Mongodb千万级数据在python下的综合压力测试及应用探讨
2015-07-24 11:18
716 查看
曾经在收集数据的项目中,用过mongodb的数据存储,但是当数据很大的时候,还是比较的吃力。很可能当时的应用水平不高,也可以是当时的服务器不是很强。 所以这次能力比以前高点了,然后服务器比以前也高端了很多,好嘞 ~再测试下。
(更多的是单机测试,没有用复制分片的测试 ~)!
相比较MySQL,MongoDB数据库更适合那些读作业较重的任务模型。MongoDB能充分利用机器的内存资源。如果机器的内存资源丰富的话,MongoDB的查询效率会快很多。
这次测试的服务器是dell 的 r510!
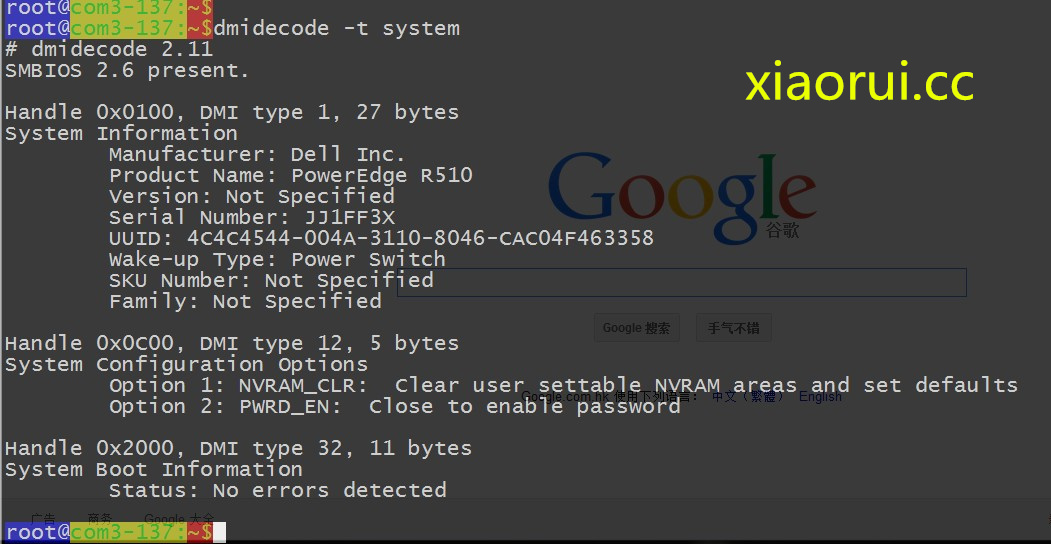
内存还行,是48G的,本来想让同事给加满,但是最终还是没有说出口 ~
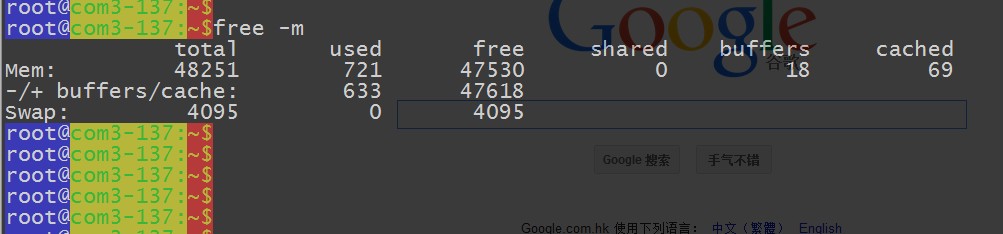
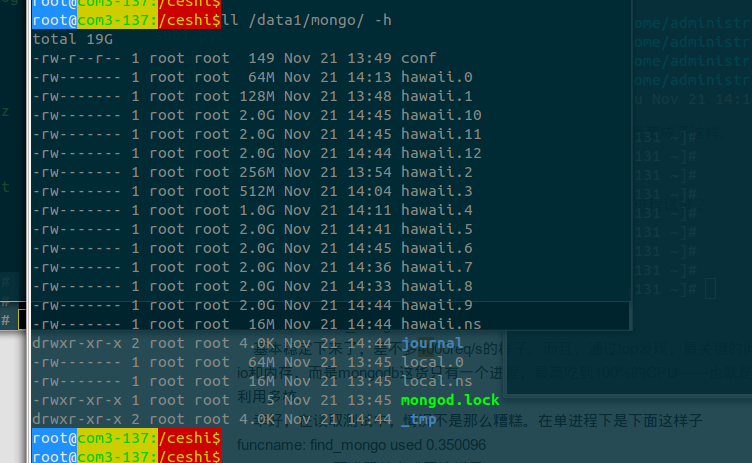
磁盘是10个2T的,但是因为格式化的时间太久了,哥们直接把其他的硬盘给拔出来了,就用了三个盘。。。data目录没有做raid,是为了让他们体现更好的硬盘速度。
既然说好了是在python下的应用测试,那就需要安装mongodb python下的模块 !
