计算机基础及发展历史
2015-08-11 17:50
369 查看
一:虚拟机安装Linux虚拟化技术: vmware workstation 11 virtualbox如何使用vmw 11安装虚拟机创建虚拟机:虚拟机监视器:vmm
cpu
time slice(分片)memory i/o 硬盘 磁盘映像文件:用文件模拟硬盘 loopback 网卡 模拟 键盘、鼠标 监视器
1、计算机如何计时的?
2、安装方式 a、cobbler b、基于ISO映像
二、软件与程序程序:指令+数据
狭义的来讲
其实程序就是软件,软件就是程序。
但从广义上来讲
软件主要是一个商业概念,而程序是一个纯计算机概念。
程序=指令+数据。其实就是说我用了一连串什么样的动作,需要输入一些什么数据,最后输出一些什么数据。
而软件不同,软件是我不仅写出了程序,我还要把这个程序和别人分享,或者是卖给用户。那用户并不知道你这个程序是干啥的,所以要配以相关的文档(文档的用途其实很多……),提供相关的服务。这样才能很好的实现程序的交换。
三、计算机体系结构上电自检:(POST:Power-On-Self-Test)是BIOS功能的一个主要部分。它负责完成对CPU、主板、内存、软硬盘子系统、显示子系统(包括显示缓存)、串并行接口、键盘、CD-ROM光驱等的检测。
BIOS: "Basic Input Output System",译为"基本输入输出系统",与前者读法相同。计算机在运行时,首先会进入BIOS,它在计算机系统中起着非常重要的作用。一块主板性能优越与否,很大程度上取决于主板上的BIOS管理功能是否先进。
计算机体系结构:
计算机硬件系统五大部件由
运算器、
控制器、
存储器、 内存 编址存储设备 每个存储单位是8位一个字节,每个字节都有地址 平面编址 (三维编址)
输入设备、
输出设备
1、控制器
控制器是对输入的指令进行分析,并统一控制计算机的各个部件完成一定任务的部件。它一般由指令寄存器、状态寄存器、指令译码器、时序电路和控制电路组成。是协调指挥计算机各部件工作的元件,其功能是从内存中依次取出命令,产生控制信号,向其他部件发出指令,指挥整个运算过程。控制器是统一指挥、协调其他部件的中枢。2、运算器
运算器又称算术逻辑单元(Arithmetic Logic Unit简称ALU),是进行算术、逻辑运算的部件。运算器的主要作用是执行各种算术运算和逻辑运算,对数据进行加工处理。
控制器、运算器和寄存器等组成硬件系统的核心----中央处理器(Central Processing Unit,简称 CPU)。CPU用大规模集成电路工艺集成在一块芯片上,是计算机系统的核心设备。
3、存储器 存储器是计算机记忆或暂存数据的部件。计算机中的全部信息,包括原始的输入数据。经过初步加工的中间数据以及最后处理完成的有用信息都存放在存储器中。而且,指挥计算机运行的各种程序,即规定对输入数据如何进行加工处理的一系列指令也都存放在存储器中。存储器分为内存储器(简称内存或主存)、外存储器(简称外存或辅存,如硬盘)。
4、输入设备
输入设备是是重要的人机接口,用来接受用户输入的原始数据和程序,并将它们变为计算机能识别的二进制存入到内存中。常用的输入设备有键盘、鼠标、扫描仪、光笔等。5、输出设备
输出设备是输出计算机处理结果的设备,用于将存入在内存中的由计算机处理的结果转变为人们能接受的形式输出。常用的输出设备有显示器、打印机、绘图仪等。南桥是主板上芯片组中最重要的两块,它们都是总线控制器.他们是总线控制芯片,相对的来讲,北桥要比南桥更加重要,北桥连接系统总线,担负着cpu访问内存的重任,同时连接这AGP插口,控制PCI总线,割断了系统总线和局部总线,在这一段上速度是最快的.南桥不和CPU连接通常用来作I/O和IDE设备的控制,所以速度比较慢,一般情况下,南桥和北桥中间是PCI总线。 1、南桥和北桥芯片主要区别 南桥主要是负责IO,北桥用于CPU和内存、显卡、PCI交换数据。中断 interrupt 硬件通知机制
