总结八大排序算法的基本思想与代码实现
2015-09-16 15:19
706 查看
在写这篇文章之前,先点一根红烛默哀我腾讯挂掉的笔试/(ㄒoㄒ)/~~小女子尽力了,真的真的尽力了/(ㄒoㄒ)/~~奈何缘浅,就此别过吧ヾ( ̄▽ ̄)Bye~Bye~
在这里先提前说明一下,在下面讲解中,会涉及到时间复杂度和空间复杂度的计算,那么先来说一下怎样计算时间复杂度和空间复杂度?
按照书上所说,时间复杂度的计算方法如下:
1.计算出基本操作的执行次数T(n);
2.计算出T(n)的数量级,令f(n)=T(n)的数量级;
3.用大O来表示时间复杂度,当n趋近于无穷大时,如果lim(T(n)/f(n))的值不等于0,则T(n)=O(f(n)),称为算法的时间复杂度。
吧啦吧啦吧啦~~~是不是很复杂的感觉,瞬间感到了深深的恶意吗?那我们简化一下,用学渣的思想去计算:
1.找到执行次数最多的语句;
2.计算语句中执行次数的数量级;
3.OK~那就是时间复杂度了,不要怀疑~~~
言回正传啦,咳咳,说排序了。
排序分为内部排序和外部排序,我们接触最多的也就是内部排序,所谓内部就是数据记录在内存中,八大排序也就是典型的内部排序。
1.直接插入排序
基本思想:
假设我们存在一个待排元素数组R[0...n-1],在排序过程中,我们将R分成两个子序区,R[0..i-1]称为有序区,R[1..n-1]称为无序区,然后我们再从无序区开头位置R[i]开始扫描,每一次在有序区中只增加一个元素到合适的位置。
C++代码:
基本思想:
类似于直接插入,但是我们可以在有序区找插入位置的时候,采用折半查找法,再通过移动元素进行插入。我们可以把R[0..n-1]设为R[low..high],找到插入位置为R[high+1],再将R[high+1..i-1]中的元素后移一个位置,并置R[high+1]=R[i]。
C++代码:
基本思想:
首先先确定增量d1的值,一般取d1=n/2,作为增量,将数组分为d1个组并且将相隔距离为d1的元素全部放在同一组内,在组内进行直接插入排序。以此类推,知道增量dt=1,也就是全部元素在同一个组内时,再将元素排序一遍即可。
C++代码:
基本思想:
通过无序区中相邻元素中关键字的比较和位置的交换,是关键字最小的元素如气泡一般逐渐往上“漂浮”直至水面。整个算法从最下面开始,对相邻元素之间进行比较,经过一趟排序后,最小的元素浮之水面。
C++代码:
基本思想:
在待排序的数组中,找到一个基准元素通常为R[0],将该元素放置合适的位置后,数据序列被划分为两部分,所有比关键字小的元素放到前面,而比关键字大的部分放到后面。先来说一下一趟快速排序的过程吧。首先我们设置两个指针,分别指向数组的头和尾,再将基准元素R[s]用tmp保存,令j从n-1开始扫描直到R[j].key<tmp.key,将R[j]移到i的位置。然后令i开始扫描直至R[i].key>tmp.key,将R[i]移到j的位置,以此类推,直到i=j。
C++代码:
6.直接选择排序
基本思想:
第i趟排序开始时,当前有序区和无序区分别为R[0..i-1]和R[i..n-1],该趟排序是从当前无序区中选出关键字最小的元素R[k],将它与无序区的第一个元素R[i]交换,是R[0..i]和R[i+1..n-1]分别变为新的有序区和新的无序区。直接选择排序每趟产生的有序区一定是全局有序区,也就是每趟产生的有序区中所有元素都归位了。
C++代码:
基本思想:
是一种树形选择排序方法,在排序过程中,将R[1..n]看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,当前无序区中选择关键字最大的元素。
基本思想:
将R[0..n-1]看成是n个长度为1的有序序列,然后进行两两归并,得到[n/2]个长度为2的有序序列,在进行两两归并。。。直到得到一个长度为n的有序序列。
C++代码:
总结:
各种排序方法的性能
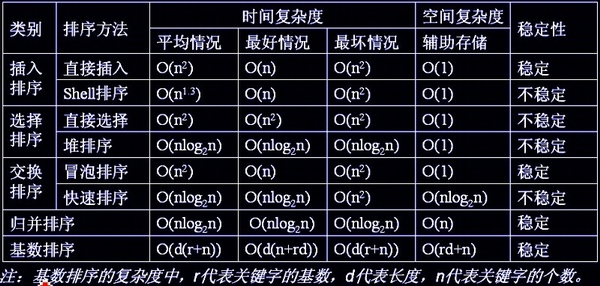
稳定性:
排序算法的稳定性:若待排序的序列中,存在多个具有相同关键字的记录,经过排序,
这些记录的相对次序保持不变,则称该算法是稳定的;若经排序后,记录的相对 次序发生了改变,则称该算法是不稳定的。
稳定性的好处:排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。另外,如果排序算法稳定,可以避免多余的比较;
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序
