java中volatile关键字的含义
2015-08-27 12:09
399 查看
在java线程并发处理中,有一个关键字volatile的使用目前存在很大的混淆,以为使用这个关键字,在进行多线程并发处理的时候就可以万事大吉。
Java语言是支持多线程的,为了解决线程并发的问题,在语言内部引入了 同步块 和 volatile 关键字机制。
synchronized
同步块大家都比较熟悉,通过 synchronized 关键字来实现,所有加上synchronized 和 块语句,在多线程访问的时候,同一时刻只能有一个线程能够用
synchronized 修饰的方法 或者 代码块。
volatile
用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最的值。volatile很容易被误用,用来进行原子性操作。
下面看一个例子,我们实现一个计数器,每次线程启动的时候,会调用计数器inc方法,对计数器进行加一
执行环境——jdk版本:jdk1.6.0_31 ,内存 :3G cpu:x86 2.4G
运行结果:Counter.count=992
运行结果还是没有我们期望的1000,下面我们分析一下原因
在 java 垃圾回收整理一文中,描述了jvm运行时刻内存的分配。其中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,
线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存
变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,
在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。下面一幅图
描述这写交互
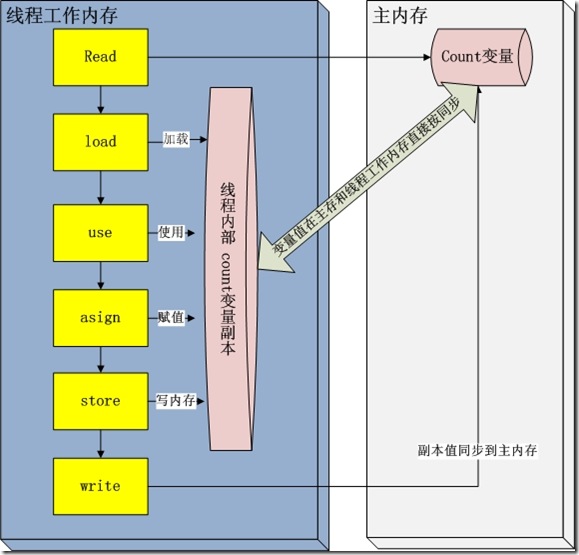
read and load 从主存复制变量到当前工作内存
use and assign 执行代码,改变共享变量值
store and write 用工作内存数据刷新主存相关内容
其中use and assign 可以多次出现
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样
对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的
例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值
在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6
线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6
导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
volatile关键字的作用
分类: C/C++
volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。下面举例说明。在DSP开发中,经常需要等待某个事件的触发,所以经常会写出这样的程序:
short flag;
void test()
{
do1();
while(flag==0);
do2();
}这段程序等待内存变量flag的值变为1(怀疑此处是0,有点疑问,)之后才运行do2()。变量flag的值由别的程序更改,这个程序可能是某个硬件中断服务程序。例如:如果某个按钮按下的话,就会对DSP产生中断,在按键中断程序中修改flag为1,这样上面的程序就能够得以继续运行。但是,编译器并不知道flag的值会被别的程序修改,因此在它进行优化的时候,可能会把flag的值先读入某个寄存器,然后等待那个寄存器变为1。如果不幸进行了这样的优化,那么while循环就变成了死循环,因为寄存器的内容不可能被中断服务程序修改。为了让程序每次都读取真正flag变量的值,就需要定义为如下形式:
volatile short flag;
需要注意的是,没有volatile也可能能正常运行,但是可能修改了编译器的优化级别之后就又不能正常运行了。因此经常会出现debug版本正常,但是release版本却不能正常的问题。所以为了安全起见,只要是等待别的程序修改某个变量的话,就加上volatile关键字。
C语言void及void指针深层探索
1.概述
本文将对void关键字的深刻含义进行解说,并详述void及void指针类型的使用方法与技巧。
2.void的含义
void的字面意思是“无类型”,void *则为“无类型指针”,void *可以指向任何类型的数据。
void几乎只有“注释”和限制程序的作用,因为从来没有人会定义一个void变量,让我们试着来定义:
void a;
这行语句编译时会出错,提示“illegal use of type 'void'”。不过,即使void a的编译不会出错,它也没有任何实际意义。
void真正发挥的作用在于:
(1) 对函数返回的限定;
(2) 对函数参数的限定。
我们将在第三节对以上二点进行具体说明。
众所周知,如果指针p1和p2的类型相同,那么我们可以直接在p1和p2间互相赋值;如果p1和p2指向不同的数据类型,则必须使用强制类型转换运算符把赋值运算符右边的指针类型转换为左边指针的类型。
例如:
float *p1;
int *p2;
p1 = p2;
其中p1 = p2语句会编译出错,提示“'=' : cannot convert from 'int *' to 'float *'”,必须改为:
p1 = (float *)p2;
而void *则不同,任何类型的指针都可以直接赋值给它,无需进行强制类型转换:
void *p1;
int *p2;
p1 = p2;
但这并不意味着,void *也可以无需强制类型转换地赋给其它类型的指针。因为“无类型”可以包容“有类型”,而“有类型”则不能包容“无类型”。道理很简单,我们可以说“男人和女人都是人”,但不能说“人是男人”或者“人是女人”。下面的语句编译出错:
void *p1;
int *p2;
p2 = p1;
提示“'=' : cannot convert from 'void *' to 'int *'”。
3.void的使用
下面给出void关键字的使用规则:
规则一 如果函数没有返回值,那么应声明为void类型
在C语言中,凡不加返回值类型限定的函数,就会被编译器作为返回整型值处理。但是许多程序员却误以为其为void类型。例如:
add ( int a, int b )
{
return a + b;
}
int main(int argc, char* argv[])
{
printf ( "2 + 3 = %d", add ( 2, 3) );
}
程序运行的结果为输出:
2 + 3 = 5
这说明不加返回值说明的函数的确为int函数。