不同的设备对应的中断不同,而每个中断都通过一个惟一的数字标识。因此,来自键盘的中断就有别于来自硬盘的中断,从而使得操作系统能够对中断进行区分,并知道哪个硬件设备产生了哪个中断。这样,操作系统才能给不同的中断提供不同的中断处理程序。
在它执行程序的时候,如果有另外的事件发生(比如用户又打开了一个程序)那么这时候就需要由计算机系统的中断机制来处理了。
中断机制包括硬件的中断装置和操作系统的中断处理服务程序。
让硬件在需要的时候再向内核发出信号。
程序的局部性原理:
时间局部性:
空间局部性:
机器语言:
微码(汇编语言)-----编译器 跟硬件芯片结合紧密 低级语言
高级语言:实现效率高,执行效率低,对硬件的可控性弱,目标代码大,可维护性好,可移植性好低级语言:实现效率低,执行效率高,对硬件的可控性强,目标代码小,可维护性差,可移植性差越低级的语言,形式上越接近机器指令,汇编语言就是与机器指令一一对应的。而越高级的语言,一条语句对应的指令数越多,其中原因就是高级语言对底层操作进行了抽象和封装,使编写程序的过程更符合人类的思维习惯,并且极大了简化了人力劳动。也就是说你用高级语言写一句,会被转换成许多底层操作,大部分的工作交给了负责转换的机器(即编译器),从而人力得到了解放
三、操作系统
操作系统是用户和计算机的接口,同时也是计算机硬件和其他软件的接口。操作系统的功能包括管理计算机系统的硬件、软件及数据资源,控制程序运行,改善人机界面,为其它应用软件提供支持,让计算机系统所有资源最大限度地发挥作用,提供各种形式的用户界面,使用户有一个好的工作环境,为其它软件的开发提供必要的服务和相应的接口等。实际上,用户是不用接触操作系统的,
操作系统管理着计算机硬件资源,同时按照应用程序的资源请求,分配资源,如:划分CPU时间,内存空间的开辟,调用打印机等。
内核,是一个操作系统的核心。它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性
OS的功能:
1、将硬件规格抽象为系统调用(system call)
2、进程管理,
7、 内存管理
3、文件系统
4、硬件驱动
5、网络协议栈
6、安全功能
系统调用 system call
库调用
系统运行模式:
用户模式
内核模式
API:应用编程接口 库的调用规范,
IEEE:POS(Portable Operationg System) posix
ABI: 应用二进制接口
库:一推程序,没有执行入口,被其它程序调用执行,弥补硬件平台不同 指令功能模块,减少程序体积
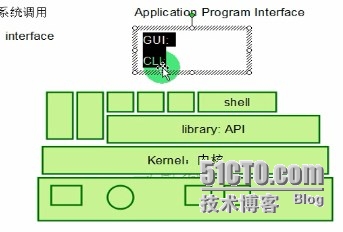
shell:人机交互接口
图形化 GUI
命令行 CLI
复杂指令集CPU内部为将较复杂的指令译码,也就是指令较长,分成几个微指令去执行,正是如此开发程序比较容易(指令多的缘故),但是由于指令复杂,执行工作效率较差,处理数据速度较慢,PC 中 Pentium的结构都为CISC CPU。
RISC是精简指令集CPU,指令位数较短,内部还有快速处理指令的电路,使得指令的译码与数据的处理较快,所以执行效率比CISC高,不过,必须经过编译程序的处理,才能发挥它的效率,我所知道的IBM的 Power PC为RISC CPU的结构,CISCO 的CPU也是RISC的结构。
