深入浅出 Java Concurrency (20): 并发容器 part 5 ConcurrentLinkedQueue
2015-07-20 18:31
686 查看
ConcurrentLinkedQueue是Queue的一个线程安全实现。先来看一段文档说明。
一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序。队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。此队列不允许使用 null 元素。
由于ConcurrentLinkedQueue只是简单的实现了一个队列Queue,因此从API的角度讲,没有多少值的介绍,使用起来也很简单,和前面遇到的所有FIFO队列都类似。出队列只能操作头节点,入队列只能操作尾节点,任意节点操作就需要遍历完整的队列。
重点放在解释ConcurrentLinkedQueue的原理和实现上。
在继续探讨之前,结合前面线程安全的相关知识,我来分析设计一个线程安全的队列哪几种方法。
第一种:使用synchronized同步队列,就像Vector或者Collections.synchronizedList/Collection那样。显然这不是一个好的并发队列,这会导致吞吐量急剧下降。
第二种:使用Lock。一种好的实现方式是使用ReentrantReadWriteLock来代替ReentrantLock提高读取的吞吐量。但是显然ReentrantReadWriteLock的实现更为复杂,而且更容易导致出现问题,另外也不是一种通用的实现方式,因为ReentrantReadWriteLock适合哪种读取量远远大于写入量的场合。当然了ReentrantLock是一种很好的实现,结合Condition能够很方便的实现阻塞功能,这在后面介绍BlockingQueue的时候会具体分析。
第三种:使用CAS操作。尽管Lock的实现也用到了CAS操作,但是毕竟是间接操作,而且会导致线程挂起。一个好的并发队列就是采用某种非阻塞算法来取得最大的吞吐量。
ConcurrentLinkedQueue采用的就是第三种策略。它采用了参考资料1 中的算法。
在锁机制中谈到过,要使用非阻塞算法来完成队列操作,那么就需要一种“循环尝试”的动作,就是循环操作队列,直到成功为止,失败就会再次尝试。这在前面的章节中多次介绍过。
针对各种功能深入分析。
在开始之前先介绍下ConcurrentLinkedQueue的数据结构。

在上面的数据结构中,ConcurrentLinkedQueue只有头结点、尾节点两个元素,而对于一个节点Node而言除了保存队列元素item外,还有一个指向下一个节点的引用next。
看起来整个数据结构还是比较简单的。但是也有几点是需要说明:
所有结构(head/tail/item/next)都是volatile类型。 这是因为ConcurrentLinkedQueue是非阻塞的,所以只有volatile才能使变量的写操作对后续读操作是可见的(这个是有happens-before法则保证的)。同样也不会导致指令的重排序。
所有结构的操作都带有原子操作,这是由AtomicReferenceFieldUpdater保证的,这在原子操作中介绍过。它能保证需要的时候对变量的修改操作是原子的。
由于队列中任何一个节点(Node)只有下一个节点的引用,所以这个队列是单向的,根据FIFO特性,也就是说出队列在头部(head),入队列在尾部(tail)。头部保存有进入队列最长时间的元素,尾部是最近进入的元素。
没有对队列长度进行计数,所以队列的长度是无限的,同时获取队列的长度的时间不是固定的,这需要遍历整个队列,并且这个计数也可能是不精确的。
初始情况下队列头和队列尾都指向一个空节点,但是非null,这是为了方便操作,不需要每次去判断head/tail是否为空。但是head却不作为存取元素的节点,tail在不等于head情况下保存一个节点元素。也就是说head.item这个应该一直是空,但是tail.item却不一定是空(如果head!=tail,那么tail.item!=null)。
对于第5点,可以从ConcurrentLinkedQueue的初始化中看到。这种头结点也叫“伪节点”,也就是说它不是真正的节点,只是一标识,就像c中的字符数组后面的\0以后,只是用来标识结束,并不是真正字符数组的一部分。
private transient volatile Node<E> head = new Node<E>(null, null);
private transient volatile Node<E> tail = head;
有了上述5点再来解释相关API操作就容易多了。
在上一节中列出了add/offer/remove/poll/element/peek等价方法的区别,所以这里就不再重复了。
清单1 入队列操作
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
Node<E> n = new Node<E>(e, null);
for (;;) {
Node<E> t = tail;
Node<E> s = t.getNext();
if (t == tail) {
if (s == null) {
if (t.casNext(s, n)) {
casTail(t, n);
return true;
}
} else {
casTail(t, s);
}
}
}
}
清单1 描述的是入队列的过程。整个过程是这样的。
获取尾节点t,以及尾节点的下一个节点s。如果尾节点没有被别人修改,也就是t==tail,进行2,否则进行1。
如果s不为空,也就是说此时尾节点后面还有元素,那么就需要把尾节点往后移,进行1。否则进行3。
修改尾节点的下一个节点为新节点,如果成功就修改尾节点,返回true。否则进行1。
从操作3中可以看到是先修改尾节点的下一个节点,然后才修改尾节点位置的,所以这才有操作2中为什么获取到的尾节点的下一个节点不为空的原因。
特别需要说明的是,对尾节点的tail的操作需要换成临时变量t和s,一方面是为了去掉volatile变量的可变性,另一方面是为了减少volatile的性能影响。
清单2 描述的出队列的过程,这个过程和入队列相似,有点意思。