林锐博士《高质量C/C++编程》中提到:“C++语言有很严格的类型安全检查,不允许上述情况(指函数不加类型声明)发生”。可是编译器并不一定这么认定,譬如在Visual C++6.0中上述add函数的编译无错也无警告且运行正确,所以不能寄希望于编译器会做严格的类型检查。
因此,为了避免混乱,我们在编写C/C++程序时,对于任何函数都必须一个不漏地指定其类型。如果函数没有返回值,一定要声明为void类型。这既是程序良好可读性的需要,也是编程规范性的要求。另外,加上void类型声明后,也可以发挥代码的“自注释”作用。代码的“自注释”即代码能自己注释自己。
规则二 如果函数无参数,那么应声明其参数为void
在C++语言中声明一个这样的函数:
int function(void)
{
return 1;
}
则进行下面的调用是不合法的:
function(2);
因为在C++中,函数参数为void的意思是这个函数不接受任何参数。
我们在Turbo C 2.0中编译:
#i nclude "stdio.h"
fun()
{
return 1;
}
main()
{
printf("%d",fun(2));
getchar();
}
编译正确且输出1,这说明,在C语言中,可以给无参数的函数传送任意类型的参数,但是在C++编译器中编译同样的代码则会出错。在C++中,不能向无参数的函数传送任何参数,出错提示“'fun' : function does not take 1 parameters”。
所以,无论在C还是C++中,若函数不接受任何参数,一定要指明参数为void。
规则三 小心使用void指针类型
按照ANSI(American National Standards Institute)标准,不能对void指针进行算法操作,即下列操作都是不合法的:
void * pvoid;
pvoid++; //ANSI:错误
pvoid += 1; //ANSI:错误
//ANSI标准之所以这样认定,是因为它坚持:进行算法操作的指针必须是确定知道其指向数据类型大小的。
//例如:
int *pint;
pint++; //ANSI:正确
pint++的结果是使其增大sizeof(int)。
但是大名鼎鼎的GNU(GNU's Not Unix的缩写)则不这么认定,它指定void *的算法操作与char *一致。
因此下列语句在GNU编译器中皆正确:
pvoid++; //GNU:正确
pvoid += 1; //GNU:正确
pvoid++的执行结果是其增大了1。
在实际的程序设计中,为迎合ANSI标准,并提高程序的可移植性,我们可以这样编写实现同样功能的代码:
void * pvoid;
(char *)pvoid++; //ANSI:正确;GNU:正确
(char *)pvoid += 1; //ANSI:错误;GNU:正确
GNU和ANSI还有一些区别,总体而言,GNU较ANSI更“开放”,提供了对更多语法的支持。但是我们在真实设计时,还是应该尽可能地迎合ANSI标准。
规则四 如果函数的参数可以是任意类型指针,那么应声明其参数为void *
典型的如内存操作函数memcpy和memset的函数原型分别为:
void * memcpy(void *dest, const void *src, size_t len);
void * memset ( void * buffer, int c, size_t num );
这样,任何类型的指针都可以传入memcpy和memset中,这也真实地体现了内存操作函数的意义,因为它操作的对象仅仅是一片内存,而不论这片内存是什么类型。如果memcpy和memset的参数类型不是void *,而是char *,那才叫真的奇怪了!这样的memcpy和memset明显不是一个“纯粹的,脱离低级趣味的”函数!
下面的代码执行正确:
//示例:memset接受任意类型指针
int intarray[100];
memset ( intarray, 0, 100*sizeof(int) ); //将intarray清0
//示例:memcpy接受任意类型指针
int intarray1[100], intarray2[100];
memcpy ( intarray1, intarray2, 100*sizeof(int) ); //将intarray2拷贝给intarray1
有趣的是,memcpy和memset函数返回的也是void *类型,标准库函数的编写者是多么地富有学问啊!
规则五 void不能代表一个真实的变量
下面代码都企图让void代表一个真实的变量,因此都是错误的代码:
void a; //错误
function(void a); //错误
void体现了一种抽象,这个世界上的变量都是“有类型”的,譬如一个人不是男人就是女人.
void的出现只是为了一种抽象的需要,如果你正确地理解了面向对象中“抽象基类”的概念,也很容易理解void数据类型。正如不能给抽象基类定义一个实例,我们也不能定义一个void(让我们类比的称void为“抽象数据类型”)变量。
关于CONST的用法
const在C语言中算是一个比较新的描述符,我们称之为常量修饰符,意即其所修饰
的对象为常量(immutable)。
我们来分情况看语法上它该如何被使用。
1、函数体内修饰局部变量。
例:
void func(){
const int a=0;
}
首先,我们先把const这个单词忽略不看,那么a是一个int类型的局部自动变量,
我们给它赋予初始值0。
然后再看const.
const作为一个类型限定词,和int有相同的地位。
const int a;
int const a;
是等价的。于是此处我们一定要清晰的明白,const修饰的对象是谁,是a,和int没
有关系。const 要求他所修饰的对象为常量,不可被改变,不可被赋值,不可作为
左值(l-value)。
这样的写法也是错误的。
const int a;
a=0;
这是一个很常见的使用方式:
const double pi=3.14;
在程序的后面如果企图对pi再次赋值或者修改就会出错。
然后看一个稍微复杂的例子。
const int* p;
还是先去掉const 修饰符号。
注意,下面两个是等价的。
int* p;
int *p;
其实我们想要说的是,*p是int类型。那么显然,p就是指向int的指针。
同理
const int* p;
其实等价于
const int (*p);
int const (*p);
即,*p是常量。也就是说,p指向的数据是常量。
于是
p+=8; //合法
*p=3; //非法,p指向的数据是常量。
那么如何声明一个自身是常量指针呢?方法是让const尽可能的靠近p;
int* const p;
const右面只有p,显然,它修饰的是p,说明p不可被更改。然后把const去掉,可以
看出p是一个指向 int形式变量的指针。
于是
p+=8; //非法
*p=3; //合法
再看一个更复杂的例子,它是上面二者的综合
const int* const p;
说明p自己是常量,且p指向的变量也是常量。
于是
p+=8; //非法
*p=3; //非法
const 还有一个作用就是用于修饰常量静态字符串。
例如:
const char* name="David";
