主席树初探
2015-07-27 18:25
435 查看
Twelves Monkeys
Time Limit: 5 Seconds
Memory Limit: 32768 KB
James Cole is a convicted criminal living beneath a post-apocalyptic Philadelphia. Many years ago, the Earth's surface had been contaminated by a virus so deadly that it forced the survivors to move underground. In the years that followed, scientists
had engineered an imprecise form of time travel. To earn a pardon, Cole allows scientists to send him on dangerous missions to the past to collect information on the virus, thought to have been released by a terrorist organization known as the Army
of the Twelve Monkeys.
The time travel is powerful so that sicentists can send Cole from year
x[i] back to year y[i]. Eventually, Cole finds that Goines is the founder of the Army of the Twelve Monkeys, and set out in search of him. When they find and confront him, however, Goines denies any involvement with the viruscan.
After that, Cole goes back and tells scientists what he knew. He wants to quit the mission to enjoy life. He wants to go back to the any year before current year, but scientists only allow him to use time travel once. In case of failure,
Cole will find at least one route for backup. Please help him to calculate how many years he can go with at least two routes.
The first line contains three integers n,m,q(1≤ n
≤ 50000, 1≤ m ≤ 50000, 1≤ q ≤ 50000), indicating the maximum year, the number of time travel path and the number of queries.
The following m lines contains two integers x,y(1≤ y
≤ x ≤ 50000) indicating Cole can travel from year
x to year y.
The following q lines contains one integers p(1≤ p
≤ n) indicating the year Cole is at now
Cole can go.
Author: GAN, Tiansheng
上面的是这个月的zoj月赛的一道题目,当时觉得很简单,可是那时候已经没时间了,所以就没敲。后来再去细细揣摩的时候,才发现不是随随便便就写出来的。
本来的思路是这样的,当前是p年,那么我要知道过去有几年我是可以通过两种及以上的总路径抵达的,那么就看p后面是不是有两个及以上能到p前面的时间穿梭点,然后取其中能达到的第二小的年份q,答案就是p-q。但是考虑到数据量比较大,这样是妥妥的会超时的。于是想,先输入所有的传送路径。然后预处理n年内所有的年份,然后输入p直接输出即可。本来以为就只是线段树,但是后来代码敲着敲着发现没那么简单。。。
然后就是闪亮亮主席树登场了。。。之前没搞过主席树,于是现在搜集了一些资料喵~
可持久化数据结构就是利用函数式编程的思想使其支持询问历史版本、同时充分利用它们之间的共同数据来减少时间和空间消耗。
而函数式线段树又称主席树。。(SBT)。。简称sb树或者super bt。。捂脸。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
可持续化数据结构:
原址:
http://www.cnblogs.com/tedzhao/archive/2008/11/12/1332112.html
下面这个部分比较便于理解概念:
with a null reference. To traverse a singly linked list, you begin at the head of the list and move from one node to the next until you have reached the node you are looking for or have reached the last node:
单向链表是一个在编程中使用非常广泛的基础数据结构,它是由一系列相互链接的节点组成。每一个节点都拥有一个指向下一个节点的引用,链表中的最后一个节点将拥有一个空引用。如果你想遍历一个单向链表,可以从第一个节点开始,逐个向后移动,直到到达最后的节点。
如下图所示:
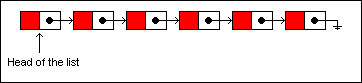
Let's insert a new item into the list. This list is not persistent, meaning that it can be changed in-place without generating a new version. After taking a look at the insertion operation on a non-persistent list, we'll look at the same operation on a persistent
list.
让我们插入一个新的节点到这个链表中去,并且该链表是非持久化的,也就是说这个链表可以被改变而无需产生一个新的版本。在查看了非持久化链表的插入操作之后,我们将会查看同样的操作在持久化链表中。
Inserting a new item into a singly linked list involves creating a new node:
插入一个新的节点到单向列表中会涉及到创建一个新的节点:
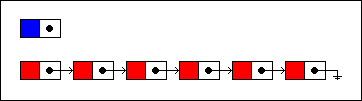
We will insert the new node at the fourth position in the list. First, we traverse the list until we've reached that position. Then the node that will precede the new node is unlinked from the next node...
