Java HashMap 源码解析
2015-09-14 17:52
267 查看
Java HashMap 源码解析
继上一篇文章Java集合框架综述后,今天正式开始分析具体集合类的代码,首先以既熟悉又陌生的HashMap开始。
签名(signature)
123 | publicclassHashMap<K,V>extendsAbstractMap<K,V>implementsMap<K,V>, Cloneable, Serializable |
HashMap继承了
标记接口Cloneable,用于表明
HashMap对象会重写
java.lang.Object#clone()方法,HashMap实现的是浅拷贝(shallow
copy)。
标记接口Serializable,用于表明
HashMap对象可以被序列化
比较有意思的是,
HashMap同时继承了抽象类
AbstractMap与接口
Map,因为抽象类
AbstractMap的签名为
1 | publicabstractclassAbstractMap<K,V> implementsMap<K,V> |
Overfloooow上解释到:
在语法层面继承接口
Map是多余的,这么做仅仅是为了让阅读代码的人明确知道
HashMap是属于
Map体系的,起到了文档的作用
AbstractMap相当于个辅助类,
Map的一些操作这里面已经提供了默认实现,后面具体的子类如果没有特殊行为,可直接使用
AbstractMap提供的实现。
Cloneable接口
It's evil, don't use it.
Cloneable这个接口设计的非常不好,最致命的一点是它里面竟然没有
clone方法,也就是说我们自己写的类完全可以实现这个接口的同时不重写
clone方法。
关于
Cloneable的不足,大家可以去看看《Effective Java》一书的作者给出的理由,在所给链接的文章里,Josh
Bloch也会讲如何实现深拷贝比较好,我这里就不在赘述了。
Map接口
在eclipse中的outline面板可以看到Map接口里面包含以下成员方法与内部类:
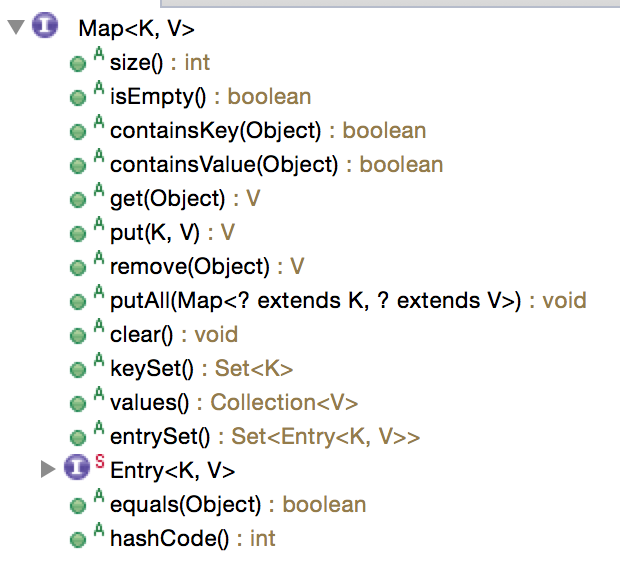
Map_field_method
可以看到,这里的成员方法不外乎是“增删改查”,这也反映了我们编写程序时,一定是以“数据”为导向的。
在上篇文章讲了
Map虽然并不是
Collection,但是它提供了三种“集合视角”(collection
views),与下面三个方法一一对应:
Set<K> keySet(),提供key的集合视角
Collection<V> values(),提供value的集合视角
Set<Map.Entry<K, V>> entrySet(),提供key-value序对的集合视角,这里用内部类
Map.Entry表示序对
AbstractMap抽象类
AbstractMap对
Map中的方法提供了一个基本实现,减少了实现
Map接口的工作量。
举例来说:
如果要实现个不可变(unmodifiable)的map,那么只需继承
AbstractMap,然后实现其
entrySet方法,这个方法返回的set不支持add与remove,同时这个set的迭代器(iterator)不支持remove操作即可。
相反,如果要实现个可变(modifiable)的map,首先继承
AbstractMap,然后重写(override)
AbstractMap的put方法,同时实现
entrySet所返回set的迭代器的remove方法即可。
设计理念(design concept)
哈希表(hash table)
HashMap是一种基于哈希表(hash
table)实现的map,哈希表(也叫关联数组)一种通用的数据结构,大多数的现代语言都原生支持,其概念也比较简单:
key经过hash函数作用后得到一个槽(buckets或slots)的索引(index),槽中保存着我们想要获取的值,如下图所示
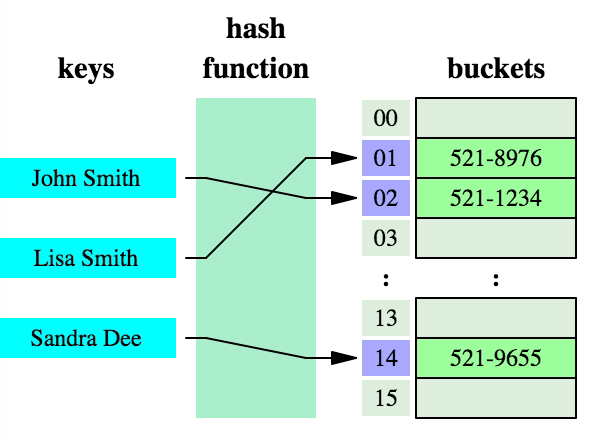
hash
table demo
很容易想到,一些不同的key经过同一hash函数后可能产生相同的索引,也就是产生了冲突,这是在所难免的。
所以利用哈希表这种数据结构实现具体类时,需要:
设计个好的hash函数,使冲突尽可能的减少
其次是需要解决发生冲突后如何处理。
后面会重点介绍
HashMap是如何解决这两个问题的。
HashMap的一些特点
线程非安全,并且允许key与value都为null值,HashTable与之相反,为线程安全,key与value都不允许null值。
不保证其内部元素的顺序,而且随着时间的推移,同一元素的位置也可能改变(resize的情况)
