MongoDB的数据复制和数据切片
2015-09-18 23:01
627 查看
MongoDB简介
MongoDB由C++开发,是NoSQL中比较接近关系型数据库的一种。MongoDB中的数据以类似于json的格式存储,性能非常优越,且支持大量的数据存储。但是MongoDB不支持事务性的操作,使得其适用场景受到限制。
MongoDB副本集
MongoDB的数据复制有两种类型:
1)master/slave
2)replica set
第一种为类似于MySQL的主从复制模型,第二种为副本集复制方式。现在主要应用的为副本集复制模型。结构图如下:

一个副本集即为服务于同一数据集的多个MongoDB实例,其中一个为主节点,其余的都为从节点。主节点上能够完成读写操作,从节点仅能用于读操作。主节点需要记录所有改变数据库状态的操作,这些记录保存在oplog中,这个文件存储在local数据库,各个从节点通过此oplog来复制数据并应用于本地,保持本地的数据与主节点的一致。oplog具有幂等性,即无论执行几次其结果一致,这个比mysql的二进制日志更好用。
集群中的各节点还会通过传递心跳信息来检测各自的健康状况。当主节点故障时,多个从节点会触发一次新的选举操作,并选举其中的一个成为新的主节点(通常谁的优先级更高,谁就是新的主节点),心跳信息默认每2秒传递一次。

实现过程
副本集的实现至少需要三个节点,且应该为奇数个节点,可以使用arbiter(仲裁节点)来参与选举。
实验环境:
主节点:192.168.1.132
从节点:192.168.1.139,192.168.1.140
1)安装配置MongoDB
在各个节点上安装MongoDB服务器端需要的rpm包(安装包的下载地址:http://downloads-distro.mongodb.org/repo/redhat/os/):
replIndexPrefetch指定副本集的索引预取,如果有预取功能可以让复制过程更为高效,有3个值none,_id_only,all。none:不预取任何索引,_id_only:预取ID索引,all:预取所有索引。这个预取操作只能定义在从节点上。
在各节点上创建数据存放目录,然后启动服务:
2)配置集群的成员
查看集群信息(此时没有任何节点)
在创建副本集时,有3种方式:
1、db.runCommand( { replSetInitiate : <config_object> } )
2、rs.initiate(<config_object>)
3、rs.initiate() #先在其中一个节点上初始化,再通过rs.add添加另外的节点
这里采用的是第二种方式,<config_object>即为上述中的cfg文件,对该文件的修改使用replSetInitiate命令。
[b]3)访问测试[/b]
在主节点上添加数据(192.168.1.132):
此时在从节点上访问数据会报如下错误:
当主节点故障时,从节点会重新投票选举出主节点,继续提供服务,避免单点故障。
主节点上关闭服务:
4)添加一个从节点
数据库运行一段时间后,可能需要再次添加节点来分散压力。通过rs.add命令添加从节点。添加完成后,该节点需要和主节点同步数据,同步过程有3个步骤:
1、初始同步(initial sync)
2、回滚后追赶(post-rollback catch-up)
3、切分块迁移(sharding chunk migrations)
添加从节点(在主节点上):
5)更改某个节点的优先级
若某个从节点的硬件配置不错,可以对应的调高其优先级,使其在选举过程中能够优先被选举为主节点。例如设置第3个节点的优先级为2(默认均为1),过程如下:
MongoDB数据分片
随着数据集的扩大和吞吐量的提升,单个MongoDB服务器可能在cpu,内存或IO这些资源上出现瓶颈,这是需要对MongoDB进行扩展,比较经济的方式是水平扩展,将数据集分布到多个节点上来分散访问压力。这里的每个节点也称作分片,每个分片都是一个独立的数据库。所有的分片组合在一起才是一个完整的数据库。
MongoDB的分片框架中有3个角色:
1)Query Routers:路由
2)Config servers:元数据服务器
3)Shards:数据节点
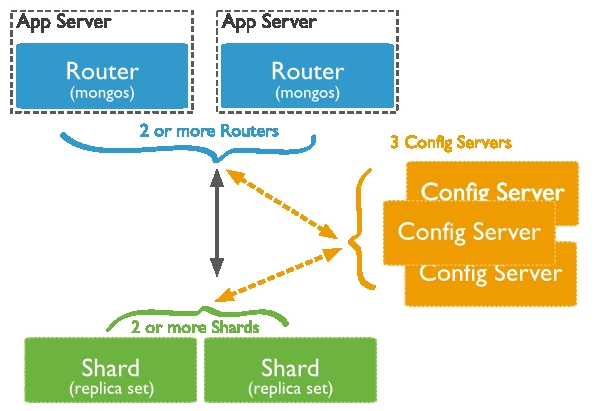
工作机制:Query Routers用于接收用户的请求,将请求路由到对应的分片上(shards)执行,然后将结果返回给客户端。Config servers存储服务器集群的元数据,Query Routers通过使用这些元数据将请求定位至特定的shard节点。Shards节点存储数据,为了提供高可用性和数据一致性,每个shard都可以是一个副本集。在生产环境中,为了避免单点故障,Query Routers和Config servers往往有多个节点。
实现过程
实验环境:
Config server:192.168.1.106
Query Routers:192.168.1.131
Shared:192.168.1.138,192.168.1.127
1[b])配置config server[/b]