我们将会在第四个位置插入新的节点,第一我们遍历链表到达指定位置,也就是插入节点前面的那个节点,将其与后面节点断开。
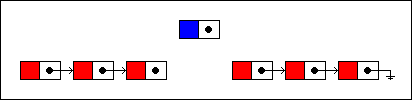
...and relinked to the new node. The new node is, in turn, linked to the remaining nodes in the list:
然后链接该节点与待插入节点,在下来,链接新的节点与上一步剩余的节点。

Inserting a new item into a persistent singly linked list will not alter the existing list but create a new version with the item inserted into it. Instead of copying the entire list and then inserting the item into the copy, a better strategy is to reuse
as much of the old list as possible. Since the nodes themselves are persistent, we don't have to worry about aliasing problems.
如果插入一个新的节点到持久化的单向链表中,我们不应该改变当前链表的状态,而需要创建一个新的链表而后插入指定节点。相对于拷贝当前链表,而后插入指定节点,一个更好的策略是尽可能的重用旧的链表。因为节点本身是可持久化的,所以我们不必担心对象混淆的问题。
To insert a new node at the fourth position, we traverse the list as before only copying each node along the way. Each copied node is linked to the next copied node:
为了插入新节点到第四个位置,我们遍历链表到指定位置,拷贝每个遍历节点,同时指定拷贝的节点指向其下一个节点的拷贝。
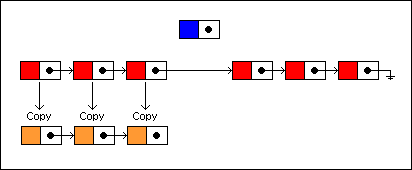
The last copied node is linked to the new node, and the new node is linked to the remaining nodes in the old list:
最后一个拷贝的节点指向新的插入节点,而后,新节点指向旧链表剩下的节点。
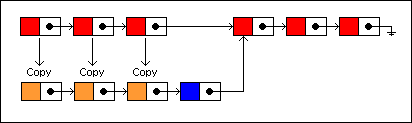
On an average, about N/2 nodes will be copied in the persistent version for insertions and deletions, where N equals the number of nodes in the list. This isn't terribly efficient but does give us some savings. One persistent data structure where this approach
to singly linked list buys us a lot is the stack. Imagine the above data structure with insertions and deletions restricted to the head of the list. In this case, N nodes can be reused for pushing items onto a stack and N - 1 nodes can be reused for popping
a stack.
平均来看,对于插入和删除操作,大约有N/2的节点将被拷贝,而N等于链表长度。这并不是特别的高效,仅仅只是节省了一些空间。与通过这样的方式来构建单向链表一样的一个数据结构是堆栈,我们可以想象一下在链表起始位置的插入以及删除操作,在这个场景中,对于堆栈来讲,压栈操作时全部节点都可以被重用,而出栈操作也有N-1个节点被重用。
然后便是二叉树
In the binary search tree version, each node usually stores a key/value pair. The tree is searched and ordered according to its keys. The key stored at a node is always greater than the keys stored in its left descendents and always less than the keys stored
in its right descendents. This makes searching for any particular key very fast.