咱们经常见到的PC中的CPU,Pentium-Pro(P6)、Pentium-II,Cyrix的M1、M2、AMD的K5、K6实际上是改进了的CISC,也可以说是结合了CISC和RISC的部分优点。
四、cpu架构与操作系统类型
CPU架构类型:
x86:Intel,amd,32bits
x64:amd64,
pc server
ARM:32,64
安腾:
sparc unlrasparc SUN
Alpha:
UltraSparc SUN
Power: IBM
M68000,M68K MOTO
PowerPC: APPLE IBM MOTO
OS:
Windows
Linux
Unix
HP-UX alpha HP
Solaris SUN
AIX IBM
SCO UNIX SCO
OS/2
批处理系统
GE,BELL,MIT Multics是由麻省理工学院,AT&T贝尔实验室和通用电气合作进行的操作系统项目
MULTICS 汇编语言
ken汤普逊: space travel
IBM:
DEC: PDP-11,PDP-7 VAX -- vms 1969 汇编语言
C语言 1971 B语言在进行系统编程时不够强大,所以汤普逊和里奇对其进行了改造,并与1971年共同发明了C语言
用C语重写Unix 1973 用C语言编写的Unix代码简洁紧凑、易移植、易读、易修改,为此后Unix的发展奠定了坚实基础。
1980,DARPA,
TCP/IP
Bill Joy: BSRG
BSD:Berkeley System Distribution 1977
System V
1981年 Microsoft,Xenix
cp/m--DOS
Windows NT Server
Xerox:PARK实验室 第一个图形操作界面,第一个鼠标
jobs:Apple
Andrew:Minix
Linus:Linux
GNU/Linux
80年代:Stallman,Freedom
GNU: GNU is Not Unix
GPL:General Public License 通用公用许可证
LGPL:
GPLV2
GPLV3
BSD
Apache
开源:开放源代码
自由软件:使用的自由 研究的自由 散步的自由 改良的自由
CEN
FreeBSD pc机
OpenBSD 安全
NetBSD 服务
Sun OS -- Solaris
Cshell
五、linux版本
linux 内核版本 https://www.kernel.org 4.1.5 version: major:主版号 minor:次版本号 release:发行号,修正号
LINUX OS发行版: kernel,GNU 提供一个安装程序 REDHAT:red hat enterpise linux fedora(red hat linux9.0) centos DEBIAN:Ubuntu slackware:suse Gentoo:
LFS
Unix的哲学基础:
简而言之:一个程序只做一件事,并做好,程序间要能互相协作,程序要能处理文本流
Linux的基本原则:
1、由目的单一的小程序组成:组合小程序完成复杂任务
2、一切皆文件
3、尽量避免捕获用户接口
4、配置文件保存为纯文本格式
密码复杂性:1、使用4种类别字符中至少3种2、足够长,大于7位3、使用随机字符串4、定期更换5、循环周期足够大