在192.168.1.106上更改配置文件信息:

可以看到对应的服务监听在27019上。
2)[b][b]配置Query Routers[/b][/b]
Query Routers节点只需要安装mongodb-org-mongos即可,无需安装其他的软甲包。
启动mongos:
1)注释dbpath指令
2)添加configdb指令,并指定config服务器的地址
3)启动mongos,命令:mongos -f /etc/mongod.conf
3)配置shard节点
shard(数据节点)的配置与配置mongodb一致,如果不是副本集,把以下两项注销。
在两个shard节点上启动mongod服务:
4)[b]向分区集群中添加各shard服务器或副本集[/b]
连接mongos节点,添加shard。由于在mongos节点上仅安装了mongos的包,没有mongo命令,可以在其他节点上使用mongo --host 来连接。
添加shard节点:
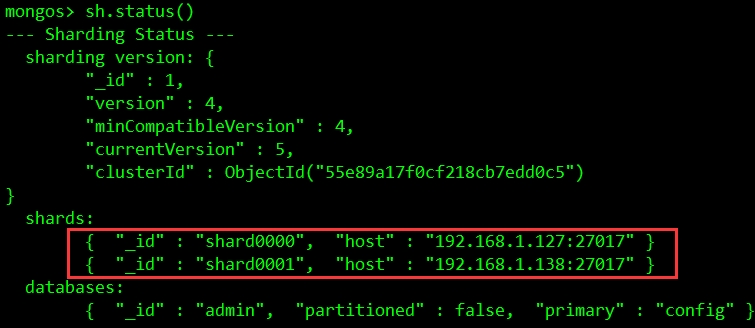
可以看到节点已经添加成功,只是上面还没有数据,没有进行分片。
5)启用sharding功能
启用指定数据库的sharding功能:
指定需要分片的Collection及索引:
查看集群的状态信息:
若需要分片时,数据已经存在,则需要对collection中的某一字段先创建索引,然后才能够分片。以上是MongoDB的简单应用。.................^_^
MongoDB由C++开发,是NoSQL中比较接近关系型数据库的一种。MongoDB中的数据以类似于json的格式存储,性能非常优越,且支持大量的数据存储。但是MongoDB不支持事务性的操作,使得其适用场景受到限制。
MongoDB副本集
MongoDB的数据复制有两种类型:
1)master/slave
2)replica set
第一种为类似于MySQL的主从复制模型,第二种为副本集复制方式。现在主要应用的为副本集复制模型。结构图如下:
一个副本集即为服务于同一数据集的多个MongoDB实例,其中一个为主节点,其余的都为从节点。主节点上能够完成读写操作,从节点仅能用于读操作。主节点需要记录所有改变数据库状态的操作,这些记录保存在oplog中,这个文件存储在local数据库,各个从节点通过此oplog来复制数据并应用于本地,保持本地的数据与主节点的一致。oplog具有幂等性,即无论执行几次其结果一致,这个比mysql的二进制日志更好用。
集群中的各节点还会通过传递心跳信息来检测各自的健康状况。当主节点故障时,多个从节点会触发一次新的选举操作,并选举其中的一个成为新的主节点(通常谁的优先级更高,谁就是新的主节点),心跳信息默认每2秒传递一次。
实现过程
副本集的实现至少需要三个节点,且应该为奇数个节点,可以使用arbiter(仲裁节点)来参与选举。
实验环境:
主节点:192.168.1.132
从节点:192.168.1.139,192.168.1.140
1)安装配置MongoDB
在各个节点上安装MongoDB服务器端需要的rpm包(安装包的下载地址:http://downloads-distro.mongodb.org/repo/redhat/os/):
[root@mongo1 mongodb-2.6.5]# yum install -y mongodb-org-server-2.6.5-1.x86_64.rpm mongodb-org-tools-2.6.5-1.x86_64.rpm mongodb-org-shell-2.6.5-1.x86_64.rpm配置文件信息:
[root@mongo1 ~]# vim /etc/mongod.conf logpath=/var/log/mongodb/mongod.log logappend=true fork=true dbpath=/mongodb/data pidfilepath=/var/run/mongodb/mongod.pid bind_ip=0.0.0.0 httpinterface=true rest=true replSet=rs0 replIndexPrefetch = _id_onlyreplSet指定副本集的名称,这个至关重要,这个决定了对应的每一个节点加入的是哪一个副本集的集群。
replIndexPrefetch指定副本集的索引预取,如果有预取功能可以让复制过程更为高效,有3个值none,_id_only,all。none:不预取任何索引,_id_only:预取ID索引,all:预取所有索引。这个预取操作只能定义在从节点上。
在各节点上创建数据存放目录,然后启动服务:
[root@mongo1 ~]# mkdir -pv /mongodb/data mkdir: created directory `/mongodb' mkdir: created directory `/mongodb/data' [root@mongo1 ~]# chown -R mongod.mongod /mongodb [root@mongo1 ~]# service mongod start Starting mongod: [ OK ]