一个二叉树是一系列节点的集合,每一个节点都包含有两个子节点,一个称之为左节点,而另一个称之为右节点。而子节点也是这样一个节点,也有一个左节点和一个右节点,当然也可以没有子节点,也就是说一个节点可能有零个或者两个子节点。在二叉查找树中,每一个节点通常包含了一个键值对,树结构将会依照节点的键来进行查找和组织。节点的键会永远大于其左节点的键,永远小于其右节点的键,这将使得对于特定键的查找非常迅速。
Here is an example of a binary search tree. The keys are listed as numbers; the values have been omitted but are assumed to exist. Notice how each key as you descend to the left is less than the key of its predecessor, and vice versa as you descend to the
right:
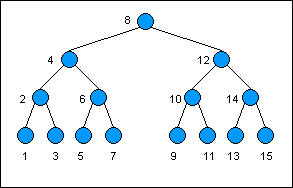
下图是一个二叉查找树的例子,节点的键作为数字被列出,而节点的值则被忽略尽管是始终存在的。注意到每一个左边节点的键值一定会小于它的父节点即前驱节点,而每一个右边节点的键值一定大于其父节点键值。
Changing the value of a particular node in a non-persistent tree involves starting at the root of the tree and searching for a particular key associated with that value, and then changing the value once the node has been found. Changing a persistent tree,
on the other hand, generates a new version of the tree. We will use the same strategy in implementing a persistent binary tree as we did for the persistent singly linked list, which is to reuse as much of the data structure as possible when making a new version.
如果在一个非持久化的树中更改一个特定节点的值,我们会从根节点按照特定键值开始搜索,如果找到则直接更改该节点的值。但是如果是在一个持久化的树上的话,换句话说,我们需要创建一个新版本的树,同时还需要保持同实现一个持久化的二叉树或者单向链表一样的策略,即尽可能的重用当前的数据来创建一个新的版本。
Let's change the value stored in the node with the key 7. As the search for the key leads us down the tree, we copy each node along the way. If we descend to the left, we point the previously copied node's left child to the currently copied node. The previous
node's right child continues to point to nodes in the older version. If we descend to the right, we do just the opposite.
下面让我们来尝试改变键为7的节点的值,按照自顶向下查找该节点的路径,我们需要拷贝该路径上的每一个节点。如果转向左边,需要将上一个拷贝的节点指向当前拷贝节点,而前一个节点的右侧节点则继续指向原来旧版本的节点。如果转向右边,则采用相反的做法。
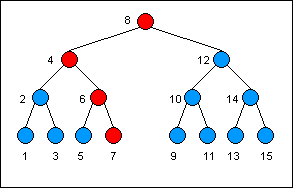
This illustrates the "spine" of the search down the tree. The red nodes are the only nodes that need to be copied in making a new version of the tree:
下图列出了在树上自顶向下搜索特定节点的路径,在构建新版本的树的时候仅仅需要拷贝那些红色的节点。
You can see that the majority of the nodes do not need to be copied. Assuming the binary tree is balanced, the number of nodes that need to be copied any time a write operation is performed is at most O(Log N), where Log is base 2. This is much more efficient
than the persistent singly linked list.
你能够发现大多数节点是不要拷贝的,假定二叉树是平衡的,在每一次节点值的写操作中需要拷贝的节点数目大约是O(LogN),对数的底为2。显然比起持久化的单向链表效率很高。
Insertions and deletions work the same way, only steps should be taken to keep the tree in balance, such as using an AVL tree. If a binary tree becomes degenerate, we run into the same efficiency problems as we did with the singly linked list.
插入以及删除操作将按照同样的方式进行,但是一些额外的保持树平衡的操作还是必须的,例如使用AVL树作为底层数据结构的时候。如果二叉树变得很不平衡,我们将会碰到同样的效率问题如同在持久化单向链表是一样。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
写代码是按着这位大大的代码来的,主要重点在理解,来一发源地址:
http://www.cnblogs.com/Empress/p/4678907.html
T数组便是tree,而L和R各自存这个点前面和后面出现的数的出现次数之和。(雾?)