计算机中带符号的整数为何采用二进制的补码进行存储? 我们都知道在计算机内部数据的存储和运算都采用二进制,是因为计算机是由很多晶体管组成的,而晶体管只有2种状态,恰好可以用二进制的0和1表示,并且采用二进制可以使得计算机内部的运算规则简单,稳定性高。在计算机中存在实数和整数,而整数又分为无符号整数和有符号整数,无符号的整数表示很简单,直接采用其二进制形式表示即可,而对于有符号数的表示却成了问题,如何表示正负?如何去处理正负号?下面来具体说下其中的原因,在这之前先了解一下原码、反码和补码这几个概念。1.原码、反码和补码的概念 在了解原码、反码和补码之前先说一下有符号数和无符号数。用过C语言的都知道在C语言中用signed和unsigned来标识一个数是否是有符号还是无符号类型的。对于一个8bit的二进制来说,若当做无符号数处理,其能表示的整型值范围是0~255,但是这样表示数据就有个局限性,如果数据是负的该如何表示?因此就引入了有符号类型的概念,对于有符号类型,规定取最高位为符号位,若最高位为0,则为正数,否则为负数,这样一来对于8位二进制,示数值的就只有7位了,能够表示的非负数值范围变为0~127,负值范围为-127~-1,相当于可以理解为将无符号类型能够表示的128~255拿来去表示-127~-1了。事实上,在计算机内部存储中,计算机自己是无法去区分无符号还是有符号类型的,对于255和-1,在计算机内部存储的都是11111111。换个角度来说,如果事先知道内存中存储了这样一个8位二进制11111111,但是谁也不能肯定它具体表示什么数值,是-1还是255?这个是需要靠程序员自己去指定的,如果指定为无符号类型,则编译器则通过相应指令将其转换为数值255。事实上对于-x的二进制补码表示形式和(256-x)(256-x当做无符号类型处理)的二进制表示形式相同,从这里可以略微了解了补码的含义了。在教材中对于原码、反码以及补码一般是这么定义的: 对于正数原码、反码以及补码是其本身。负数的原码是其本身,反码是对原码除符号位之外的各位取反,补码则是反码加1。 因为(-x)的二进制补码形式和256-x的二进制表示形式相同,而255-x相当于对x的每一位取反,那么256-x就是255-x后加1。 注意:1)原码、反码、补码的概念是针对有符号类型而言的。 2)实数始终是有符号类型的(实数并不是采用补码形式存储的,具体可参考《浅谈C/C++的浮点数在内存中的存储方式》一文),整型数据包括无符号和有符号类型的。2.采用补码表示带符号的整数的原因 对于有符号类型的整数,有原码、反码和补码三种形式,最后选择了补码来表示,具体来说有下面几点原因。 1)能够统一+0和-0的表示 采用原码表示,+0的二进制表示形式为0 000 0000,而-0的二进制表示形式为1 000 0000;
采用反码表示,+0的二进制表示形式为0 000 0000,而-0的二进制表示形式为1 111 1111; 采用补码表示,+0的二进制表示形式为0 000 0000,而-0的二进制表示形式为1 111 1111+1=1 0000 0000,因为计算机会进行截断,只取低8位,所以-0的补码表示形式为0000 0000。 从上面可以看出只有用补码表示,+0和-0的表示形式才一致。正因为如此,所以补码的表示范围比原码和反码表示的范围都要大,用补码能够表示的范围为-128~127,0~127分别用00000000~01111111来表示,而-127~-1则用10000001~11111111来表示,多出的10000000则用来表示-128。因此对于任何一个n位的二进制,假若表示带符号的整数,其表示范围为-2^(n-1)~2^(n-1)-1,且有MAX+1=MIN。看下面一段代码:
cpu
time slice(分片)memory i/o 硬盘 磁盘映像文件:用文件模拟硬盘 loopback 网卡 模拟 键盘、鼠标 监视器
1、计算机如何计时的?