如果没有const,我们可能会在后面有意无意的写name[4]='x'这样的语句,这样会
导致对只读内存区域的赋值,然后程序会立刻异常终止。有了 const,这个错误就
能在程序被编译的时候就立即检查出来,这就是const的好处。让逻辑错误在编译
期被发现。
const 还可以用来修饰数组
const char s[]="David";
与上面有类似的作用。
2、在函数声明时修饰参数
来看实际中的一个例子。
NAME
memmove -- copy byte string
LIBRARY
Standard C Library (libc, -lc)
SYNOPSIS
#i nclude
void *
memmove(void *dst, const void *src, size_t len);
这是标准库中的一个函数,用于按字节方式复制字符串(内存)。
它的第一个参数,是将字符串复制到哪里去(dest),是目的地,这段内存区域必须
是可写。
它的第二个参数,是要将什么样的字符串复制出去,我们对这段内存区域只做读
取,不写。
于是,我们站在这个函数自己的角度来看,src 这个指针,它所指向的内存内所存
储的数据在整个函数执行的过程中是不变。于是src所指向的内容是常量。于是就
需要用const修饰。
例如,我们这里这样使用它。
const char* s="hello";
char buf[100];
memmove(buf,s,6); //这里其实应该用strcpy或memcpy更好
如果我们反过来写,
memmove(s,buf,6);
那么编译器一定会报错。事实是我们经常会把各种函数的参数顺序写反。事实是编
译器在此时帮了我们大忙。如果编译器静悄悄的不报错,(在函数声明处去掉
const即可),那么这个程序在运行的时候一定会崩溃。
这里还要说明的一点是在函数参数声明中const一般用来声明指针而不是变量本身。
例如,上面的size_t len,在函数实现的时候可以完全不用更改len的值,那么是否
应该把len也声明为常量呢?可以,可以这么做。我们来分析这么做有什么优劣。
如果加了const,那么对于这个函数的实现者,可以防止他在实现这个函数的时候修
改不需要修改的值(len),这样很好。
但是对于这个函数的使用者,
1。这个修饰符号毫无意义,我们可以传递一个常量整数或者一个非常量整数过
去,反正对方获得的只是我们传递的一个copy。
2。暴露了实现。我不需要知道你在实现这个函数的时候是否修改过len的值。
所以,const一般只用来修饰指针。
再看一个复杂的例子
int execv(const char *path, char *const argv[]);
着重看后面这个,argv.它代表什么。
如果去掉const,我们可以看出
char * argv[];
argv是一个数组,它的每个元素都是char *类型的指针。
如果加上const.那么const修饰的是谁呢?他修饰的是一个数组,argv[],意思就是
说这个数组的元素是只读的。那么数组的元素的是什么类型呢?是char *类型的指
针.也就是说指针是常量,而它指向的数据不是。
于是
argv[1]=NULL; //非法
argv[0][0]='a'; //合法
3、全局变量。
我们的原则依然是,尽可能少的使用全局变量。
我们的第二条规则 则是,尽可能多的使用const。
如果一个全局变量只在本文件中使用,那么用法和前面所说的函数局部变量没有什
么区别。
如果它要在多个文件间共享,那么就牵扯到一个存储类型的问题。
有两种方式。
1.使用extern
例如
/* file1.h */
extern const double pi;
/* file1.c */
const double pi=3.14;
然后其他需要使用pi这个变量的,包含file1.h
#i nclude "file1.h"
或者,自己把那句声明复制一遍就好。
这样做的结果是,整个程序链接完后,所有需要使用pi这个变量的共享一个存储区域。
2.使用static,静态外部存储类
/* constant.h */
static const pi=3.14;
需要使用这个变量的*.c文件中,必须包含这个头文件。
前面的static一定不能少。否则链接的时候会报告说该变量被多次定义。
这样做的结果是,每个包含了constant.h的*.c文件,都有一份该变量自己的copy,
该变量实际上还是被定义了多次,占用了多个存储空间,不过在加了static关键字
后,解决了文件间重定义的冲突。
坏处是浪费了存储空间,导致链接完后的可执行文件变大。但是通常,这个,小小
几字节的变化,不是问题。
好处是,你不用关心这个变量是在哪个文件中被初始化的。
最后,说说const的作用。
const 的好处,是引入了常量的概念,让我们不要去修改不该修改的内存。直接的
作用就是让更多的逻辑错误在编译期被发现。所以我们要尽可能的多使用const。
但是很多人并不习惯使用它,更有甚者,是在整个程序 编写/调试 完后才补
const。如果是给函数的声明补const,尚好。如果是给 全局/局部变量补const,那
么……那么,为时已晚,无非是让代码看起来更漂亮了。
联 合(union)
1. 联合说明和联合变量定义
联合也是一种新的数据类型, 它是一种特殊形式的变量。
联合说明和联合变量定义与结构十分相似。其形式为:
union 联合名{
数据类型成员名;
数据类型成员名;
...
} 联合变量名;
联合表示几个变量公用一个内存位置, 在不同的时间保存不同的数据类型 和不同长度的变量。
下例表示说明一个联合a_bc:
union a_bc{
int i;
char mm;
};
再用已说明的联合可定义联合变量。
例如用上面说明的联合定义一个名为lgc的联合变量, 可写成:
union a_bc lgc;
在联合变量lgc中, 整型量i和字符mm公用同一内存位置。
当一个联合被说明时, 编译程序自动地产生一个变量, 其长度为联合中最大的变量长度。
联合访问其成员的方法与结构相同。同样联合变量也可以定义成数组或指针,但定义为指针时, 也要用"->;"符号, 此时联合访问成员可表示成:
联合名->;成员名
另外, 联合既可以出现在结构内, 它的成员也可以是结构。
例如:
struct{
int age;
char *addr;
union{
int i;
char *ch;
}x;
}y[10];
若要访问结构变量y[1]中联合x的成员i, 可以写成:
y[1].x.i;
若要访问结构变量y[2]中联合x的字符串指针ch的第一个字符可写成:
*y[2].x.ch;
若写成"y[2].x.*ch;"是错误的。
2. 结构和联合的区别
结构和联合有下列区别:
1. 结构和联合都是由多个不同的数据类型成员组成, 但在任何同一时刻, 联合转只存放了一个被选中的成员, 而结构的所有成员都存在。
2. 对于联合的不同成员赋值, 将会对其它成员重写, 原来成员的值就不存在了, 而对于结构的不同成员赋值是互不影响的。
下面举一个例了来加对深联合的理解。
例4:
main()
{
union{ /*定义一个联合*/
int i;
struct{ /*在联合中定义一个结构*/
