zabbix自动发现结合shell实现自动发现占用内存最大top10进程并监控其资源 推荐
2015-08-17 16:36
1076 查看
最近在想一个问题,线上服务器跑的服务五花八门,可能这台跑的是nginx,另一台跑的是mysql,其他的跑的是nfs或者其他服务等等,通过某一个脚本中固定的写入一些服务来实现监控所有的服务器的进程占用资源情况占用zabbix服务器资源不说,假如该服务器跑的服务不在固定列表中,监控服务获取不到相应数据。
为了解决这个问题,最近在想通过zabbix的自动发现功能能不能实现自动发现占用服务器内存最大的N个进程,然后对这些进程占用内存和CPU的资源情况进行监控获取数据呢?于是就有了本篇文章的诞生。
首先,我们需要获取到top命令结果,可以使用下面的命令将top命令获取的结果重定向到一个文件中去:
将该命令添加到zabbix用户的计划任务中去,每分钟执行一次,命令如下:
==========================================================================================
==========================================================================================
好了,获取到了数据后,就需要对数据进行处理了,下面是两个脚本,一个是为了获取占用内存资源最高的进程名,另一个是获取某进程占用内存和cpu资源的信息。先来看第一个脚本:
第二个脚本的作用就是获取某个进程占用的cpu和内存资源情况,脚本内容如下:
==========================================================================================
==========================================================================================
==========================================================================================
抱歉,上面用====框住的这段代码存在问题,经过博友们的提醒,我已经发现问题的所在了,在top命令中内存的占用单位默认是KB,但是当某个进程占用内存比较大时,其单位将会变成MB甚至是GB,乃至TB,目前来说我通过awk无法获取到正确的数值(抱歉,本人水平有限,对AWK使用还欠缺火候),于是,本人今天使用python实现了上面框住部分的代码,下面贴出本人使用python写出的脚本:
在组态---》模板---》创建模板里面创建一个模板,叫做temple top_process如下图所示:
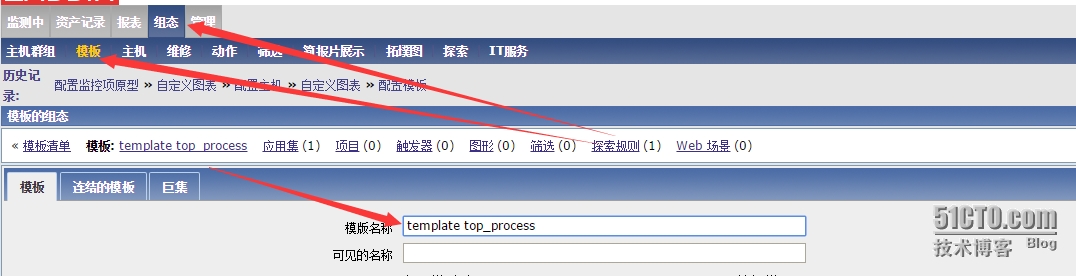
创建一个应用集叫做top of process resource,如下图所示:

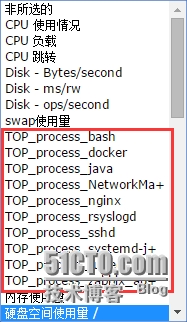
创建好后,需要添加探索规则了,这是我们的重头戏。新建探索规则,如下图所示:
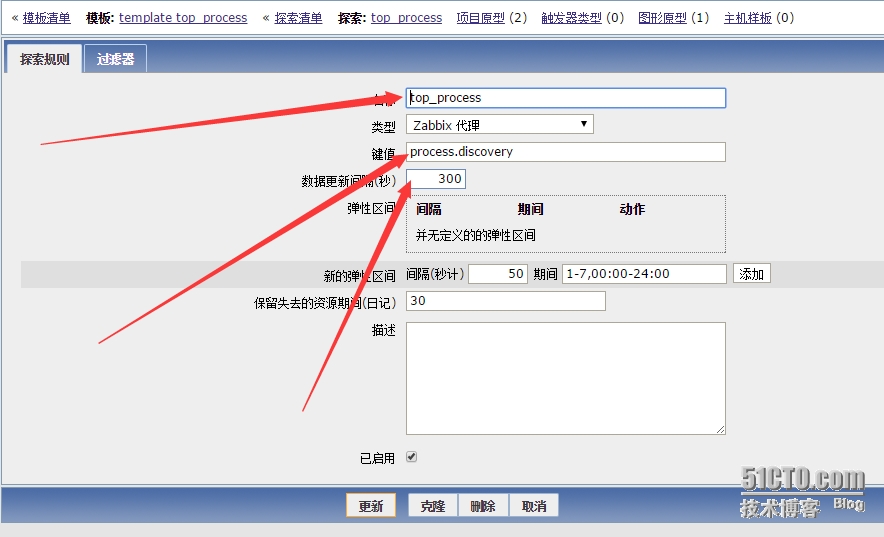
其中的键值就是我们在客户端上面配置的键值,数据更新间隔我这里设置为5分钟,就是说每间隔5分钟它就会去客户端获取占用内存最大的十个进程,然后取它们的内存和cpu占用资源数据。下面就需要配置项目原型了,如下图所示:
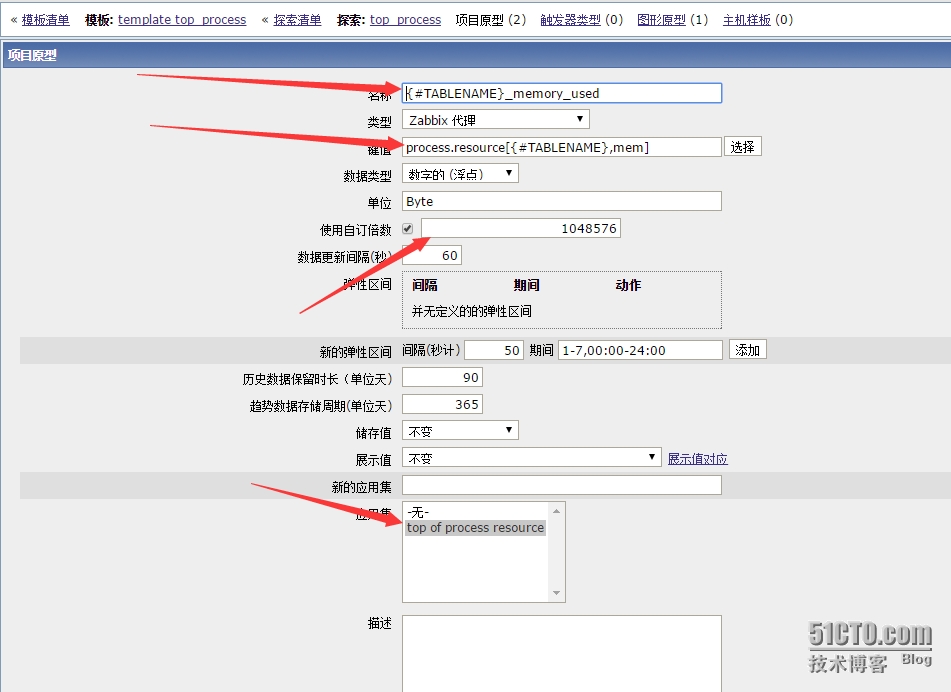
如上图所示,{#TABLENAME}获取的就是十个进程名的列表,process.resource[{#TABLENAME},mem]就是我们在客户端配置的键值,其中获取的内存数值单位是MB,这里将它转换成BYTE单位,所以将获取到的数值*1024*1024=1048576,单位改成Byte,将该项目应用到top of process resourceying应用集上。这样,一个项目原型就做成功了。下面是cpu占用资源的项目原型配置:
