Hibernate笔记总结整理
2015-07-04 11:26
543 查看
一.Hibernate是什么
Hibernate是一种基于Java的轻量级的ORM框架基于Java:底层是Java语言实现的 native
轻量级:内存消耗比较少,运行速度比较快,性能稍高
ORM: Object:对象
类 属性 数据类型 对象
Relation:关系型数据库表
表名 字段 数据类型 数据
Mapping:映射
将上面的具有对应关系的模型关联起来,操作对象,即操作数据库表
Hibernate实质:自动的JDBC+自动的SQL语句(最差设计)
Hibernate是一个数据层解决方案,应对Dao的开发
二.Hibernate有什么
图的分类:系统架构图,技术架构图系统架构图:描述的是整个系统的模块层次关系,讲究:上层依赖于下层
Hibernate内部包含有事务对象与创建该对象的事务工厂对象
Hibernate内部包含有自己创建JDBC连接的对象和使用其他数据库连接池的对象
Hibenrate内部没有实现JDBC,JNDI,JTA接口,仅仅是调用被人的
Hibernate与App打交道靠PO完成,App内部包含有一个TO对象
三.Hibernate基础实例
1. 制作模型类
public class UserModel {
//1.提供一个公共的无参的构造方法(默认)
//2.提供一个主键属性
private String uuid;
//3.提供其他属性
private String name;
private Integer age;
private String address;
//4.封装所有的属性
}2. 制作映射
在模型类所在的包下制作一个与模型名相同的文件,扩展名.hbm.xmlUserModel.hbm.xml
模板通过查找资源文件中的User.hbm.xml第一个就OK
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-mapping PUBLIC '-//Hibernate/Hibernate Mapping DTD 3.0//EN' 'http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd'> <hibernate-mapping> <!-- 声明类与表的关系 --> <class name="cn.itcast.h3.user.UserModel" table="tbl_user"> <!-- 声明主键的映射 --> <id name="uuid" column="uuid"> <!-- 声明主键的生成策略 --> <generator class="assigned"/> </id> <!-- 声明属性与字段的映射 --> <property name="name" column="userName"/> <property name="age"/> <property name="address"/> </class> </hibernate-mapping>
3.制作Hibernate的系统配置文件
放置在src目录下,文件名hibernate.cfg.xml模板通过查找资源文件中的*.cfg.xml第一个就OK
<?xml version='1.0' encoding='utf-8'?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <session-factory> <!-- 声明连接的数据库 --> <property name="connection.driver_class">com.mysql.jdbc.Driver</property> <property name="connection.url">jdbc:mysql://localhost:3306/h3db</property> <property name="connection.username">root</property> <property name="connection.password">root</property> <!-- Hibernate的基础配置信息 --> <property name="dialect">org.hibernate.dialect.MySQLDialect</property> <property name="show_sql">true</property> <!-- 将写好的配置文件hbm.xml添加过来 --> <mapping resource="cn/itcast/h3/user/UserModel.hbm.xml"/> </session-factory> </hibernate-configuration> <?xml version='1.0' encoding='utf-8'?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://w 4000 ww.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <session-factory> <!-- 声明连接的数据库 --> <property name="connection.driver_class">com.mysql.jdbc.Driver</property> <property name="connection.url">jdbc:mysql://localhost:3306/h3db</property> <property name="connection.username">root</property> <property name="connection.password">root</property> <!-- Hibernate的基础配置信息 --> <property name="dialect">org.hibernate.dialect.MySQLDialect</property> <property name="show_sql">true</property> <!-- 将写好的配置文件hbm.xml添加过来 --> <mapping resource="cn/itcast/h3/user/UserModel.hbm.xml"/> </session-factory> </hibernate-configuration>
4.测试
UserModel um = new UserModel();