char first;
char second;
}half;
}number;
number.i=0x4241; /*联合成员赋值*/
printf("%c%c\n", number.half.first, mumber.half.second);
number.half.first='a'; /*联合中结构成员赋值*/
number.half.second='b';
printf("%x\n", number.i);
getch();
}
输出结果为:
AB
6261
从上例结果可以看出: 当给i赋值后, 其低八位也就是first和second的值;当给first和second赋字符后, 这两个字符的ASCII码也将作为i 的低八位和高八位。
关于c中volatile关键字
一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份。下面是volatile变量的几个例子:
1). 并行设备的硬件寄存器(如:状态寄存器)
2). 一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
3). 多线程应用中被几个任务共享的变量
回答不出这个问题的人是不会被雇佣的。我认为这是区分C程序员和嵌入式系统程序员的最基本的问题。嵌入式系统程序员经常同硬件、中断、RTOS等等打交道,所用这些都要求volatile变量。不懂得volatile内容将会带来灾难。
假设被面试者正确地回答了这是问题(嗯,怀疑这否会是这样),我将稍微深究一下,看一下这家伙是不是直正懂得volatile完全的重要性。
1). 一个参数既可以是const还可以是volatile吗?解释为什么。
2). 一个指针可以是volatile 吗?解释为什么。
3). 下面的函数有什么错误:
int square(volatile int *ptr)
{
return *ptr * *ptr;
}
下面是答案:
1). 是的。一个例子是只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。
2). 是的。尽管这并不很常见。一个例子是当一个中服务子程序修该一个指向一个buffer的指针时。
3). 这段代码的有个恶作剧。这段代码的目的是用来返指针*ptr指向值的平方,但是,由于*ptr指向一个volatile型参数,编译器将产生类似下面的代码:
int square(volatile int *ptr)
{
int a,b;
a = *ptr;
b = *ptr;
return a * b;
}
由于*ptr的值可能被意想不到地该变,因此a和b可能是不同的。结果,这段代码可能返不是你所期望的平方值!正确的代码如下:
long square(volatile int *ptr)
{
int a;
a = *ptr;
return a * a;
}
Volatile 关键字告诉编译器不要持有变量的临时性拷贝。一般用在多线程程序中,以避免在其中一个线程操作该变量时,将其拷贝入寄存器。请看以下情形:
A线程将变量复制入寄存器,然后进入循环,反复检测寄存器的值是否满足一定条件(它期待B线程改变变量的值。
在此种情况下,当B线程改变了变量的值时,已改变的值对其在寄存器的值没有影响。所以A线程进入死循环。
volatile 就是在此种情况下使用。
volatile 提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有 volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。下面举例说明。在DSP开发中,经常需要等待某个事件的触发,所以经常会写出这样的程序:
short flag;
void test()
{
do1();
while(flag==0);
do2();
} 这段程序等待内存变量flag的值变为1(怀疑此处是0,有点疑问,)之后才运行do2()。变量flag的值由别的程序更改,这个程序可能是某个硬件中断服务程序。例如:如果某个按钮按下的话,就会对DSP产生中断,在按键中断程序中修改flag为1,这样上面的程序就能够得以继续运行。但是,编译器并不知道flag的值会被别的程序修改,因此在它进行优化的时候,可能会把flag的值先读入某个寄存器,然后等待那个寄存器变为1。如果不幸进行了这样的优化,那么while循环就变成了死循环,因为寄存器的内容不可能被中断服务程序修改。为了让程序每次都读取真正flag变量的值,就需要定义为如下形式:
volatile short flag;
需要注意的是,没有volatile也可能能正常运行,但是可能修改了编译器的优化级别之后就又不能正常运行了。因此经常会出现debug版本正常,但是release版本却不能正常的问题。所以为了安全起见,只要是等待别的程序修改某个变量的话,就加上volatile关键字。
volatile的本意是“易变的”
由于访问寄存器的速度要快过RAM,所以编译器一般都会作减少存取外部RAM的优化。比如:
static int i=0;
int main(void)
{
...
while (1)
{
if (i) do_something();
}
}
/* Interrupt service routine. */
void ISR_2(void)
{
i=1;
}
程序的本意是希望ISR_2中断产生时,在main当中调用do_something函数,但是,由于编译器判断在main函数里面没有修改过i,因此可能只执行一次对从i到某寄存器的读操作,然后每次if判断都只使用这个寄存器里面的“i副本”,导致do_something永远也不会被调用。如果将将变量加上volatile修饰,则编译器保证对此变量的读写操作都不会被优化(肯定执行)。此例中i也应该如此说明。
一般说来,volatile用在如下的几个地方:
1、中断服务程序中修改的供其它程序检测的变量需要加volatile;
2、多任务环境下各任务间共享的标志应该加volatile;
3、存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义;
另外,以上这几种情况经常还要同时考虑数据的完整性(相互关联的几个标志读了一半被打断了重写),在1中可以通过关中断来实现,2中可以禁止任务调度,3中则只能依靠硬件的良好设计了。
volatile 的含义
volatile总是与优化有关,编译器有一种技术叫做数据流分析,分析程序中的变量在哪里赋值、在哪里使用、在哪里失效,分析结果可以用于常量合并,常量传播等优化,进一步可以死代码消除。但有时这些优化不是程序所需要的,这时可以用volatile关键字禁止做这些优化,volatile的字面含义是易变的,它有下面的作用:
1 不会在两个操作之间把volatile变量缓存在寄存器中。在多任务、中断、甚至setjmp环境下,变量可能被其他的程序改变,编译器自己无法知道,volatile就是告诉编译器这种情况。
2 不做常量合并、常量传播等优化,所以像下面的代码:
volatile int i = 1;
if (i > 0) ...
