[转]Redis有序集内部实现原理分析
2015-08-12 14:48
656 查看
原文地址:
http://www.cnblogs.com/WJ5888/p/4516782.html
Redis中支持的数据结构比Memcached要多的多啦,如基本的字符串、哈希表、列表、集合、可排序集,在这些基本数据结构上也提供了针对该数据结构的各种操作,这也是Redis之所以流行起来的一个重要原因,当然Redis能够流行起来的原因,远远不只这一个,如支持高并发的读写、数据的持久化、高效的内存管理及淘汰机制...
从Redis的git提交历史中,可以查到,2009/10/24在1.050版本,Redis开始支持可排序集,在该版本中,只提供了一条命令zadd,宏定义如下所示:
那么什么是可排序集呢? 从Redis 1.0开始就给我们提供了集合(Set)这种数据结构,集合就跟数学上的集合概念是一个道理【无序性,确定性,互异性】,集合里的元素无法保证元素的顺序,而业务上的需求,可能不止是一个集合,而且还要求能够快速地对集合元素进行排序,于是乎,Redis中提供了可排序集这么一种数据结构,似乎也是合情合理,无非就是在集合的基础上增加了排序功能,也许有人会问,Redis中不是有Sort命令嘛,下面的操作不也是同样可以达到对无序集的排序功能嘛,是的,是可以,但是在这里我们一直强调的是快速这两个字,而Sort命令的时间复杂度为O(N+M*Log(M)),可排序集获取一定范围内元素的时间复杂度为O(log(N)
+ M)
在了解可排序集是如何实现之前,需要了解一种数据结构跳表(Skip List),跳表与AVL、红黑树...等相比,数据结构简单,算法易懂,但查询的时间复杂度与平衡二叉树/红黑树相当,跳表的基本结构如下图所示
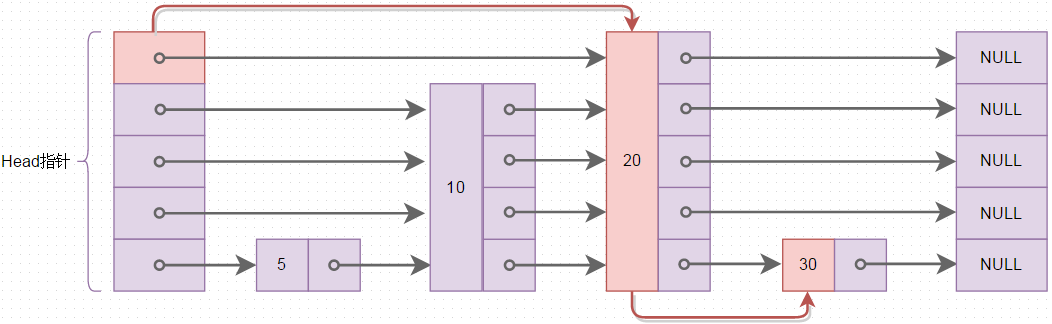