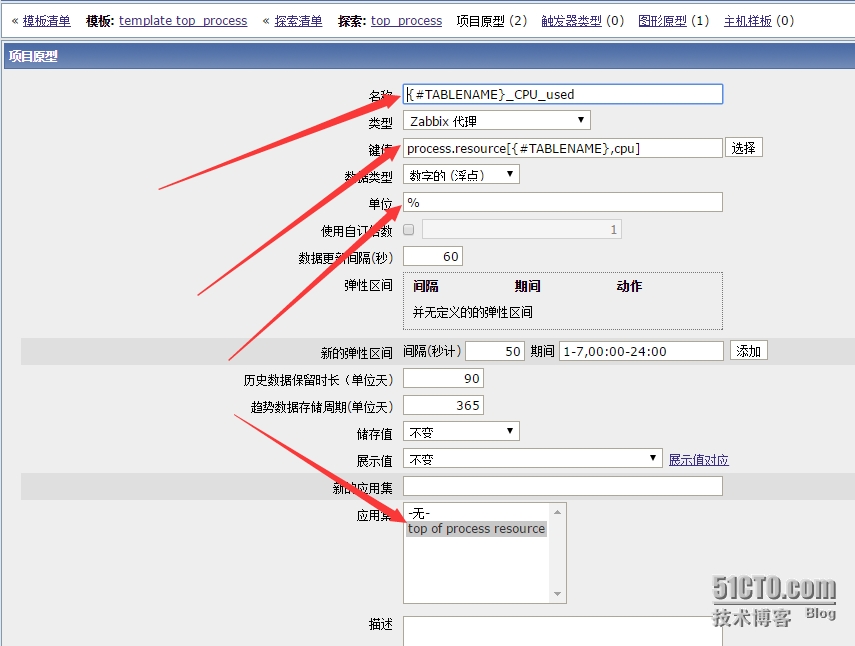
添加完项目原型后需要配置图形原型,如下图所示:
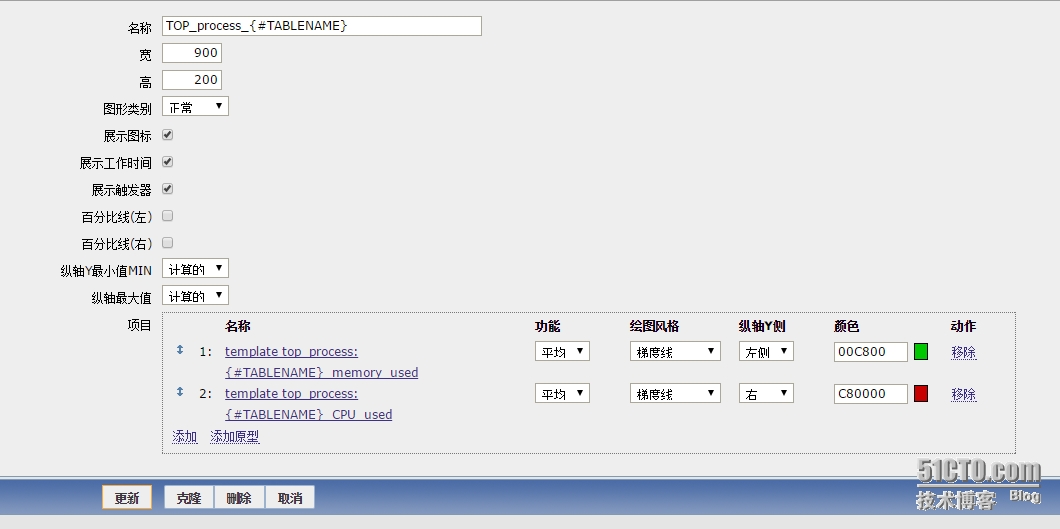
添加好图形原形后,改模版就制作成功了,接下来将该模板添加到主机上,就能够获取到数据了,这里因为我设置的自动发现时间间隔是5分钟,所以需要等待五分钟以上才会出现图形,下面是出现的图形效果。
这就是获取到的十个占用内存最大的进程的占用资源图形,下面是详细效果。

这是刚获取到的数据,至此,通过自动发现获取top10进程占用资源的监控结束,这只是本人匆忙之中写出的一个监控方式,拿出来给大家作参考,如果有更好的方式,可以和我共同探讨,大家共同进步,zabbix模板我将会放在附件中供大家下载。
由于参数有稍微的改变,于是模板文件也进行了稍微的修改,我将会将修改后的模版文件上传至附件中
附件:http://down.51cto.com/data/2366043
为了解决这个问题,最近在想通过zabbix的自动发现功能能不能实现自动发现占用服务器内存最大的N个进程,然后对这些进程占用内存和CPU的资源情况进行监控获取数据呢?于是就有了本篇文章的诞生。
首先,我们需要获取到top命令结果,可以使用下面的命令将top命令获取的结果重定向到一个文件中去:
top -b -n 1 >/tmp/top.txt其中该命令的意思是执行一次top命令并将结果重定向到top.txt文件中去
将该命令添加到zabbix用户的计划任务中去,每分钟执行一次,命令如下:
crontab -e */1 * * * * top -b -n 1 >/tmp/top.txt放进去之后在tmp目录下会生成一个top.txt文件
$ head -10 /tmp/top.txt top - 15:42:01 up 72 days, 22:25, 2 users, load average: 0.09, 0.08, 0.06 Tasks: 880 total, 1 running, 879 sleeping, 0 stopped, 0 zombie %Cpu(s): 2.8 us, 0.7 sy, 0.0 ni, 96.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 13175284+total, 97396048 free, 20357148 used, 13999640 buff/cache KiB Swap: 32767996 total, 32452380 free, 315616 used. 11058964+avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 20732 zabbix 20 0 130716 2436 1204 R 11.8 0.0 0:00.03 top 126808 upload 20 0 8375636 945876 27268 S 5.9 0.7 63:33.97 java 127591 upload 20 0 9898.1m 1.078g 27960 S 5.9 0.9 63:58.01 java==========================================================================================
==========================================================================================
==========================================================================================