if的条件不会当作无条件真。
3 对volatile变量的读写不会被优化掉。如果你对一个变量赋值但后面没用到,编译器常常可以省略那个赋值操作,然而对Memory Mapped IO的处理是不能这样优化的。
前面有人说volatile可以保证对内存操作的原子性,这种说法不大准确,其一,x86需要LOCK前缀才能在SMP下保证原子性,其二,RISC根本不能对内存直接运算,要保证原子性得用别的方法,如atomic_inc。
对于jiffies,它已经声明为volatile变量,我认为直接用jiffies++就可以了,没必要用那种复杂的形式,因为那样也不能保证原子性。
你可能不知道在Pentium及后续CPU中,下面两组指令
inc jiffies
;;
mov jiffies, %eax
inc %eax
mov %eax, jiffies
作用相同,但一条指令反而不如三条指令快。
文章出处:DIY部落(http://www.diybl.com/course/6_system/linux/Linuxjs/20090213/155402.html)
Java语言是支持多线程的,为了解决线程并发的问题,在语言内部引入了 同步块 和 volatile 关键字机制。
synchronized
同步块大家都比较熟悉,通过 synchronized 关键字来实现,所有加上synchronized 和 块语句,在多线程访问的时候,同一时刻只能有一个线程能够用
synchronized 修饰的方法 或者 代码块。
volatile
用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最的值。volatile很容易被误用,用来进行原子性操作。
下面看一个例子,我们实现一个计数器,每次线程启动的时候,会调用计数器inc方法,对计数器进行加一
执行环境——jdk版本:jdk1.6.0_31 ,内存 :3G cpu:x86 2.4G
运行结果还是没有我们期望的1000,下面我们分析一下原因
在 java 垃圾回收整理一文中,描述了jvm运行时刻内存的分配。其中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,
线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存
变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,
在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。下面一幅图
描述这写交互

read and load 从主存复制变量到当前工作内存
use and assign 执行代码,改变共享变量值
store and write 用工作内存数据刷新主存相关内容
其中use and assign 可以多次出现
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样
对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的
例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值
在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6
线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6
导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
volatile关键字的作用
分类: C/C++
volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。下面举例说明。在DSP开发中,经常需要等待某个事件的触发,所以经常会写出这样的程序:
short flag;
void test()
{
do1();
while(flag==0);
do2();
}这段程序等待内存变量flag的值变为1(怀疑此处是0,有点疑问,)之后才运行do2()。变量flag的值由别的程序更改,这个程序可能是某个硬件中断服务程序。例如:如果某个按钮按下的话,就会对DSP产生中断,在按键中断程序中修改flag为1,这样上面的程序就能够得以继续运行。但是,编译器并不知道flag的值会被别的程序修改,因此在它进行优化的时候,可能会把flag的值先读入某个寄存器,然后等待那个寄存器变为1。如果不幸进行了这样的优化,那么while循环就变成了死循环,因为寄存器的内容不可能被中断服务程序修改。为了让程序每次都读取真正flag变量的值,就需要定义为如下形式:
volatile short flag;
需要注意的是,没有volatile也可能能正常运行,但是可能修改了编译器的优化级别之后就又不能正常运行了。因此经常会出现debug版本正常,但是release版本却不能正常的问题。所以为了安全起见,只要是等待别的程序修改某个变量的话,就加上volatile关键字。
C语言void及void指针深层探索
1.概述
本文将对void关键字的深刻含义进行解说,并详述void及void指针类型的使用方法与技巧。
2.void的含义
void的字面意思是“无类型”,void *则为“无类型指针”,void *可以指向任何类型的数据。
void几乎只有“注释”和限制程序的作用,因为从来没有人会定义一个void变量,让我们试着来定义:
void a;
这行语句编译时会出错,提示“illegal use of type 'void'”。不过,即使void a的编译不会出错,它也没有任何实际意义。
void真正发挥的作用在于:
(1) 对函数返回的限定;
(2) 对函数参数的限定。
我们将在第三节对以上二点进行具体说明。
众所周知,如果指针p1和p2的类型相同,那么我们可以直接在p1和p2间互相赋值;如果p1和p2指向不同的数据类型,则必须使用强制类型转换运算符把赋值运算符右边的指针类型转换为左边指针的类型。
例如:
float *p1;
int *p2;
p1 = p2;
其中p1 = p2语句会编译出错,提示“'=' : cannot convert from 'int *' to 'float *'”,必须改为:
p1 = (float *)p2;
而void *则不同,任何类型的指针都可以直接赋值给它,无需进行强制类型转换:
void *p1;
int *p2;
p1 = p2;
但这并不意味着,void *也可以无需强制类型转换地赋给其它类型的指针。因为“无类型”可以包容“有类型”,而“有类型”则不能包容“无类型”。道理很简单,我们可以说“男人和女人都是人”,但不能说“人是男人”或者“人是女人”。下面的语句编译出错:
void *p1;
int *p2;
p2 = p1;
提示“'=' : cannot convert from 'void *' to 'int *'”。
3.void的使用
下面给出void关键字的使用规则:
规则一 如果函数没有返回值,那么应声明为void类型
在C语言中,凡不加返回值类型限定的函数,就会被编译器作为返回整型值处理。但是许多程序员却误以为其为void类型。例如:
add ( int a, int b )
{
return a + b;
}
int main(int argc, char* argv[])
{
printf ( "2 + 3 = %d", add ( 2, 3) );
}
程序运行的结果为输出:
2 + 3 = 5
这说明不加返回值说明的函数的确为int函数。
林锐博士《高质量C/C++编程》中提到:“C++语言有很严格的类型安全检查,不允许上述情况(指函数不加类型声明)发生”。可是编译器并不一定这么认定,譬如在Visual C++6.0中上述add函数的编译无错也无警告且运行正确,所以不能寄希望于编译器会做严格的类型检查。
因此,为了避免混乱,我们在编写C/C++程序时,对于任何函数都必须一个不漏地指定其类型。如果函数没有返回值,一定要声明为void类型。这既是程序良好可读性的需要,也是编程规范性的要求。另外,加上void类型声明后,也可以发挥代码的“自注释”作用。代码的“自注释”即代码能自己注释自己。
规则二 如果函数无参数,那么应声明其参数为void
在C++语言中声明一个这样的函数:
int function(void)
{
return 1;
}
则进行下面的调用是不合法的:
function(2);
因为在C++中,函数参数为void的意思是这个函数不接受任何参数。
我们在Turbo C 2.0中编译:
#i nclude "stdio.h"
fun()
{
return 1;
}
main()
{
printf("%d",fun(2));
getchar();
}
编译正确且输出1,这说明,在C语言中,可以给无参数的函数传送任意类型的参数,但是在C++编译器中编译同样的代码则会出错。在C++中,不能向无参数的函数传送任何参数,出错提示“'fun' : function does not take 1 parameters”。
所以,无论在C还是C++中,若函数不接受任何参数,一定要指明参数为void。
规则三 小心使用void指针类型
按照ANSI(American National Standards Institute)标准,不能对void指针进行算法操作,即下列操作都是不合法的:
void * pvoid;
pvoid++; //ANSI:错误
pvoid += 1; //ANSI:错误
//ANSI标准之所以这样认定,是因为它坚持:进行算法操作的指针必须是确定知道其指向数据类型大小的。
//例如:
int *pint;
pint++; //ANSI:正确
pint++的结果是使其增大sizeof(int)。
但是大名鼎鼎的GNU(GNU's Not Unix的缩写)则不这么认定,它指定void *的算法操作与char *一致。
因此下列语句在GNU编译器中皆正确:
pvoid++; //GNU:正确
pvoid += 1; //GNU:正确
pvoid++的执行结果是其增大了1。
在实际的程序设计中,为迎合ANSI标准,并提高程序的可移植性,我们可以这样编写实现同样功能的代码:
void * pvoid;
(char *)pvoid++; //ANSI:正确;GNU:正确
(char *)pvoid += 1; //ANSI:错误;GNU:正确
GNU和ANSI还有一些区别,总体而言,GNU较ANSI更“开放”,提供了对更多语法的支持。但是我们在真实设计时,还是应该尽可能地迎合ANSI标准。
规则四 如果函数的参数可以是任意类型指针,那么应声明其参数为void *
典型的如内存操作函数memcpy和memset的函数原型分别为:
void * memcpy(void *dest, const void *src, size_t len);
void * memset ( void * buffer, int c, size_t num );
这样,任何类型的指针都可以传入memcpy和memset中,这也真实地体现了内存操作函数的意义,因为它操作的对象仅仅是一片内存,而不论这片内存是什么类型。如果memcpy和memset的参数类型不是void *,而是char *,那才叫真的奇怪了!这样的memcpy和memset明显不是一个“纯粹的,脱离低级趣味的”函数!