上图中整个跳表结构存放了4个元素5->10->20->30,图中的红色线表示查找元素30时,走的查找路线,从Head指针数组里最顶层的指针所指的20开始比较,与普通的链表查找相比,跳表的查询可以跳跃元素,上图中查询30,发现30比20大,则查找就是20开始,而普通链表的查询必须一个元素一个元素的比较,时间复杂度为O(n)
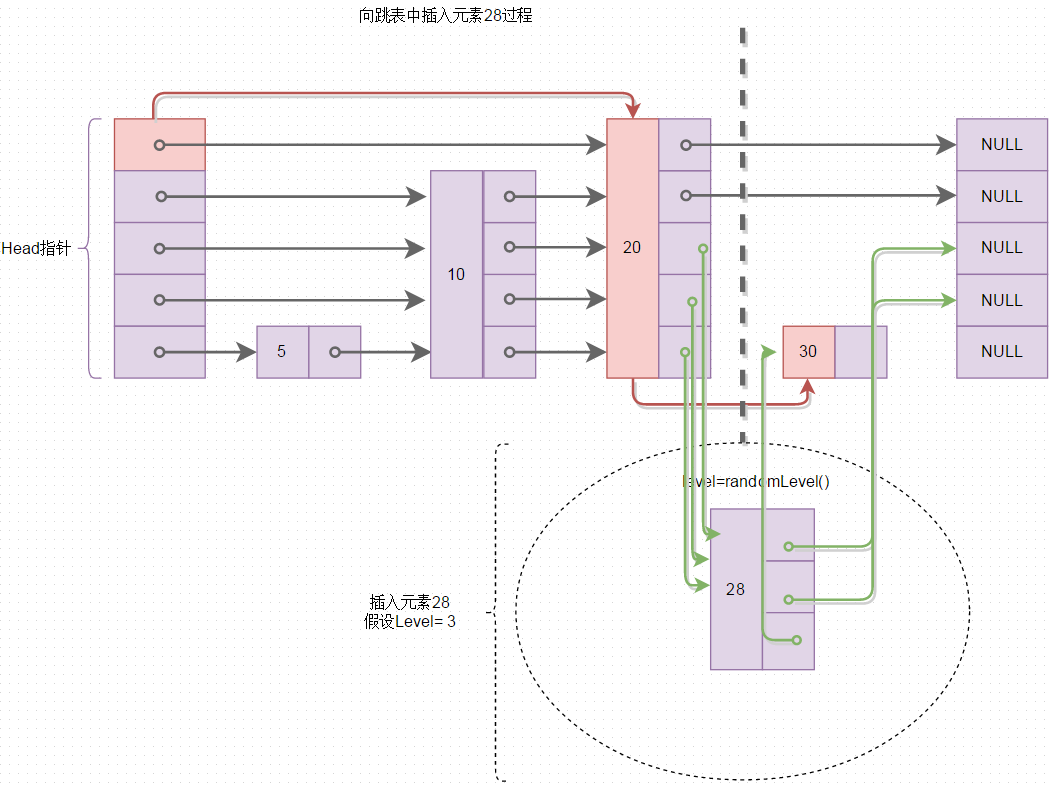
有了上图所示的跳表基本结构,再看看如何向跳表中插入元素,向跳表中插入元素,由于元素所在层级的随机性,平均起来也是O(logn),说白了,就是查找元素应该插入在什么位置,然后就是普通的移动指针问题,再想想往有序单链表的插入操作吧,时间复杂度是不是也是O(n),下图所示是往跳表中插入元素28的过程,图中红色线表示查找插入位置的过程,绿色线表示进行指针的移动,将该元素插入
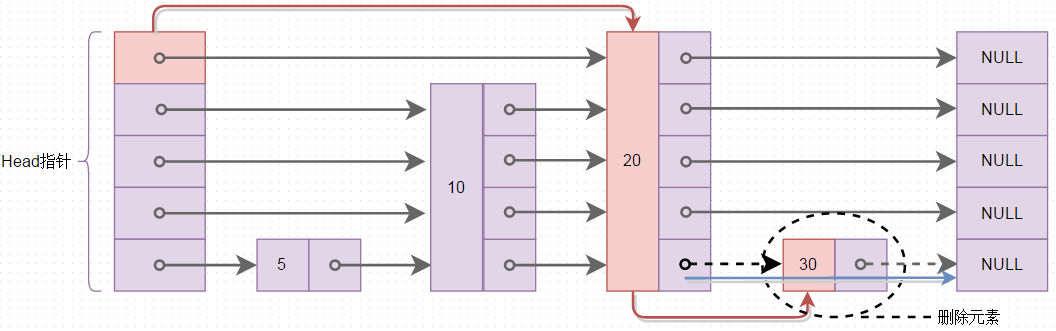
有了跳表的查找及插入那么就看看在跳表中如何删除元素吧,跳表中删除元素的个程,查找要删除的元素,找到后,进行指针的移动,过程如下图所示,删除元素30
有了上面的跳表基本结构图及原理,自已设计及实现跳表吧,这样当看到Redis里面的跳表结构时我们会更加熟悉,更容易理解些,【下面是对Redis中的跳表数据结构及相关代码进行精减后形成的可运行代码】,首先定义跳表的基本数据结构如下所示
?
在代码中我们定义了跳表结构中保存的数据为Key->Value这种形式的键值对,注意的是skiplistNode里面内含了一个结构体,代表的是层级,并且定义了跳表的最大层级为32级,下面的代码是创建空跳表,以及层级的获取方式
?
在这段代码中,使用了随机函数获取过元素所在的层级,下面就是重点,向跳表中插入元素,插入元素之前先查找插入的位置,代码如下所示,代码中注意update[i]
?
下面是代码中删除节点的操作,和插入节点类似
?
最后,附上一个不优雅的测试样例
?
