数据挖掘之CART剪枝
2015-08-26 15:59
246 查看
与上篇文章中提到的ID3算法和C4.5算法类似,CART算法也是一种决策树分类算法。CART分类回归树算法的本质也是对数据进行分类的,最终数据的表现形式也是以树形的模式展现的,CART与ID3,C4.5所采用的分类标准是不同了。
下面列出了其中的一些不同之处:
1、CART最后形成的树是一个二叉树,每个节点会分成2个节点,左孩子节点和右孩子节点,于是这就要求CART算法在所选定的属性中又要划分出最佳的属性划分值,节点如果选定了划分属性名称还要确定里面按照哪个值做一个二元的划分(为属性的值为一类,否则为零另一类)
而在ID3和C4.5中是按照分类属性的值类型进行划分(属性的取值可以为1个也可以为多个)
2、CART算法对于属性的值采用的是基于Gini系数值的方式做比较,gini某个属性的某次值的划分的gini指数的值为:

,pk就是分别为正负实例的概率,gini系数越小说明分类纯度越高,可以想象成与熵的定义一样。因此在最后计算的时候我们只取其中值最小的做出划分。最后做比较的时候用的是gini的增益做比较,要对分类号的数据做出一个带权重的gini指数的计算
3
CART算法在按照Gini指数构建好的树,但是这样构建的树和ID3和C4.5一样,容易导致过拟合现象,在数据集中,在测试集中过拟合的决策树的错误率比经过简化的决策树的错误率要高,过拟合的决策树对训练集拟合的很好,错误率很低(但这并不代表这样的模型是最好的)。
现在问题就在于,如何(HOW)在原生的过拟合决策树的基础上,生成简化版的决策树,可以通过剪枝的方法来简化过拟合的决策树。剪枝可以分为两种:预剪枝(Pre-Pruning)和后剪枝(Post-Pruning),下面我们来详细学习下这两种方法:
PrePrune:预剪枝,及早的停止树增长,方法可以参考见上面树停止增长的方法。
PostPrune:后剪枝,在已生成过拟合决策树上进行剪枝,可以得到简化版的剪枝决策树。
常见的后剪枝发包括代价复杂度剪枝,悲观误差剪枝等等。为非叶子节点计算误差代价,这里的后剪枝法用的是CCP代价复杂度剪枝,代价复杂度剪枝的算法公式为:
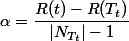
α表示的是每个非叶子节点的误差增益率,可以理解为误差代价,最后选出误差代价最小的一个节点进行剪枝(减掉此分支和原来的树的训练集的准确度相差最小)。
里面变量的意思为:

是子树中包含的叶子节点个数;

是节点t的误差代价,如果该节点被剪枝;