下面的代码执行正确:
//示例:memset接受任意类型指针
int intarray[100];
memset ( intarray, 0, 100*sizeof(int) ); //将intarray清0
//示例:memcpy接受任意类型指针
int intarray1[100], intarray2[100];
memcpy ( intarray1, intarray2, 100*sizeof(int) ); //将intarray2拷贝给intarray1
有趣的是,memcpy和memset函数返回的也是void *类型,标准库函数的编写者是多么地富有学问啊!
规则五 void不能代表一个真实的变量
下面代码都企图让void代表一个真实的变量,因此都是错误的代码:
void a; //错误
function(void a); //错误
void体现了一种抽象,这个世界上的变量都是“有类型”的,譬如一个人不是男人就是女人.
void的出现只是为了一种抽象的需要,如果你正确地理解了面向对象中“抽象基类”的概念,也很容易理解void数据类型。正如不能给抽象基类定义一个实例,我们也不能定义一个void(让我们类比的称void为“抽象数据类型”)变量。
关于CONST的用法
const在C语言中算是一个比较新的描述符,我们称之为常量修饰符,意即其所修饰
的对象为常量(immutable)。
我们来分情况看语法上它该如何被使用。
1、函数体内修饰局部变量。
例:
void func(){
const int a=0;
}
首先,我们先把const这个单词忽略不看,那么a是一个int类型的局部自动变量,
我们给它赋予初始值0。
然后再看const.
const作为一个类型限定词,和int有相同的地位。
const int a;
int const a;
是等价的。于是此处我们一定要清晰的明白,const修饰的对象是谁,是a,和int没
有关系。const 要求他所修饰的对象为常量,不可被改变,不可被赋值,不可作为
左值(l-value)。
这样的写法也是错误的。
const int a;
a=0;
这是一个很常见的使用方式:
const double pi=3.14;
在程序的后面如果企图对pi再次赋值或者修改就会出错。
然后看一个稍微复杂的例子。
const int* p;
还是先去掉const 修饰符号。
注意,下面两个是等价的。
int* p;
int *p;
其实我们想要说的是,*p是int类型。那么显然,p就是指向int的指针。
同理
const int* p;
其实等价于
const int (*p);
int const (*p);
即,*p是常量。也就是说,p指向的数据是常量。
于是
p+=8; //合法
*p=3; //非法,p指向的数据是常量。
那么如何声明一个自身是常量指针呢?方法是让const尽可能的靠近p;
int* const p;
const右面只有p,显然,它修饰的是p,说明p不可被更改。然后把const去掉,可以
看出p是一个指向 int形式变量的指针。
于是
p+=8; //非法
*p=3; //合法
再看一个更复杂的例子,它是上面二者的综合
const int* const p;
说明p自己是常量,且p指向的变量也是常量。
于是
p+=8; //非法
*p=3; //非法
const 还有一个作用就是用于修饰常量静态字符串。
例如:
const char* name="David";
如果没有const,我们可能会在后面有意无意的写name[4]='x'这样的语句,这样会
导致对只读内存区域的赋值,然后程序会立刻异常终止。有了 const,这个错误就
能在程序被编译的时候就立即检查出来,这就是const的好处。让逻辑错误在编译
期被发现。
const 还可以用来修饰数组
const char s[]="David";
与上面有类似的作用。
2、在函数声明时修饰参数
来看实际中的一个例子。
NAME
memmove -- copy byte string
LIBRARY
Standard C Library (libc, -lc)
SYNOPSIS
#i nclude
void *
memmove(void *dst, const void *src, size_t len);
这是标准库中的一个函数,用于按字节方式复制字符串(内存)。
它的第一个参数,是将字符串复制到哪里去(dest),是目的地,这段内存区域必须
是可写。
它的第二个参数,是要将什么样的字符串复制出去,我们对这段内存区域只做读
取,不写。
于是,我们站在这个函数自己的角度来看,src 这个指针,它所指向的内存内所存
储的数据在整个函数执行的过程中是不变。于是src所指向的内容是常量。于是就
需要用const修饰。
例如,我们这里这样使用它。
const char* s="hello";
char buf[100];
memmove(buf,s,6); //这里其实应该用strcpy或memcpy更好
如果我们反过来写,
memmove(s,buf,6);
那么编译器一定会报错。事实是我们经常会把各种函数的参数顺序写反。事实是编
译器在此时帮了我们大忙。如果编译器静悄悄的不报错,(在函数声明处去掉
const即可),那么这个程序在运行的时候一定会崩溃。
这里还要说明的一点是在函数参数声明中const一般用来声明指针而不是变量本身。
例如,上面的size_t len,在函数实现的时候可以完全不用更改len的值,那么是否
应该把len也声明为常量呢?可以,可以这么做。我们来分析这么做有什么优劣。
如果加了const,那么对于这个函数的实现者,可以防止他在实现这个函数的时候修
改不需要修改的值(len),这样很好。
但是对于这个函数的使用者,
1。这个修饰符号毫无意义,我们可以传递一个常量整数或者一个非常量整数过
去,反正对方获得的只是我们传递的一个copy。
2。暴露了实现。我不需要知道你在实现这个函数的时候是否修改过len的值。
所以,const一般只用来修饰指针。
再看一个复杂的例子
int execv(const char *path, char *const argv[]);
着重看后面这个,argv.它代表什么。
如果去掉const,我们可以看出
char * argv[];
argv是一个数组,它的每个元素都是char *类型的指针。
如果加上const.那么const修饰的是谁呢?他修饰的是一个数组,argv[],意思就是
说这个数组的元素是只读的。那么数组的元素的是什么类型呢?是char *类型的指
针.也就是说指针是常量,而它指向的数据不是。
于是
argv[1]=NULL; //非法
argv[0][0]='a'; //合法
3、全局变量。
我们的原则依然是,尽可能少的使用全局变量。
我们的第二条规则 则是,尽可能多的使用const。