然而没能彻底融会贯通,于是又去找资料。
这个是我找到的笔记,对我的理解有一定的帮助:
http://blog.csdn.net/xiaofengcanyuexj/article/details/25553521
查询
由于主席树每个节点是棵线段树,信息域、结构相同,可以相减。这是主席树查找的关键所在。例如查找第k小的元素,若左子树信息域data之差大于等于k,则直接到左子树查找;否则调整k值即减去左子树的信息域data之差,然后到相应的右子树查找。由于是线段树属于二叉树结构,故整个过程的时间复杂度为O(log(M)),M往往是原问题离散化后的数据数量级。对于任意主席树的节点即某棵线段树,其含义再次说明一下,存储的是原序列的某个前缀:a[1]、a[2]…a[k],其中k小于等于M,所以主席树节点i、j信息域data相减得到的即为原序列在区间[i,j]上的信息域data
。 此过程时间复杂度为O(log(M)),。
感觉自己还是有点陌生,等会儿回去好好研究下树这个专题。
2015年7月的zoj月赛题目Twelves Monkeys
通过这道题接触了主席树,深深意识到自己树方面实在薄弱,之后也要练习树方面的专题了。喵。
Time Limit: 5 Seconds
Memory Limit: 32768 KB
James Cole is a convicted criminal living beneath a post-apocalyptic Philadelphia. Many years ago, the Earth's surface had been contaminated by a virus so deadly that it forced the survivors to move underground. In the years that followed, scientists
had engineered an imprecise form of time travel. To earn a pardon, Cole allows scientists to send him on dangerous missions to the past to collect information on the virus, thought to have been released by a terrorist organization known as the Army
of the Twelve Monkeys.
The time travel is powerful so that sicentists can send Cole from year
x[i] back to year y[i]. Eventually, Cole finds that Goines is the founder of the Army of the Twelve Monkeys, and set out in search of him. When they find and confront him, however, Goines denies any involvement with the viruscan.
After that, Cole goes back and tells scientists what he knew. He wants to quit the mission to enjoy life. He wants to go back to the any year before current year, but scientists only allow him to use time travel once. In case of failure,
Cole will find at least one route for backup. Please help him to calculate how many years he can go with at least two routes.
Input
The input file contains multiple test cases.The first line contains three integers n,m,q(1≤ n
≤ 50000, 1≤ m ≤ 50000, 1≤ q ≤ 50000), indicating the maximum year, the number of time travel path and the number of queries.
The following m lines contains two integers x,y(1≤ y
≤ x ≤ 50000) indicating Cole can travel from year
x to year y.
The following q lines contains one integers p(1≤ p
≤ n) indicating the year Cole is at now
Output
For each test case, you should output one line, contain a number which is the total number of the yearCole can go.
Sample Input
9 3 3 9 1 6 1 4 1 6 7 2
Sample Output
5 0 1
Hint
6 can go back to 1 for two route. One is 6-1, the other is 6-7-8-9-1.6 can go back to 2 for two route. One is 6-1-2, the other is 6-7-8-9-1-2.Author: GAN, Tiansheng
上面的是这个月的zoj月赛的一道题目,当时觉得很简单,可是那时候已经没时间了,所以就没敲。后来再去细细揣摩的时候,才发现不是随随便便就写出来的。
本来的思路是这样的,当前是p年,那么我要知道过去有几年我是可以通过两种及以上的总路径抵达的,那么就看p后面是不是有两个及以上能到p前面的时间穿梭点,然后取其中能达到的第二小的年份q,答案就是p-q。但是考虑到数据量比较大,这样是妥妥的会超时的。于是想,先输入所有的传送路径。然后预处理n年内所有的年份,然后输入p直接输出即可。本来以为就只是线段树,但是后来代码敲着敲着发现没那么简单。。。
然后就是闪亮亮主席树登场了。。。之前没搞过主席树,于是现在搜集了一些资料喵~
可持久化数据结构就是利用函数式编程的思想使其支持询问历史版本、同时充分利用它们之间的共同数据来减少时间和空间消耗。
而函数式线段树又称主席树。。(SBT)。。简称sb树或者super bt。。捂脸。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
可持续化数据结构:
原址:
http://www.cnblogs.com/tedzhao/archive/2008/11/12/1332112.html
下面这个部分比较便于理解概念:
Persistent Singly Linked Lists
持久化的单向链表
The singly linked list is one of the most widely used data structures in programming. It consists of a series of nodes linked together one right after the other. Each node has a reference to the node that comes after it, and the last node in the list terminateswith a null reference. To traverse a singly linked list, you begin at the head of the list and move from one node to the next until you have reached the node you are looking for or have reached the last node:
单向链表是一个在编程中使用非常广泛的基础数据结构,它是由一系列相互链接的节点组成。每一个节点都拥有一个指向下一个节点的引用,链表中的最后一个节点将拥有一个空引用。如果你想遍历一个单向链表,可以从第一个节点开始,逐个向后移动,直到到达最后的节点。
如下图所示:
Let's insert a new item into the list. This list is not persistent, meaning that it can be changed in-place without generating a new version. After taking a look at the insertion operation on a non-persistent list, we'll look at the same operation on a persistent
list.
