[SQL入门级] 接上篇,继续查询
2015-07-08 16:48
239 查看
距离上一篇时间隔得蛮久了,这篇继续查询,简单总结一下聚合函数、分组的知识。
一、聚合函数(组函数/多行函数)
一、聚合函数(组函数/多行函数)
何谓多行函数,顾名思义就是函数作用于多行数据得出一个输出结果,什么意思呢?看图:
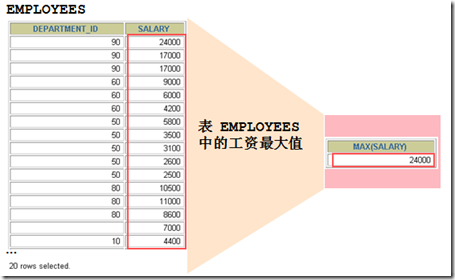

那么常用的有哪些这样的函数呢?
AVG(平均值)
SUM(合计)
COUNT(计数)
MAX(最大值)
MIN(最小值)
STDDEV(标准差)
组函数使用的语法,用法很简单,但有两点要注意:

I. 函数参数类型
对数值型数据使用AVG和SUM函数
对任意数据类型的数据使用MIN、MAX、COUNT函数
II. 有关空值的处理
首先组函数是忽略空值的,例如COUNT(*)返回的是表中所有的记录数,而COUNT(expr)返回的是expr字段不为空的记录数
那么怎样来处理空值呢,就要用到上一篇中提到的NVL函数,SELECT AVG(NVL(commission_pct,0)) FROM employees
DISTINCT关键字表达的非空且不重复,COUNT(DISTINCT expr)返回的expr非空且不重复的记录数
III. 不能在WHERE子句中使用组函数,这点结合后面的HAVING子句解释。
IV. 组函数可以嵌套使用
二、数据分组SUM(合计)
COUNT(计数)
MAX(最大值)
MIN(最小值)
STDDEV(标准差)
组函数使用的语法,用法很简单,但有两点要注意:

I. 函数参数类型
对数值型数据使用AVG和SUM函数
对任意数据类型的数据使用MIN、MAX、COUNT函数
II. 有关空值的处理
首先组函数是忽略空值的,例如COUNT(*)返回的是表中所有的记录数,而COUNT(expr)返回的是expr字段不为空的记录数
那么怎样来处理空值呢,就要用到上一篇中提到的NVL函数,SELECT AVG(NVL(commission_pct,0)) FROM employees
DISTINCT关键字表达的非空且不重复,COUNT(DISTINCT expr)返回的expr非空且不重复的记录数
III. 不能在WHERE子句中使用组函数,这点结合后面的HAVING子句解释。
IV. 组函数可以嵌套使用
GROUP BY子句,分组数据
意思咱就不废话了,用的时候注意两点:
SELECT后面的所有列中,没有使用聚合函数的列,必须出现在GROUP BY后面,反过来包含在GROUP BY子句的中的列却不必包含在SELECT列表中。
GROUP BY子句可以包含多个列,同意也适用规则1。
有点晕,什么意思呢?我来解释一下,判断一个sql语句是否合法其实可以试着去理解你要写的sql语句要表达的实际想法,例如:
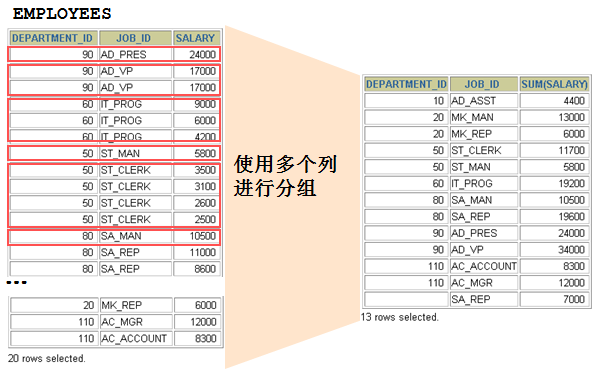
select department_id,job_id,avg(salary)
from employees
group by department_id,job_id

如上语句,我想要表达的意思是:从雇员这张表中求出不同部门和不同工种的人的平均工资,输出的格式是按照SELECT语句列表。那么如果我从SELECT列表中随便删掉一个字段,改变的只是我输出的格式,我还是按部门和工种进行分类了;但是如果只从GROUP
BY子句中删掉job_id,则语句表达的意思就不能成立了,我按部门进行分组,但是部门中有很多个工种,结果到底要怎样对应不得而知。
意思咱就不废话了,用的时候注意两点:
SELECT后面的所有列中,没有使用聚合函数的列,必须出现在GROUP BY后面,反过来包含在GROUP BY子句的中的列却不必包含在SELECT列表中。
GROUP BY子句可以包含多个列,同意也适用规则1。
有点晕,什么意思呢?我来解释一下,判断一个sql语句是否合法其实可以试着去理解你要写的sql语句要表达的实际想法,例如:
select department_id,job_id,avg(salary)
from employees
group by department_id,job_id
如上语句,我想要表达的意思是:从雇员这张表中求出不同部门和不同工种的人的平均工资,输出的格式是按照SELECT语句列表。那么如果我从SELECT列表中随便删掉一个字段,改变的只是我输出的格式,我还是按部门和工种进行分类了;但是如果只从GROUP
BY子句中删掉job_id,则语句表达的意思就不能成立了,我按部门进行分组,但是部门中有很多个工种,结果到底要怎样对应不得而知。
HAVING子句,过滤分组
WHERE子句的作用是筛选满足条件的数据行,即在分组之前过滤数据,条件中不能使用聚合函数;使用WHERE条件显示特定的行;
HAVING子句的作用是筛选满足条件的组,即在分组之后过滤分组,条件中经常包含聚合函数;使用HAVING条件显示特定的分组;
WHERE子句的作用是筛选满足条件的数据行,即在分组之前过滤数据,条件中不能使用聚合函数;使用WHERE条件显示特定的行;
HAVING子句的作用是筛选满足条件的组,即在分组之后过滤分组,条件中经常包含聚合函数;使用HAVING条件显示特定的分组;

相关文章推荐
- 使用PowerDesigner 设计SQL Server 数据库
- 在C#应用程序中,利用表值参数过滤重复,批量向数据库导入数据,并且返回重复数据
- MongoDB安装和简介
- MySQl Study学习之--MySQl二进制日志管理
- mongodb的安装和简单命令
- 使用maatkit工具检查并同步mysql主从数据
- 使用maatkit工具检查并同步mysql主从数据
- oracle id 自动增长
- windows下安装并启动redis服务
- mongodb文档型数据库特点介绍
- MySQL安装配置
- mysql UNIX时间戳与日期的相互转换
- 【转】安装mysql 出现:Fatal error: Can't open and lock privilege tables: Table 'mysql.user' doesn't exist
- 数据库设计
- mysql左/右/内连接
- oracle数据库存储过程范例(使用游标进行循环)
- Sql语句,先查询再插入一条语句完成。
- LeetCode_Mysql_Rising Temperature
- SQL SERVER 2008安全配置
- 如何让PL/SQL Developer记住密码?