对了,不知道mongodb-server的安装要不要说下?
Pymongo的基本用法
测试的代码:
咱们就先来个百万的数据做做测试~
综合点的数据:
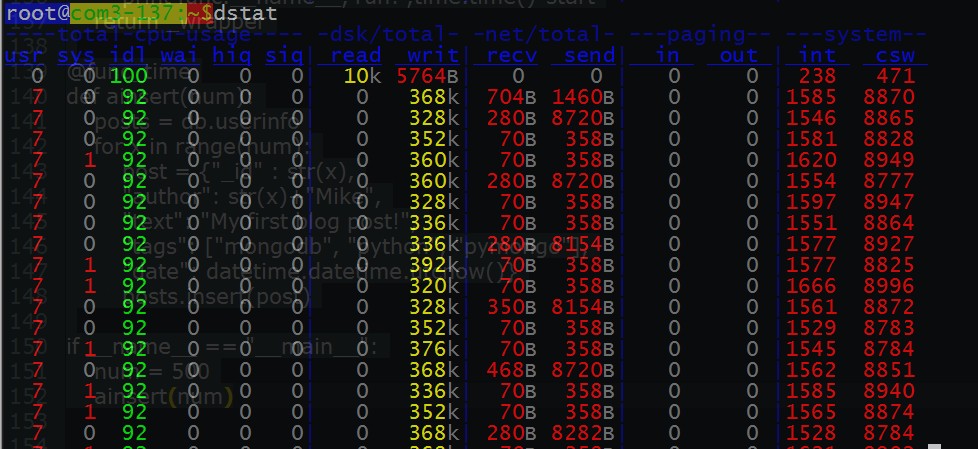
在top下看到的程序占用资源的情况 ~ 我们看到的是有两个进程的很突出,对头 ! 正是mongodb的服务和我们正在跑的python脚本 !
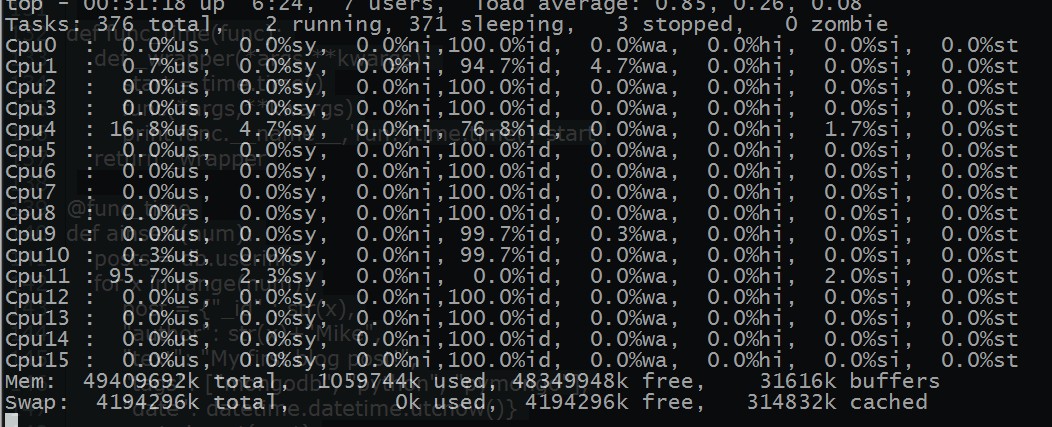
看下服务的io的情况 ~
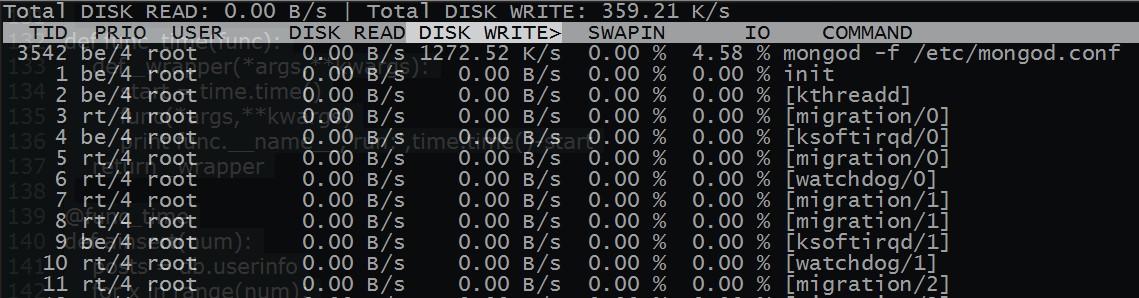
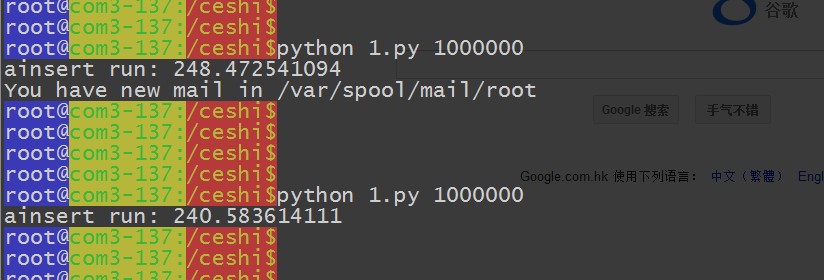
脚本运行完毕,总结下运行的时间 ~

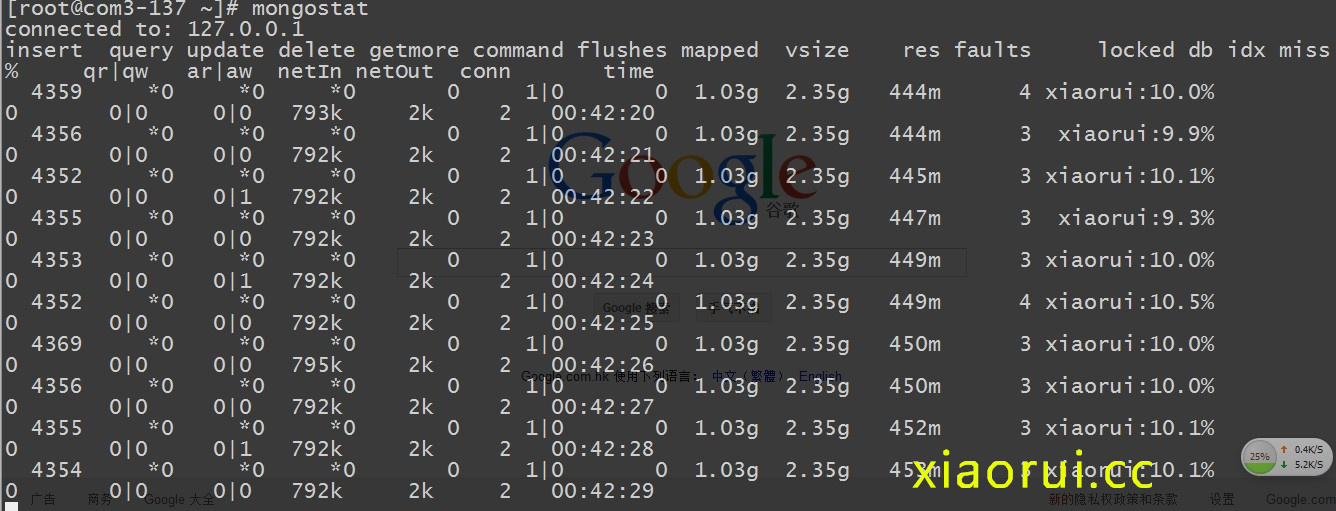
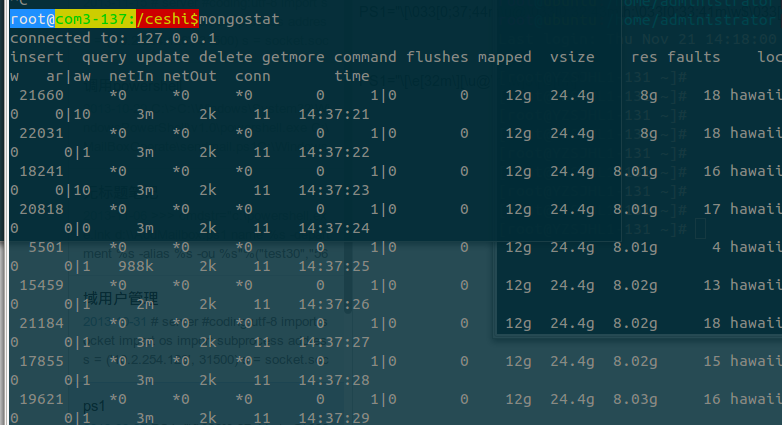
查看mongodb的状态~