头结点是为了标识队列起始,也为了减少空指针的比较,所以头结点总是一个item为null的非null节点。也就是说head!=null并且head.item==null总是成立。所以实际上获取的是head.next,一旦将头结点head设置为head.next成功就将新head的item设置为null。至于以前就的头结点h,h.item=null并且h.next为新的head,但是由于没有对h的引用,所以最终会被GC回收。这就是整个出队列的过程。
清单2 出队列操作
public E poll() {
for (;;) {
Node<E> h = head;
Node<E> t = tail;
Node<E> first = h.getNext();
if (h == head) {
if (h == t) {
if (first == null)
return null;
else
casTail(t, first);
} else if (casHead(h, first)) {
E item = first.getItem();
if (item != null) {
first.setItem(null);
return item;
}
// else skip over deleted item, continue loop,
}
}
}
}
另外对于清单3 描述的获取队列大小的过程,由于没有一个计数器来对队列大小计数,所以获取队列的大小只能通过从头到尾完整的遍历队列,显然这个代价是很大的。所以通常情况下ConcurrentLinkedQueue需要和一个AtomicInteger搭配才能获取队列大小。后面介绍的BlockingQueue正是使用了这种思想。
清单3 遍历队列大小
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = p.getNext()) {
if (p.getItem() != null) {
// Collections.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
}
}
return count;
}
参考资料:
Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms
多线程基础总结十一—ConcurrentLinkedQueue
对ConcurrentLinkedQueue进行的并发测试
一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序。队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。此队列不允许使用 null 元素。
由于ConcurrentLinkedQueue只是简单的实现了一个队列Queue,因此从API的角度讲,没有多少值的介绍,使用起来也很简单,和前面遇到的所有FIFO队列都类似。出队列只能操作头节点,入队列只能操作尾节点,任意节点操作就需要遍历完整的队列。
重点放在解释ConcurrentLinkedQueue的原理和实现上。
在继续探讨之前,结合前面线程安全的相关知识,我来分析设计一个线程安全的队列哪几种方法。
第一种:使用synchronized同步队列,就像Vector或者Collections.synchronizedList/Collection那样。显然这不是一个好的并发队列,这会导致吞吐量急剧下降。
第二种:使用Lock。一种好的实现方式是使用ReentrantReadWriteLock来代替ReentrantLock提高读取的吞吐量。但是显然ReentrantReadWriteLock的实现更为复杂,而且更容易导致出现问题,另外也不是一种通用的实现方式,因为ReentrantReadWriteLock适合哪种读取量远远大于写入量的场合。当然了ReentrantLock是一种很好的实现,结合Condition能够很方便的实现阻塞功能,这在后面介绍BlockingQueue的时候会具体分析。
第三种:使用CAS操作。尽管Lock的实现也用到了CAS操作,但是毕竟是间接操作,而且会导致线程挂起。一个好的并发队列就是采用某种非阻塞算法来取得最大的吞吐量。
ConcurrentLinkedQueue采用的就是第三种策略。它采用了参考资料1 中的算法。
在锁机制中谈到过,要使用非阻塞算法来完成队列操作,那么就需要一种“循环尝试”的动作,就是循环操作队列,直到成功为止,失败就会再次尝试。这在前面的章节中多次介绍过。
针对各种功能深入分析。
在开始之前先介绍下ConcurrentLinkedQueue的数据结构。
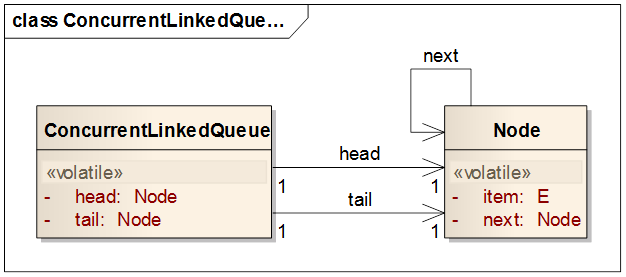
在上面的数据结构中,ConcurrentLinkedQueue只有头结点、尾节点两个元素,而对于一个节点Node而言除了保存队列元素item外,还有一个指向下一个节点的引用next。
看起来整个数据结构还是比较简单的。但是也有几点是需要说明:
所有结构(head/tail/item/next)都是volatile类型。 这是因为ConcurrentLinkedQueue是非阻塞的,所以只有volatile才能使变量的写操作对后续读操作是可见的(这个是有happens-before法则保证的)。同样也不会导致指令的重排序。
所有结构的操作都带有原子操作,这是由AtomicReferenceFieldUpdater保证的,这在原子操作中介绍过。它能保证需要的时候对变量的修改操作是原子的。
由于队列中任何一个节点(Node)只有下一个节点的引用,所以这个队列是单向的,根据FIFO特性,也就是说出队列在头部(head),入队列在尾部(tail)。头部保存有进入队列最长时间的元素,尾部是最近进入的元素。
没有对队列长度进行计数,所以队列的长度是无限的,同时获取队列的长度的时间不是固定的,这需要遍历整个队列,并且这个计数也可能是不精确的。
初始情况下队列头和队列尾都指向一个空节点,但是非null,这是为了方便操作,不需要每次去判断head/tail是否为空。但是head却不作为存取元素的节点,tail在不等于head情况下保存一个节点元素。也就是说head.item这个应该一直是空,但是tail.item却不一定是空(如果head!=tail,那么tail.item!=null)。