如果一个全局变量只在本文件中使用,那么用法和前面所说的函数局部变量没有什
么区别。
如果它要在多个文件间共享,那么就牵扯到一个存储类型的问题。
有两种方式。
1.使用extern
例如
/* file1.h */
extern const double pi;
/* file1.c */
const double pi=3.14;
然后其他需要使用pi这个变量的,包含file1.h
#i nclude "file1.h"
或者,自己把那句声明复制一遍就好。
这样做的结果是,整个程序链接完后,所有需要使用pi这个变量的共享一个存储区域。
2.使用static,静态外部存储类
/* constant.h */
static const pi=3.14;
需要使用这个变量的*.c文件中,必须包含这个头文件。
前面的static一定不能少。否则链接的时候会报告说该变量被多次定义。
这样做的结果是,每个包含了constant.h的*.c文件,都有一份该变量自己的copy,
该变量实际上还是被定义了多次,占用了多个存储空间,不过在加了static关键字
后,解决了文件间重定义的冲突。
坏处是浪费了存储空间,导致链接完后的可执行文件变大。但是通常,这个,小小
几字节的变化,不是问题。
好处是,你不用关心这个变量是在哪个文件中被初始化的。
最后,说说const的作用。
const 的好处,是引入了常量的概念,让我们不要去修改不该修改的内存。直接的
作用就是让更多的逻辑错误在编译期被发现。所以我们要尽可能的多使用const。
但是很多人并不习惯使用它,更有甚者,是在整个程序 编写/调试 完后才补
const。如果是给函数的声明补const,尚好。如果是给 全局/局部变量补const,那
么……那么,为时已晚,无非是让代码看起来更漂亮了。
| c语言中的结构(struct)和联合(union)简介 |
1. 联合说明和联合变量定义
联合也是一种新的数据类型, 它是一种特殊形式的变量。
联合说明和联合变量定义与结构十分相似。其形式为:
union 联合名{
数据类型成员名;
数据类型成员名;
...
} 联合变量名;
联合表示几个变量公用一个内存位置, 在不同的时间保存不同的数据类型 和不同长度的变量。
下例表示说明一个联合a_bc:
union a_bc{
int i;
char mm;
};
再用已说明的联合可定义联合变量。
例如用上面说明的联合定义一个名为lgc的联合变量, 可写成:
union a_bc lgc;
在联合变量lgc中, 整型量i和字符mm公用同一内存位置。
当一个联合被说明时, 编译程序自动地产生一个变量, 其长度为联合中最大的变量长度。
联合访问其成员的方法与结构相同。同样联合变量也可以定义成数组或指针,但定义为指针时, 也要用"->;"符号, 此时联合访问成员可表示成:
联合名->;成员名
另外, 联合既可以出现在结构内, 它的成员也可以是结构。
例如:
struct{
int age;
char *addr;
union{
int i;
char *ch;
}x;
}y[10];
若要访问结构变量y[1]中联合x的成员i, 可以写成:
y[1].x.i;
若要访问结构变量y[2]中联合x的字符串指针ch的第一个字符可写成:
*y[2].x.ch;
若写成"y[2].x.*ch;"是错误的。
2. 结构和联合的区别
结构和联合有下列区别:
1. 结构和联合都是由多个不同的数据类型成员组成, 但在任何同一时刻, 联合转只存放了一个被选中的成员, 而结构的所有成员都存在。
2. 对于联合的不同成员赋值, 将会对其它成员重写, 原来成员的值就不存在了, 而对于结构的不同成员赋值是互不影响的。
下面举一个例了来加对深联合的理解。
例4:
main()
{
union{ /*定义一个联合*/
int i;
struct{ /*在联合中定义一个结构*/
char first;
char second;
}half;
}number;
number.i=0x4241; /*联合成员赋值*/
printf("%c%c\n", number.half.first, mumber.half.second);
number.half.first='a'; /*联合中结构成员赋值*/
number.half.second='b';
printf("%x\n", number.i);
getch();
}
输出结果为:
AB
6261
从上例结果可以看出: 当给i赋值后, 其低八位也就是first和second的值;当给first和second赋字符后, 这两个字符的ASCII码也将作为i 的低八位和高八位。
关于c中volatile关键字
一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份。下面是volatile变量的几个例子:
1). 并行设备的硬件寄存器(如:状态寄存器)
2). 一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
3). 多线程应用中被几个任务共享的变量
回答不出这个问题的人是不会被雇佣的。我认为这是区分C程序员和嵌入式系统程序员的最基本的问题。嵌入式系统程序员经常同硬件、中断、RTOS等等打交道,所用这些都要求volatile变量。不懂得volatile内容将会带来灾难。
假设被面试者正确地回答了这是问题(嗯,怀疑这否会是这样),我将稍微深究一下,看一下这家伙是不是直正懂得volatile完全的重要性。
1). 一个参数既可以是const还可以是volatile吗?解释为什么。
2). 一个指针可以是volatile 吗?解释为什么。
3). 下面的函数有什么错误:
int square(volatile int *ptr)
{
return *ptr * *ptr;
}
下面是答案:
1). 是的。一个例子是只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。
2). 是的。尽管这并不很常见。一个例子是当一个中服务子程序修该一个指向一个buffer的指针时。
3). 这段代码的有个恶作剧。这段代码的目的是用来返指针*ptr指向值的平方,但是,由于*ptr指向一个volatile型参数,编译器将产生类似下面的代码:
int square(volatile int *ptr)
{
int a,b;
a = *ptr;
b = *ptr;
return a * b;
}
由于*ptr的值可能被意想不到地该变,因此a和b可能是不同的。结果,这段代码可能返不是你所期望的平方值!正确的代码如下:
long square(volatile int *ptr)
{
int a;
a = *ptr;
return a * a;
}