um.setUuid("1");
um.setName("Jock");
um.setAge(34);
um.setAddress("河南开封");
//将配置文件的信息加载到对象中
Configuration conf = new Configuration().configure();
//创建SessionFactory,基于配置对象
SessionFactory sf = conf.buildSessionFactory();
//开启Session
Session s = sf.openSession();
//开启事务
Transaction t = s.beginTransaction();
//将一个信息保存到数据库中
s.save(um);
//提交事务
t.commit();
//关闭Session
s.close();四.Hibernate基础配置详解和注意点
一.模型制作规则
提供公共无参的构造方法(可使用自动生成的)如果使用投影技术,一定要显式声明公共无参的构造方法
提供一个标识属性,作为对象的主键,映射数据库表主键
通常使用uuid作为主键
对所有其他属性进行私有化声明,并进行标准封装
属性声明时使用封装类模型,避免使用基本数据类型
不要使用final修饰符(否则将无法生成代理对象进行优化)
* OID——用于区分对象的属性
**OID选取规则:优先考虑代理主键
属性:身份证号具有业务含义,自然主键
属性:uuid不具有任何业务含义,代理主键
对象的属性选择:优先使用封装类,避免使用基本数据类型
使用基本数据类型还是封装类类型
针对所拥有的数据值是否存在的描述性不同
int 0 Integer null
double 0.0 Double null
二.映射配置文件
包含内容:类与表的映射
主键的映射
属性与字段的映射
关系的映射(后期)
命名规范:
****.hbm.xml
可以写成任意的名称a.xml,不满足规范
<hibernate-mapping> <!-- 类与表的映射 --> <!-- class:描述类与表的映射 --> <!-- class:name:说明类的全路径名 --> <!-- class:table:说明的是表名 --> <class name="cn.itcast.h3.user.UserModel" table="tbl_user" schema="h3db"> <!-- 主键的映射 --> <!-- id:描述类的OID与表的主键映射关系 --> <!-- id:name:配置类中用于作为OID的属性名 --> <!-- id:column:数据库表中的主键字段名,如果该值与name相同,可以省略 --> <id name="uuid" column="uuid"> <!-- generator:用于指定当前OID值的生成策略 --> <generator class="assigned"/> </id> <!-- 属性与字段的映射 --> <!-- property:描述类中的属性与表中的字段之间的映射关系 --> <!-- property:name:类中的属性名 --> <!-- property:colun:表中的字段名 --> <property name="age"/> <property name="usreName" column="userName"></property> <property name="address"> <column name="address"></column> </property> </class> </hibernate-mapping>
三.主键生成策略
手工控制:assigned:开发者提供
自动生成:
uuid:要求字符串类型,长度至少32位,由Java计算生成
increment:要求整数类型,长度不限制,由通过查询当前OID最大值后+1赋值给OID
identity:要求整数类型,长度不限制,由MySQL数据库实现,要求字段自增
sequence:要求整数类型,长度不限制,由Oracle数据库实现
native:要求整数类型,长度不限制,会根据所使用的数据库自动选择identity/ sequence
四.系统配置文件
包含内容:数据库连接的配置
可选配置
资源注册
二级缓存(后面讲解)
<hibernate-configuration> <session-factory> <!-- 数据库连接的配置:封装所连接的数据库的信息 --> <!-- 前面的hibernate.可以省略,简写格式 --> <property name="connection.driver_class">com.mysql.jdbc.Driver</property> <property name="connection.url">jdbc:mysql://localhost:3306/h3db</property> <property name="connection.username">root</property> <property name="connection.password">root</property> <!-- 可选配置 --> <!-- 方言配置 :指定使用的数据库的语法规则 --> <!-- 方言如果设置错误,增删改语句可以运行,查询语句个别可以运行 --> <property name="dialect">org.hibernate.dialect.MySQLDialect</property> <!-- 显示执行的SQL语句 :控制台输出的指令--> <property name="show_sql">true</property> <!-- 格式化SQL语句 --> <property name="format_sql">true</property> <!-- 自动生成表结构 --> <!-- <property name="hbm2ddl.auto">update</property> --> <!-- 自动提交事务 --> <!-- <property name="connection.autocommit">true</property> --> <!-- 资源注册 --> <mapping resource="cn/itcast/h3/user/UserModel.hbm.xml"/> <mapping resource="cn/itcast/h3/user/UserModel1.hbm.xml"/> <mapping resource="cn/itcast/h3/user/UserModel2.hbm.xml"/> <mapping resource="cn/itcast/h3/user/UserModel3.hbm.xml"/> </session-factory> </hibernate-configuration>