好了,获取到了数据后,就需要对数据进行处理了,下面是两个脚本,一个是为了获取占用内存资源最高的进程名,另一个是获取某进程占用内存和cpu资源的信息。先来看第一个脚本:
$ cat scripts/check_process.sh
#!/bin/bash
TABLESPACE=`tail -n +8 /tmp/top.txt|awk '{a[$NF]+=$6}END{for(k in a)print a[k]/1024,k}'|sort -gr|head -10|cut -d" " -f2`
COUNT=`echo "$TABLESPACE" |wc -l`
INDEX=0
echo '{"data":['
echo "$TABLESPACE" | while read LINE; do
echo -n '{"{#TABLENAME}":"'$LINE'"}'
INDEX=`expr $INDEX + 1`
if [ $INDEX -lt $COUNT ]; then
echo ','
fi
done
echo ']}'其中最关键的是`tail -n +8 /tmp/top.txt|awk '{a[$NF]+=$6}END{for(k in a)print a[k]/1024,k}'|sort -gr|head -10|cut -d" " -f2`这条命令:这条命令的意思是从top.txt文件中取出从第八行到末尾行的数据,然后使用awk对这些数据进行累加,效果是以最后一列为关键字,每个关键字对应的第6列的数值进行累加,输出第六列数据的累加结果和最后一列数据,然后使用sort进行排序,注意这里的参数是使用-gr而不是使用-nr是因为获取到的第六列的值是以KB为单位的,假如某进程占用内存大于10G的话,将会使用科学记数法计数,sort -nr参数无法对科学记数法进行计数,需要将参数改成-gr才行,其中的-r是进行反向排序,同时为了防止zabbix获取到该值是科学记数法获取的值从而无法识别,先将该值/1024将单位变成MB,当zabbix获取到数据后再*1024*1024将该值还原成BYTE单位。head -10是取出占用内存最大的十个进程,然后使用cut对数据进行切分,获得十个进程的进程名。至于下面的代码是将获取到的十个进程名进行json格式化的输出,输出结果如下:$ sh ./scripts/check_process.sh
{"data":[
{"{#TABLENAME}":"java"},
{"{#TABLENAME}":"docker"},
{"{#TABLENAME}":"nginx"},
{"{#TABLENAME}":"sshd"},
{"{#TABLENAME}":"tuned"},
{"{#TABLENAME}":"NetworkMa+"},
{"{#TABLENAME}":"zabbix_ag+"},
{"{#TABLENAME}":"systemd-j+"},
{"{#TABLENAME}":"crond"},
{"{#TABLENAME}":"rsyslogd"}]}至于为啥要进行json格式化前面博客已经阐述过了,因为zabbix自动发现获取的值格式就是json格式化的值才能被识别到。第二个脚本的作用就是获取某个进程占用的cpu和内存资源情况,脚本内容如下:
$ cat ./scripts/processmonitor.sh
#!/bin/bash
process=$1
name=$2
case $2 in
mem)
echo "`tail -n +8 /tmp/top.txt|awk '{a[$NF]+=$6}END{for(k in a)print a[k]/1024,k}'|grep "$process"|cut -d" " -f1`"
;;
cpu)
echo "`tail -n +8 /tmp/top.txt|awk '{a[$NF]+=$9}END{for(k in a)print a[k],k}'|grep "$process"|cut -d" " -f1`"
;;
*)
echo "Error input:"
;;
esac