选择排序算法准则:
每种排序算法都各有优缺点。因此,在实用时需根据不同情况适当选用,甚至可以将多种方法结合起来使用。
选择排序算法的依据
影响排序的因素有很多,平均时间复杂度低的算法并不一定就是最优的。相反,有时平均时间复杂度高的算法可能更适合某些特殊情况。同时,选择算法时还得考虑它的可读性,以利于软件的维护。一般而言,需要考虑的因素有以下四点:
1.待排序的记录数目n的大小;
2.记录本身数据量的大小,也就是记录中除关键字外的其他信息量的大小;
3.关键字的结构及其分布情况;
4.对排序稳定性的要求。
设待排序元素的个数为n.
1)当n较大,则应采用时间复杂度为O(nlog2n)的排序方法:快速排序、堆排序或归并排序序。
快速排序:是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
堆排序 : 如果内存空间允许且要求稳定性的,
归并排序:它有一定数量的数据移动,所以我们可能过与插入排序组合,先获得一定长度的序列,然后再合并,在效率上将有所提高。
2) 当n较大,内存空间允许,且要求稳定性 =》归并排序
3)当n较小,可采用直接插入或直接选择排序。
直接插入排序:当元素分布有序,直接插入排序将大大减少比较次数和移动记录的次数。
直接选择排序 :元素分布有序,如果不要求稳定性,选择直接选择排序
5)一般不使用或不直接使用传统的冒泡排序。
6)基数排序
它是一种稳定的排序算法,但有一定的局限性:
1、关键字可分解。
2、记录的关键字位数较少,如果密集更好
3、如果是数字时,最好是无符号的,否则将增加相应的映射复杂度,可先将其正负分开排序。
在这里先提前说明一下,在下面讲解中,会涉及到时间复杂度和空间复杂度的计算,那么先来说一下怎样计算时间复杂度和空间复杂度?
按照书上所说,时间复杂度的计算方法如下:
1.计算出基本操作的执行次数T(n);
2.计算出T(n)的数量级,令f(n)=T(n)的数量级;
3.用大O来表示时间复杂度,当n趋近于无穷大时,如果lim(T(n)/f(n))的值不等于0,则T(n)=O(f(n)),称为算法的时间复杂度。
吧啦吧啦吧啦~~~是不是很复杂的感觉,瞬间感到了深深的恶意吗?那我们简化一下,用学渣的思想去计算:
1.找到执行次数最多的语句;
2.计算语句中执行次数的数量级;
3.OK~那就是时间复杂度了,不要怀疑~~~
言回正传啦,咳咳,说排序了。
排序分为内部排序和外部排序,我们接触最多的也就是内部排序,所谓内部就是数据记录在内存中,八大排序也就是典型的内部排序。
1.直接插入排序
基本思想:
假设我们存在一个待排元素数组R[0...n-1],在排序过程中,我们将R分成两个子序区,R[0..i-1]称为有序区,R[1..n-1]称为无序区,然后我们再从无序区开头位置R[i]开始扫描,每一次在有序区中只增加一个元素到合适的位置。
C++代码:
void InsertSort(RecType R[],int n){
int i,j;
RecType temp;
for(i=1;i<n;i++){
temp = R[i];
j=i-1; //从右向左,在有序区中找到插入的位置
while(j>=0 && temp.key<R[j].key){
R[j+1]=R[j]; //将关键字大于R[i]的元素后移
j--;
}
R[j+1]=temp;
}
}2.折半插入排序基本思想:
类似于直接插入,但是我们可以在有序区找插入位置的时候,采用折半查找法,再通过移动元素进行插入。我们可以把R[0..n-1]设为R[low..high],找到插入位置为R[high+1],再将R[high+1..i-1]中的元素后移一个位置,并置R[high+1]=R[i]。
C++代码:
void InsertSort(RecType R[],int n){
int i,j,low,high,mid;
RecType tmp;
for(i=1;i<n;i++){
tmp=R[i];
low=0;
high=i-1;
while(low<=high){
mid=(low+high)/2;
if(tmp.key<R[mid].key)
high=mid-1;
else
low=mid+1;
}
for(j=i-1;j>=high+1;j--)
R[j+1]=R[j];
R[high+1]=tmp;
}
}3.希尔排序基本思想:
首先先确定增量d1的值,一般取d1=n/2,作为增量,将数组分为d1个组并且将相隔距离为d1的元素全部放在同一组内,在组内进行直接插入排序。以此类推,知道增量dt=1,也就是全部元素在同一个组内时,再将元素排序一遍即可。