*c3p0连接池配置
1.导入c3p0.jar
2.开启任意一条c3p0在hibernate中的配置即启用c3p0连接池
<property name="hibernate.c3p0.max_size">171</property>
<property name="hibernate.c3p0.min_size">43</property>
<property name="hibernate.c3p0.timeout">-1</property>
五.核心API
l.Configuration
封装hibernate的系统配置信息,将hibernate.cfg.xml文件中的内容转化成一个对象配置文件名可以为任意的,需要执行是为其指定对应的名称即可
//早期格式:读取hibernate.properties文件的格式
//Configuration conf = new Configuration();
//流行格式:读取hibernate.properties文件后,再读取hibernate.cfg.xml
Configuration conf = new Configuration().configure("hibernate.cfg.xml");2.SessionFactory
SessionFactory对象是通过读取Configuration,然后将其中的配置信息转化成可以制作Session对象的工厂类Configuration conf = new Configuration().configure(); SessionFactory sf = conf.buildSessionFactory();
3.Session
描述的是H3与应用程序进行数据交换的对象,由SessionFactory对象获取,创建过程伴随着SessionFactory对象的创建已经完成,所有对象位于连接池内Session完成了Java程序中的对象与数据库表中数据的转化过程,实际执行过程则是通过JDBC+SQL完成
使用完毕后,记得关闭Session,否则连接池中的连接对象将会被占用
Configuration conf = new Configuration().configure(); SessionFactory sf = conf.buildSessionFactory();
//该操作仅仅是从连接池中获取对象
Session s = sf.openSession();
//Session对应的是请求对象,使用完毕后需要关闭
//不是将连接对象释放,是将其交回到连接池
s.close();
操作:
添加数据
save(obj) 返回添加数据的OID生成值persist(obj) 无返回值
删除数据
delete(obj) 删除操作必须依赖OID进行,因此删除的对象必须具有OID,否则不执行修改数据
update(obj)修改操作必须依赖OID进行,因此修改的对象必须具有OID,否则抛出异常saveOrUpdate(obj) 提供的数据如果有OID修改,如果没有OID新增
查询单个数据
load(查询模型.class,OID) 根据OID进行查询,查询结果封装成一个查询模型.class类型的对象get 目前同上,区别有3点
**制作标准的HibernateUitls(H3Utils)
public class H3Utils {
private static Configuration conf = null;
//将SessionFactory缓存
private static SessionFactory sf = null;
static{
conf = new Configuration().configure();
sf = conf.buildSessionFactory();
}
public static Session getSession(){
return sf.openSession();
}
}4.Transaction
描述的是数据库进行增删改操作时,事务保障对应的对象//操作数据库增删改操作,需要事务保障 //事务对象需要由Session对象开启得到,每个事务对象绑定一个Session对象 Transaction t = s.beginTransaction(); //提交事务 t.commit(); //回滚事务 t.rollback();
5.Query
描述的是可以执行任意查询的对象Query对象执行查询使用的是Hibernate专用的查询语句,HQL
HQL与SQL的区别
SQL:SELECT * FROM TBL_USERHQL:from UserModel
HQL:select um from UserModel um
SQL:select userName from tbl_user
HQL:select userName from UserModel
HQL:select um.userName from UserModel um
HQL:select um.userName from UserModel 错误
HQL:select userName from UserModel um 正确
1.创建Query对象
String hql = “。。。。HQL查询语句。。。。“;Query q = s.createQuery(hql);
2.获取查询结果
list():用于执行查询,返回的结果是0到多条
uniqueResult():
用于执行查询,返回的结果是0到1条
3.查询返回值类型(单一)
select 属性名 from **Model返回的数据只有一个结果,数据总量根据实际总量
4.查询返回值类型(多个)
select 属性名1,属性名2,…from **Model返回的数据是一个对象数组,数据总量根据实际总量
对象数组Object[]封装了查询的所有属性/字段
*以上查询内容不是整个模型的查询称为投影查询
5.分页查询
setFirstResult(首数据索引);setMaxResults(最大记录数);
6.按条件查询(3种格式)
固定参数条件查询String hql = "from UserModel where userName = 'aa'";
Hibernate内部的SQL语句是预编译格式,不推荐使用
无参数条件查询
