redis sentinel & cluster 原理分析
2015-09-29 11:10
956 查看
1. Redis集群实现分析
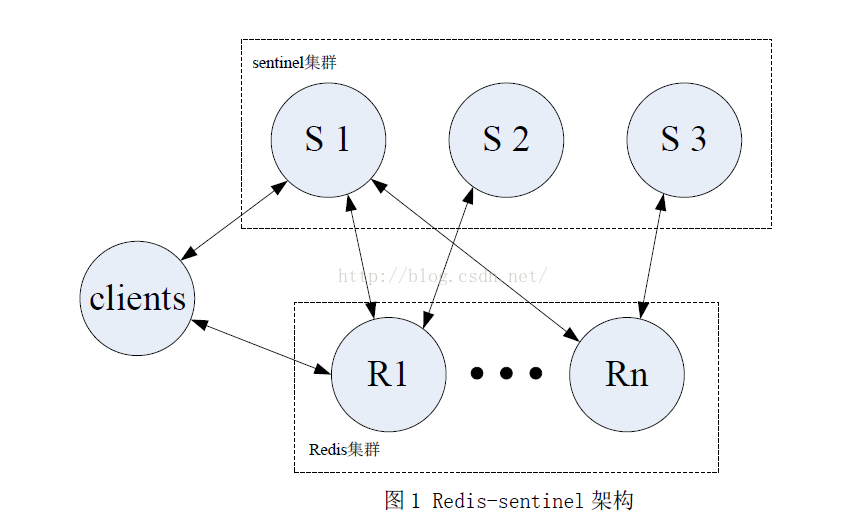
1.1 sentinel
1. 功能
Sentinel实现如下功能:(1)monitoring——redis实例是否正常运行。
(2)notification——通知application错误信息。
(3)failover——某个master死掉,选择一个slave升级为master,修改其他slave的slaveof关系,更新client连接。
(4)configurationprovider——client通过sentinel获取redis地址,并在failover时更新地址。
Redis 2.8及以上版本可用。
2. sentinels and slaves autodiscovery
配置文件中只配置master地址,slave地址和sentinel地址可以自动发现。(1)sentinels——sentinel之间通过redis pub/sub交换信息获得。
(2)slaves——询问master获得。
3. sdown、odown、failover
故障检测一般都是通过ping-pong机制,sentinel引入sdown(主观下线)和odown(客观下线)机制,目的应该是在集群规模较大时,检测更客观。(1)sdwon——is-master-down-after-milliseconds(可配置)时间内ping-pong失败。sdown的slave不能升级为master。
(2)odown——超过一定数目(可配置)的sentinel认为sdown,odown只针对master。
(3)failover——多数sentinel认为odown。
4. sentinel集群
sentinel至少需要部署三台以上,形成一个sentinel集群。(1)作用
failure detection更客观
可用性强,防止sentinel挂掉后不工作
(2)实现
Sentinels之间的数据同步,包括redis状态(odown,sdown),通过redis pub/sub实现。
执行failover需要选举一个sentinel作为leader去执行。
添加sentinel:自动发现
移除sentinel:stopsentinel process/reset all sentinel/check sentinel num
5. slaves选举leader
在slaves中选举一台作为新的master,选举的参考以下数据:(1)disconnection timefrom the master
(2)slave priority。每个redis instance有一个配置项slave-prority,可以通过info命令读取。slave to master时选择优先级高的,为0的never。
(3)replication offsetprocessed。
(4)run id。
6. 执行failver
(1) slave leader升级为master(2) 其他slave修改为新master的slave
(3) 客户端修改连接
(4) 老的master如果重启成功,变为新master的slave
7. 配置
必须使用配置文件sentinel.conf,以备重启时恢复信息,sentinel.conf实时更新。关键内容:
port——默认26379
sentinel monitor mymaster ip quorum——quorum odown
sentinel down-after-millisecondes mymaster
failover-timeout mymaster
parallel-syncs mymaster(修改配置时,同时修改slaveof的个数,越大failover时间越短)
master-name非必要,data-infrastructure实现是可以不使用。采用ip-port列表,针对单个master-name的参数都改为全局参数。
8. 其他
(1)sentinel添加了几个新的api,下面是几个关键的:masters
slaves master-name
sentinel集群相关的
master-name相关的
(2)reconfiguringsentinel at runtime
sentinel monitor name ip prot quorum
sentinel remove name
sentinel set name option value
(3)removeing the oldmaster or unreachable slaves
(4)sentinel and redisauthentication
(5)sentinelreconfiguration of instances outside the failover procedure
1.2 sentinel clients
Sentinel需要client端的支持。Finigle-redis目前不支持,jedis支持。1. service discovery
是指在client端输入sentinel地址列表、service name后,自动发现redis实例地址。支持sentinel之前,硬编码redis-instance地址。步骤:
(1)按顺序尝试连接sentinel集群
(2)get-master-addr-by-namemaster-name询问ip:port,查询失败,请求下一个sentinel
(3)使用role命令检查redis实例是否为master,如果不是(正在failover?),等一会,在从a开始。
2. handling reconnections
以下情况下,client需要重新通过sentinel获取地址建立连接(1)reconnects after atimeout or socket error
(2)explicitly closed orreconnected by user.
