SQL Server里简单参数化的痛苦
2015-08-18 08:06
399 查看
在今天的文章里,我想谈下对于即席SQL语句(ad-hoc SQL statements),SQL Server使用的[b]简单参数化(Simple Parameterization)[/b]的一些特性和副作用。首先,如果你的SQL语句包含这些,简单参数化不会发生:
JOIN
IN
BULK INSERT
UNION
INTO
DISTINCT
TOP
GROUP BY
HAVING
COMPUTE
Sub Queries
一般来说,如果你处理所谓的[b]安全执行计划(Safe Execution Plan)[/b],SQL Server自动参数化你的SQL语句:不管提供的参数值,查询总必须通向一样的执行计划。如果你的执行计划里有书签查找,这就是不可能的例子。因为临界点定义了是否进行书签查找还是全表/聚集索引扫描。
然后当你查看计划缓存时,你会看到SQL Server能为你自动参数化SQL语句:
(@1 numeric(3,2))SELECT * FROM [Orders] WHERE [Price]=@1
但什么是选择的作为参数的数据类型?最小可能的那个!在这里是NUMERIC(3,2)!如果现在你执行下列2个查询:
SQL Server能重用为第1个使用8.7值SQL语句的参数化SQL语句的执行计划。但用124.50值的第2个SQL语句呢?对于这个SQL语句缓存的计划不能被重用,因为124.50值不符合NUMERIC(3,2)。在这个情况下,SQL Server用NUMERIC(5,2)数据类型生成你SQL语句的新参数化版本。你刚用你的SQL语句的额外的参数化版本污染了你的计划缓存!当你执行下列语句会变得更糟:
这个会再次给你新的用NUMERIC(6,2)数据类型的新参数化版本——计划缓存里另一个版本!当我展示这个行为的时候,很多人都建议我应该用逆序来执行刚才的SQL语句。我们通过首先清空计划缓存来试下。
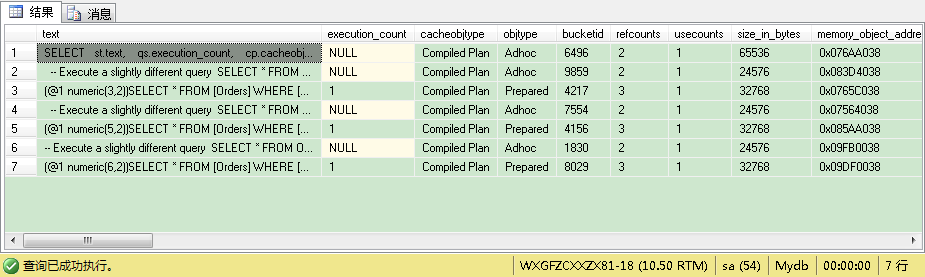
然后当你看计划缓存时,没有任何改变:SQL Server还生成了3个不同的参数化SQL语句——每次都用最小可能的数据类型。
你怎么做没有一点关系,即你执行你SQL语句的顺序:在自动参数化期间,SQL Server总会选择最小可能的数据类型。当你依赖SQL Server这个特性时,好好考虑下。
VARCHAR如何呢?SQL Server自动参数化包含字符值(例如VARCHAR)的SQL语句时,事情会好点。假设有下列表定义和下列2个查询:
在这个情况下,SQL Server用VARCHAR(8000)生成1个自动参数化SQL语句——最大可能的数据类型。从刚才例子里,这是你所期待的行为。有时SQL Server好事坏事同时做……
感谢关注!
JOIN
IN
BULK INSERT
UNION
INTO
DISTINCT
TOP
GROUP BY
HAVING
COMPUTE
Sub Queries
一般来说,如果你处理所谓的[b]安全执行计划(Safe Execution Plan)[/b],SQL Server自动参数化你的SQL语句:不管提供的参数值,查询总必须通向一样的执行计划。如果你的执行计划里有书签查找,这就是不可能的例子。因为临界点定义了是否进行书签查找还是全表/聚集索引扫描。
自动参数化并不那么酷!