2)配置集群的成员
查看集群信息(此时没有任何节点)
[root@mongo1 ~]# mongo --host 192.168.1.132
MongoDB shell version: 2.6.5
connecting to: 192.168.1.132:27017/test
> rs.status()
{
"startupStatus" : 3,
"info" : "run rs.initiate(...) if not yet done for the set",
"ok" : 0,
"errmsg" : "can't get local.system.replset config from self or any seed (EMPTYCONFIG)"
}添加集群成员,首先配置cfg定义集群信息,然后执行rs.initiate(cfg)完成节点的添加。在定义集群时,需要指定每一个节点的属性信息,例如_id,host。还有很多属性字段,常见的有priority,votes,arbiterOnly..... 具体的信息可以参考官方网站http://docs.mongodb.org/manual/reference/command/replSetGetConfig/#replsetgetconfig-output。> cfg={_id:'rs0',members:[
... ... {_id:0,host:'192.168.1.132:27017'},
... ... {_id:1,host:'192.168.1.139:27017'},
... ... {_id:2,host:'192.168.1.140:27017'}]
... ... }
{
"_id" : "rs0",
"members" : [
{
"_id" : 0,
"host" : "192.168.1.132:27017"
},
{
"_id" : 1,
"host" : "192.168.1.139:27017"
},
{
"_id" : 2,
"host" : "192.168.1.140:27017"
}
]
}
#################################
> rs.initiate(cfg)
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}查看各节点的状态信息:> rs.status()
{
"set" : "rs0",
"date" : ISODate("2015-09-04T23:02:13Z"),
"myState" : 1,
"members" : [ #显示副本集的所有成员信息
{
"_id" : 0, #节点的标识符
"name" : "192.168.1.132:27017", #节点名称
"health" : 1, #节点的健康状态
"state" : 1,
"stateStr" : "PRIMARY", #该节点为主节点
"uptime" : 1750, #运行时长
"optime" : Timestamp(1441407002, 1), #oplog最后一次操作的时间戳
"optimeDate" : ISODate("2015-09-04T22:50:02Z"), #oplog最后一次操作的时间
"electionTime" : Timestamp(1441407011, 1), #选举时间
"electionDate" : ISODate("2015-09-04T22:50:11Z"), #选举日期
"self" : true #表示是否为当前节点
},
{
"_id" : 1,
"name" : "192.168.1.139:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY", #从节点
"uptime" : 730,
"optime" : Timestamp(1441407002, 1),
"optimeDate" : ISODate("2015-09-04T22:50:02Z"),
"lastHeartbeat" : ISODate("2015-09-04T23:02:13Z"),
"lastHeartbeatRecv" : ISODate("2015-09-04T23:02:12Z"),
"pingMs" : 0,
"syncingTo" : "192.168.1.132:27017" #指向的主节点
},
{
"_id" : 2,
"name" : "192.168.1.140:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 730,
"optime" : Timestamp(1441407002, 1),
"optimeDate" : ISODate("2015-09-04T22:50:02Z"),
"lastHeartbeat" : ISODate("2015-09-04T23:02:13Z"),