他的insert也不到5k ~ 插入量也就800k左右 ~
它的输出有以下几列:
inserts/s 每秒插入次数
query/s 每秒查询次数
update/s 每秒更新次数
delete/s 每秒删除次数
getmore/s 每秒执行getmore次数
command/s 每秒的命令数,比以上插入、查找、更新、删除的综合还多,还统计了别的命令
flushs/s 每秒执行fsync将数据写入硬盘的次数。
mapped/s 所有的被mmap的数据量,单位是MB,
vsize 虚拟内存使用量,单位MB
res 物理内存使用量,单位MB
faults/s 每秒访问失败数(只有Linux有),数据被交换出物理内存,放到swap。不要超过100,否则就是机器内存太小,造成频繁swap写入。此时要升级内存或者扩展
locked % 被锁的时间百分比,尽量控制在50%以下吧
idx miss % 索引不命中所占百分比。如果太高的话就要考虑索引是不是少了
q t|r|w 当Mongodb接收到太多的命令而数据库被锁住无法执行完成,它会将命令加入队列。这一栏显示了总共、读、写3个队列的长度,都为0的话表示mongo毫无压力。高并发时,一般队列值会升高。
conn 当前连接数
time 时间戳
瞅下面的监控数据 !
然后我们在测试下在一千万的数据下的消耗时间情况 ~
共用了2294秒,每秒插入 4359个数据 ~
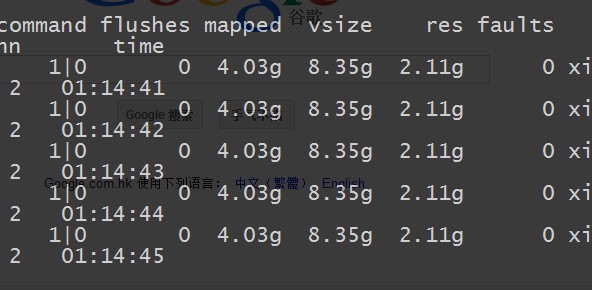
看看他的内存的使用情况:
虚拟内存在8gb左右,真实内存在2gb左右
再换成多线程的模式跑跑 ~ 个人不太喜欢用多线程,这东西属于管你忙不忙,老大说了要公平,我就算抢到了,但是没事干,我也不让给你。。。属于那种蛮干的机制 ~
nima,要比单个跑的慢呀 ~ 线程这东西咋会这么不靠谱呀 ~
应该是没有做线程池pool,拉取队列。导致线程过多导致的。不然不可能比单进程都要慢~
还有就是像这些涉及到IO的东西,交给协程的事件框架更加合理点 !!!