如果SQL Server能自动参数化你的SQL语句,你还是要考虑下SQL Server引入的自动参数化SQL语句的一些副作用。我们来看一个具体的例子。下列查询创建一个表,执行一个会被SQL Server自动参数化的简单SQL语句。-- Create a simple table CREATE TABLE Orders ( Col1 INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, Price DECIMAL(18, 2) ) GO -- This query gets auto parametrized, because it is a simple query with a safe (consistent) plan SELECT * FROM Orders WHERE Price = 5.70 GO -- Analyze the Plan Cache SELECT st.text, qs.execution_count, cp.cacheobjtype, cp.objtype, cp.*, qs.*, p.* FROM sys.dm_exec_cached_plans cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) p CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st LEFT JOIN sys.dm_exec_query_stats qs ON qs.plan_handle = cp.plan_handle WHERE st.text LIKE '%Orders%' GO
然后当你查看计划缓存时,你会看到SQL Server能为你自动参数化SQL语句:
(@1 numeric(3,2))SELECT * FROM [Orders] WHERE [Price]=@1
但什么是选择的作为参数的数据类型?最小可能的那个!在这里是NUMERIC(3,2)!如果现在你执行下列2个查询:
-- Execute a slightly different query SELECT * FROM Orders WHERE Price = 8.70 GO -- Execute a slightly different query SELECT * FROM Orders WHERE Price = 124.50 GO
SQL Server能重用为第1个使用8.7值SQL语句的参数化SQL语句的执行计划。但用124.50值的第2个SQL语句呢?对于这个SQL语句缓存的计划不能被重用,因为124.50值不符合NUMERIC(3,2)。在这个情况下,SQL Server用NUMERIC(5,2)数据类型生成你SQL语句的新参数化版本。你刚用你的SQL语句的额外的参数化版本污染了你的计划缓存!当你执行下列语句会变得更糟:
-- Execute a slightly different query SELECT * FROM Orders WHERE Price = 1204.50 GO
这个会再次给你新的用NUMERIC(6,2)数据类型的新参数化版本——计划缓存里另一个版本!当我展示这个行为的时候,很多人都建议我应该用逆序来执行刚才的SQL语句。我们通过首先清空计划缓存来试下。
-- Clear the Plan Cache
DBCC FREEPROCCACHE
GO
-- Execute a slightly different query SELECT * FROM Orders WHERE Price = 1204.50 GO
-- Execute a slightly different query
SELECT * FROM Orders
WHERE Price = 124.50
GO
-- Execute a slightly different query
SELECT * FROM Orders
WHERE Price = 8.70
GO
然后当你看计划缓存时,没有任何改变:SQL Server还生成了3个不同的参数化SQL语句——每次都用最小可能的数据类型。
你怎么做没有一点关系,即你执行你SQL语句的顺序:在自动参数化期间,SQL Server总会选择最小可能的数据类型。当你依赖SQL Server这个特性时,好好考虑下。
VARCHAR如何呢?SQL Server自动参数化包含字符值(例如VARCHAR)的SQL语句时,事情会好点。假设有下列表定义和下列2个查询:
-- Create another table to demonstrate this problem CREATE TABLE Orders3 ( Col1 INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, Col2 VARCHAR(100) ) GO -- Clears the Plan Cache DBCC FREEPROCCACHE GO -- A VARCHAR/CHAR column is always auto parametrized to a VARCHAR(8000) SELECT * FROM Orders3 WHERE Col2 = 'Woody' GO -- A VARCHAR column is always auto parametrized to a VARCHAR(8000) SELECT * FROM Orders3 WHERE Col2 = 'Tu' GO
在这个情况下,SQL Server用VARCHAR(8000)生成1个自动参数化SQL语句——最大可能的数据类型。从刚才例子里,这是你所期待的行为。有时SQL Server好事坏事同时做……
小结
当你和简单SQL语句打交道时,自动参数化可以非常棒。但如你在这个文章里所见,你要知道SQL Server引入的副作用。另外SQL Server的简单参数化特性还会提供你强制参数化(Forced Parameterization)功能,这个我会在以后的文章里介绍。感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2015/04/27/the-pain-of-simple-parameterization-in-sql-server/
相关文章推荐
- SQLServer的数据类型
- mysql 数据处理
- mongodb 示例
- Node.js开发入门——MongoDB与Mongoose
- MongoDB 重启之后无法连接问题
- SQLserver备份文件还原对应用户修复所需操作
- Oracle Coherence中文教程二十:预加载缓存
- Oracle Coherence中文教程十九:使用便携式对象格式
- Oracle Coherence中文教程十八:序列化对象
- Oracle Coherence中文教程十五:序列化分页缓存
- Oracle Coherence中文教程十四:缓存数据来源
- Oracle Coherence中文教程十三:实施存储和备份的Map
- Oracle Coherence中文教程十二:配置高速缓存
- 数据库设计理论及应用(5)——逻辑结构设计
- mysql的增删改查常用语法
- Oracle Coherence中文教程十:调整TCMP行为
- MYSQL explain详解
- Oracle Coherence中文教程九:动态管理群集成员
- Oracle Coherence中文教程八:启动和停止群集成员
- Oracle Coherence中文教程六:Coherence集群简介