java 7 collection 详解(二)
2015-08-07 18:27
519 查看
转载自:http://peiquan.blog.51cto.com/7518552/1290180
Queue提供了队列的实现,除了基本的Collection操作外,队列还提供其他的插入、提取和检查操作。队列通常(除优先级队列、LIFO队列)以 FIFO(先进先出)的方式排序各个元素。Queue接口代码如下:
每一个Queue方法都提供了两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(null 或 false,具体取决于操作)。插入操作的后一种形式是用于专门为有容量限制的 Queue 实现设计的;在大多数实现中,插入操作不会失败。详解如下表:
add和offer(e)可向队列里插入一个元素,插入失败事add抛出IllegalStateException,offer(e)返回false;remove和poll可移除可返回队列的头部元素,如果队列为空时,remove抛出NoSuchElementException,poll返回null;element和peek可以查看队列的头部元素(不移除),如果队列为空时,element抛出NoSuchElementException,peek返回null。
即使Queue的实现允许插入null元素,也不要往Queue队列里插入null。因为 null 也用作 poll 方法的一个特殊返回值,表明队列不包含元素。
这里给出一个计时器的Demo,来演示Queue的FIFO特性:
以上实现了一个十秒钟的倒计时,当然了对倒计时器可以有着更好的实现,这里只是为了更好演示Queue FIFO的性质。同样地,可以看一下优先级队列的性质。PriorityQueue,是一个基于优先级堆的无界优先级队列,其元素是按照其自然顺序排列,或者根据构造时提供的Comparator进行排序。PriorityQueue不允许使用
Demo:PriorityQueueTest,演示了优先级队列的性质:
其输出如下:

(按自然顺序输出)。
注意的,Queue 接口并未定义阻塞队列的方法,而这在并发编程中是很常见的。BlockingQueue 接口定义了那些等待元素出现或等待队列中有可用空间的方法,这些方法扩展了此接口。
BlockingQueue继承了Queue接口,在Queue的基础上增加了两个操作:(1)将指定元素插入此队列中,将等待可用的空间(如果有必要);(2)获取并移除此队列的头部,在元素变得可用之前一直等待(如果有必要)。 方法如下表:
在此已经涉及并发编程了,例如我们可以使用BlockingQueue来控制连接池的连接,如果连接池已满,新来的连接则需要等待,过了一定的时间,可以移除部分连接,这些将会在java并发里谈到,有兴趣的可以了解一下java的并发编程。
一个Map就是将键映射到值得对象。一个映射里不能包含相同的Key,同时一个Key最多映射到一个值。这个概念有点像数学里的函数定义。Map接口代码如下:
java提供了三种常用的Map实现:HashMap, TreeMap, 和LinkedHashMap. 其机制与HashSet、TreeSet和LinkedHashSet相似,详情可了解上一节的Set接口的内容。同样地,从java 2开始,HashTable改进为Map的一种实现。
Map的基本操作有put、get、containsKey、containsValue、size和isEmpty。以Demo Frequency.java演示Map的基本操作,在这个Demo里,我们去计算一段话里各个单词出现的次数。
其输出如下:

与Set类似,如果需要以自然顺序输出map的键值对,可以使用TreeMap实现。
Map<String, Integer> map = new TreeMap<>();
其输出如下:
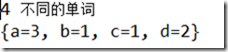
同样地,如果想按照插入的顺序输出map的键值对,可以使用LinkedHashMap。
Map<String, Integer> map = new LinkedHashMap<>();
其输出如下:

在此,也需要指出的就是,所有Map的实现,都需要提供一个空的构造函数,另外是有一个map参数的构造函数,带map参数的构造函数可以允许复制一个map。其作用原理与Collection类似。
Map<K, V> copy = new HashMap<K, V>(m);
clear()方法可以清空Map里的所有键值对;putall()方法可以将另一个map里的键值对添加进来,类似于Collection里的addAll()方法。类似地,我们可以利用putAll()方法将两个Map合并成一个新的Map,如下所示:
Collection视图方法允许把Map当作一个Collection来处理。Map 接口提供三种了Collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容,其方法如下:
遍历Collection视图的方法,类似的可以使用foreach方法或使用Iterator接口,当中Key视图与value视图的遍历操作类似,这里以key视图为例:
key-value视图的遍历其实也很是类似,只不过这次用的是Map,Entry,
在这三种视图里,都可以是用Iterator#remove()方法移除Map里的元素.对于key-value视图,迭代时还可以Map.Entry#setValue.