2、安装方式 a、cobbler b、基于ISO映像
二、软件与程序程序:指令+数据
狭义的来讲
其实程序就是软件,软件就是程序。
但从广义上来讲
软件主要是一个商业概念,而程序是一个纯计算机概念。
程序=指令+数据。其实就是说我用了一连串什么样的动作,需要输入一些什么数据,最后输出一些什么数据。
而软件不同,软件是我不仅写出了程序,我还要把这个程序和别人分享,或者是卖给用户。那用户并不知道你这个程序是干啥的,所以要配以相关的文档(文档的用途其实很多……),提供相关的服务。这样才能很好的实现程序的交换。
三、计算机体系结构上电自检:(POST:Power-On-Self-Test)是BIOS功能的一个主要部分。它负责完成对CPU、主板、内存、软硬盘子系统、显示子系统(包括显示缓存)、串并行接口、键盘、CD-ROM光驱等的检测。
BIOS: "Basic Input Output System",译为"基本输入输出系统",与前者读法相同。计算机在运行时,首先会进入BIOS,它在计算机系统中起着非常重要的作用。一块主板性能优越与否,很大程度上取决于主板上的BIOS管理功能是否先进。
计算机体系结构:
计算机硬件系统五大部件由
运算器、
控制器、
存储器、 内存 编址存储设备 每个存储单位是8位一个字节,每个字节都有地址 平面编址 (三维编址)
输入设备、
输出设备
1、控制器
控制器是对输入的指令进行分析,并统一控制计算机的各个部件完成一定任务的部件。它一般由指令寄存器、状态寄存器、指令译码器、时序电路和控制电路组成。是协调指挥计算机各部件工作的元件,其功能是从内存中依次取出命令,产生控制信号,向其他部件发出指令,指挥整个运算过程。控制器是统一指挥、协调其他部件的中枢。2、运算器
运算器又称算术逻辑单元(Arithmetic Logic Unit简称ALU),是进行算术、逻辑运算的部件。运算器的主要作用是执行各种算术运算和逻辑运算,对数据进行加工处理。
控制器、运算器和寄存器等组成硬件系统的核心----中央处理器(Central Processing Unit,简称 CPU)。CPU用大规模集成电路工艺集成在一块芯片上,是计算机系统的核心设备。
3、存储器 存储器是计算机记忆或暂存数据的部件。计算机中的全部信息,包括原始的输入数据。经过初步加工的中间数据以及最后处理完成的有用信息都存放在存储器中。而且,指挥计算机运行的各种程序,即规定对输入数据如何进行加工处理的一系列指令也都存放在存储器中。存储器分为内存储器(简称内存或主存)、外存储器(简称外存或辅存,如硬盘)。
4、输入设备
输入设备是是重要的人机接口,用来接受用户输入的原始数据和程序,并将它们变为计算机能识别的二进制存入到内存中。常用的输入设备有键盘、鼠标、扫描仪、光笔等。5、输出设备
输出设备是输出计算机处理结果的设备,用于将存入在内存中的由计算机处理的结果转变为人们能接受的形式输出。常用的输出设备有显示器、打印机、绘图仪等。南桥是主板上芯片组中最重要的两块,它们都是总线控制器.他们是总线控制芯片,相对的来讲,北桥要比南桥更加重要,北桥连接系统总线,担负着cpu访问内存的重任,同时连接这AGP插口,控制PCI总线,割断了系统总线和局部总线,在这一段上速度是最快的.南桥不和CPU连接通常用来作I/O和IDE设备的控制,所以速度比较慢,一般情况下,南桥和北桥中间是PCI总线。 1、南桥和北桥芯片主要区别 南桥主要是负责IO,北桥用于CPU和内存、显卡、PCI交换数据。中断 interrupt 硬件通知机制
不同的设备对应的中断不同,而每个中断都通过一个惟一的数字标识。因此,来自键盘的中断就有别于来自硬盘的中断,从而使得操作系统能够对中断进行区分,并知道哪个硬件设备产生了哪个中断。这样,操作系统才能给不同的中断提供不同的中断处理程序。
在它执行程序的时候,如果有另外的事件发生(比如用户又打开了一个程序)那么这时候就需要由计算机系统的中断机制来处理了。
中断机制包括硬件的中断装置和操作系统的中断处理服务程序。
让硬件在需要的时候再向内核发出信号。
程序的局部性原理:
时间局部性:
空间局部性:
机器语言:
微码(汇编语言)-----编译器 跟硬件芯片结合紧密 低级语言
