/**
* 判断是否存在指定的关键字
* @param key
* @return
*/
public boolean containsKey(Object key) {
return findIndex(key)!=-1;
}
public Object get(Object key) {
int index = findIndex(key);
if(index!=-1){
return values[index];
}
return null;
}
public synchronized Object put(Object key, Object value) {
int i = findIndex(hash(key));
Object temp = null;
if(i != -1){
//表中已经存在该关键字
temp = values[i];
values[i] = value;
//返回被替换的内容
return temp;
}else if(manyItems < values.length){
//表中不存在该关键字且表未满
i = hash(key);
//检查散列码是否有冲突
if(keys[i]!= null){
//散列码有冲突,索引前移
i = nextIndex(i);
}
keys[i] = key;
values[i]= value;
hasBeenUsed[i] = true;
manyItems ++;
return null;
}else{
//表已满
throw new IllegalStateException("Table is full");
}
}
public synchronized Object remove(Object key) {
int index = findIndex(key);
Object result = null;
if(index!=-1){
result = values[index];
keys[index]= null;
values[index]= null;
hasBeenUsed[index]=false;
manyItems --;
}
return result;
}
/**
* 如果在表中找到了指定的关键字,返回指定关键字的索引。否则返回 -1.
* @param key
* @return
*/
public int findIndex(Object key){
int count = 0;
int i = hash(key);
while((count < values.length) && hasBeenUsed[i]){
//分配的位置已经被使用,而且存在指定的关键字
if(keys[i].equals(key)){
return i;
}
//编辑遍历的次数,当全部元素都遍历完之后,退出遍历
count++;
i = nextIndex(i);
}
return -1;
}
/**
* 获取散列码,大小不超过表的大小
* @param key
* @return
*/
public int hash(Object key){
return Math.abs(key.hashCode())%values.length;
}
public int nextIndex(int index){
if(index+1 == values.length){
return 0;
}else{
return index + 1;
}
}
/**
* 判断指定的位置是否已经被使用
* @param index
* @return
*/
public boolean hasBeenUsed(int index){
return hasBeenUsed[index];
}
/**
* 返回该表中有多少对键值对。
* @return
*/
public int size() {
return manyItems;
}
}
回到正题来,这个小节主要介绍ConcurrentHashMap的API以及应用,下一节才开始将原理和分析。

除了实现Map接口里面对象的方法外,ConcurrentHashMap还实现了ConcurrentMap里面的四个方法。
V putIfAbsent(K key,V value)
如果不存在key对应的值,则将value以key加入Map,否则返回key对应的旧值。这个等价于清单1 的操作:
清单1 putIfAbsent的等价操作
if (!map.containsKey(key))
return map.put(key, value);
else
return map.get(key);
在前面的章节中提到过,连续两个或多个原子操作的序列并不一定是原子操作。比如上面的操作即使在Hashtable中也不是原子操作。而putIfAbsent就是一个线程安全版本的操作的。
有些人喜欢用这种功能来实现单例模式,例如清单2。
清单2 一种单例模式的实现
当然这里只是一个操作的例子,实际上在单例模式文章中有很多的实现和比较。清单2 在存在大量单例的情况下可能有用,实际情况下很少用于单例模式。但是这个方法避免了向Map中的同一个Key提交多个结果的可能,有时候在去掉重复记录上很有用(如果记录的格式比较固定的话)。
boolean remove(Object key,Object value)
只有目前将键的条目映射到给定值时,才移除该键的条目。这等价于清单3 的操作。
清单3 remove(Object,Object)的等价操作
if (map.containsKey(key) && map.get(key).equals(value)) {
map.remove(key);
return true;
}
return false;
由于集合类通常比较的hashCode和equals方法,而这两个方法是在Object对象里面,因此两个对象如果hashCode一致,并且覆盖了equals方法后也一致,那么这两个对象在集合类里面就是“相同”的,不管是否是同一个对象或者同一类型的对象。也就是说只要key1.hashCode()==key2.hashCode() && key1.equals(key2),那么key1和key2在集合类里面就认为是一致,哪怕他们的Class类型不一致也没关系,所以在很多集合类里面允许通过Object来类型来比较(或者定位)。比如说Map尽管添加的时候只能通过制定的类型<K,V>,但是删除的时候却允许通过一个Object来操作,而不必是K类型。
既然Map里面有一个remove(Object)方法,为什么ConcurrentMap还需要remove(Object,Object)方法呢?这是因为尽管Map里面的key没有变化,但是value可能已经被其他线程修改了,如果修改后的值是我们期望的,那么我们就不能拿一个key来删除此值,尽管我们的期望值是删除此key对于的旧值。