Collection视图允许使用各种移除元素的方法,包括remove, removeAll, retainAll, 和 clear 方法,还包括Iterator的remove方法.可注意的是,在任何情况下,Collection视图都不支持添加元素的方法.添加元素对于key视图和value视图没有任何意思,对key-value视图也没有必要,因为Map的put和putAll方法已经提供了添加元素的方法.
Collection视图的应用,往往就是各种Map批量操作的应用(
类似的,可以判断一下,m1与m2是否相等,即key的所有值都一样:
通常,我们会遇到这么一种情况,去判断Map对象是否有指定的值构成,现在我们假设有两个Set,当中一个Set包含里必须有的值,另外一个Set则包含里可能的值(可能的值包含了必须有的值),现在我们来判断一下,Map的属性值是否合法(即是否全包好了必须的值,其他值又是否都在可能的值去到):
在validate里只是简单的输出对应的信息,实际编程时来合理添加具体逻辑。类似的,看一下其他应用:如求两个Map的共同元素(即交集),可以这样实现:
那又如何删除两个Map的相同元素呢(差集)??
m1.entrySet().removeAll(m2.entrySet());
以上三种方法都可以删除map里相同的元素,可也有一定的区别。entrySet移除的是key-value一致的键值对(唯一),keySet移除的是key相同的值(唯一),values移除的是值相同的键值对(可能有多个,因为一个value,可以对应多个key)。
到现在为止所说的关于map的方法,都是无损的,因为这些方法都没有尝试去修改Map里的值。如果需要修改map的key值,注意不能原map里的其他key相同(map里包含相同的key),如果修改后的key值与某一key相同,会引发异常。
现在进一步来学一下map的应用,可以设想一下,如果在map批量操作里,同时操作里key和value视图,会发生什么情况或者说有什么作用??举个例子:假设有一个Map对象managers,以员工-上司的键值形式存储(这里假设员工、上司都是Employee对象,具体实现可根据实际情况来设计),现在需要找出没有分配到的经上司的员工,应该如何去找呢??
接着看一下,如何去删除(解雇)某个上司(经理)下的所有员工呢??
附:工厂方法Collections.singleton()在前面谈过,可以返回只包含某个对象的Set。
如果需要找出一线员工(即最低层的员工,注意上司还可以有上司的上司等)??
为了加深对上面逻辑的了解,可以看一下一个简单的Demo:MapTest.java
当中A输出:{3=2, 2=1}。注:此处“=”没有任何的意义,只是表示键值对的形式。
B输出:{2=1}
C输出:{3=2}
D输出:{3=2}
三种Collection视图方法,在实际应用的时候,只需要稍加推到可以得到多种灵活的变化。
一、Queue接口
Queue提供了队列的实现,除了基本的Collection操作外,队列还提供其他的插入、提取和检查操作。队列通常(除优先级队列、LIFO队列)以 FIFO(先进先出)的方式排序各个元素。Queue接口代码如下:public interface Queue<E> extends Collection<E> {
E element();
boolean offer(E e);
E peek();
E poll();
E remove();
}每一个Queue方法都提供了两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(null 或 false,具体取决于操作)。插入操作的后一种形式是用于专门为有容量限制的 Queue 实现设计的;在大多数实现中,插入操作不会失败。详解如下表:
| 操作类型 | 抛出异常 | 返回特殊值 |
| 插入 | add(e) | offer(e) |
| 删除 | remove() | poll() |
| 查看 | element() | peek() |
即使Queue的实现允许插入null元素,也不要往Queue队列里插入null。因为 null 也用作 poll 方法的一个特殊返回值,表明队列不包含元素。
这里给出一个计时器的Demo,来演示Queue的FIFO特性:
public class Counter {
public static void main(String[] args) throws Exception {
int time = 10;//十秒倒数
Queue<Integer> queue = new LinkedList<Integer>();
//初始化queue
for (int i = time; i >= 0; i--){
queue.add(i);
}
while (!queue.isEmpty()) {
System.out.println(queue.remove());
Thread.sleep(1000);
}
}
}以上实现了一个十秒钟的倒计时,当然了对倒计时器可以有着更好的实现,这里只是为了更好演示Queue FIFO的性质。同样地,可以看一下优先级队列的性质。PriorityQueue,是一个基于优先级堆的无界优先级队列,其元素是按照其自然顺序排列,或者根据构造时提供的Comparator进行排序。PriorityQueue不允许使用
null元素,依靠自然顺序的PriorityQueue还不允许插入不可比较的对象(会抛出
ClassCastException)。
