Scrapy的Ip代理的配置(未完成)
2015-07-08 21:04
495 查看
1、编写代理中间件
这是最直接的方式,也是能够比较快速实现的。前提是你需要拥有可用的代理ip。网上有一些免费的代理ip资源可以使用,但是往往都不稳定。如果有条件可以买一些IP代理来使用。
代理中间件的代码如下所示:
代理中间件代码编写完成后,还要修改一下配置文件,如下所示:
在没有计划购买代理ip,免费代理ip又不能满足需求的情况下,可以考虑曲线救国的策略。我主要参考了如下几种方式:
2、Scrapy+Goagent策略
Goagent是google的代理项目,使用它你可以通过google的服务器去访问目的站点,也就实现了ip代理的功能。但是Goagent项目特别注明了,他的ip不是匿名的,所以这个策略能起到的效果还是很有限的。
使用这个策略只需要将1中代理中间件中的代理ip设置为Goagent代理ip即可。
备注:如果你想抓取国外被XX的网站,这也是一个不错的选择。
3、Scrapy+Crawlera策略
Crawlera是Scrapinghub公司提供的一个下载的中间件,其提供了很多服务器和ip,scrapy可以通过Crawlera向目标站点发起请求。
该文章对scrapy使用Crawlera做了比较好的介绍,可以参考。
详细信息可以参考官方文档: http://doc.scrapinghub.com/crawlera.html
最重要的是需要在配置文件里,配置开启Crawlera中间件。如下所示:
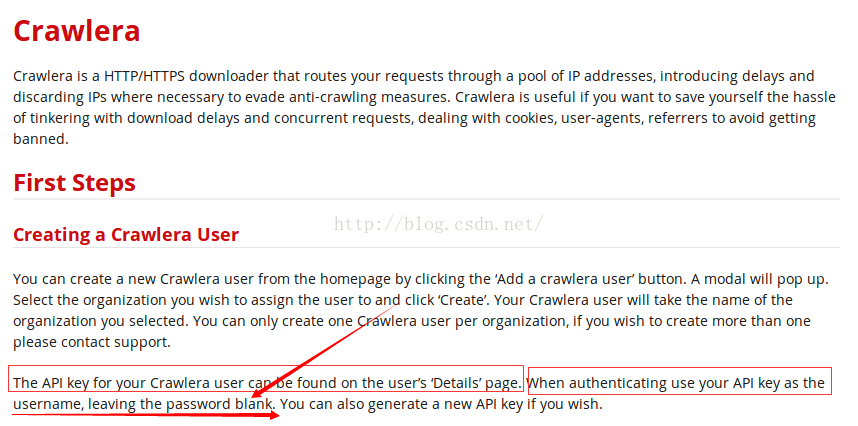
我因为这个错误,浪费了好长时间,一般默认是不填写的,空白即可。
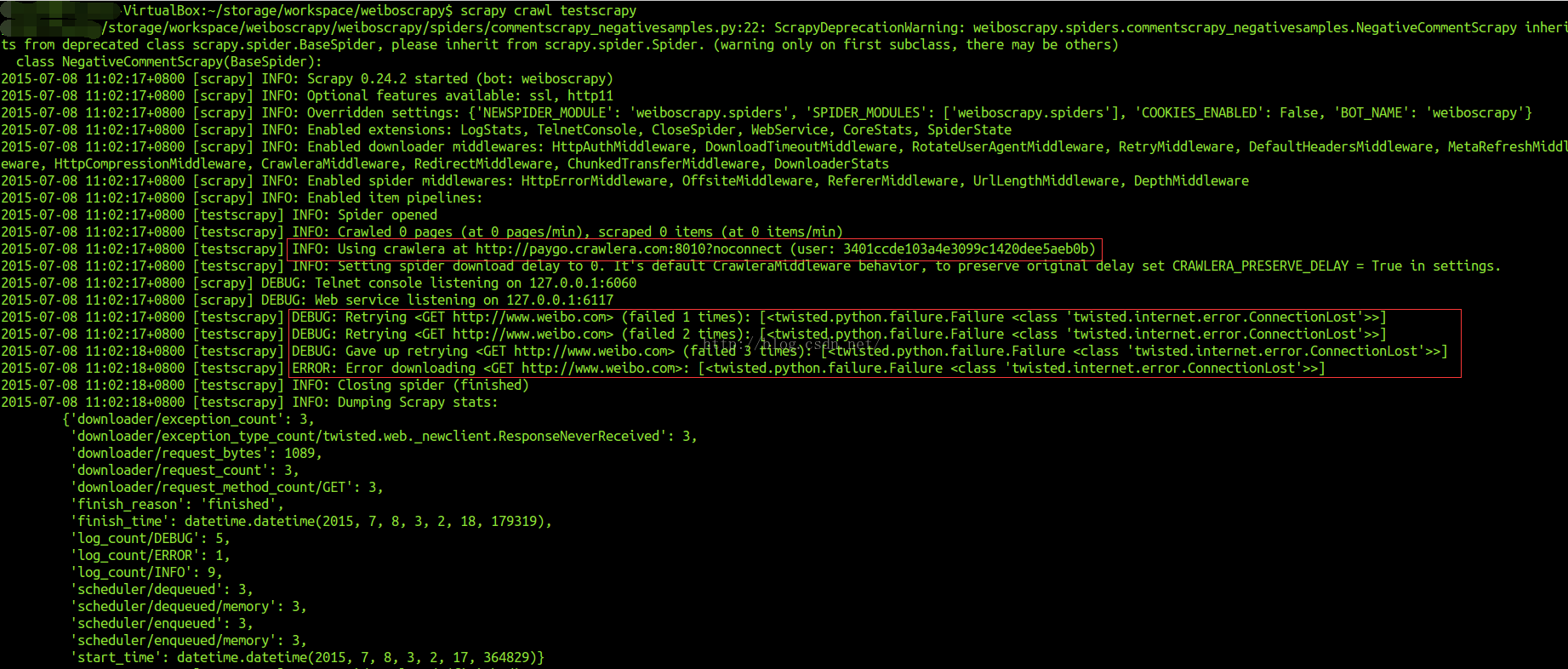
在配置完成后,使用crawlera中间件访问“http://www.weibo.com”出现如下错误:
[<twisted.python.failure<class 'twisted.internet.error.ConnectionLost'>>]
搞了半天没搞明白,后来尝试访问别的url地址,结果就没有这个错误了:
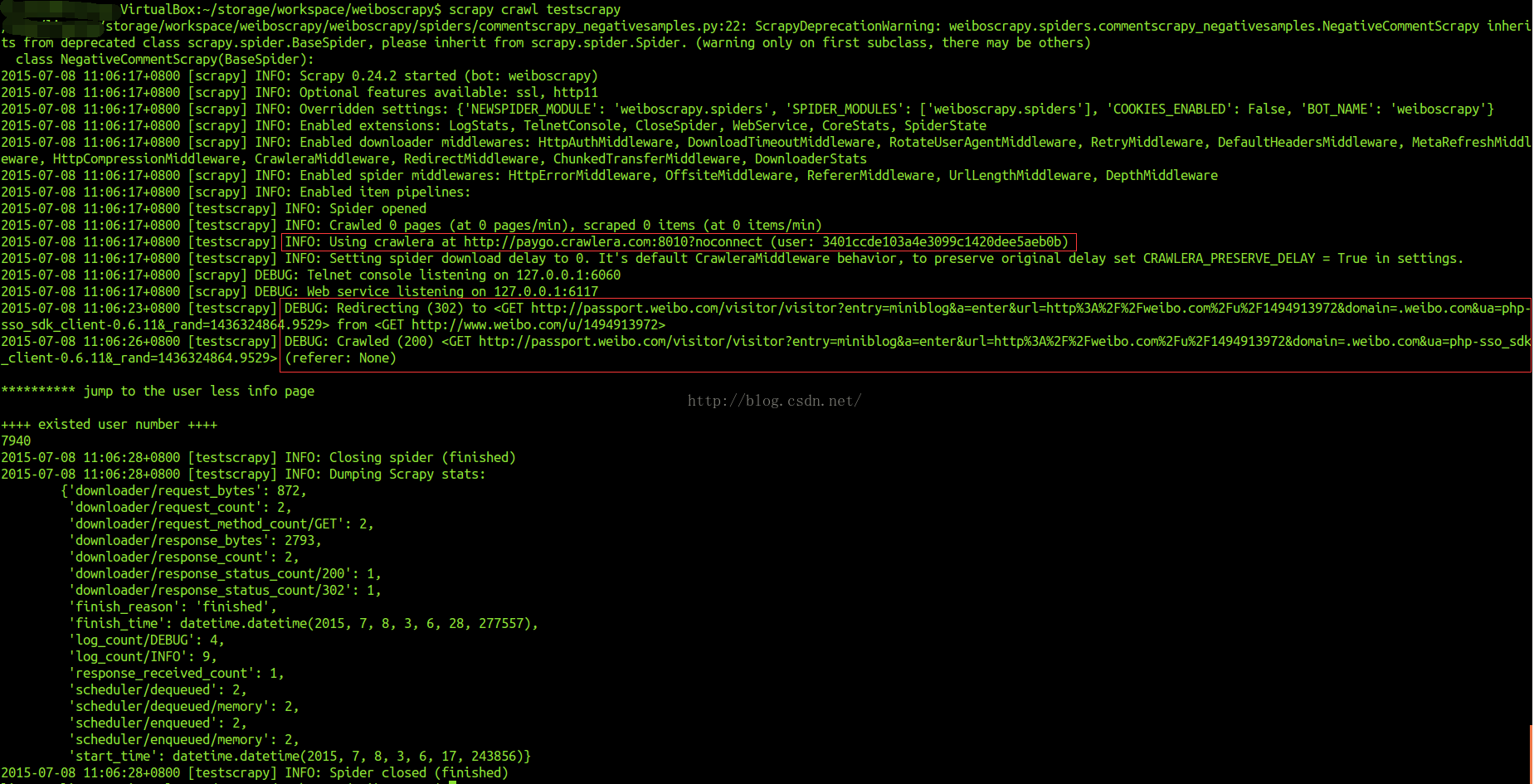
不知道是怎么搞的。主要是对Twisted模块也不是很熟,这个问题暂时没有解决。
4、Scrapy+Tor(高度匿名的免费代理)
XX-Net在Github首页上指明其本身不是匿名的,向用户推荐了Tor这个工具。暂时还没有实现,待验证。
http://pkmishra.github.io/blog/2013/03/18/how-to-run-scrapy-with-TOR-and-multiple-browser-agents-part-1-mac/
未完待续...