高级语言:实现效率高,执行效率低,对硬件的可控性弱,目标代码大,可维护性好,可移植性好低级语言:实现效率低,执行效率高,对硬件的可控性强,目标代码小,可维护性差,可移植性差越低级的语言,形式上越接近机器指令,汇编语言就是与机器指令一一对应的。而越高级的语言,一条语句对应的指令数越多,其中原因就是高级语言对底层操作进行了抽象和封装,使编写程序的过程更符合人类的思维习惯,并且极大了简化了人力劳动。也就是说你用高级语言写一句,会被转换成许多底层操作,大部分的工作交给了负责转换的机器(即编译器),从而人力得到了解放
三、操作系统
操作系统是用户和计算机的接口,同时也是计算机硬件和其他软件的接口。操作系统的功能包括管理计算机系统的硬件、软件及数据资源,控制程序运行,改善人机界面,为其它应用软件提供支持,让计算机系统所有资源最大限度地发挥作用,提供各种形式的用户界面,使用户有一个好的工作环境,为其它软件的开发提供必要的服务和相应的接口等。实际上,用户是不用接触操作系统的,
操作系统管理着计算机硬件资源,同时按照应用程序的资源请求,分配资源,如:划分CPU时间,内存空间的开辟,调用打印机等。
内核,是一个操作系统的核心。它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性
OS的功能:
1、将硬件规格抽象为系统调用(system call)
2、进程管理,
7、 内存管理
3、文件系统
4、硬件驱动
5、网络协议栈
6、安全功能
系统调用 system call
库调用
系统运行模式:
用户模式
内核模式
API:应用编程接口 库的调用规范,
IEEE:POS(Portable Operationg System) posix
ABI: 应用二进制接口
库:一推程序,没有执行入口,被其它程序调用执行,弥补硬件平台不同 指令功能模块,减少程序体积
shell:人机交互接口
图形化 GUI
命令行 CLI
复杂指令集CPU内部为将较复杂的指令译码,也就是指令较长,分成几个微指令去执行,正是如此开发程序比较容易(指令多的缘故),但是由于指令复杂,执行工作效率较差,处理数据速度较慢,PC 中 Pentium的结构都为CISC CPU。
RISC是精简指令集CPU,指令位数较短,内部还有快速处理指令的电路,使得指令的译码与数据的处理较快,所以执行效率比CISC高,不过,必须经过编译程序的处理,才能发挥它的效率,我所知道的IBM的 Power PC为RISC CPU的结构,CISCO 的CPU也是RISC的结构。
咱们经常见到的PC中的CPU,Pentium-Pro(P6)、Pentium-II,Cyrix的M1、M2、AMD的K5、K6实际上是改进了的CISC,也可以说是结合了CISC和RISC的部分优点。
四、cpu架构与操作系统类型
CPU架构类型:
x86:Intel,amd,32bits
x64:amd64,
pc server
ARM:32,64
安腾:
sparc unlrasparc SUN
Alpha:
UltraSparc SUN
Power: IBM
M68000,M68K MOTO
PowerPC: APPLE IBM MOTO
OS:
Windows
Linux
Unix
HP-UX alpha HP
Solaris SUN
AIX IBM
SCO UNIX SCO
OS/2
批处理系统
GE,BELL,MIT Multics是由麻省理工学院,AT&T贝尔实验室和通用电气合作进行的操作系统项目
MULTICS 汇编语言
ken汤普逊: space travel
IBM:
DEC: PDP-11,PDP-7 VAX -- vms 1969 汇编语言
C语言 1971 B语言在进行系统编程时不够强大,所以汤普逊和里奇对其进行了改造,并与1971年共同发明了C语言
用C语重写Unix 1973 用C语言编写的Unix代码简洁紧凑、易移植、易读、易修改,为此后Unix的发展奠定了坚实基础。
1980,DARPA,
TCP/IP
Bill Joy: BSRG
BSD:Berkeley System Distribution 1977
System V
1981年 Microsoft,Xenix
cp/m--DOS
Windows NT Server
Xerox:PARK实验室 第一个图形操作界面,第一个鼠标
jobs:Apple
Andrew:Minix
Linus:Linux
GNU/Linux