Demo:PriorityQueueTest,演示了优先级队列的性质:
public class PriorityQueueTest {
static <E> List<E> heapSort(Collection<E> c) {
Queue<E> queue = new PriorityQueue<>(c);
List<E> result = new ArrayList<>();
while (!queue.isEmpty()) {
result.add(queue.remove());
}
return result;
}
public static void main(String[] args) {
String[] str = { "d", "b", "a", "c" };
List<String> list = new ArrayList<>();
for (String s : str) {
list.add(s);
}
System.out.println(heapSort(list));
}
}其输出如下:

(按自然顺序输出)。
注意的,Queue 接口并未定义阻塞队列的方法,而这在并发编程中是很常见的。BlockingQueue 接口定义了那些等待元素出现或等待队列中有可用空间的方法,这些方法扩展了此接口。
BlockingQueue继承了Queue接口,在Queue的基础上增加了两个操作:(1)将指定元素插入此队列中,将等待可用的空间(如果有必要);(2)获取并移除此队列的头部,在元素变得可用之前一直等待(如果有必要)。 方法如下表:
| 抛出异常 | 特殊值 | 阻塞 | 超时 | |
| 插入 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 移除 | remove() | poll() | take() | poll(time, unit) |
| 检查 | element() | peek() | 不可用 | 不可用 |
Map接口
一个Map就是将键映射到值得对象。一个映射里不能包含相同的Key,同时一个Key最多映射到一个值。这个概念有点像数学里的函数定义。Map接口代码如下:public interface Map<K,V> {
//基本操作
V put(K key, V value);
V get(Object key);
V remove(Object key);
boolean containsKey(Object key);
boolean containsValue(Object value);
int size();
boolean isEmpty();
// 批量操作
void putAll(Map<? extends K, ? extends V> m);
void clear();
// Collection视图
public Set<K> keySet();
public Collection<V> values();
public Set<Map.Entry<K,V>> entrySet();
//为entrySet元素提供的接口
public interface Entry {
K getKey();
V getValue();
V setValue(V value);
}
}java提供了三种常用的Map实现:HashMap, TreeMap, 和LinkedHashMap. 其机制与HashSet、TreeSet和LinkedHashSet相似,详情可了解上一节的Set接口的内容。同样地,从java 2开始,HashTable改进为Map的一种实现。
Map的基本操作
Map的基本操作有put、get、containsKey、containsValue、size和isEmpty。以Demo Frequency.java演示Map的基本操作,在这个Demo里,我们去计算一段话里各个单词出现的次数。public class Frequency {
public static void main(String[] args) {
String[] str = { "a", "c", "b", "d", "a", "d", "a" };
Map<String, Integer> map = new HashMap<>();
// 遍历str,取得频数分布表
for (String a : str) {
Integer count = map.get(a);
map.put(a, (count == null) ? 1 : count + 1);
}
System.out.println(map.size() + " 不同的单词");
System.out.println(map);
}
}其输出如下:

与Set类似,如果需要以自然顺序输出map的键值对,可以使用TreeMap实现。
Map<String, Integer> map = new TreeMap<>();
其输出如下:

同样地,如果想按照插入的顺序输出map的键值对,可以使用LinkedHashMap。
Map<String, Integer> map = new LinkedHashMap<>();
其输出如下:

在此,也需要指出的就是,所有Map的实现,都需要提供一个空的构造函数,另外是有一个map参数的构造函数,带map参数的构造函数可以允许复制一个map。其作用原理与Collection类似。
Map<K, V> copy = new HashMap<K, V>(m);
Map的批量操作
