Spark Streaming编程指南
2015-08-25 08:57
375 查看
Spark Streaming属于Spark的核心api,它支持高吞吐量、支持容错的实时流数据处理。
它可以接受来自Kafka, Flume, Twitter, ZeroMQ和TCP Socket的数据源,使用简单的api函数比如 map, reduce, join, window等操作,还可以直接使用内置的机器学习算法、图算法包来处理数据。

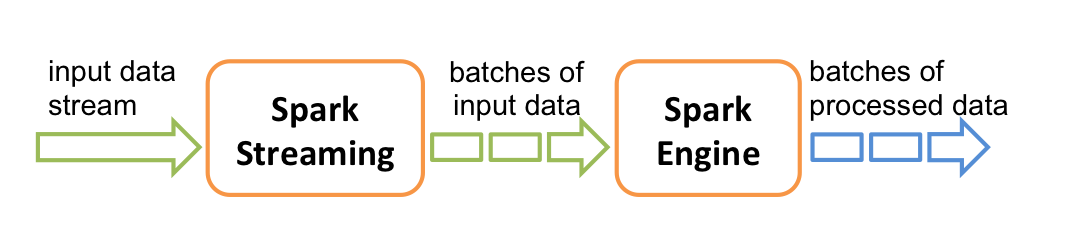
它的工作流程像下面的图所示一样,接受到实时数据后,给数据分批次,然后传给Spark Engine处理最后生成该批次的结果。
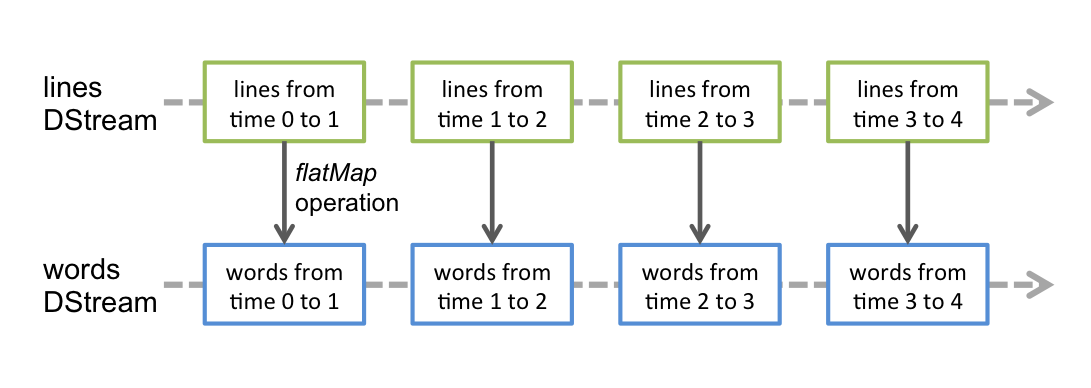
它支持的数据流叫Dstream,直接支持Kafka、Flume的数据源。Dstream是一种连续的RDDs,下面是一个例子帮助大家理解Dstream。
A Quick Example
具体的代码可以访问这个页面:
完整代码
使用下面这句命令来启动Netcat:
接着启动example
在Netcat这端输入hello world,看Spark这边的
接着就是示例化
这里有3个要点:
(1)dataDirectory下的文件格式都是一样
(2)在这个目录下创建文件都是通过移动或者重命名的方式创建的
(3)一旦文件进去之后就不能再改变
假设我们要创建一个Kafka的Dstream。
如果我们需要自定义流的receiver,可以查看https://spark.incubator.apache.org/docs/latest/streaming-custom-receivers.html
Transformations
UpdateStateByKey Operation
使用这个操作,我们是希望保存它状态的信息,然后持续的更新它,使用它有两个步骤:
(1)定义状态,这个状态可以是任意的数据类型
(2)定义状态更新函数,从前一个状态更改新的状态
下面展示一个例子:
参考链接
它可以接受来自Kafka, Flume, Twitter, ZeroMQ和TCP Socket的数据源,使用简单的api函数比如 map, reduce, join, window等操作,还可以直接使用内置的机器学习算法、图算法包来处理数据。
它的工作流程像下面的图所示一样,接受到实时数据后,给数据分批次,然后传给Spark Engine处理最后生成该批次的结果。
它支持的数据流叫Dstream,直接支持Kafka、Flume的数据源。Dstream是一种连续的RDDs,下面是一个例子帮助大家理解Dstream。
A Quick Example
// 创建StreamingContext,1秒一个批次
val ssc = new StreamingContext(sparkConf, Seconds(1));
// 穿件一个DStream来连接 监听端口:地址
val lines = ssc.socketTextStream(serverIP, serverPort);
// 对每一行数据执行Split操作
val words = lines.flatMap(_.split(" "));
// 统计word的数量
val pairs = words.map(word => (word, 1));
val wordCounts = pairs.reduceByKey(_ + _);
// 输出结果
wordCount.print();
ssc.start(); // 开始
ssc.awaitTermination(); // 计算完毕退出具体的代码可以访问这个页面:
完整代码
使用下面这句命令来启动Netcat:
$ nc -lk 9999
接着启动example
$ ./bin/run-example org.apache.spark.streaming.examples.NetworkWordCount local[2] localhost 9999
在Netcat这端输入hello world,看Spark这边的
# TERMINAL 1: # Running Netcat $ nc -lk 9999 hello world ... # TERMINAL 2: RUNNING NetworkWordCount or JavaNetworkWordCount $ ./bin/run-example org.apache.spark.streaming.examples.NetworkWordCount local[2] localhost 9999 ... ------------------------------------------- Time: 1357008430000 ms ------------------------------------------- (hello,1) (world,1) ...