这种特性在原子操作章节的AtomicMarkableReference和AtomicStampedReference里面介绍过。
boolean replace(K key,V oldValue,V newValue)
只有目前将键的条目映射到给定值时,才替换该键的条目。这等价于清单4 的操作。
清单4 replace(K,V,V)的等价操作
if (map.containsKey(key) && map.get(key).equals(oldValue)) {
map.put(key, newValue);
return true;
}
return false;
V replace(K key,V value)
只有当前键存在的时候更新此键对于的值。这等价于清单5 的操作。
清单5 replace(K,V)的等价操作
if (map.containsKey(key)) {
return map.put(key, value);
}
return null;
replace(K,V,V)相比replace(K,V)而言,就是增加了匹配oldValue的操作。
其实这4个扩展方法,是ConcurrentMap附送的四个操作,其实我们更关心的是Map本身的操作。当然如果没有这4个方法,要完成类似的功能我们可能需要额外的锁,所以有总比没有要好。比如清单6,如果没有putIfAbsent内置的方法,我们如果要完成此操作就需要完全锁住整个Map,这样就大大降低了ConcurrentMap的并发性。这在下一节中有详细的分析和讨论。
清单6 putIfAbsent的外部实现
public V putIfAbsent(K key, V value) {
synchronized (map) {
if (!map.containsKey(key)) return map.put(key, value);
return map.get(key);
}
}
在介绍ConcurrencyMap之前先来回顾下Map的体系结构。下图描述了Map的体系结构,其中蓝色字体的是JDK 5以后新增的并发容器。

针对上图有以下几点说明:
Hashtable是JDK 5之前Map唯一线程安全的内置实现(Collections.synchronizedMap不算)。特别说明的是Hashtable的t是小写的(不知道为啥),Hashtable继承的是Dictionary(Hashtable是其唯一公开的子类),并不继承AbstractMap或者HashMap。尽管Hashtable和HashMap的结构非常类似,但是他们之间并没有多大联系。
ConcurrentHashMap是HashMap的线程安全版本,ConcurrentSkipListMap是TreeMap的线程安全版本。
最终可用的线程安全版本Map实现是ConcurrentHashMap/ConcurrentSkipListMap/Hashtable/Properties四个,但是Hashtable是过时的类库,因此如果可以的应该尽可能的使用ConcurrentHashMap和ConcurrentSkipListMap。
用java实现的一个哈希表(散列表)。只是简单实现了一些功能,想借此深入了解哈希表的具体实现。最好的学习方法还是看java源码。public class Table{
private int manyItems;
private Object[] keys;
private Object[] values;
private boolean[] hasBeenUsed;
public Table(int capacity){
if(capacity <= 0){
throw new IllegalArgumentException("Capacity is negative.");
}
keys = new Object[capacity];
values =new Object[capacity];
hasBeenUsed = new boolean[capacity];
}
/**
* 判断表是否为空
* @return
*/
public boolean isEmpty(){
return manyItems == 0;
}
/**
* 清空表
*/
public synchronized void clear() {
if(manyItems !=0){
for(int i = 0;i < values.length;i++){
keys[i]=null;
values[i]=null;
hasBeenUsed[i]=false;
}
manyItems = 0;
}
}
/**
* 判断是否存在指定的关键字
* @param key
* @return
*/
public boolean containsKey(Object key) {
return findIndex(key)!=-1;
}
public Object get(Object key) {
int index = findIndex(key);
if(index!=-1){
return values[index];
}
return null;
}
public synchronized Object put(Object key, Object value) {
int i = findIndex(hash(key));
Object temp = null;
if(i != -1){
//表中已经存在该关键字
temp = values[i];
values[i] = value;
//返回被替换的内容
return temp;
}else if(manyItems < values.length){
//表中不存在该关键字且表未满
i = hash(key);
//检查散列码是否有冲突
if(keys[i]!= null){
//散列码有冲突,索引前移
i = nextIndex(i);
}
keys[i] = key;
values[i]= value;
hasBeenUsed[i] = true;
manyItems ++;
return null;
}else{
//表已满
throw new IllegalStateException("Table is full");
}
}
public synchronized Object remove(Object key) {
int index = findIndex(key);
Object result = null;
if(index!=-1){
result = values[index];
keys[index]= null;
values[index]= null;
hasBeenUsed[index]=false;
manyItems --;
}
return result;
}
/**
* 如果在表中找到了指定的关键字,返回指定关键字的索引。否则返回 -1.