clear()方法可以清空Map里的所有键值对;putall()方法可以将另一个map里的键值对添加进来,类似于Collection里的addAll()方法。类似地,我们可以利用putAll()方法将两个Map合并成一个新的Map,如下所示:static <K, V> Map<K, V> newAttributeMap(Map<K, V>defaults, Map<K, V> overrides) {
Map<K, V> result = new HashMap<K, V>(defaults);
result.putAll(overrides);
return result;
}
Collection视图
Collection视图方法允许把Map当作一个Collection来处理。Map 接口提供三种了Collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容,其方法如下:keySet— 由Key组成Set视图
values— 由value组成Collection视图,但又与Set视图有区别,因为一个value可以映射到多个Key上(即可能有重复的元素)
entrySet— 由key-value组成的Set视图。在Map接口里内嵌里一个小接口Map.Entry
遍历Collection视图的方法,类似的可以使用foreach方法或使用Iterator接口,当中Key视图与value视图的遍历操作类似,这里以key视图为例:
//foreach方法
for (KeyType key : m.keySet()){
System.out.println(key);
}
//使用iterator接口
for (Iterator<Type> it = m.keySet().iterator(); it.hasNext(); ){
if (it.next().isBogus()){
it.remove();
}
}key-value视图的遍历其实也很是类似,只不过这次用的是Map,Entry,
for (Map.Entry<KeyType, ValType> e : m.entrySet()) {
System.out.println(e.getKey() + ": " + e.getValue());
}在这三种视图里,都可以是用Iterator#remove()方法移除Map里的元素.对于key-value视图,迭代时还可以Map.Entry#setValue.
Collection视图允许使用各种移除元素的方法,包括remove, removeAll, retainAll, 和 clear 方法,还包括Iterator的remove方法.可注意的是,在任何情况下,Collection视图都不支持添加元素的方法.添加元素对于key视图和value视图没有任何意思,对key-value视图也没有必要,因为Map的put和putAll方法已经提供了添加元素的方法.
Collection视图的应用:Map代数
Collection视图的应用,往往就是各种Map批量操作的应用(containsAll,
removeAll, 和
retainAll).
首先了解一下,如何去判断m2是不是m1的子Map,即判断m1是否包含了m2所有的key,
if (m1.entrySet().containsAll(m2.entrySet())) {
...
}类似的,可以判断一下,m1与m2是否相等,即key的所有值都一样:
if (m1.keySet().equals(m2.keySet())) {
...
}通常,我们会遇到这么一种情况,去判断Map对象是否有指定的值构成,现在我们假设有两个Set,当中一个Set包含里必须有的值,另外一个Set则包含里可能的值(可能的值包含了必须有的值),现在我们来判断一下,Map的属性值是否合法(即是否全包好了必须的值,其他值又是否都在可能的值去到):
static <K, V> boolean validate(Map<K, V> attrMap, Set<K> requiredAttrs, Set<K>permittedAttrs) {
boolean valid = true;
Set<K> attrs = attrMap.keySet();
if (! attrs.containsAll(requiredAttrs)) {//没有全包含必须有的值
Set<K> missing = new HashSet<K>(requiredAttrs);
missing.removeAll(attrs);
System.out.println("缺少的值有:" + missing);
valid = false;
}
if (! permittedAttrs.containsAll(attrs)) {
Set<K> illegal = new HashSet<K>(attrs);
illegal.removeAll(permittedAttrs);
System.out.println("不合法的值有: " + illegal);
valid = false;
}
return valid;
}在validate里只是简单的输出对应的信息,实际编程时来合理添加具体逻辑。类似的,看一下其他应用:如求两个Map的共同元素(即交集),可以这样实现:
Set<KeyType> commonKeys = new HashSet<>(m1.keySet()); commonKeys.retainAll(m2.keySet());
那又如何删除两个Map的相同元素呢(差集)??