这是最直接的方式,也是能够比较快速实现的。前提是你需要拥有可用的代理ip。网上有一些免费的代理ip资源可以使用,但是往往都不稳定。如果有条件可以买一些IP代理来使用。
代理中间件的代码如下所示:
import random class ProxyMiddleware(object): # overwrite process request def process_request(self, request, spider): # Set the location of the proxy proxy_ip = random.choice(self.user_agent_ip_list) request.meta['proxy'] = proxy_ip print '+'*8, 'the Current ip address is', proxy_ip, '+'*8 # ip from http://pachong.org/ user_agent_ip_list = [\ "http://122.96.59.102:81", "http://14.18.238.177:4040", "http://144.112.91.97:90", "http://124.202.169.54:8118" ]
代理中间件代码编写完成后,还要修改一下配置文件,如下所示:
DOWNLOADER_MIDDLEWARES = {
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 110,
'weiboscrapy.rotate_ipagent.ProxyMiddleware': 100,
}在没有计划购买代理ip,免费代理ip又不能满足需求的情况下,可以考虑曲线救国的策略。我主要参考了如下几种方式:
2、Scrapy+Goagent策略
Goagent是google的代理项目,使用它你可以通过google的服务器去访问目的站点,也就实现了ip代理的功能。但是Goagent项目特别注明了,他的ip不是匿名的,所以这个策略能起到的效果还是很有限的。
使用这个策略只需要将1中代理中间件中的代理ip设置为Goagent代理ip即可。
proxy_ip = “https://127.0.0.1:8087”前提是你在自己的电脑上安装了Goagent或者XX-Net(内部集成了Goagent)。
备注:如果你想抓取国外被XX的网站,这也是一个不错的选择。
3、Scrapy+Crawlera策略
Crawlera是Scrapinghub公司提供的一个下载的中间件,其提供了很多服务器和ip,scrapy可以通过Crawlera向目标站点发起请求。
该文章对scrapy使用Crawlera做了比较好的介绍,可以参考。
详细信息可以参考官方文档: http://doc.scrapinghub.com/crawlera.html
最重要的是需要在配置文件里,配置开启Crawlera中间件。如下所示:
DOWNLOADER_MIDDLEWARES = {
# ********CRAWLERA SETTING********
'scrapy_crawlera.CrawleraMiddleware': 600
}然后要添加以下配置信息:# ********CRAWLERA SETTING******** CRAWLERA_ENABLED = True CRAWLERA_USER = '3401ccde103a4e3099c1420dee5aeb0b' CRAWLERA_PASS = '' CRAWLERA_PRESERVE_DELAY = True其中CRAWLERA_USER是注册crawlera之后申请到的API Key;是
CRAWLERA_PASS<span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);">则代表crawlera的password,关于是否填写password,参考官网上的一句话,如下图所示。</span>
我因为这个错误,浪费了好长时间,一般默认是不填写的,空白即可。
在配置完成后,使用crawlera中间件访问“http://www.weibo.com”出现如下错误:
[<twisted.python.failure<class 'twisted.internet.error.ConnectionLost'>>]
搞了半天没搞明白,后来尝试访问别的url地址,结果就没有这个错误了:
不知道是怎么搞的。主要是对Twisted模块也不是很熟,这个问题暂时没有解决。
4、Scrapy+Tor(高度匿名的免费代理)
XX-Net在Github首页上指明其本身不是匿名的,向用户推荐了Tor这个工具。暂时还没有实现,待验证。
http://pkmishra.github.io/blog/2013/03/18/how-to-run-scrapy-with-TOR-and-multiple-browser-agents-part-1-mac/
未完待续...

相关文章推荐
- install and upgrade scrapy
- install scrapy with pip and easy_install
- Scrapy的架构介绍
- python使用scrapy解析js示例
- Python基于scrapy采集数据时使用代理服务器的方法
- 使用scrapy实现爬网站例子和实现网络爬虫(蜘蛛)的步骤
- Python打印scrapy蜘蛛抓取树结构的方法
- Python实现在线程里运行scrapy的方法
- Python使用scrapy采集时伪装成HTTP/1.1的方法
- Python使用Scrapy爬取妹子图
- 基于scrapy实现的简单蜘蛛采集程序
- 零基础写python爬虫之使用Scrapy框架编写爬虫
- Python使用scrapy采集数据时为每个请求随机分配user-agent的方法
- Python自定义scrapy中间模块避免重复采集的方法
- 在Linux系统上安装Python的Scrapy框架的教程
- Python使用scrapy采集数据过程中放回下载过大页面的方法
- Python实现从脚本里运行scrapy的方法
- Python使用scrapy抓取网站sitemap信息的方法
- 零基础写python爬虫之爬虫框架Scrapy安装配置
- Python+Scrapy安装