python毕竟有gil的限制,虽然multiprocess号称可以解决多进程的。但是用过的朋友知道,这个东西更不靠谱 ~ 属于坑人的东西 ~
要是有朋友怀疑是python的单进程的性能问题,那咱们就用supervisord跑了几个后台的python压力脚本
~ supervisord的配置我就不说了,我以前的文章里面有详述的 ~
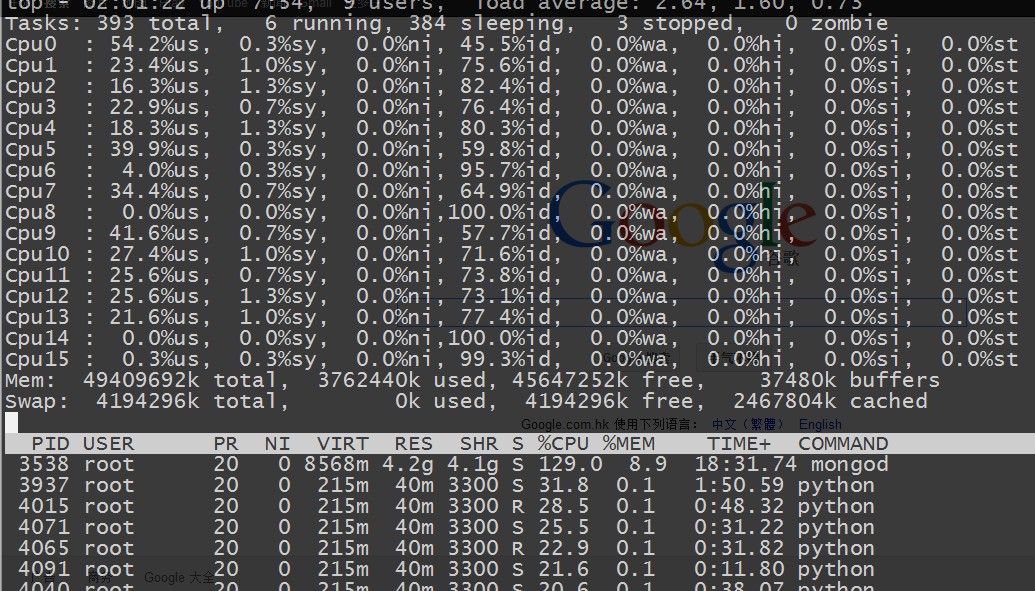
cpu方面是跑的有点均匀了,但是mongodb那边的压力总是上不去
当加大到16个后台进程做压力测试的时候 ~ 大家会发现insert很不稳定。 看来他的极限也就是2MB左右的数据 ~
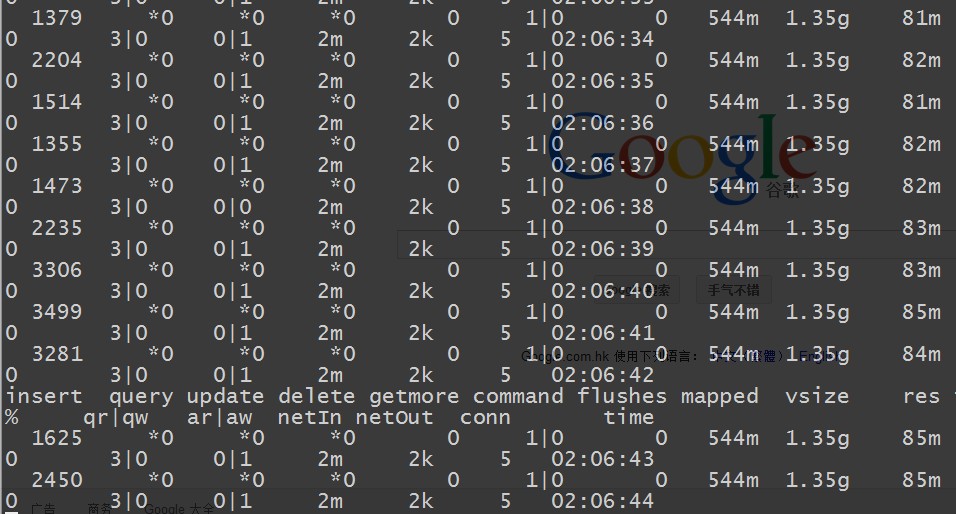
当减少到8个压力进程的时候 ~ 我们发现他的insert慢慢的提供到正常了,也就是说 他真的是2MB的极限 ~
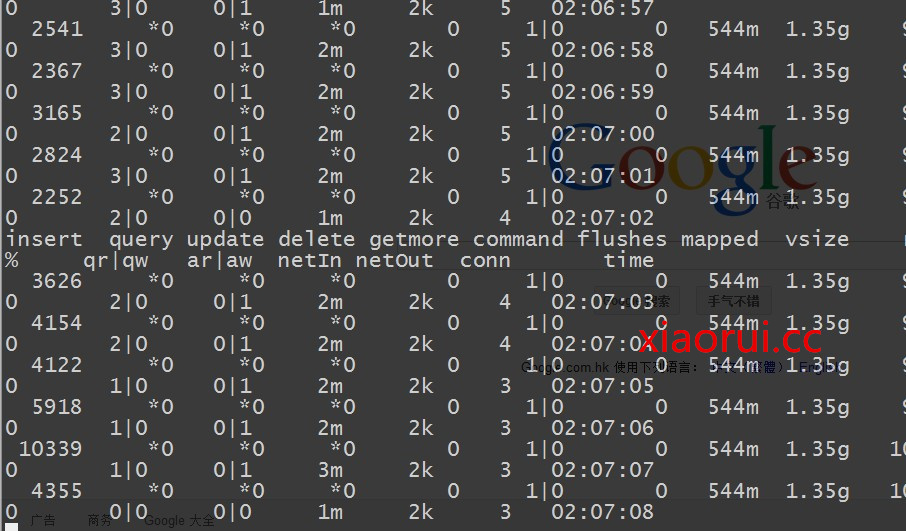