C++代码:
void shellSort(RecType R[],int n){
int i,j,gap;
RecType tmp;
gap = n/2;
while(gap>0){
for(i=gap;i<n;i++){ //将所有相隔gap元素组采用直接插入排序
tmp = R[i];
j=i-gap;
while(j>=0 && tmp.key<R[j].key){
R[j+gap]=R[j];
j=j-gap;
}
R[j+gap]=tmp;
}
gap=gap/2; //减少增量
}
}4.冒泡排序基本思想:
通过无序区中相邻元素中关键字的比较和位置的交换,是关键字最小的元素如气泡一般逐渐往上“漂浮”直至水面。整个算法从最下面开始,对相邻元素之间进行比较,经过一趟排序后,最小的元素浮之水面。
C++代码:
void BubbleSort(RecType R[],int n){
int i,j;
RecType tmp;
bool flag;
for(i=0;i<n-1;i++){
flag=false;
for(j=n-1;j>i;j--)
if(R[j].key<R[j-1].key){
tmp=R[j];
R[j]=R[j-1];
R[j-1]=tmp;
flag=true;
}
if(!flag)
return ;
}
}5.快速排序基本思想:
在待排序的数组中,找到一个基准元素通常为R[0],将该元素放置合适的位置后,数据序列被划分为两部分,所有比关键字小的元素放到前面,而比关键字大的部分放到后面。先来说一下一趟快速排序的过程吧。首先我们设置两个指针,分别指向数组的头和尾,再将基准元素R[s]用tmp保存,令j从n-1开始扫描直到R[j].key<tmp.key,将R[j]移到i的位置。然后令i开始扫描直至R[i].key>tmp.key,将R[i]移到j的位置,以此类推,直到i=j。
C++代码:
void quickSort(RecType R[],int s,int t){
int i=s,j=t;
RecType tmp;
if(s<t){
tmp=R[s];
while(i!=j){
while(j>i && R[j].key>=tmp.key)
j--; //从右向左扫描,找到第一个小于tmp的R[j]
R[i]=R[j];
while(i<j && R[i].key<=tmp.key)
i++; //从左到右扫描,找到第一个大于tmp的R[i]
R[j]=R[i];
}
R[i]=tmp;
quickSort(R,s,i-1);
quickSort(R,i+1,t);
}
}6.直接选择排序
基本思想:
第i趟排序开始时,当前有序区和无序区分别为R[0..i-1]和R[i..n-1],该趟排序是从当前无序区中选出关键字最小的元素R[k],将它与无序区的第一个元素R[i]交换,是R[0..i]和R[i+1..n-1]分别变为新的有序区和新的无序区。直接选择排序每趟产生的有序区一定是全局有序区,也就是每趟产生的有序区中所有元素都归位了。
C++代码:
void SelectSort(RecType R[],int n){
int i,j,k;
RecType tmp;
for(i=0;i<n-1;i++){
k=i;
for(j=i+1;j<n;j++) //在当前无序区R[i..n-1]中选key最小的R[k]
if(R[j].key<R[k].key)
k=j;
if(k!=i){
tmp=R[i];
R[i]=R[k];
R[k]=tmp;
}
}
}7.堆排序基本思想:
是一种树形选择排序方法,在排序过程中,将R[1..n]看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,当前无序区中选择关键字最大的元素。
void sift(RecType R[],int low,int high){
int i=low,j=2*i;
RecType tmp=R[i];
while(j<=high){
if(j<high && R[j],key<R[j+1].key)
j++;
if(tmp.key<R[j].key){
R[i]=R[j];
i=j;
j=2*i;
}
else
break;
}
R[i]=tmp;
}
void HeapSort(RecType R[],int n){
int i;
RecType tmp;
for(i=n/2;i>=1;i--)
sift(R,i,n);