对于第5点,可以从ConcurrentLinkedQueue的初始化中看到。这种头结点也叫“伪节点”,也就是说它不是真正的节点,只是一标识,就像c中的字符数组后面的\0以后,只是用来标识结束,并不是真正字符数组的一部分。
private transient volatile Node<E> head = new Node<E>(null, null);
private transient volatile Node<E> tail = head;
有了上述5点再来解释相关API操作就容易多了。
在上一节中列出了add/offer/remove/poll/element/peek等价方法的区别,所以这里就不再重复了。
清单1 入队列操作
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
Node<E> n = new Node<E>(e, null);
for (;;) {
Node<E> t = tail;
Node<E> s = t.getNext();
if (t == tail) {
if (s == null) {
if (t.casNext(s, n)) {
casTail(t, n);
return true;
}
} else {
casTail(t, s);
}
}
}
}
清单1 描述的是入队列的过程。整个过程是这样的。
获取尾节点t,以及尾节点的下一个节点s。如果尾节点没有被别人修改,也就是t==tail,进行2,否则进行1。
如果s不为空,也就是说此时尾节点后面还有元素,那么就需要把尾节点往后移,进行1。否则进行3。
修改尾节点的下一个节点为新节点,如果成功就修改尾节点,返回true。否则进行1。
从操作3中可以看到是先修改尾节点的下一个节点,然后才修改尾节点位置的,所以这才有操作2中为什么获取到的尾节点的下一个节点不为空的原因。
特别需要说明的是,对尾节点的tail的操作需要换成临时变量t和s,一方面是为了去掉volatile变量的可变性,另一方面是为了减少volatile的性能影响。
清单2 描述的出队列的过程,这个过程和入队列相似,有点意思。
头结点是为了标识队列起始,也为了减少空指针的比较,所以头结点总是一个item为null的非null节点。也就是说head!=null并且head.item==null总是成立。所以实际上获取的是head.next,一旦将头结点head设置为head.next成功就将新head的item设置为null。至于以前就的头结点h,h.item=null并且h.next为新的head,但是由于没有对h的引用,所以最终会被GC回收。这就是整个出队列的过程。
清单2 出队列操作
public E poll() {
for (;;) {
Node<E> h = head;
Node<E> t = tail;
Node<E> first = h.getNext();
if (h == head) {
if (h == t) {
if (first == null)
return null;
else
casTail(t, first);
} else if (casHead(h, first)) {
E item = first.getItem();
if (item != null) {
first.setItem(null);
return item;
}
// else skip over deleted item, continue loop,
}
}
}
}
另外对于清单3 描述的获取队列大小的过程,由于没有一个计数器来对队列大小计数,所以获取队列的大小只能通过从头到尾完整的遍历队列,显然这个代价是很大的。所以通常情况下ConcurrentLinkedQueue需要和一个AtomicInteger搭配才能获取队列大小。后面介绍的BlockingQueue正是使用了这种思想。
清单3 遍历队列大小
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = p.getNext()) {
if (p.getItem() != null) {
// Collections.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
}
}
return count;
}
参考资料:
Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms
多线程基础总结十一—ConcurrentLinkedQueue
对ConcurrentLinkedQueue进行的并发测试

相关文章推荐
- String StringBuffer StringBuilder区别
- Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Query was empty
- Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Query was empty
- 深入浅出 Java Concurrency (19): 并发容器 part 4 并发队列与Queue简介
- (L1)AudioService AudioManagerInternal , Ringer mode, stream uid
- CF 129C Statues
- autolayout 动态计算高度时 UILabel的preferredMaxLayoutWidth设置
- 关于uitableviewcell的accessoryType属性
- easyui删除多行问题
- UI线程与handle
- ajax调用期间添加蒙层blockUI
- 关于UIBarButtonItem的一点札记
- iOS-UITextField属性设置备忘
- Nasm Intro - Understand nasm by OpenH264 WelsCPUId
- UIControl
- Message、Handler、MessageQueue、Looper之间关系图文总结
- Java Scripting Programmer's Guide
- HDU 2604 Queuing
- easyui treegrid 分页
- ListView局部更新(非notifyDataSetChanged)