String hql = "from UserModel where userName = address";
动态参数条件查询
参数的设定可以使用?或者:变量名格式
String hql = "from UserModel where age < ? and age > ?";
String hql = "from UserModel where age > :age2 and age < :age";
推荐使用第二种,变量名格式
参数设置的方法可以使用两种
setParameter(***,参数值); 所有类型
set***类型(***,参数值); 具体类型 推荐
推荐格式
String hql = "from UserModel where age > :age2 and age < :age";
q.setInteger(“age”,3);
q.setString(“userName”,”aa”);
7.链式格式
仅仅是一个设计格式,所有的方法返回值如果类型都是调用对象的类型,均支持链式格式8.聚合函数
count:返回类型Longmax/min:返回类型为原始数据的类型
sum:返回类型Long或Double
avg:返回类型Double
9.分组与排序:与SQL查询完全相同
10.投影数据封装(了解)
在类中提供具体对应的构造方法,用于在HQL语句中封装数据改造HQL语句:select new UserModel(userName,age) from UserModel
使用Hibernate完成按条件查询,优先推荐使用Criteria对象
1.Criteria对象获取方式和查询方式
Critieria c = session.createCriteria(查询模型.class);获取0到多条数据c.list(); 同Query.list()
获取0到1条数据c.uniqueResult();
同Query.uniqueResult();
2.QBC投影查询
单个属性
Property p = Property.forName(“查询字段名”); //Property为Projection的一个实现类criteria.setProjection(p);//设置查询内容
多个属性
Property p1 = Property.forName(“查询字段名1”);Property p2 = Property.forName(“查询字段名2”);
ProjectionList plist = Projections.projectionList();
plist.add(p1);
plist.add(p2);
criteria.setProjection(plist);
3.QBC按条件查询
criteria.add(条件);条件通过下列格式获取
Restrictions.查询模式(..参数),具体参看下标
| 短语 | 含义 |
| Restrictions.eq | 等于= |
| Restrictions.allEq | 使用Map,使用key/value进行多个等于的判断 |
| Restrictions.gt | 大于> |
| Restrictions.ge | 大于等于>= |
| Restrictions.lt | 小于< |
| Restrictions.le | 小于等于<= |
| Restrictions.between | 对应sql的between子句 |
| Restrictions.like | 对应sql的like子句 |
| Restrictions.in | 对应sql的in子句 |
| Restrictions.and | and 关系 |
| Restrictions.or | or关系 |
| Restrictions.sqlRestriction | Sql限定查询 |
| Restrictions.asc() | 根据传入的字段进行升序排序 |
| Restrictions.desc() | 根据传入的字段进行降序排序 |
4.QBC查询支持链式格式(格式复杂,不推荐使用)
5.QBC聚合函数的使用
所有的聚合函数使用全部划归投影范畴统计数量
Projection condition = Projections.rowCount();求最值
Projection conditionMax = Projections.max("age");Projection conditionMin = Projections.min("min");
求和、求平均
Projection conditionAvg = Projections.avg("age");Projection conditionSum = Projections.sum("age");
最后c.setProjection(…);
6.QBC分组查询
分组划归为投影系列,而不是条件系列Projection p = Projections.groupProperty("分组属性名");
7.查询排序
criteria.addOrder(Order.asc(排序属性名))Order.asc升序
Order.desc降序
8.离线查询
查询条件值是用户输入的,通过页面传递到后台的Action/Servlet将查询的具体条件数据传递到业务层
将查询的具体条件数据传递到数据层
数据层根据查询条件的内容完成查询
离线查询对象DetachedCriteria的目的是在非数据层内对查询的所有条件和投影进行封装,然后将该对象传入数据层,通过getExecutableCriteria,将某个Session对象关联起来,转化为一个可以运行的Criteria对象,然后执行查询
9.HQL与QBC区别
HQL:写HQL语句,所有的查询与投影的设计均使用HQL语句完成QBC:没有任何查询语句,所有的查询与投影的设计靠面向对象的格式设计
如果查询十分简单,推荐HQL
如果查询中具有大量的按条件查询,推荐使用QBC
10.QBCTest
public class QBCApp {
//测试Criteria对象的创建
public void test1(){
Session s = H3Utils.getSession();
//需要转入一个要查询的模型对象.class
Criteria c = s.createCriteria(UserModel.class);
//1.获取0到多条数据
List<UserModel> list = c.list();
//2.获取单条数据
//c.uniqueResult();
for(UserModel um:list){