r(t)是节点t的误差率;
p(t)是节点t上的数据占所有数据的比例。

是子树Tt的误差代价,如果该节点不被剪枝。它等于子树Tt上所有叶子节点的误差代价之和。下面说说我对于这个公式的理解:其实这个公式的本质是对于剪枝前和剪枝后的样本偏差率做一个差值比较,一个好的分类当然是分类后的样本偏差率相较于没分类(就是剪枝掉的时候)的偏差率小,所以这时的值就会大,如果分类前后基本变化不大,则意味着分类不起什么效果,α值的分子位置就小,所以误差代价就小,可以被剪枝。但是一般分类后的偏差率会小于分类前的,因为偏差数在高层节点的时候肯定比子节点的多,子节点偏差数最多与父亲节点一样。
主程序如下:
package DataMining_CART;
public class Client {
public static void main(String[] args){
String filePath = "E:\\code\\data mining\\DataMining_CART\\src\\DataMining_CART\\input.txt";//训练数据集的路径
CARTTool tool = new CARTTool(filePath);//构造函数
tool.startBuildingTree();//CART主程序的入口
}
}
每个节点的类如下
关键程序CARTTool如下
训练数据input.txt
输出的结果如图所示:
下面列出了其中的一些不同之处:
1、CART最后形成的树是一个二叉树,每个节点会分成2个节点,左孩子节点和右孩子节点,于是这就要求CART算法在所选定的属性中又要划分出最佳的属性划分值,节点如果选定了划分属性名称还要确定里面按照哪个值做一个二元的划分(为属性的值为一类,否则为零另一类)
而在ID3和C4.5中是按照分类属性的值类型进行划分(属性的取值可以为1个也可以为多个)
2、CART算法对于属性的值采用的是基于Gini系数值的方式做比较,gini某个属性的某次值的划分的gini指数的值为:
,pk就是分别为正负实例的概率,gini系数越小说明分类纯度越高,可以想象成与熵的定义一样。因此在最后计算的时候我们只取其中值最小的做出划分。最后做比较的时候用的是gini的增益做比较,要对分类号的数据做出一个带权重的gini指数的计算
3
CART算法在按照Gini指数构建好的树,但是这样构建的树和ID3和C4.5一样,容易导致过拟合现象,在数据集中,在测试集中过拟合的决策树的错误率比经过简化的决策树的错误率要高,过拟合的决策树对训练集拟合的很好,错误率很低(但这并不代表这样的模型是最好的)。
现在问题就在于,如何(HOW)在原生的过拟合决策树的基础上,生成简化版的决策树,可以通过剪枝的方法来简化过拟合的决策树。剪枝可以分为两种:预剪枝(Pre-Pruning)和后剪枝(Post-Pruning),下面我们来详细学习下这两种方法:
PrePrune:预剪枝,及早的停止树增长,方法可以参考见上面树停止增长的方法。
PostPrune:后剪枝,在已生成过拟合决策树上进行剪枝,可以得到简化版的剪枝决策树。
常见的后剪枝发包括代价复杂度剪枝,悲观误差剪枝等等。为非叶子节点计算误差代价,这里的后剪枝法用的是CCP代价复杂度剪枝,代价复杂度剪枝的算法公式为:
α表示的是每个非叶子节点的误差增益率,可以理解为误差代价,最后选出误差代价最小的一个节点进行剪枝(减掉此分支和原来的树的训练集的准确度相差最小)。
里面变量的意思为:
是子树中包含的叶子节点个数;
是节点t的误差代价,如果该节点被剪枝;
r(t)是节点t的误差率;
p(t)是节点t上的数据占所有数据的比例。
是子树Tt的误差代价,如果该节点不被剪枝。它等于子树Tt上所有叶子节点的误差代价之和。下面说说我对于这个公式的理解:其实这个公式的本质是对于剪枝前和剪枝后的样本偏差率做一个差值比较,一个好的分类当然是分类后的样本偏差率相较于没分类(就是剪枝掉的时候)的偏差率小,所以这时的值就会大,如果分类前后基本变化不大,则意味着分类不起什么效果,α值的分子位置就小,所以误差代价就小,可以被剪枝。但是一般分类后的偏差率会小于分类前的,因为偏差数在高层节点的时候肯定比子节点的多,子节点偏差数最多与父亲节点一样。
主程序如下:
package DataMining_CART;
public class Client {
public static void main(String[] args){
String filePath = "E:\\code\\data mining\\DataMining_CART\\src\\DataMining_CART\\input.txt";//训练数据集的路径
CARTTool tool = new CARTTool(filePath);//构造函数
tool.startBuildingTree();//CART主程序的入口
}
}
每个节点的类如下
关键程序CARTTool如下
训练数据input.txt
输出的结果如图所示:

相关文章推荐
- [leetcode] 188.Best Time to Buy and Sell Stock IV
- android Studio svn 的配置
- IOS学习第六篇——代码块(block)
- Spring MVC textbox example
- HDU - 2545 树上战争(没有路径压缩的并查集)
- Mr. Process的一生-Linux内核的社会视角 (2) 启动
- [前端] grunt入门
- Android开发和iOS开发那个更有前景?如何选择?
- JDBC实现图片存取数据库(1)
- Intent 转向
- qt编程
- brew 出现 git 错误的问题分析
- BLToolkit: Sogen - Code generator for BLToolkit
- Axis 2 客户端必须的一些包
- linux 共享库的编译和连接
- PHP生成PDF文件
- 安卓5.0新特性
- UVO 120 Stacks of Flapjacks (整行输入+构造函数)
- 浅谈流形学习
- 并发编程网