(3)other case where theclient lost connection with redis
3. sentinel failover disconnection
sentinel修改redis配置时,发送client kill命令断开此redis与所有client的连接,使client重新通过sentinel获取配置。4. connectiong to slaves
sentinel slaves master-name返回slave listrole命令验证
5. connection pools
clients端连接池,修改配置时需要断开所有client连接6.subscribe to sentinel events to improve responsiveness
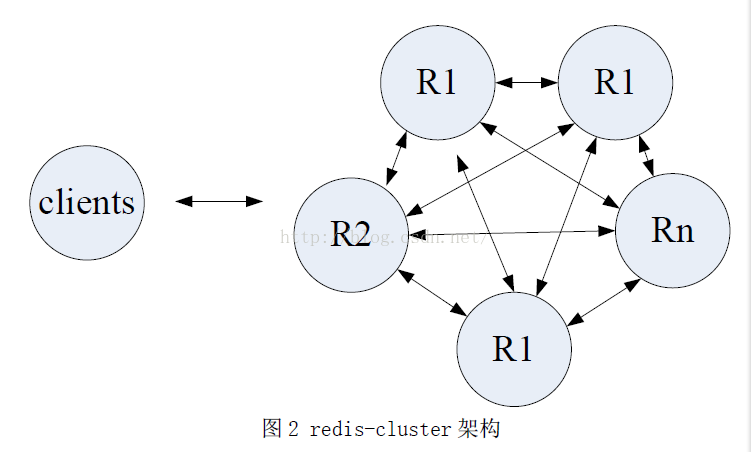
client使用pub/sub订阅sentinel reconfigure redis,非必要功能。1.3 redis cluster
1.设计目标
(1)高性能并1000个node之内线性扩展(2)高可用性(容错)
(3)可以接受的写安全(acceptabledegree of write safety)
版本:redis3.0及以上版本可用。
集群实现了所有处理单个数据库键的命令,没有实现针对多个数据库键的复杂计算。
不支持多数据库,只使用默认的0号数据库。
2.数据分布
不使用consistant hash,使用hashslot(哈希槽),共有16384个slot。hash_slot = crc16(key) mod 16384
每个node负责slot的一个子集,增加或者删除节点修改slot分布
hash-slot灵活性不如一致性hash,但便于实现数据迁移
3.redirection and resharding(核心部分)
(1)moved重定向client向任意一个node发送请求
若对应slot不在本地,返回movedresponse,携带正确的地址
client继续向新地址发送请求
可能move多次
客户端最好缓存key-node映射表
(2)cluster livereconfiguration
指的是在cluster运行期间添加或删除nodes,本质是把hash slot从一个节点移动到另一个节点(与故障迁移是不同的,这里处理的是集群的伸缩性)。
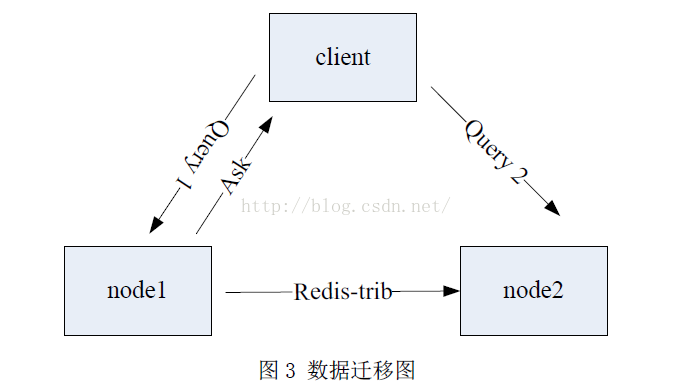
移动hash slot的步骤如下:
a. 停止new keys:向对应的两个nodes发送migrating\importing命令:
Migrating——key不在本地,ask重定向。
Importing——只接受ask请求,否者moved。
从而停止new key的导入。
b. 移动old keys: 然后启动另一个程序redis-trib,逐步的移动old keys。
(3)ask
ask与moved不同,ask重定向下一次请求
ask只在数据迁移阶段有用
4. 容错
使用master-slave模型,与sentinel类似,对节点失效的检测方法与sentinel有些不同(1)节点失效检测
ping无返回标记为pfail(possible failure)