让我们插入一个新的节点到这个链表中去,并且该链表是非持久化的,也就是说这个链表可以被改变而无需产生一个新的版本。在查看了非持久化链表的插入操作之后,我们将会查看同样的操作在持久化链表中。
Inserting a new item into a singly linked list involves creating a new node:
插入一个新的节点到单向列表中会涉及到创建一个新的节点:
We will insert the new node at the fourth position in the list. First, we traverse the list until we've reached that position. Then the node that will precede the new node is unlinked from the next node...
我们将会在第四个位置插入新的节点,第一我们遍历链表到达指定位置,也就是插入节点前面的那个节点,将其与后面节点断开。
...and relinked to the new node. The new node is, in turn, linked to the remaining nodes in the list:
然后链接该节点与待插入节点,在下来,链接新的节点与上一步剩余的节点。
Inserting a new item into a persistent singly linked list will not alter the existing list but create a new version with the item inserted into it. Instead of copying the entire list and then inserting the item into the copy, a better strategy is to reuse
as much of the old list as possible. Since the nodes themselves are persistent, we don't have to worry about aliasing problems.
如果插入一个新的节点到持久化的单向链表中,我们不应该改变当前链表的状态,而需要创建一个新的链表而后插入指定节点。相对于拷贝当前链表,而后插入指定节点,一个更好的策略是尽可能的重用旧的链表。因为节点本身是可持久化的,所以我们不必担心对象混淆的问题。
To insert a new node at the fourth position, we traverse the list as before only copying each node along the way. Each copied node is linked to the next copied node:
为了插入新节点到第四个位置,我们遍历链表到指定位置,拷贝每个遍历节点,同时指定拷贝的节点指向其下一个节点的拷贝。
The last copied node is linked to the new node, and the new node is linked to the remaining nodes in the old list:
最后一个拷贝的节点指向新的插入节点,而后,新节点指向旧链表剩下的节点。
On an average, about N/2 nodes will be copied in the persistent version for insertions and deletions, where N equals the number of nodes in the list. This isn't terribly efficient but does give us some savings. One persistent data structure where this approach
to singly linked list buys us a lot is the stack. Imagine the above data structure with insertions and deletions restricted to the head of the list. In this case, N nodes can be reused for pushing items onto a stack and N - 1 nodes can be reused for popping
a stack.
平均来看,对于插入和删除操作,大约有N/2的节点将被拷贝,而N等于链表长度。这并不是特别的高效,仅仅只是节省了一些空间。与通过这样的方式来构建单向链表一样的一个数据结构是堆栈,我们可以想象一下在链表起始位置的插入以及删除操作,在这个场景中,对于堆栈来讲,压栈操作时全部节点都可以被重用,而出栈操作也有N-1个节点被重用。
然后便是二叉树
Persistent Binary Trees
持久化二叉树
A binary tree is a collection of nodes in which each node contains two links, one to its left child and another to its right child. Each child is itself a node, and either or both of the child nodes can be null, meaning that a node may have zero to two children.In the binary search tree version, each node usually stores a key/value pair. The tree is searched and ordered according to its keys. The key stored at a node is always greater than the keys stored in its left descendents and always less than the keys stored
in its right descendents. This makes searching for any particular key very fast.