System.out.println(um);
}
s.close();
}
//查询单个属性
public void test2(){
Session s = H3Utils.getSession();
Criteria c = s.createCriteria(UserModel.class);
//设置查询的结果内容:仅仅查询用户名
//设置要查询的属性
Property p = Property.forName("userName");
//Projection p = Property.;
c.setProjection(p);
List<String> list = c.list();
for(String name : list){
System.out.println(name);
}
s.close();
}
//查询多个属性
public void test3(){
Session s = H3Utils.getSession();
Criteria c = s.createCriteria(UserModel.class);
/*
//设置每一个独立查询的属性
Property p1 = Property.forName("userName");
Property p2 = Property.forName("age");
//将这些属相添加到属性列表对象中,属性列表对象可以保存多个查询属性
ProjectionList pList = Projections.projectionList();
pList.add(p1);
pList.add(p2);
*/
//设置查询的内容为保存了多个属性的属性列表对象
c.setProjection(Projections.projectionList().add(Property.forName("userName")).add(Property.forName("age")));
System.out.println(c.list());
s.close();
}
//测试分页
public void test4(){
Session s = H3Utils.getSession();
Criteria c = s.createCriteria(UserModel.class);
c.setFirstResult(1);
c.setMaxResults(2);
System.out.println(c.list());
s.close();
}
//测试按条件查询
public void test5(){
Session s = H3Utils.getSession();
Criteria c = s.createCriteria(UserModel.class);
//为QBC查询设置查询条件的方式
//c.add(Restrictions.eq("userName", "aa"));
//c.add(Restrictions.lt("age", 34));
//c.add(Restrictions.between("age", 30, 35));
//c.add(Restrictions.like("address", "%bb%"));
//and 不推荐使用
//c.add(Restrictions.and(Restrictions.eq("userName", "jock"), Restrictions.and(lhs, rhs)));
//默认add的条件之间即为and关系
c.add(Restrictions.eq("userName", "aa"));
c.add(Restrictions.le("age", 34));
//or
//c.add(Restrictions.or(条件, 条件2));
List<UserModel> list = c.list();
for(UserModel um:list){
System.out.println(um);
}
s.close();
}
//测试查询排序
public void test6(){
Session s = H3Utils.getSession();
Criteria c = s.createCriteria(UserModel.class);
//设置查询排序
c.addOrder(Order.desc("age"));
c.addOrder(Order.asc("address"));
List<UserModel> list = c.list();
for(UserModel um:list){
System.out.println(um);
}
s.close();
}
//测试聚合函数使用
public void test7(){
Session s = H3Utils.getSession();
Criteria c = s.createCriteria(UserModel.class);
//获取数据总量count
/*
c.setProjection(Projections.rowCount());
Object obj = c.uniqueResult();
System.out.println(obj);
*/
c.setProjection(Projections.max("age"));
Object obj = c.uniqueResult();
System.out.println(obj);
s.close();
}
//测试分组
public void test8(){
Session s = H3Utils.getSession();
Criteria c = s.createCriteria(UserModel.class);
Projection p = Projections.groupProperty("age");
Projection p2 = Projections.rowCount();
ProjectionList plist = Projections.projectionList();
plist.add(p);
plist.add(p2);
c.setProjection(plist);
List<Object[]> list = c.list();
for(Object[] objs:list){
for(Object obj:objs){
System.out.print(obj+"\t");
}
System.out.println();
}
s.close();
}
//测试离线查询