m1.entrySet().removeAll(m2.entrySet());
或:m1.keySet().removeAll(m2.keySet());
或:m1.values().removeAll(m2.values());
以上三种方法都可以删除map里相同的元素,可也有一定的区别。entrySet移除的是key-value一致的键值对(唯一),keySet移除的是key相同的值(唯一),values移除的是值相同的键值对(可能有多个,因为一个value,可以对应多个key)。
到现在为止所说的关于map的方法,都是无损的,因为这些方法都没有尝试去修改Map里的值。如果需要修改map的key值,注意不能原map里的其他key相同(map里包含相同的key),如果修改后的key值与某一key相同,会引发异常。
现在进一步来学一下map的应用,可以设想一下,如果在map批量操作里,同时操作里key和value视图,会发生什么情况或者说有什么作用??举个例子:假设有一个Map对象managers,以员工-上司的键值形式存储(这里假设员工、上司都是Employee对象,具体实现可根据实际情况来设计),现在需要找出没有分配到的经上司的员工,应该如何去找呢??
Set<Employee> individualContributors = new HashSet<>(managers.keySet()); individualContributors.removeAll(managers.values());
接着看一下,如何去删除(解雇)某个上司(经理)下的所有员工呢??
Employee manager = ... ;//某个经理对象 managers.values().removeAll(Collections.singleton(manager));
附:工厂方法Collections.singleton()在前面谈过,可以返回只包含某个对象的Set。
如果需要找出一线员工(即最低层的员工,注意上司还可以有上司的上司等)??
Map<Employee, Employee> m = new HashMap<>(managers);//复制managers对象 m.values().removeAll(managers.keySet());//移除职位是上司(或上司的上司)的对象 Set<Employee> slackers = m.keySet();//剩下的就是一线员工了
为了加深对上面逻辑的了解,可以看一下一个简单的Demo:MapTest.java
public class MapTest {
public static void main(String[] args) {
Map<String, String> m1=new HashMap<String, String>();
Map<String, String> m2=new HashMap<String, String>();
m1.put("1", "1");
m1.put("2", "1");
m1.put("3", "2");
m2.put("3", "1");
m2.put("1", "1");
m2.put("4", "1");
m1.entrySet().removeAll(m2.entrySet());// A
// m1.keySet().removeAll(m2.keySet()); // B
// m1.values().removeAll(m2.keySet()); // C
// m1.values().removeAll(m2.keySet()); //D
System.out.println(m1);
}
}当中A输出:{3=2, 2=1}。注:此处“=”没有任何的意义,只是表示键值对的形式。
B输出:{2=1}
C输出:{3=2}
D输出:{3=2}
三种Collection视图方法,在实际应用的时候,只需要稍加推到可以得到多种灵活的变化。

相关文章推荐
- java nio的使用
- java 7 collection 详解(一)
- Java使用UDP协议收发数据简单实现
- java源程序加密解决方案(基于Classloader解密)
- java DES 加密解密 (二)
- java DES加密,解密 (一)
- Java MD5加密类
- java对比IO和NIO的文件读写性能测试
- 位运算
- java编程思想随笔(1)
- Arcgis for Java(一)在应用程序中添加地图
- Java阅读word程序说明文件
- Spring中如何配置Hibernate事务
- java volatile关键字
- 搭建SpringMVC开发环境
- JAVA生成EXCEL图表
- java 学习总结
- java反射机制详解 及 Method.invoke解释 getMethod
- Android:Eclipse 安装Genymotion插件的时候出现 There are no categorized items
- java使用jxl导出数据到xls文件