一个二叉树是一系列节点的集合,每一个节点都包含有两个子节点,一个称之为左节点,而另一个称之为右节点。而子节点也是这样一个节点,也有一个左节点和一个右节点,当然也可以没有子节点,也就是说一个节点可能有零个或者两个子节点。在二叉查找树中,每一个节点通常包含了一个键值对,树结构将会依照节点的键来进行查找和组织。节点的键会永远大于其左节点的键,永远小于其右节点的键,这将使得对于特定键的查找非常迅速。
Here is an example of a binary search tree. The keys are listed as numbers; the values have been omitted but are assumed to exist. Notice how each key as you descend to the left is less than the key of its predecessor, and vice versa as you descend to the
right:
下图是一个二叉查找树的例子,节点的键作为数字被列出,而节点的值则被忽略尽管是始终存在的。注意到每一个左边节点的键值一定会小于它的父节点即前驱节点,而每一个右边节点的键值一定大于其父节点键值。
Changing the value of a particular node in a non-persistent tree involves starting at the root of the tree and searching for a particular key associated with that value, and then changing the value once the node has been found. Changing a persistent tree,
on the other hand, generates a new version of the tree. We will use the same strategy in implementing a persistent binary tree as we did for the persistent singly linked list, which is to reuse as much of the data structure as possible when making a new version.
如果在一个非持久化的树中更改一个特定节点的值,我们会从根节点按照特定键值开始搜索,如果找到则直接更改该节点的值。但是如果是在一个持久化的树上的话,换句话说,我们需要创建一个新版本的树,同时还需要保持同实现一个持久化的二叉树或者单向链表一样的策略,即尽可能的重用当前的数据来创建一个新的版本。
Let's change the value stored in the node with the key 7. As the search for the key leads us down the tree, we copy each node along the way. If we descend to the left, we point the previously copied node's left child to the currently copied node. The previous
node's right child continues to point to nodes in the older version. If we descend to the right, we do just the opposite.
下面让我们来尝试改变键为7的节点的值,按照自顶向下查找该节点的路径,我们需要拷贝该路径上的每一个节点。如果转向左边,需要将上一个拷贝的节点指向当前拷贝节点,而前一个节点的右侧节点则继续指向原来旧版本的节点。如果转向右边,则采用相反的做法。
This illustrates the "spine" of the search down the tree. The red nodes are the only nodes that need to be copied in making a new version of the tree:
下图列出了在树上自顶向下搜索特定节点的路径,在构建新版本的树的时候仅仅需要拷贝那些红色的节点。
You can see that the majority of the nodes do not need to be copied. Assuming the binary tree is balanced, the number of nodes that need to be copied any time a write operation is performed is at most O(Log N), where Log is base 2. This is much more efficient
than the persistent singly linked list.
你能够发现大多数节点是不要拷贝的,假定二叉树是平衡的,在每一次节点值的写操作中需要拷贝的节点数目大约是O(LogN),对数的底为2。显然比起持久化的单向链表效率很高。
Insertions and deletions work the same way, only steps should be taken to keep the tree in balance, such as using an AVL tree. If a binary tree becomes degenerate, we run into the same efficiency problems as we did with the singly linked list.