public void test9(){
//表现层
Integer age = 15;
Integer age2 = 60;
DetachedCriteria dc = DetachedCriteria.forClass(UserModel.class);
dc.add(Restrictions.ge("age", age));
dc.add(Restrictions.le("age", age2));
//--------------------------------------
//业务层
//--------------------------------------
//数据层
Session s = H3Utils.getSession();
//使用Session对象关联一个DetachedCriteria就可以使其转化为一个可以用于查询的Criteria对象
Criteria c = dc.getExecutableCriteria(s);
List<UserModel> list = c.list();
for(UserModel um: list){
System.out.println(um);
}
s.close();
}SQLQuery(了解)
可以用于执行原生SQL该对象的主要目的是为了执行配置文件中声明的命名查询
使用XML语法规则<![CDATA[*****]]>控制SQL语句中出现的与XML冲突的错误符号
<![CDATA[from TeacherModel where teacherName = :name]]>
Session管理(了解)
可以将Session对象绑定到当前线程中,使用当前线程管理Session的生命周期七..Hibernate对象状态(重点)
1.对象的状态描述的是同一个对象的不同状态,而不是多个对象
2.对象的状态分为三种
瞬时状态:瞬时对象 TO不具有OID,不受Hibernate控制
持久化状态:持久化对象 PO
具有OID,受Hibernate控制
托管状态:托管对象 DO
具有OID,不受Hibernate控制
3.对象状态切换
切换状态不会产生全新的对象,仅仅指Hibernate与对象之间的关系发生了变化TO: 应用程序new出来的对象就是TO(不能为其赋值OID)
为DO设置OID为null,可以将DO转换为TO(特殊)
PO: 添加,删除,修改,查询(按照OID查询get,load,QBC,HQL,SQLQuery)
DO: 曾经受Hibernate控制,但是此时Session关闭以后,被控制的对象转换为DO
为TO对象赋值OID,TO转换为DO
八.一级缓存(重点)
1.缓存的作用
临时存放数据的空间,并不是真实数据的存放位置,但是与真实数据拥有一一对应的关系为了加速查询,才有了缓存,如果从缓存中能够获取到数据,就不从真实存放数据的地方获取
2.Hibenrate缓存的种类共两类
一级缓存二级缓存(后期研究)
3.Hibernate的一级缓存
Hibernate的一级缓存是存在于Session对象内部的不同的Session对象对应不同的一级缓存空间
4.一级缓存空间的验证
一级缓存确实存在,而且是绑定Session对象的5.load与get的区别(重点)
A.是否延迟加载get操作在执行时立即执行查询,load操作执行时不执行查询,当访问OID之外的属性时候才执行查询,load是延迟加载的,get方法是立即加载的
可以通过配置中的属性lazy设置该对象是否延迟加载,默认为true,如果设置为false表明不支持延迟加载
<class name="cn.itcast.h3.api.UserModel" table="tbl_user" lazy="false">
B.读取不存在的OID数据
get返回null对象
load范围异常,表明该OID对应的对象不存在
C.加载的对象格式
get返回的是原始对象
load返回代理对象,所以模型不能声明为final修饰,否则将没有该效果,同时lazy也不能为false
查询快照
一级缓存的刷新

九.关联关系
一.关联关系
一对一一对多
多对多
转化为Java模型
在本模型中描述关系,如果对一,描述对象,如果对多,描述集合
二.一对多关联关系
1.构造表
两张表:老师和学生表,学生表保存老师数据的外键2.制作模型
老师模型中声明学生的Set集合学生模型中声明老师的对象
3.配置hbm
老师端声明set学生端声明many-to-one
4.将所有资源注册入cfg.xml
到此模型设计结束两边的配置如果只配置一方,也可以使用
配置在老师端:可以通过老师找到学生,但是不能通过学生找到老师
配置在学生端:可以通过学生照到老师,但是不能通过老师找到学生
TeacherModel.xml(一方)
<hibernate-mapping> <class name="cn.itcast.h3.one2many.TeacherModel" table="tbl_teacher"> <id name="uuid"> <generator class="native"/> </id> <property name="name"/> <property name="nick"/> <!-- 一名老师对应对名学生 --> <!-- 描述一对多关系 --> <!-- set:描述对应关系的集合 --> <!-- set:name:设置为当前模型对应的关系集合对象名 --> <!-- cascade:设置级联关系,save-update:级联添加 --> <set name="students" cascade="save-update"> <!-- 定义关联关系字段 --> <!-- key:描述对应的关联关系字段 --> <!-- key:column:具体的外键字段名 ,该字段在对应的关联关系表中声明--> <key column="teacherUuid"/> <!-- 声明对应的模型 及其对应关系--> <!-- one-to-many:描述对应关系 --> <!-- one-to-many:class:描述对应的模型类 --> <one-to-many class="cn.itcast.h3.one2many.StudentModel"/> </set> </class> </hibernate-mapping>
StudentModel.xml(多方)
