推荐系统中常见的几种相似度计算方法和其适用数据
2015-08-27 18:45
357 查看
在推荐系统中,相似度的计算是一个很重要的课题。而相似度的计算方法多种多样,今天我们来把这些方法比较一下,也为以后做项目留个笔记。其实无论是基于user的cf还是基于item的cf,亦或是基于svd的推荐,相似度计算都是必不可少的一步,只不过cf中计算相似度是一个中间步骤,而svd中的计算是放在最后面的(例如计算最后的余弦夹角)。这篇文章我们以item-cf来举例说明。
共现次数
评价:这是最粗略的一种计算相似度的方法,只需计算待推荐物品与用户之前所选物品之间的共现次数,这个共现次数是从所有用户的角度看的。
适用数据:适合用户有explicit feedback,即用户对物品有评分情况的数据或者是没有explicit feedback的user-item的(1,0)矩阵。
余弦相似度
评价:这是使用最多一种相似度计算方法。如下所示:
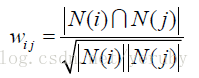
N(i)∩N(j)为物品i和j同是出现的情况。当然,这个计算方法页游很多变种,例如当我们考虑到用户活跃度问题的时候,我们会加一个修正项在里面,这样我们就突出了非活跃用户对于物品相似度的影响。
适用数据:多使用在implicit feedback中,不知道用户对物品的具体评分,只有user-item的(1,0)矩阵。
pearson相关系数
评价:也是比较常用的一种方法,跟余弦相似度的使用频度不相上下。皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,它的取值在 [-1,+1] 之间。
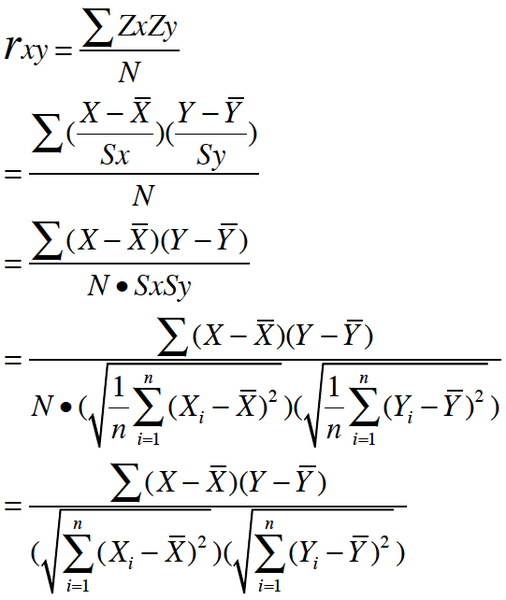
适用数据:多使用在有explicit feedback中,有具体评分的时候。
以上也是我在工程中常使用的方法。像欧几里得距离、Jaccard 系数等也有很多文献中提到,被运用于相似度计算中。从算法的角度来说,没有什么最优的相似度计算方法,这还是要根据自己的数据情况来做出选择。其实根据经验来看,不同的相似度计算方法对最后结果的影响其实是很小的,所以在选择的时候可以优先考虑其计算时间,不必太纠结于准确度这些。另外,这里我没有提到数据稀疏的问题,其实在推荐中,数据稀疏是一个几乎必须要面对的问题,而解决这个问题不应该留到相似度计算这一步,所以这里我将其忽略掉了。
共现次数
评价:这是最粗略的一种计算相似度的方法,只需计算待推荐物品与用户之前所选物品之间的共现次数,这个共现次数是从所有用户的角度看的。
适用数据:适合用户有explicit feedback,即用户对物品有评分情况的数据或者是没有explicit feedback的user-item的(1,0)矩阵。
余弦相似度
评价:这是使用最多一种相似度计算方法。如下所示:
N(i)∩N(j)为物品i和j同是出现的情况。当然,这个计算方法页游很多变种,例如当我们考虑到用户活跃度问题的时候,我们会加一个修正项在里面,这样我们就突出了非活跃用户对于物品相似度的影响。
适用数据:多使用在implicit feedback中,不知道用户对物品的具体评分,只有user-item的(1,0)矩阵。
pearson相关系数
评价:也是比较常用的一种方法,跟余弦相似度的使用频度不相上下。皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,它的取值在 [-1,+1] 之间。
适用数据:多使用在有explicit feedback中,有具体评分的时候。
以上也是我在工程中常使用的方法。像欧几里得距离、Jaccard 系数等也有很多文献中提到,被运用于相似度计算中。从算法的角度来说,没有什么最优的相似度计算方法,这还是要根据自己的数据情况来做出选择。其实根据经验来看,不同的相似度计算方法对最后结果的影响其实是很小的,所以在选择的时候可以优先考虑其计算时间,不必太纠结于准确度这些。另外,这里我没有提到数据稀疏的问题,其实在推荐中,数据稀疏是一个几乎必须要面对的问题,而解决这个问题不应该留到相似度计算这一步,所以这里我将其忽略掉了。