80年代:Stallman,Freedom
GNU: GNU is Not Unix
GPL:General Public License 通用公用许可证
LGPL:
GPLV2
GPLV3
BSD
Apache
开源:开放源代码
自由软件:使用的自由 研究的自由 散步的自由 改良的自由
CEN
FreeBSD pc机
OpenBSD 安全
NetBSD 服务
Sun OS -- Solaris
Cshell
五、linux版本
linux 内核版本 https://www.kernel.org 4.1.5 version: major:主版号 minor:次版本号 release:发行号,修正号
LINUX OS发行版: kernel,GNU 提供一个安装程序 REDHAT:red hat enterpise linux fedora(red hat linux9.0) centos DEBIAN:Ubuntu slackware:suse Gentoo:
LFS
Unix的哲学基础:
简而言之:一个程序只做一件事,并做好,程序间要能互相协作,程序要能处理文本流
Linux的基本原则:
1、由目的单一的小程序组成:组合小程序完成复杂任务
2、一切皆文件
3、尽量避免捕获用户接口
4、配置文件保存为纯文本格式
密码复杂性:1、使用4种类别字符中至少3种2、足够长,大于7位3、使用随机字符串4、定期更换5、循环周期足够大
计算机中带符号的整数为何采用二进制的补码进行存储? 我们都知道在计算机内部数据的存储和运算都采用二进制,是因为计算机是由很多晶体管组成的,而晶体管只有2种状态,恰好可以用二进制的0和1表示,并且采用二进制可以使得计算机内部的运算规则简单,稳定性高。在计算机中存在实数和整数,而整数又分为无符号整数和有符号整数,无符号的整数表示很简单,直接采用其二进制形式表示即可,而对于有符号数的表示却成了问题,如何表示正负?如何去处理正负号?下面来具体说下其中的原因,在这之前先了解一下原码、反码和补码这几个概念。1.原码、反码和补码的概念 在了解原码、反码和补码之前先说一下有符号数和无符号数。用过C语言的都知道在C语言中用signed和unsigned来标识一个数是否是有符号还是无符号类型的。对于一个8bit的二进制来说,若当做无符号数处理,其能表示的整型值范围是0~255,但是这样表示数据就有个局限性,如果数据是负的该如何表示?因此就引入了有符号类型的概念,对于有符号类型,规定取最高位为符号位,若最高位为0,则为正数,否则为负数,这样一来对于8位二进制,示数值的就只有7位了,能够表示的非负数值范围变为0~127,负值范围为-127~-1,相当于可以理解为将无符号类型能够表示的128~255拿来去表示-127~-1了。事实上,在计算机内部存储中,计算机自己是无法去区分无符号还是有符号类型的,对于255和-1,在计算机内部存储的都是11111111。换个角度来说,如果事先知道内存中存储了这样一个8位二进制11111111,但是谁也不能肯定它具体表示什么数值,是-1还是255?这个是需要靠程序员自己去指定的,如果指定为无符号类型,则编译器则通过相应指令将其转换为数值255。事实上对于-x的二进制补码表示形式和(256-x)(256-x当做无符号类型处理)的二进制表示形式相同,从这里可以略微了解了补码的含义了。在教材中对于原码、反码以及补码一般是这么定义的: 对于正数原码、反码以及补码是其本身。负数的原码是其本身,反码是对原码除符号位之外的各位取反,补码则是反码加1。 因为(-x)的二进制补码形式和256-x的二进制表示形式相同,而255-x相当于对x的每一位取反,那么256-x就是255-x后加1。 注意:1)原码、反码、补码的概念是针对有符号类型而言的。 2)实数始终是有符号类型的(实数并不是采用补码形式存储的,具体可参考《浅谈C/C++的浮点数在内存中的存储方式》一文),整型数据包括无符号和有符号类型的。2.采用补码表示带符号的整数的原因 对于有符号类型的整数,有原码、反码和补码三种形式,最后选择了补码来表示,具体来说有下面几点原因。 1)能够统一+0和-0的表示 采用原码表示,+0的二进制表示形式为0 000 0000,而-0的二进制表示形式为1 000 0000;