<hibernate-mapping> <class name="cn.itcast.h3.one2many.StudentModel" table="tbl_student"> <id name="uuid"> <generator class="native"/> </id> <property name="name"/> <property name="className"/> <!-- 多名学生对应一名老师 --> <!-- 描述多对一关系 --> <!-- 定义关联关系 --> <!-- many-to-one:描述关联关系多对一 --> <!-- many-to-one:name:配置关联关系属性 --> <!-- many-to-one:class:配置关联关系对应的模型类 --> <!-- many-to-one:column:具体的外键字段名 ,该字段在多方表中声明--> <many-to-one cascade="save-update" name="teacher" column="teacherUuid" class="cn.itcast.h3.one2many.TeacherModel" /> </class> </hibernate-mapping>
三.添加操作
1.单独添加:同普通操作
2.同时添加:
相互绑定关系,然后所有对象同时save,此时可以将对象保存,同时关联关系伴随着建立3.级联添加
通过配置cascade=”save-update”可以保存当前对象的同时,将所关联的所有对象不管是什么状态,全部保存进去级联Test
//测试一对多
public class One2ManyApp {
//测试单独添加一个老师和单独添加一个学生
public void test1(){
Session s = H3Utils.getSession();
Transaction t = s.beginTransaction();
/*
//创建一个老师对象
TeacherModel tm = new TeacherModel();
tm.setName("李若亮");
tm.setNick("Jock");
s.save(tm);
*/
StudentModel sm = new StudentModel();
sm.setName("张三");
sm.setClassName("0213JY");
s.save(sm);
t.commit();
s.close();
}
//测试同时添加老师的和学生
public void test2(){
Session s = H3Utils.getSession();
Transaction t = s.beginTransaction();
TeacherModel tm = new TeacherModel();
tm.setName("李若亮2");
tm.setNick("Jock2");
StudentModel sm = new StudentModel();
sm.setName("张三2");
sm.setClassName("0213JY2");
StudentModel sm2 = new StudentModel();
sm2.setName("张三3");
sm2.setClassName("0213JY3");
//建立学生和老师的关系
sm.setTeacher(tm);
sm2.setTeacher(tm);
//建立老师和学生的关系
Set<StudentModel> students = new HashSet<StudentModel>();
students.add(sm);
students.add(sm2);
tm.setStudents(students);
//保存数据
s.save(tm);
s.save(sm);
s.save(sm2);
//保存sm对象时,检测到了many-to-one的配置,发现了students这个属性是关联关系
//将sm对象中的teacher对象取出来,读取它的OID属性值,将该值,放入到配置中column对应字段上
//最终执行:update 学生 set column字段名= 关联关系对象的OID where 自己的OID字段名 = 当前模型的OID值
t.commit();
s.close();
}
//测试级联添加老师的和学生
public void test3(){
Session s = H3Utils.getSession();
Transaction t = s.beginTransaction();
TeacherModel tm = new TeacherModel();
tm.setName("aaaa");
tm.setNick("aaaa");
StudentModel sm = new StudentModel();
sm.setName("bbbb");
sm.setClassName("bbbb");
StudentModel sm2 = new StudentModel();
sm2.setName("张三5");
sm2.setClassName("0213JY5");
//建立学生和老师的关系
sm.setTeacher(tm);
//sm2.setTeacher(tm);
//建立老师和学生的关系
Set<StudentModel> students = new HashSet<StudentModel>();
students.add(sm);
//students.add(sm2);
tm.setStudents(students);
//仅仅保存老师数据,想保存时将对应的学生数据也保存了
//此时当前对象关联了瞬时对象,抛出异常,必须在保存对象前将关联的对象一起保存,这种操作叫做级联添加
//将配置set元素中添加属性cascasde="save-update"
//s.save(tm);
//单独添加一个学生
s.save(sm);
//当前保存sm,级联到sm的teacher对象tm
//tm对象那边还设置有级联,它又级联到了sm2对象
t.commit();
s.close();
}小结:
添加:
单独添加,没有特殊之处同时添加,必须先绑定关系,然后同时添加
如果添加时,没有将全部对象进行save,仅仅对其中某一部分进行save,抛出关联TO对象异常
解决方案:添加配置级联添加 cascade=”save-update”
删除:
1.单独删除,删除多方时,没有特殊之处2.单独删除一方,先将其对应关联对象的所有外键设置为null,然后删除(外键字段可否为空)
同时删除,设置级联删除 cascade=”delete,…”设置后,被关联对象也将被删除
注意:如果删除时,不使用get方法查询,而是new出一个老师对象,什么现象?