"lastHeartbeatRecv" : ISODate("2015-09-04T23:02:12Z"),
"pingMs" : 0,
"syncingTo" : "192.168.1.132:27017"
}
],
"ok" : 1
}在创建副本集时,有3种方式:
1、db.runCommand( { replSetInitiate : <config_object> } )
2、rs.initiate(<config_object>)
3、rs.initiate() #先在其中一个节点上初始化,再通过rs.add添加另外的节点
这里采用的是第二种方式,<config_object>即为上述中的cfg文件,对该文件的修改使用replSetInitiate命令。
[b]3)访问测试[/b]
在主节点上添加数据(192.168.1.132):
rs0:PRIMARY> use student_db
switched to db student_db
rs0:PRIMARY> for (i=1;i<=100000;i++) db.students.insert({name:"student"+i,age:(i%120),address:"china_nb"});
WriteResult({ "nInserted" : 1 })此时在从节点上访问数据会报如下错误:
rs0:SECONDARY> use student_db
switched to db student_db
rs0:SECONDARY> db.students.findOne()
2015-09-04T19:28:10.730-0400 error: { "$err" : "not master and slaveOk=false", "code" : 13435 } at src/mongo/shell/query.js:131执行rs.slaveOk()后,数据才可读。rs0:SECONDARY> rs.slaveOk()
rs0:SECONDARY> db.student.findOne()
null
rs0:SECONDARY> db.students.findOne()
{
"_id" : ObjectId("55ea287ce476f31ac766a383"),
"name" : "student1",
"age" : 1,
"address" : "china_nb"
}当主节点故障时,从节点会重新投票选举出主节点,继续提供服务,避免单点故障。
主节点上关闭服务:
[root@mongo1 ~]# service mongod stop Stopping mongod: [ OK ]从节点上查看状态信息:
rs0:SECONDARY> rs.status()
{
"set" : "rs0",
"date" : ISODate("2015-09-04T23:31:49Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "192.168.1.132:27017",
"health" : 0, #主节点已经下线
"state" : 8,
"stateStr" : "(not reachable/healthy)",
................
},
{
"_id" : 1,
"name" : "192.168.1.139:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY", #新选出的主节点
............
},
{
"_id" : 2,
"name" : "192.168.1.140:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
.........
}
],
"ok" : 1
}可以看到原来的主节点已经下线(health为0),重新选举的主节点为192.168.1.139。可以通过rs.isMaster()查看当前节点是否为主节点。4)添加一个从节点
数据库运行一段时间后,可能需要再次添加节点来分散压力。通过rs.add命令添加从节点。添加完成后,该节点需要和主节点同步数据,同步过程有3个步骤:
1、初始同步(initial sync)
2、回滚后追赶(post-rollback catch-up)
3、切分块迁移(sharding chunk migrations)
添加从节点(在主节点上):
rs0:PRIMARY> rs.add("192.168.1.138")
{ "ok" : 1 }查看状态:{
"_id" : 2,
"name" : "192.168.1.127:27017",
"health" : 1,
.....................
"lastHeartbeatMessage" : "still initializing" #正在初始化
}
#######################
{
"_id" : 1,
"name" : "192.168.1.138:27017",
"health" : 1,
........