exit 0该脚本的核心和上一个脚本的很相似,相信读者理解了上面的脚本在理解下面的脚本也是轻轻松松的啦。下面看该脚本执行的结果:$ sh ./scripts/processmonitor.sh java mem 13115.5 $ sh ./scripts/processmonitor.sh java cpu 17.7能获取到值了之后就需要在zabbix_agentd.conf里面配置相应的键值来获取数据了,下面是需要添加的配置:
$ tail -3 ./etc/zabbix_agentd.conf #top_process UserParameter=process.discovery,/home/zabbix/zabbix-2.4.4/scripts/check_process.sh UserParameter=process.resource[*],/home/zabbix/zabbix-2.4.4/scripts/processmonitor.sh $1 $2添加该配置之后需要重启zabbix_agentd才能使配置生效,重启需要使用pkill zabbix && zabbix-2.4.4/sbin/zabbix_agentd
==========================================================================================
==========================================================================================
==========================================================================================
抱歉,上面用====框住的这段代码存在问题,经过博友们的提醒,我已经发现问题的所在了,在top命令中内存的占用单位默认是KB,但是当某个进程占用内存比较大时,其单位将会变成MB甚至是GB,乃至TB,目前来说我通过awk无法获取到正确的数值(抱歉,本人水平有限,对AWK使用还欠缺火候),于是,本人今天使用python实现了上面框住部分的代码,下面贴出本人使用python写出的脚本:
$ cat process.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author: huxianglin
#date:2015-09-11
import string
import sys
def read_line(line):
line = line.strip('\n').strip()
programname = line.split()[11]
memoryuse = line.split()[5]
cpuuse = line.split()[8]
return programname,memoryuse,cpuuse
def getdate(file_path):
with open(file_path) as f:
for line in range(1,8):
next(f)
result=[]
for line in f:
result.append(list(read_line(line)))
return result
def topprogram(file_path):
date=getdate(file_path)
top={}
for i in date:
if 't' in i[1]:
i[1]=string.atof(i[1].split('t')[0])*1073741824
elif 'g' in i[1]:
i[1]=string.atof(i[1].split('g')[0])*1048576
elif 'm' in i[1]:
i[1]=string.atof(i[1].split('m')[0])*1024
else:
i[1]=string.atof(i[1])