插入以及删除操作将按照同样的方式进行,但是一些额外的保持树平衡的操作还是必须的,例如使用AVL树作为底层数据结构的时候。如果二叉树变得很不平衡,我们将会碰到同样的效率问题如同在持久化单向链表是一样。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
写代码是按着这位大大的代码来的,主要重点在理解,来一发源地址:
http://www.cnblogs.com/Empress/p/4678907.html
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
typedef pair<int, int> PI;
#define lson l, m
#define rson m+1, r
const int N=50005;
int L[N<<5], R[N<<5], sum[N<<5];
int tot;
int T
, Hash
;
int build(int l, int r)
{
int rt=(++tot);
sum[rt]=0;
if(l<r)
{
int m=(l+r)>>1;
L[rt]=build(lson);
R[rt]=build(rson);
}
return rt;
}
int update(int pre, int l, int r, int x)
{
int rt=(++tot);
L[rt]=L[pre], R[rt]=R[pre], sum[rt]=sum[pre]+1;
if(l<r)
{
int m=(l+r)>>1;
if(x<=m)
L[rt]=update(L[pre], lson, x);
else
R[rt]=update(R[pre], rson, x);
}
return rt;
}
int query(int u, int v, int l, int r, int k)
{
if(l>=r)
return l;
int m=(l+r)>>1;
int num=sum[L[v]]-sum[L[u]];
if(num>=k)
return query(L[u], L[v], lson, k);
else
return query(R[u], R[v], rson, k-num);
}
PI a
;
int main()
{
int n, m, q;
while(~scanf("%d%d%d", &n, &m, &q))
{
tot=0;
for(int i=1; i<=m; i++)
{
int x, y;
scanf("%d%d", &x, &y);
a[i]=make_pair(x, y);
}
sort(a+1, a+1+m);
for(int i=1;i<=m;i++)
Hash[i]=a[i].second;
int d=unique(Hash+1, Hash+1+m)-Hash;
T[0]=build(1, d);
for(int i=1; i<=m; i++)
{
int x=lower_bound(Hash+1, Hash+1+m, a[i].second)-Hash;
T[i]=update(T[i-1], 1, d, x);
}
while(q--)
{
int k;
scanf("%d", &k);
int p=lower_bound(a+1, a+1+m, make_pair(k, 0))-a;
if(m-p<1)
{
puts("0");
continue;
}
int x=query(T[p-1], T[m], 1, d, 2);
int ans=k-Hash[x];
if(ans<=0)
puts("0");
else
printf("%d\n", ans);
}
}
return 0;
}
/*
9 3 9
9 7
8 5
6 3
1 2 3 4 5 6 7 8 9
*/
ZOJ 3888自己按着上面的代码一句句看着实现了,前面的sum[i]的意思是前i个数一共出现的次数之和,那么根据sum[i]和i就可以判断是不是有出现了不止一次的数了,因为我们要的是能够两种及以上的方式到达的年份数目。T数组便是tree,而L和R各自存这个点前面和后面出现的数的出现次数之和。(雾?)
然而没能彻底融会贯通,于是又去找资料。
这个是我找到的笔记,对我的理解有一定的帮助:
http://blog.csdn.net/xiaofengcanyuexj/article/details/25553521
查询
由于主席树每个节点是棵线段树,信息域、结构相同,可以相减。这是主席树查找的关键所在。例如查找第k小的元素,若左子树信息域data之差大于等于k,则直接到左子树查找;否则调整k值即减去左子树的信息域data之差,然后到相应的右子树查找。由于是线段树属于二叉树结构,故整个过程的时间复杂度为O(log(M)),M往往是原问题离散化后的数据数量级。对于任意主席树的节点即某棵线段树,其含义再次说明一下,存储的是原序列的某个前缀:a[1]、a[2]…a[k],其中k小于等于M,所以主席树节点i、j信息域data相减得到的即为原序列在区间[i,j]上的信息域data
。 此过程时间复杂度为O(log(M)),。
感觉自己还是有点陌生,等会儿回去好好研究下树这个专题。
2015年7月的zoj月赛题目Twelves Monkeys
通过这道题接触了主席树,深深意识到自己树方面实在薄弱,之后也要练习树方面的专题了。喵。

相关文章推荐
- 使用C++实现JNI接口需要注意的事项
- 关于指针的一些事情
- c++ primer 第五版 笔记前言
- share_ptr的几个注意点
- Lua中调用C++函数示例
- Lua教程(一):在C++中嵌入Lua脚本
- Lua教程(二):C++和Lua相互传递数据示例
- C++联合体转换成C#结构的实现方法
- C++编写简单的打靶游戏
- C++ 自定义控件的移植问题
- C++变位词问题分析
- C/C++数据对齐详细解析
- C++基于栈实现铁轨问题
- C++中引用的使用总结
- 使用Lua来扩展C++程序的方法
- C++中调用Lua函数实例
- Lua和C++的通信流程代码实例
- C与C++之间相互调用实例方法讲解
- C++ Custom Control控件向父窗体发送对应的消息
- C++中拷贝构造函数的应用详解