编写代码
首先我们要在SBT或者Maven工程添加以下信息:groupId = org.apache.spark artifactId = spark-streaming_2.10 version = 0.9.0-incubating
//需要使用一下数据源的,还要添加相应的依赖 Source Artifact Kafka spark-streaming-kafka_2.10 Flume spark-streaming-flume_2.10 Twitter spark-streaming-twitter_2.10 ZeroMQ spark-streaming-zeromq_2.10 MQTT spark-streaming-mqtt_2.10
接着就是示例化
new StreamingContext(master, appName, batchDuration, [sparkHome], [jars]) 这是之前的例子对DStream的操作。
数据源
除了sockets之外,我们还可以这样创建DstreamstreamingContext.fileStream(dataDirectory)
这里有3个要点:
(1)dataDirectory下的文件格式都是一样
(2)在这个目录下创建文件都是通过移动或者重命名的方式创建的
(3)一旦文件进去之后就不能再改变
假设我们要创建一个Kafka的Dstream。
import org.apache.spark.streaming.kafka._ KafkaUtils.createStream(streamingContext, kafkaParams, …)
如果我们需要自定义流的receiver,可以查看https://spark.incubator.apache.org/docs/latest/streaming-custom-receivers.html
Operations
对于Dstream,我们可以进行两种操作,transformations 和 outputTransformations
Transformation Meaning map(func) 对每一个元素执行func方法 flatMap(func) 类似map函数,但是可以map到0+个输出 filter(func) 过滤 repartition(numPartitions) 增加分区,提高并行度 union(otherStream) 合并两个流 count() 统计元素的个数 reduce(func) 对RDDs里面的元素进行聚合操作,2个输入参数,1个输出参数 countByValue() 针对类型统计,当一个Dstream的元素的类型是K的时候,调用它会返回一个新的Dstream,包含<K,Long>键值对,Long是每个K出现的频率。 reduceByKey(func, [numTasks]) 对于一个(K, V)类型的Dstream,为每个key,执行func函数,默认是local是2个线程,cluster是8个线程,也可以指定numTasks join(otherStream, [numTasks]) 把(K, V)和(K, W)的Dstream连接成一个(K, (V, W))的新Dstream cogroup(otherStream, [numTasks]) 把(K, V)和(K, W)的Dstream连接成一个(K, Seq[V], Seq[W])的新Dstream transform(func) 转换操作,把原来的RDD通过func转换成一个新的RDD updateStateByKey(func) 针对key使用func来更新状态和值,可以将state该为任何值
UpdateStateByKey Operation
使用这个操作,我们是希望保存它状态的信息,然后持续的更新它,使用它有两个步骤:
(1)定义状态,这个状态可以是任意的数据类型
(2)定义状态更新函数,从前一个状态更改新的状态
下面展示一个例子:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}参考链接

相关文章推荐
- 面向接口编程详解(一)——思想基础
- Python连接mysql数据库及python使用mysqldb连接数据库教程
- 面向接口编程详解(一)——思想基础
- JSON 转javabean 利器
- 选择编程开发书籍的反思
- C++中的explicit关键字
- vbox挂载共享文件夹
- Python正则表达式+自创口诀
- java-内部类说明
- struts2学习笔记——03
- 《Java实战开发经典》第五章5.1
- java获得当前时间戳
- python数据库操作-MySQL,SQLite
- 轻松python文本专题-字符与字符值转换
- 轻松python文本专题-字符与字符值转换
- C++笔试总结-面试笔试常考题型(一)指针-引用-宏定义-sizeof
- Myeclipse 安装 gradle 插件以及基本使用
- Spring MVC XmlViewResolver example
- Spring MVC InternalResourceViewResolver example
- 去哪网实习总结:windows下配置JavaWeb环境、开发helloworld、发布系统(附截图,绝对详细)(JavaWeb)