Volatile 关键字告诉编译器不要持有变量的临时性拷贝。一般用在多线程程序中,以避免在其中一个线程操作该变量时,将其拷贝入寄存器。请看以下情形:
A线程将变量复制入寄存器,然后进入循环,反复检测寄存器的值是否满足一定条件(它期待B线程改变变量的值。
在此种情况下,当B线程改变了变量的值时,已改变的值对其在寄存器的值没有影响。所以A线程进入死循环。
volatile 就是在此种情况下使用。
volatile 提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有 volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。下面举例说明。在DSP开发中,经常需要等待某个事件的触发,所以经常会写出这样的程序:
short flag;
void test()
{
do1();
while(flag==0);
do2();
} 这段程序等待内存变量flag的值变为1(怀疑此处是0,有点疑问,)之后才运行do2()。变量flag的值由别的程序更改,这个程序可能是某个硬件中断服务程序。例如:如果某个按钮按下的话,就会对DSP产生中断,在按键中断程序中修改flag为1,这样上面的程序就能够得以继续运行。但是,编译器并不知道flag的值会被别的程序修改,因此在它进行优化的时候,可能会把flag的值先读入某个寄存器,然后等待那个寄存器变为1。如果不幸进行了这样的优化,那么while循环就变成了死循环,因为寄存器的内容不可能被中断服务程序修改。为了让程序每次都读取真正flag变量的值,就需要定义为如下形式:
volatile short flag;
需要注意的是,没有volatile也可能能正常运行,但是可能修改了编译器的优化级别之后就又不能正常运行了。因此经常会出现debug版本正常,但是release版本却不能正常的问题。所以为了安全起见,只要是等待别的程序修改某个变量的话,就加上volatile关键字。
volatile的本意是“易变的”
由于访问寄存器的速度要快过RAM,所以编译器一般都会作减少存取外部RAM的优化。比如:
static int i=0;
int main(void)
{
...
while (1)
{
if (i) do_something();
}
}
/* Interrupt service routine. */
void ISR_2(void)
{
i=1;
}
程序的本意是希望ISR_2中断产生时,在main当中调用do_something函数,但是,由于编译器判断在main函数里面没有修改过i,因此可能只执行一次对从i到某寄存器的读操作,然后每次if判断都只使用这个寄存器里面的“i副本”,导致do_something永远也不会被调用。如果将将变量加上volatile修饰,则编译器保证对此变量的读写操作都不会被优化(肯定执行)。此例中i也应该如此说明。
一般说来,volatile用在如下的几个地方:
1、中断服务程序中修改的供其它程序检测的变量需要加volatile;
2、多任务环境下各任务间共享的标志应该加volatile;
3、存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义;
另外,以上这几种情况经常还要同时考虑数据的完整性(相互关联的几个标志读了一半被打断了重写),在1中可以通过关中断来实现,2中可以禁止任务调度,3中则只能依靠硬件的良好设计了。
volatile 的含义
volatile总是与优化有关,编译器有一种技术叫做数据流分析,分析程序中的变量在哪里赋值、在哪里使用、在哪里失效,分析结果可以用于常量合并,常量传播等优化,进一步可以死代码消除。但有时这些优化不是程序所需要的,这时可以用volatile关键字禁止做这些优化,volatile的字面含义是易变的,它有下面的作用:
1 不会在两个操作之间把volatile变量缓存在寄存器中。在多任务、中断、甚至setjmp环境下,变量可能被其他的程序改变,编译器自己无法知道,volatile就是告诉编译器这种情况。
2 不做常量合并、常量传播等优化,所以像下面的代码:
volatile int i = 1;
if (i > 0) ...
if的条件不会当作无条件真。
3 对volatile变量的读写不会被优化掉。如果你对一个变量赋值但后面没用到,编译器常常可以省略那个赋值操作,然而对Memory Mapped IO的处理是不能这样优化的。
前面有人说volatile可以保证对内存操作的原子性,这种说法不大准确,其一,x86需要LOCK前缀才能在SMP下保证原子性,其二,RISC根本不能对内存直接运算,要保证原子性得用别的方法,如atomic_inc。
对于jiffies,它已经声明为volatile变量,我认为直接用jiffies++就可以了,没必要用那种复杂的形式,因为那样也不能保证原子性。
你可能不知道在Pentium及后续CPU中,下面两组指令
inc jiffies
;;
mov jiffies, %eax
inc %eax
mov %eax, jiffies
作用相同,但一条指令反而不如三条指令快。
文章出处:DIY部落(http://www.diybl.com/course/6_system/linux/Linuxjs/20090213/155402.html)

相关文章推荐
- springMVC上传多个文件
- Struts2笔记——通配符和动态方法调用
- Struts2笔记——通配符和动态方法调用
- Struts2笔记——类型转换
- Struts2笔记——类型转换
- Java集合框架
- java的枚举类型初始
- java 集合(arraylist set map)遍历问题
- java-captcha实现验证码(二)
- import javax.servlet.jsp.JspException; import javax.servlet.jsp.tagext.TagSupport;这两行报错
- demo2 JAVA变量
- kafka学习(三)--java开发(基于kafka0.8版本)
- Android SDK+Eclipse+ADT+CDT+NDK 开发环境在windows 7下的搭建
- java中四种引用类型
- MyBatis之java.lang.UnsupportedOperationException异常解决方案
- salesforce rest api 登录 | Authenticating to Salesforce using REST, OAuth 2.0 and Java
- JAVA问题总结之16-一维数组案例
- java annotation 例子
- 《Java并发编程的艺术》读书笔记(一)
- Eclipse更改字体大小