"lastHeartbeatMessage" : "initial sync need a member to be primary or secondary to do our initial sync" #同步数据
}
#######################
{
"_id" : 1,
"name" : "192.168.1.138:27017",
"health" : 1,
........
"syncingTo" : "node1.xiaoxiao.com:27017" #同步完成
}执行rs.slaveOk()后,即可实现访问。5)更改某个节点的优先级
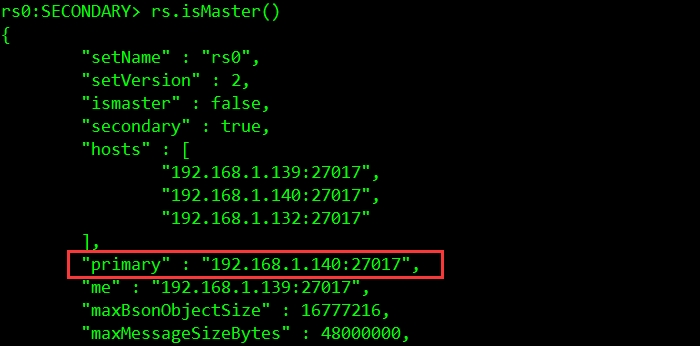
若某个从节点的硬件配置不错,可以对应的调高其优先级,使其在选举过程中能够优先被选举为主节点。例如设置第3个节点的优先级为2(默认均为1),过程如下:
rs0:PRIMARY> cfg=rs.conf()
rs0:PRIMARY> cfg.members[2].priority=2 #节点的标识符为2
rs0:PRIMARY> rs.reconfig(cfg) #更新配置
################
rs0:SECONDARY> rs.config()
{
................
{
"_id" : 2,
"host" : "192.168.1.140:27017",
"priority" : 2 #对应优先级
}
]
}此时会立刻进行选举,优先级最高的为主节点,如下图所示:MongoDB数据分片
随着数据集的扩大和吞吐量的提升,单个MongoDB服务器可能在cpu,内存或IO这些资源上出现瓶颈,这是需要对MongoDB进行扩展,比较经济的方式是水平扩展,将数据集分布到多个节点上来分散访问压力。这里的每个节点也称作分片,每个分片都是一个独立的数据库。所有的分片组合在一起才是一个完整的数据库。
MongoDB的分片框架中有3个角色:
1)Query Routers:路由
2)Config servers:元数据服务器
3)Shards:数据节点
工作机制:Query Routers用于接收用户的请求,将请求路由到对应的分片上(shards)执行,然后将结果返回给客户端。Config servers存储服务器集群的元数据,Query Routers通过使用这些元数据将请求定位至特定的shard节点。Shards节点存储数据,为了提供高可用性和数据一致性,每个shard都可以是一个副本集。在生产环境中,为了避免单点故障,Query Routers和Config servers往往有多个节点。
实现过程
实验环境:
Config server:192.168.1.106
Query Routers:192.168.1.131
Shared:192.168.1.138,192.168.1.127
1[b])配置config server[/b]
在192.168.1.106上更改配置文件信息:
[root@node1 ~]# vim /etc/mongod.conf #replSet=rs0 #replIndexPrefetch = _id_only configsvr = true配置完成后启动服务:
[root@node1 ~]# service mongod start Starting mongod: [ OK ]
可以看到对应的服务监听在27019上。
2)[b][b]配置Query Routers[/b][/b]
Query Routers节点只需要安装mongodb-org-mongos即可,无需安装其他的软甲包。
[root@node4 mongodb-2.6.5]# yum install mongodb-org-mongos-2.6.5-1.x86_64.rpm默认情况下,mongos监听于27017端口,在启动mongos是需要指定config服务器的地址。
启动mongos:
[root@node4 ~]# mkdir /var/log/mongodb [root@node4 ~]# mongos --configdb=192.168.1.106 --fork --logpath=/var/log/mongodb/mongo.log也可以直接编辑配置文件:
1)注释dbpath指令
2)添加configdb指令,并指定config服务器的地址
3)启动mongos,命令:mongos -f /etc/mongod.conf
3)配置shard节点
shard(数据节点)的配置与配置mongodb一致,如果不是副本集,把以下两项注销。
#replSet=rs0 #replIndexPrefetch = _id_only
在两个shard节点上启动mongod服务:
[root@node2 ~]# service mongod start Starting mongod: [ OK ] ################### [root@node3 ~]# service mongod start Starting mongod: [ OK ]
4)[b]向分区集群中添加各shard服务器或副本集[/b]
连接mongos节点,添加shard。由于在mongos节点上仅安装了mongos的包,没有mongo命令,可以在其他节点上使用mongo --host 来连接。
[root@node1 ~]# mongo --host 192.168.1.131 MongoDB shell version: 2.6.5 connecting to: 192.168.1.131:27017/test mongos>
添加shard节点:
mongos> sh.addShard("192.168.1.127")