脚本里面是有做有序的id插入的,我们试试把id的插入给去掉,看看有没有提升~
结果和不插入id差不多的结果 ~
调优之后~ 再度测试
ulimit的优化
内核的tcp优化
启动的时候,加上多核的优化参数
insert的频率已经到了2w左右 ~ 内存占用了8G左右 ~
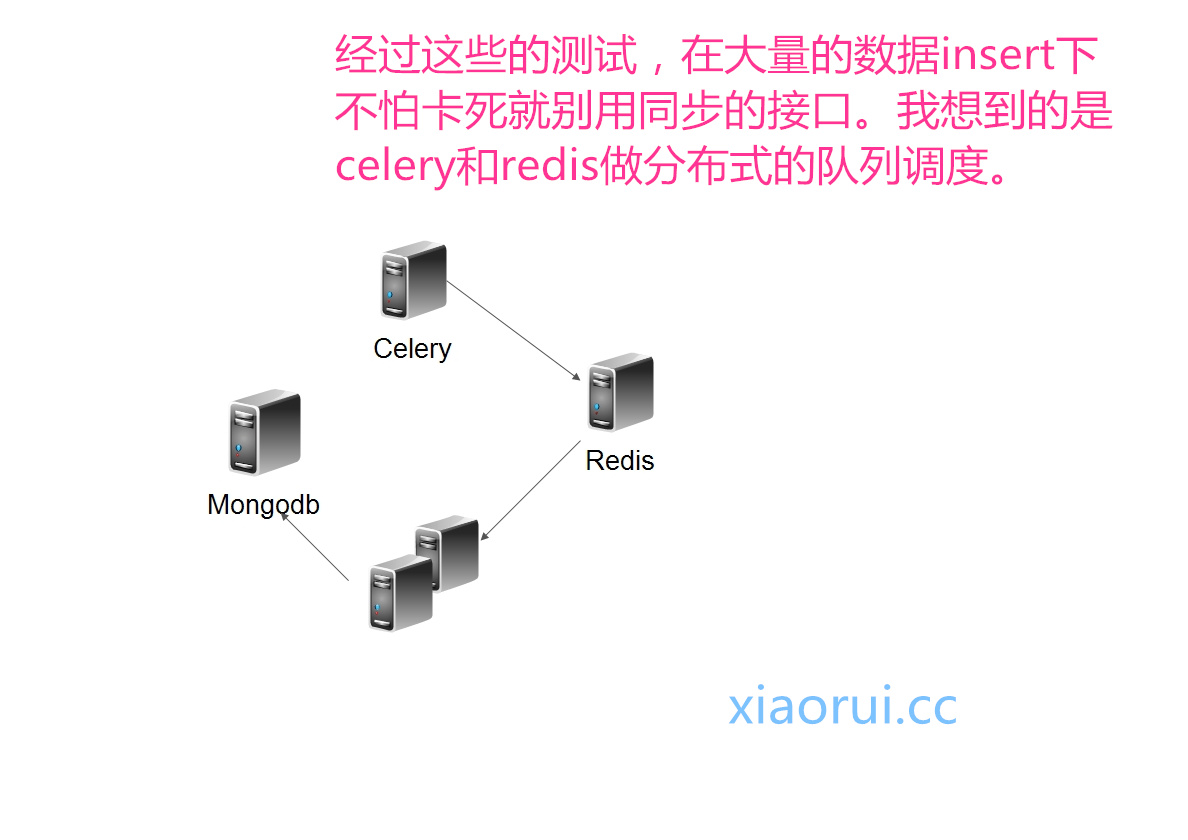
我想到的一个方案:
当然不用非要celery,就算咱们用socket写分发,和zeromq的pub sub也可以实现这些的。这是celery的调度更加专业点。
刚才我们测试的都是insert,现在我们再来测试下在千万级别数据量下的查询如何:
查询正则的,以2开头的字符
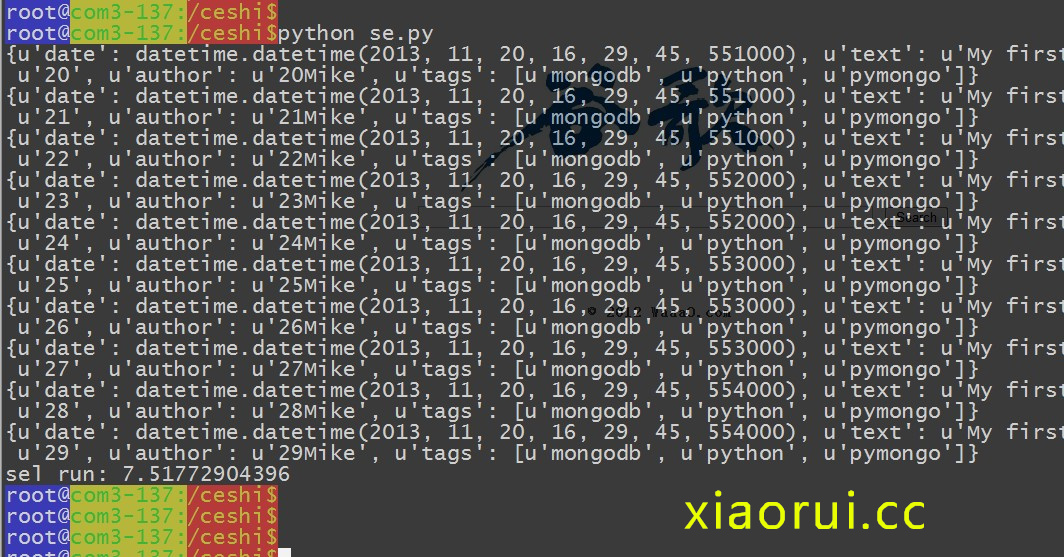
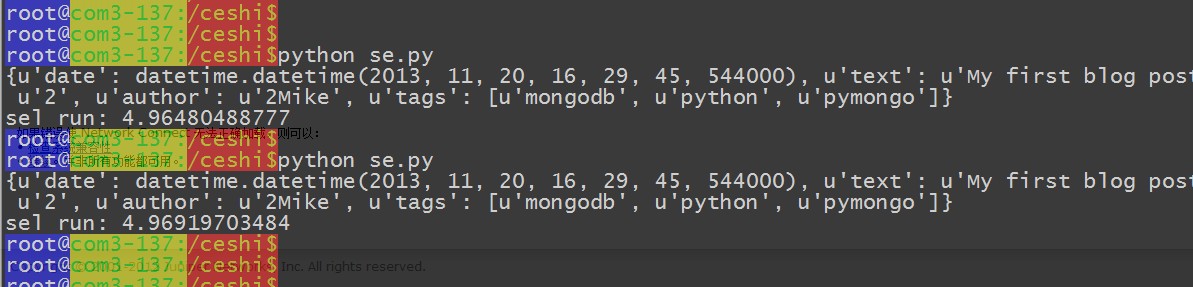
精确的查询:
查询在5s左右 ~
总结:
典型的高读低写数据库 !
有时间加索引再度测试下 !
(更多的是单机测试,没有用复制分片的测试 ~)!
相比较MySQL,MongoDB数据库更适合那些读作业较重的任务模型。MongoDB能充分利用机器的内存资源。如果机器的内存资源丰富的话,MongoDB的查询效率会快很多。
这次测试的服务器是dell 的 r510!
内存还行,是48G的,本来想让同事给加满,但是最终还是没有说出口 ~
磁盘是10个2T的,但是因为格式化的时间太久了,哥们直接把其他的硬盘给拔出来了,就用了三个盘。。。data目录没有做raid,是为了让他们体现更好的硬盘速度。
既然说好了是在python下的应用测试,那就需要安装mongodb python下的模块 !
对了,不知道mongodb-server的安装要不要说下?
Pymongo的基本用法
综合点的数据:
在top下看到的程序占用资源的情况 ~ 我们看到的是有两个进程的很突出,对头 ! 正是mongodb的服务和我们正在跑的python脚本 !