put、get操作的时间复杂度为O(1)。
遍历其集合视角的时间复杂度与其容量(capacity,槽的个数)和现有元素的大小(entry的个数)成正比,所以如果遍历的性能要求很高,不要把capactiy设置的过高或把平衡因子(load factor,当entry数大于capacity*loadFactor时,会进行resize,reside会导致key进行rehash)设置的过低。
由于HashMap是线程非安全的,这也就是意味着如果多个线程同时对一hashmap的集合试图做迭代时有结构的上改变(添加、删除entry,只改变entry的value的值不算结构改变),那么会报ConcurrentModificationException,专业术语叫
fail-fast,尽早报错对于多线程程序来说是很有必要的。
Map m = Collections.synchronizedMap(new HashMap(...));通过这种方式可以得到一个线程安全的map。
源码剖析
首先从构造函数开始讲,HashMap遵循集合框架的约束,提供了一个参数为空的构造函数与有一个参数且参数类型为Map的构造函数。除此之外,还提供了两个构造函数,用于设置
HashMap的容量(capacity)与平衡因子(loadFactor)。
1234567891011121314151617181920 | publicHashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)thrownew IllegalArgumentException("Illegal initial capacity: " + initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))thrownew IllegalArgumentException("Illegal load factor: " + loadFactor);this.loadFactor = loadFactor; threshold = initialCapacity; init();}publicHashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}publicHashMap() {this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);} |
12345678910111213141516 | /** * The default initial capacity - MUST be a power of two. */staticfinalint DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16/** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. */staticfinalint MAXIMUM_CAPACITY = 1 << 30;/** * The load factor used when none specified in constructor. */staticfinalfloat DEFAULT_LOAD_FACTOR = 0.75f; |

相关文章推荐
- Java中try catch finally语句中含return语句的执行情况总结-编程陷阱
- Java文件上传到服务器
- JDK动态代理
- Java 注解
- Java中数组和集合的区别
- MyEclipse快捷键使用方法(很实用)
- myeclipse中,项目上有个叉报错,文件没有错误【解决方案】
- myeclipse中jsp项目旁边有红色感叹号
- SpringMVC框架
- java try-catch以及循环的问题
- 【学习日记】集合框架知识点总结(3)--工具类
- Spring MVC and Excel file via AbstractJExcelView
- Java MyArrayList 示例
- Spring MVC and Excel file via AbstractExcelView
- Android 如何在Eclipse 引入外部纯Java项目(不是打成Jar使用)
- java生成日期
- Java中间MD5加密算法完整版
- 关于hadoop与jstl冲突问题java.lang.AbstractMethodError: javax.servlet.jsp.PageContext.getELContext()Ljavax/e
- Spring 3 MVC and JSON example
- Solr I 入门——环境搭建与创建core