采用反码表示,+0的二进制表示形式为0 000 0000,而-0的二进制表示形式为1 111 1111; 采用补码表示,+0的二进制表示形式为0 000 0000,而-0的二进制表示形式为1 111 1111+1=1 0000 0000,因为计算机会进行截断,只取低8位,所以-0的补码表示形式为0000 0000。 从上面可以看出只有用补码表示,+0和-0的表示形式才一致。正因为如此,所以补码的表示范围比原码和反码表示的范围都要大,用补码能够表示的范围为-128~127,0~127分别用00000000~01111111来表示,而-127~-1则用10000001~11111111来表示,多出的10000000则用来表示-128。因此对于任何一个n位的二进制,假若表示带符号的整数,其表示范围为-2^(n-1)~2^(n-1)-1,且有MAX+1=MIN。看下面一段代码:
char ch=127; ch++;ch的值是多少?它的值是-128,读者可以上机验证一下。 假如不采用补码来表示,那么计算机中需要对+0和-0区别对待,显然这个对于设计来说要增加难度,而且不符合运算规则。 2)对于有符号整数的运算能够把符号位同数值位为一起处理 由于将最高位作为符号位处理,不具有实际的数值意义,那么如何在进行运算时处理这个符号位?如果单独把符号位进行处理,显然又会增加电子器件的设计难度和CPU指令设计的难度,但是采用补码能够很好地解决这个问题。下面举例说明: 比如-2+3=1 如果采用原码表示(把符号位同数值位一起处理): 1 000 0010+0 000 0011=1 000 0101=(-5)原,显然这个结果是错误的。 如果采用反码表示 1 111 1101+0 000 0011=1 0000 0000=0 0000000=(+0)反,显然这个结果也是错误的。 如果采用补码表示 1 111 1110+0 000 0011=1 0000 0001=0000 0001=(1)补,结果是正确的。 从上面可以看出,当把符号位同数值位一起进行处理时,只有补码的运算才是正确的。如果不把符号位和数值位一起处理,会给CPU指令的设计带来很大的困难,如果把符号位单独考虑的话,CPU指令还要特意对最高位进行判断,这个对于计算机的最底层实现来说是很困难的。 3)能够简化运算规则 对于-2+3=1这个例子来说,可以看作是3-2=1,也即[3]+[-2]=1,从上面的运算过程可知采用补码运算相当于是 [3]补+[-2]补=[1]补,也即可以把减法运算转换为加法运算。这样一来的好处是在设计电子器件时,只需要设计加法器即可,不需要单独再设计减法器。 总的来说,采用补码主要有以上几点好处,从而使得计算机从硬件设计上更加简单以及简化CPU指令的设计。测试代码#include<stdio.h>int main(void)
{ char ch=-1; char *p=(char *)&ch;
unsigned char uch=*p;
printf("%d\n",uch); //输出结果为255
return 0;
}

相关文章推荐
- iOS网络协议----HTTP/TCP/IP浅析!!!简单易懂
- TCP/IP协议三次握手及断开
- NOIP2014提高组 寻找道路
- NOIP2014 无线网路发射器选址
- twisted07 动态页http服务器
- NOIP2014 提高组 生活大爆炸版石头剪刀布
- 27-网络编程-23-网络编程(URL&URLConnection)
- 27-网络编程-24-网络编程(常见网络结构)
- 数据结构_堆排序介绍
- 27-网络编程-22-网络编程(模拟一个浏览器获取信息)
- http协议 telnet linux c http client 通讯
- 27-网络编程-20-网络编程(常见客户端和服务端)
- 27-网络编程-21-网络编程(了解客户端和服务器端原理)
- 数据结构实验:哈希表
- 27-网络编程-19-网络编程(TCP协议-练习-服务端多线程技术)
- 27-网络编程-17-网络编程(TCP协议-练习-上传图片客户端)
- 27-网络编程-18-网络编程(TCP协议-练习-上传图片服务端)
- 26-网络编程-15-网络编程(TCP协议-练习-常见问题)
- 26-网络编程-16-网络编程(TCP协议-练习-上传文本文件)
- NOIP2013 华容道 解题报告