看下服务的io的情况 ~
脚本运行完毕,总结下运行的时间 ~
查看mongodb的状态~
他的insert也不到5k ~ 插入量也就800k左右 ~
它的输出有以下几列:
inserts/s 每秒插入次数
query/s 每秒查询次数
update/s 每秒更新次数
delete/s 每秒删除次数
getmore/s 每秒执行getmore次数
command/s 每秒的命令数,比以上插入、查找、更新、删除的综合还多,还统计了别的命令
flushs/s 每秒执行fsync将数据写入硬盘的次数。
mapped/s 所有的被mmap的数据量,单位是MB,
vsize 虚拟内存使用量,单位MB
res 物理内存使用量,单位MB
faults/s 每秒访问失败数(只有Linux有),数据被交换出物理内存,放到swap。不要超过100,否则就是机器内存太小,造成频繁swap写入。此时要升级内存或者扩展
locked % 被锁的时间百分比,尽量控制在50%以下吧
idx miss % 索引不命中所占百分比。如果太高的话就要考虑索引是不是少了
q t|r|w 当Mongodb接收到太多的命令而数据库被锁住无法执行完成,它会将命令加入队列。这一栏显示了总共、读、写3个队列的长度,都为0的话表示mongo毫无压力。高并发时,一般队列值会升高。
conn 当前连接数
time 时间戳
瞅下面的监控数据 !
然后我们在测试下在一千万的数据下的消耗时间情况 ~
共用了2294秒,每秒插入 4359个数据 ~
看看他的内存的使用情况:
虚拟内存在8gb左右,真实内存在2gb左右
再换成多线程的模式跑跑 ~ 个人不太喜欢用多线程,这东西属于管你忙不忙,老大说了要公平,我就算抢到了,但是没事干,我也不让给你。。。属于那种蛮干的机制 ~
nima,要比单个跑的慢呀 ~ 线程这东西咋会这么不靠谱呀 ~
应该是没有做线程池pool,拉取队列。导致线程过多导致的。不然不可能比单进程都要慢~
还有就是像这些涉及到IO的东西,交给协程的事件框架更加合理点 !!!
python毕竟有gil的限制,虽然multiprocess号称可以解决多进程的。但是用过的朋友知道,这个东西更不靠谱 ~ 属于坑人的东西 ~
要是有朋友怀疑是python的单进程的性能问题,那咱们就用supervisord跑了几个后台的python压力脚本
~ supervisord的配置我就不说了,我以前的文章里面有详述的 ~
cpu方面是跑的有点均匀了,但是mongodb那边的压力总是上不去
当加大到16个后台进程做压力测试的时候 ~ 大家会发现insert很不稳定。 看来他的极限也就是2MB左右的数据 ~
当减少到8个压力进程的时候 ~ 我们发现他的insert慢慢的提供到正常了,也就是说 他真的是2MB的极限 ~
脚本里面是有做有序的id插入的,我们试试把id的插入给去掉,看看有没有提升~
结果和不插入id差不多的结果 ~
调优之后~ 再度测试
ulimit的优化
我想到的一个方案:
当然不用非要celery,就算咱们用socket写分发,和zeromq的pub sub也可以实现这些的。这是celery的调度更加专业点。
刚才我们测试的都是insert,现在我们再来测试下在千万级别数据量下的查询如何:
查询正则的,以2开头的字符
精确的查询:
查询在5s左右 ~
总结:
典型的高读低写数据库 !
有时间加索引再度测试下 !

相关文章推荐
- mongodb索引
- 深入副本集内部机制----个人记录
- mongodb的复制集配置
- mongodb java操作
- mongodb 增删改查
- 搭建简单的 mongodb
- MongoDB 的使用
- MongoDB  安全
- 搭建高可用的MongoDB集群(上):MongoDB的配置与副本集----- 个人记录
- MAC系统下phpstorm不能基于MAXP使用MongoDB的结局办法
- mongodb安装与使用
- 【mongodb系统学习之十】mongodb查询(二)
- 【mongodb系统学习之十】mongodb查询(一)
- spring mongodb 模糊查询
- 【mongodb系统学习之九】mongodb保存数据
- 【mongodb系统学习之八】mongodb shell常用操作
- Mongodb的安装和使用
- Windows下MongoDB安装和配置
- PHP操作MongoDB学习笔记
- MongoDB入门篇--增删改查