随机广播3个已知节点信息
失效报告,记录接收到的节点信息
大部分节点认为pfail,标记为fail
广播fail,所有的节点都标记其为fail
(2)fail状态的清除
从节点重新上线时标记清除----所以对于下线的节点,也进行检测
主节点fail,超限时间内未故障转移,并且主节点重新上线,清除标记
(3)集群状态检测
部分哈希槽不能正常使用,整个集群停止工作
-----为什么要做这个设计???
(4)从节点的选举
满足一定条件(主已下线、主槽非空、本节点可靠)的从节点向集群中其他主节点发送授权请求
其他主节点返回授权(id最小等)
从节点得到授权,开始故障转移
(5)执行故障转移
pong其他节点,我是主了
接管已下线主的哈希槽
其他节点更新
5.节点握手
默认端口16379(偏移固定为1000)使用二进制协议而不是redis协议
节点之间使用gossip协议
对接收到的ping进行回复或主动发起pong
承认一个新的节点:
——meet命令强制(cmd触发)
——第三者传播
集群节点的属性(参考官方文档)
6.客户端
因为节点可以转向所有的错误信息,因此客户端无须保存集群状态信息客户端保存键和节点的映射信息,可以有效的减少转向次数,由此提升效率
cluster-slot命令获取hash-slot分布,来提高client效率
需要client支持,目前支持的client比较少,jedis支持,finagle-redis不支持,redis-cli
7.一致性
性能和一致性之间做的权衡,最终一致性,不支持强一致性部分场景存在写丢失的可能
(1)异步replication,写主成功给client,在replication之前主挂掉
(2)网络故障partition,failover时也可能发生写丢失
8.配置部署
(1)配置port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes<
a006
/p>
(2)部署
最少有三个master,三个slave
步骤:
创建相关目录 -〉执行redis-trib.rb创建cluster

相关文章推荐
- 在Ubuntu中安装Redis
- redis mac版服务优化
- Redis Cluster中不能使用SUNION等命令
- redis 主从服务器
- 将数据库数据放到redis中并保持数据一致性方案
- 后台服务器及相关中间件部署(zookeeper、ActiveMQ,mysql,mongo、redis)
- Redis安装和使用记录
- Redis 集群方案
- linux--redis的安装和配置和开启多个端口
- Redis复制-续
- Redis复制
- 学习日志---redhat安装redis
- Nosql数据库——redis(二)简介和安装
- spring data redis serializer SerializationException 序列化问题
- Nosql数据库——redis(一)
- [redis] redis 如何删除匹配模式的多个key值
- CentOS安装Redis记录
- Redis Sentinel的配置和使用
- centos6.5安装redis
- 查看Linux服务器上的Redis版本号