for(i=n;i>=2;i--)
{
tmp=R[1];
R[1]=R[i];
R[i]=tmp;
sift(R,1,i-1);
}
}8.归并排序基本思想:
将R[0..n-1]看成是n个长度为1的有序序列,然后进行两两归并,得到[n/2]个长度为2的有序序列,在进行两两归并。。。直到得到一个长度为n的有序序列。
C++代码:
void Merge(RecType R[],int low,int mid,int high){
RecType *R1;
int i=low,j=mid+1,k=0;
R1=(RecType*)malloc((high-low+1)*sizeof(RecType));
while(i<=mid && j<=high)
if(R[i].key<=R[j].key)
{
R1[k]=R[i];
i++;
k++;
}else{
R1[k]=R[j];
j++;
k++;
}
while(i<=mid){
R1[k]=R[i];
i++;
k++;
}
while(j<=high)
{
R1[k]=R[j];
j++;
k++;
}
for(k=0;i=low;i<=high;k++,i++)
R[i]=R1[k];
free(R1);
}总结:
各种排序方法的性能
稳定性:
排序算法的稳定性:若待排序的序列中,存在多个具有相同关键字的记录,经过排序,
这些记录的相对次序保持不变,则称该算法是稳定的;若经排序后,记录的相对 次序发生了改变,则称该算法是不稳定的。
稳定性的好处:排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。另外,如果排序算法稳定,可以避免多余的比较;
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序
选择排序算法准则:
每种排序算法都各有优缺点。因此,在实用时需根据不同情况适当选用,甚至可以将多种方法结合起来使用。
选择排序算法的依据
影响排序的因素有很多,平均时间复杂度低的算法并不一定就是最优的。相反,有时平均时间复杂度高的算法可能更适合某些特殊情况。同时,选择算法时还得考虑它的可读性,以利于软件的维护。一般而言,需要考虑的因素有以下四点:
1.待排序的记录数目n的大小;
2.记录本身数据量的大小,也就是记录中除关键字外的其他信息量的大小;
3.关键字的结构及其分布情况;
4.对排序稳定性的要求。
设待排序元素的个数为n.
1)当n较大,则应采用时间复杂度为O(nlog2n)的排序方法:快速排序、堆排序或归并排序序。
快速排序:是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
堆排序 : 如果内存空间允许且要求稳定性的,
归并排序:它有一定数量的数据移动,所以我们可能过与插入排序组合,先获得一定长度的序列,然后再合并,在效率上将有所提高。
2) 当n较大,内存空间允许,且要求稳定性 =》归并排序
3)当n较小,可采用直接插入或直接选择排序。
直接插入排序:当元素分布有序,直接插入排序将大大减少比较次数和移动记录的次数。
直接选择排序 :元素分布有序,如果不要求稳定性,选择直接选择排序
5)一般不使用或不直接使用传统的冒泡排序。
6)基数排序
它是一种稳定的排序算法,但有一定的局限性:
1、关键字可分解。
2、记录的关键字位数较少,如果密集更好
3、如果是数字时,最好是无符号的,否则将增加相应的映射复杂度,可先将其正负分开排序。

相关文章推荐
- 使用CXF框架学习搭建WebService(二)
- 一般线性规划求最小值+c语言
- MyEclipse 10, 2013, 2014 破解、注册码
- 判断两棵二叉树是否相等
- Java集合的用法和比较
- delphi 2007 远程调试
- 底层因为接受到操作系统信号而停止
- 详解C++编程中类的成员变量和成员函数的相关知识
- 网页中代码高亮插件SyntaxHighlighter
- java、java -version能正常运行、但javac不是内部或外部命令,有可能是变量位置问题!
- JAVA中科学计数法转换普通计数法
- [Asp.net]Uploadify上传大文件
- django 1.8 官方文档翻译:7-3 Django管理文档生成器
- java实现Telnet连接
- C语言基础复习
- Java编写简单三角形与菱形
- 时间函数
- ASP.NET MVC5网站开发文章管理架构(七)
- 抽象模式
- ThinkPHP 批量删除功能