{ "shardAdded" : "shard0000", "ok" : 1 }
mongos> sh.addShard("192.168.1.138")
{ "shardAdded" : "shard0001", "ok" : 1 }可以看到节点已经添加成功,只是上面还没有数据,没有进行分片。
5)启用sharding功能
启用指定数据库的sharding功能:
mongos> sh.enableSharding("student_db")
{ "ok" : 1 }
################################
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"version" : 4,
"minCompatibleVersion" : 4,
"currentVersion" : 5,
"clusterId" : ObjectId("55e89a17f0cf218cb7edd0c5")
}
shards:
{ "_id" : "shard0000", "host" : "192.168.1.127:27017" }
{ "_id" : "shard0001", "host" : "192.168.1.138:27017" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "student_db", "partitioned" : true, "primary" : "shard0000" } #显示该数据库已经支持分片最后一行显示student_db数据库的partition为true,已支持数据分片功能。指定需要分片的Collection及索引:
mongos> sh.shardCollection("student_db.students",{"age":1})
{ "collectionsharded" : "student_db.student", "ok" : 1 }
#################################
#插入数据
mongos> for (i=1;i<=100000;i++) db.students.insert({name:"student"+i,age:(i%120),address:"china_nb"});
WriteResult({ "nInserted" : 1 })查看集群的状态信息:
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"version" : 4,
"minCompatibleVersion" : 4,
"currentVersion" : 5,
"clusterId" : ObjectId("55e89a17f0cf218cb7edd0c5")
}
shards:
{ "_id" : "shard0000", "host" : "192.168.1.127:27017" }
{ "_id" : "shard0001", "host" : "192.168.1.138:27017" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "student_db", "partitioned" : true, "primary" : "shard0000" }
student_db.students
shard key: { "age" : 1 }
chunks:
shard0001 1
shard0000 2
{ "age" : { "$minKey" : 1 } } -->> { "age" : 1 } on : shard0001 Timestamp(2, 0)
{ "age" : 1 } -->> { "age" : 119 } on : shard0000 Timestamp(2, 1)
{ "age" : 119 } -->> { "age" : { "$maxKey" : 1 } } on : shard0000 Timestamp(1, 4)可以看到数据已经分别存储在不同的shard上。若需要分片时,数据已经存在,则需要对collection中的某一字段先创建索引,然后才能够分片。以上是MongoDB的简单应用。.................^_^

相关文章推荐
- 分享微信开发Html5轻游戏中的几个坑
- 如何在 Fedora 上安装 MongoDB 服务器
- PHP添加yaf xhprof mongodb 同理
- mongodb安装
- 如何在 Ubuntu 上安装 MongoDB
- perl操作MongoDB报错undefined symbol: HeUTF8解决方法
- C#中使用1.7版本驱动操作MongoDB简单例子
- MongoDB系列教程(四):设置用户访问权限
- php实现的mongodb操作类实例
- 解决mongodb在ubuntu下启动失败,提示couldn‘t remove fs lock errno:9 Bad file descriptor的错误
- 在PostgreSQL的基础上创建一个MongoDB的副本的教程
- java操作mongodb示例分享
- php对mongodb的扩展(初出茅庐)
- 作为PHP程序员应该了解MongoDB的五件事
- 基于MySQL到MongoDB简易对照表的详解
- MongoDB入门教程之C#驱动操作实例
- MongoDB为用户设置访问权限
- MongoDB db.serverStatus()输出内容中文注释
- MongoDB的一些常用查询方法
- mongodb与mysql命令详细对比