排序算法之冒泡排序
2015-08-13 21:31
232 查看
冒泡排序
今天学习一下冒泡排序,它是最简单的一种排序算法。这里我们按照降序排列原理
比较相邻的元素。如果第一个比第二个大,就交换他们两个。对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,知道没有任何一对数字需要比较。
首先,里面用到的swap函数定义如下:
//交换位置
void swap(int a[],int i,int j)
{
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}1.第一种:
void maopaoSort1(int a[],int aLength)
{
int i,j;
for (i=0; i<aLength; i++) {
for (j=0; j<aLength-1; j++) {
if (a[j]<a[j+1]) {
swap(a, j, j+1);
}
}
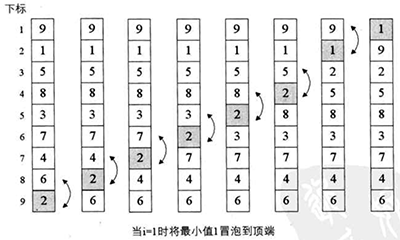
}这种排序算法是正宗的冒泡排序,原理如下:
总共比较aLength-1轮,第一轮是用相邻的两个元素比较,如果第一个元素<第二个元素,就交换。然后再次比较。
直到比较完aLengh-1轮。
排序结束。
原理图:
3.第二种:
void maopaoSort2(int a[],int aLength)
{
int i,j;
int flag = 1; //falg tag
for (i=0; i<aLength && flag==1; i++) {
flag = 0;
for (j=0; j<aLength-1; j++) {
printf("aj----aj+1:%d----%d \n",a[j],a[j+1]);
if (a[j]<a[j+1]) {
swap(a, j, j+1);
flag = 1;
}
}
}
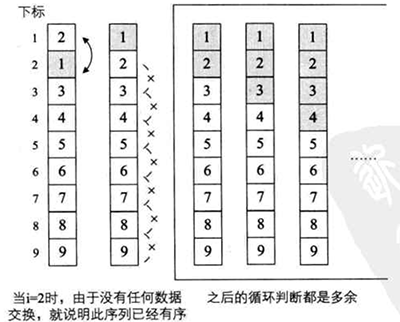
}这种排序变形就是再第二种的基础上添加了一个tag标志。这样做的目的就是由于如果一个待排序序列是这样的:
{2,1,3,4,5,6,7,8,9};
这样的排序 其实只需要将1,2交换就是有序的了,所以用第二种或者第一种方法进行排序很多就是没有必要的。也就是,2,3,4下面的都没有必要再次去比较了。
如果tag==1,说明了需要交换,但是如果tag为0,说明了后面的就没有必要再次排序了。因此可以大大的减少排序时间(当然只是针对大概有序的序列,效果会比较明显。)
原理图:
这三种排序方式都是冒泡排序。他们的时间复杂度都是:O(n^2);
测试main函数如下:
int main(int argc, const char * argv[]) {
int a[] = {12,34,9,1,5,8,3,7,4,6,2,43,42,16,23};
maopaoSort1(a,15);
printf("\n");
// maopaoSort2(a,15);
// printf("\n");
}不要一次同时执行两个排序算法,这样的话第二次执行的排序算法的数组就是第一次排序过的数组了。
至此,冒泡排序就告一段了,希望大家能够从中学到一些东西。

相关文章推荐
- NoSql---MongoDB基本操作
- 多年后再回头看那海市蜃楼
- Valid Parentheses 合法的括号匹配
- 终端、控制台、shell的关系
- Ubuntu 建立桌面快捷方式
- 基本组件之计时器
- vs2015编译zlib1.2.8
- Java基础 for 语句嵌套 记录和练习
- 电话面试问答Top 50 --[伯乐在线]
- Conscription
- HDU 5372 - Segment Game(树状数组)
- 祝贺自己的软件《万能数据库查询分析器》在非凡软件站和太平洋电脑的下载排行榜分别名列第1和第2
- 祝贺自己的软件《万能数据库查询分析器》在非凡软件站和太平洋电脑的下载排行榜分别名列第1和第2
- Java 基础 for循环基础练习记录
- POJ 题目3481 Double Queue(SBT ro map)
- linux中fork()函数详解
- HDU 5363-K - Key Set-递推
- -Dmaven.multiModuleProjectDirectory system propery is not set.
- 安装genymotion后出现无法连接adb的问题
- 资源文件对象的作用