if top.get(i[0]):
top[i[0]]=[top[i[0]][0]+i[1],top[i[0]][1]+string.atof(i[2])]
else:
top.setdefault(i[0],[i[1],string.atof(i[2])])
return sorted(top.items(),key=lambda d:d[1][0])[-1:-11:-1]
def translatejson(file_path):
data=topprogram(file_path)
print'{"data":['
for i in data:
if i != data[-1]:
print '{"{#TABLENAME}":"%s"},' %i[0]
else:
print '{"{#TABLENAME}":"%s"}]}' %i[0]
def printdata(file_path,key):
data=topprogram(file_path)
for i in data:
if key[1] == 'cpu':
if key[0] == i[0]:
print i[1][1]
else:
if key[0] == i[0]:
print i[1][0]
def main():
file_path='/tmp/top.txt'
if sys.argv[1] == 'json':
translatejson(file_path)
else:
key = [sys.argv[1],sys.argv[2]]
printdata(file_path,key)
if __name__=='__main__':
main()使用上面的python代码输入的参数稍微有点改变,下面是使用效果:$ ./process.py json
{"data":[
{"{#TABLENAME}":"java"},
{"{#TABLENAME}":"haproxy"},
{"{#TABLENAME}":"docker"},
{"{#TABLENAME}":"nginx"},
{"{#TABLENAME}":"sshd"},
{"{#TABLENAME}":"systemd-j+"},
{"{#TABLENAME}":"bash"},
{"{#TABLENAME}":"rsyslogd"},
{"{#TABLENAME}":"tuned"},
{"{#TABLENAME}":"NetworkMa+"}]}
[zabbix@dev01 scripts]$ ./process.py java mem
36773689.408
[zabbix@dev01 scripts]$ ./process.py java cpu
77.9这上面获取到的才是服务器真实资源占用的数据,之前的shell脚本作废了。由于脚本传入参数进行了改变,于是在zabbix_agentd.conf中得参数也得修改为如下形式:$ tail -3 /home/zabbix/zabbix-2.4.4/etc/zabbix_agentd.conf #top_process UserParameter=process.discovery[*],/home/zabbix/zabbix-2.4.4/scripts/process.py $1 UserParameter=process.resource[*],/home/zabbix/zabbix-2.4.4/scripts/process.py $1 $2好了,这样,客户端这边就已经配置成功了,下面需要在服务端验证是否能够获取到数据了,在服务端使用zabbix_get命令来获取数据,下面是执行的结果:
$ zabbix/bin/zabbix_get -s xxx.xxx.xxx.xxx -k"process.discovery[json]"
{"data":[
{"{#TABLENAME}":"java"},
{"{#TABLENAME}":"docker"},
{"{#TABLENAME}":"nginx"},