* @param key
* @return
*/
public int findIndex(Object key){
int count = 0;
int i = hash(key);
while((count < values.length) && hasBeenUsed[i]){
//分配的位置已经被使用,而且存在指定的关键字
if(keys[i].equals(key)){
return i;
}
//编辑遍历的次数,当全部元素都遍历完之后,退出遍历
count++;
i = nextIndex(i);
}
return -1;
}
/**
* 获取散列码,大小不超过表的大小
* @param key
* @return
*/
public int hash(Object key){
return Math.abs(key.hashCode())%values.length;
}
public int nextIndex(int index){
if(index+1 == values.length){
return 0;
}else{
return index + 1;
}
}
/**
* 判断指定的位置是否已经被使用
* @param index
* @return
*/
public boolean hasBeenUsed(int index){
return hasBeenUsed[index];
}
/**
* 返回该表中有多少对键值对。
* @return
*/
public int size() {
return manyItems;
}
}
回到正题来,这个小节主要介绍ConcurrentHashMap的API以及应用,下一节才开始将原理和分析。

除了实现Map接口里面对象的方法外,ConcurrentHashMap还实现了ConcurrentMap里面的四个方法。
V putIfAbsent(K key,V value)
如果不存在key对应的值,则将value以key加入Map,否则返回key对应的旧值。这个等价于清单1 的操作:
清单1 putIfAbsent的等价操作
if (!map.containsKey(key))
return map.put(key, value);
else
return map.get(key);
在前面的章节中提到过,连续两个或多个原子操作的序列并不一定是原子操作。比如上面的操作即使在Hashtable中也不是原子操作。而putIfAbsent就是一个线程安全版本的操作的。
有些人喜欢用这种功能来实现单例模式,例如清单2。
清单2 一种单例模式的实现
package xylz.study.concurrency;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
public class ConcurrentDemo1 {
private static final ConcurrentMap<String, ConcurrentDemo1> map = new ConcurrentHashMap<String, ConcurrentDemo1>();
private static ConcurrentDemo1 instance;
public static ConcurrentDemo1 getInstance() {
if (instance == null) {
map.putIfAbsent("INSTANCE", new ConcurrentDemo1());
instance = map.get("INSTANCE");
}
return instance;
}
private ConcurrentDemo1() {
}
}当然这里只是一个操作的例子,实际上在单例模式文章中有很多的实现和比较。清单2 在存在大量单例的情况下可能有用,实际情况下很少用于单例模式。但是这个方法避免了向Map中的同一个Key提交多个结果的可能,有时候在去掉重复记录上很有用(如果记录的格式比较固定的话)。
boolean remove(Object key,Object value)
只有目前将键的条目映射到给定值时,才移除该键的条目。这等价于清单3 的操作。
清单3 remove(Object,Object)的等价操作
if (map.containsKey(key) && map.get(key).equals(value)) {
map.remove(key);
return true;
}
return false;
由于集合类通常比较的hashCode和equals方法,而这两个方法是在Object对象里面,因此两个对象如果hashCode一致,并且覆盖了equals方法后也一致,那么这两个对象在集合类里面就是“相同”的,不管是否是同一个对象或者同一类型的对象。也就是说只要key1.hashCode()==key2.hashCode() && key1.equals(key2),那么key1和key2在集合类里面就认为是一致,哪怕他们的Class类型不一致也没关系,所以在很多集合类里面允许通过Object来类型来比较(或者定位)。比如说Map尽管添加的时候只能通过制定的类型<K,V>,但是删除的时候却允许通过一个Object来操作,而不必是K类型。
既然Map里面有一个remove(Object)方法,为什么ConcurrentMap还需要remove(Object,Object)方法呢?这是因为尽管Map里面的key没有变化,但是value可能已经被其他线程修改了,如果修改后的值是我们期望的,那么我们就不能拿一个key来删除此值,尽管我们的期望值是删除此key对于的旧值。
这种特性在原子操作章节的AtomicMarkableReference和AtomicStampedReference里面介绍过。
boolean replace(K key,V oldValue,V newValue)
只有目前将键的条目映射到给定值时,才替换该键的条目。这等价于清单4 的操作。
清单4 replace(K,V,V)的等价操作
if (map.containsKey(key) && map.get(key).equals(oldValue)) {
map.put(key, newValue);
return true;
}
return false;
V replace(K key,V value)
只有当前键存在的时候更新此键对于的值。这等价于清单5 的操作。
清单5 replace(K,V)的等价操作
if (map.containsKey(key)) {
return map.put(key, value);
}
return null;
replace(K,V,V)相比replace(K,V)而言,就是增加了匹配oldValue的操作。
其实这4个扩展方法,是ConcurrentMap附送的四个操作,其实我们更关心的是Map本身的操作。当然如果没有这4个方法,要完成类似的功能我们可能需要额外的锁,所以有总比没有要好。比如清单6,如果没有putIfAbsent内置的方法,我们如果要完成此操作就需要完全锁住整个Map,这样就大大降低了ConcurrentMap的并发性。这在下一节中有详细的分析和讨论。
清单6 putIfAbsent的外部实现
public V putIfAbsent(K key, V value) {
synchronized (map) {
if (!map.containsKey(key)) return map.put(key, value);
return map.get(key);
}
}

相关文章推荐
- java实现线性链表结构
- java Unicode与中文互换
- 类和对象浅谈(1)
- java:水仙花数打印
- IOC之基于Java类的配置Bean
- IOC之基于注解的配置bean(下)
- IOC之bean之间的关系讲解
- IOC之基于注解的配置bean(上)
- Spring之核心容器bean
- Spring之Construcotrer注入和setter注入不同的XML写法方式
- Spring之IOC自动装配解析
- Spring之IOC的注入方式总结
- Spring配置及第一个Spring HelloWorld
- Java面向对象设计主要有三大特征:封装性、继承性和多态性
- JavaWeb中3种中文乱码问题的解决方法
- Java中的堆和栈
- java简单计算器
- java学习笔记----枚举测试题
- JAVA设计模式之单件模式
- java15:面向对象