有了上面的跳表理论基础,理解Redis中跳表的实现就不是那么难了
http://www.cnblogs.com/WJ5888/p/4516782.html
Redis中支持的数据结构比Memcached要多的多啦,如基本的字符串、哈希表、列表、集合、可排序集,在这些基本数据结构上也提供了针对该数据结构的各种操作,这也是Redis之所以流行起来的一个重要原因,当然Redis能够流行起来的原因,远远不只这一个,如支持高并发的读写、数据的持久化、高效的内存管理及淘汰机制...
从Redis的git提交历史中,可以查到,2009/10/24在1.050版本,Redis开始支持可排序集,在该版本中,只提供了一条命令zadd,宏定义如下所示:
1 {"zadd",zaddCommand,4,REDIS_CMD_BULK|REDIS_CMD_DENYOOM},那么什么是可排序集呢? 从Redis 1.0开始就给我们提供了集合(Set)这种数据结构,集合就跟数学上的集合概念是一个道理【无序性,确定性,互异性】,集合里的元素无法保证元素的顺序,而业务上的需求,可能不止是一个集合,而且还要求能够快速地对集合元素进行排序,于是乎,Redis中提供了可排序集这么一种数据结构,似乎也是合情合理,无非就是在集合的基础上增加了排序功能,也许有人会问,Redis中不是有Sort命令嘛,下面的操作不也是同样可以达到对无序集的排序功能嘛,是的,是可以,但是在这里我们一直强调的是快速这两个字,而Sort命令的时间复杂度为O(N+M*Log(M)),可排序集获取一定范围内元素的时间复杂度为O(log(N)
+ M)
root@bjpengpeng-VirtualBox:/home/bjpengpeng/redis-3.0.1/src# ./redis-cli 127.0.0.1:6379> sort set 1) "1" 2) "2" 3) "3" 4) "5" 127.0.0.1:6379> sort set desc 1) "5" 2) "3" 3) "2" 4) "1" 127.0.0.1:6379>
在了解可排序集是如何实现之前,需要了解一种数据结构跳表(Skip List),跳表与AVL、红黑树...等相比,数据结构简单,算法易懂,但查询的时间复杂度与平衡二叉树/红黑树相当,跳表的基本结构如下图所示
上图中整个跳表结构存放了4个元素5->10->20->30,图中的红色线表示查找元素30时,走的查找路线,从Head指针数组里最顶层的指针所指的20开始比较,与普通的链表查找相比,跳表的查询可以跳跃元素,上图中查询30,发现30比20大,则查找就是20开始,而普通链表的查询必须一个元素一个元素的比较,时间复杂度为O(n)
有了上图所示的跳表基本结构,再看看如何向跳表中插入元素,向跳表中插入元素,由于元素所在层级的随机性,平均起来也是O(logn),说白了,就是查找元素应该插入在什么位置,然后就是普通的移动指针问题,再想想往有序单链表的插入操作吧,时间复杂度是不是也是O(n),下图所示是往跳表中插入元素28的过程,图中红色线表示查找插入位置的过程,绿色线表示进行指针的移动,将该元素插入
有了跳表的查找及插入那么就看看在跳表中如何删除元素吧,跳表中删除元素的个程,查找要删除的元素,找到后,进行指针的移动,过程如下图所示,删除元素30
有了上面的跳表基本结构图及原理,自已设计及实现跳表吧,这样当看到Redis里面的跳表结构时我们会更加熟悉,更容易理解些,【下面是对Redis中的跳表数据结构及相关代码进行精减后形成的可运行代码】,首先定义跳表的基本数据结构如下所示
?
在代码中我们定义了跳表结构中保存的数据为Key->Value这种形式的键值对,注意的是skiplistNode里面内含了一个结构体,代表的是层级,并且定义了跳表的最大层级为32级,下面的代码是创建空跳表,以及层级的获取方式
?
?
?
?

相关文章推荐
- redis安装问题小结
- Linux C函数参考手册(PDF版)
- Redis偶发连接失败案例实战记录
- Redis中实现查找某个值的范围
- Redis和Memcached的区别详解
- 分割超大Redis数据库例子
- Redis总结笔记(一):安装和常用命令
- Redis sort 排序命令详解
- Lua教程(十七):C API简介
- Lua教程(七):数据结构详解
- redis中修改配置文件中的端口号 密码方法
- 在Ruby on Rails上使用Redis Store的方法
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- Redis和Memcache的区别总结
- C#数据结构揭秘一
- C#实现打造气泡屏幕保护效果
- 在Node.js应用中使用Redis的方法简介
- Redis服务器的启动过程分析
- C/C++数据对齐详细解析