{"{#TABLENAME}":"sshd"},
{"{#TABLENAME}":"tuned"},
{"{#TABLENAME}":"NetworkMa+"},
{"{#TABLENAME}":"zabbix_ag+"},
{"{#TABLENAME}":"systemd-j+"},
{"{#TABLENAME}":"rsyslogd"},
{"{#TABLENAME}":"bash"}]}上面的xxx.xxx.xxx.xxx代表的是客户端的IP地址,-k后面的参数就是刚刚我们在客户端上面添加的参数。$ zabbix/bin/zabbix_get -s xxx.xxx.xxx.xxx -k"process.resource[java,mem]" 13115.6 $ zabbix/bin/zabbix_get -s xxx.xxx.xxx.xxx -k"process.resource[java,cpu]" 0好了,在服务端测试客户端没有问题,能够获取到数据了。接下来就需要在web端配置模板了。
在组态---》模板---》创建模板里面创建一个模板,叫做temple top_process如下图所示:
创建一个应用集叫做top of process resource,如下图所示:
创建好后,需要添加探索规则了,这是我们的重头戏。新建探索规则,如下图所示:
其中的键值就是我们在客户端上面配置的键值,数据更新间隔我这里设置为5分钟,就是说每间隔5分钟它就会去客户端获取占用内存最大的十个进程,然后取它们的内存和cpu占用资源数据。下面就需要配置项目原型了,如下图所示:
如上图所示,{#TABLENAME}获取的就是十个进程名的列表,process.resource[{#TABLENAME},mem]就是我们在客户端配置的键值,其中获取的内存数值单位是MB,这里将它转换成BYTE单位,所以将获取到的数值*1024*1024=1048576,单位改成Byte,将该项目应用到top of process resourceying应用集上。这样,一个项目原型就做成功了。下面是cpu占用资源的项目原型配置:
添加完项目原型后需要配置图形原型,如下图所示:
添加好图形原形后,改模版就制作成功了,接下来将该模板添加到主机上,就能够获取到数据了,这里因为我设置的自动发现时间间隔是5分钟,所以需要等待五分钟以上才会出现图形,下面是出现的图形效果。
这就是获取到的十个占用内存最大的进程的占用资源图形,下面是详细效果。
这是刚获取到的数据,至此,通过自动发现获取top10进程占用资源的监控结束,这只是本人匆忙之中写出的一个监控方式,拿出来给大家作参考,如果有更好的方式,可以和我共同探讨,大家共同进步,zabbix模板我将会放在附件中供大家下载。
由于参数有稍微的改变,于是模板文件也进行了稍微的修改,我将会将修改后的模版文件上传至附件中
附件:http://down.51cto.com/data/2366043

相关文章推荐
- Python 实现Zabbix自动发送报表
- 使用zabbix监控Nginx活动状态--Part1
- Zabbix安装详解
- C#实现简单屏幕监控的方法
- C#进程监控方法实例分析
- Windows下使用性能监视器监控SqlServer的常见指标
- Zabbix监控Linux主机设置方法
- Zabbix监控交换机设置方法
- Shell脚本实现Linux系统和进程资源监控
- Oracle 监控索引使用率脚本分享
- 获取键盘键的值 集合 方便监控键盘事件
- 一个监控Squid运行进程数并自动重启的简洁Shell脚本分享
- Linux下用Python脚本监控目录变化代码分享
- Shell脚本编写Nagios插件监控程序资源占用
- Shell脚本实现监控kingate并自动启动
- Shell脚本监控网站页面正常打开情况
- shell脚本监控系统负载、CPU和内存使用情况
- MySQL数据库维护中监控所用到的常用命令
- zabbix邮件报警及自定义脚本实战
- 自动化安装smokeping-2.6.11脚本 推荐