老师对象中是否包含学生的集合对象?该集合中没有真实的学生数据,会产生级联,但是没有数据被用于级联
3.开发现象:(参看图解)
用户关联了10个订单
用户要求修改个人数据,使用Struts2将数据加载到页面上
通过 struts2收集页面数据后,直接对该数据update

4.问题:如果没有设置cascade=”save-update”,修改老师数据,使用new创建,会不会将学生的信息影响到,此时关联数据不受影响
5.孤子删除
在多方数据中,如果外键关联不存在关联关系,此种数据无法被引用,称为孤儿数据
删除这种数据:cascade = “delete-orphan”
孤儿删除应该根据业务进行添加,而不是必须的
6.关系的双向维护问题:设置inverse=”true”使设置方失去关系维护权,此时操作将不再对关系进行维护
实用:通常设置一对多关系中的一方对象失去管理维护权,交由多方进行关系维护
问题:cascade=”save-update”
7.cascade与inverse
cascade只负责级联操作时的对象级联,被级联的TO->PO,DO->PO
inverse只负责关系维护,inverse=”false”表示该对象在关联关系中具有关系维护能力
inverse=”false”表示该对象在关联关系中不具有关系维护能力
//测试单独删除
@Test
public void test4(){
Session s = H3Utils.getSession();
Transaction t = s.beginTransaction();
//删除学生
//1.new一个学生的Model,删除(几乎不会用)
//2.先将这个对象查询出来
/*
StudentModel sm = (StudentModel) s.get(StudentModel.class, 2L);
s.delete(sm);
*/
//删除老师
//查询出对应的老师
/*没有配置级联删除
Hibernate: update tbl_student set teacherUuid=null where teacherUuid=?
Hibernate: delete from tbl_teacher where uuid=?
*/
/*将所有的外键设置为null
Hibernate: update tbl_student set teacherUuid=null where teacherUuid=?
当查询老师信息时,所有的学生信息伴随着查询出来了,在set集合中每一个对象都有自己的OID,这个OID就是删除依据
Hibernate: delete from tbl_student where uuid=?
Hibernate: delete from tbl_student where uuid=?
最后删除老师信息,以OID为删除依据
Hibernate: delete from tbl_teacher where uuid=?
*/
TeacherModel tm = (TeacherModel) s.get(TeacherModel.class, 1L);
s.delete(tm);
//------研究sm对象读取时的数据加载策略---------
//select 所有的property from 由类名找到表名 where id中配置的column(name) = 你传递的 OID
//System.out.println(sm);
/*发现teacher属性是关联数据
如果要访问teacher数据
执行以下SQL
select 由teacher找到的class中的对应配置文件中的所有property from 由teacher找到的class中对应配置
文件中的table where 由teacher找到的class中的对应配置文件中的id的column(name) = 由所提供的OID查询
出的关联的many-to-one关系中配置的column字段的值*/
//System.out.println(sm.getTeacher());
t.commit();
s.close();
}
//测试new出的对象与查询出的对象删除的现象差异
public void test5(){
Session s = H3Utils.getSession();
Transaction t = s.beginTransaction();
TeacherModel tm = new TeacherModel();
tm.setUuid(1L);
tm.setStudents(new HashSet<StudentModel>());
s.delete(tm);
t.commit();
s.close();
}
//测试孤子删除
public void test6(){
Session s = H3Utils.getSession();
Transaction t = s.beginTransaction();
//获取老师信息
TeacherModel tm = (TeacherModel) s.get(TeacherModel.class, 1L);
//获取学生信息
StudentModel sm = (StudentModel) s.get(StudentModel.class, 2L);
//断开关系:此时关系维护了两次,老师对象与学生对象都参与了关系维护(后面解决)
//Hibernate: update tbl_student set name=?, className=?, teacherUuid=? where uuid=?
sm.setTeacher(null);
//Hibernate: update tbl_student set teacherUuid=null where teacherUuid=? and uuid=?
// remove tm.getUuid sm.getUuid
tm.getStudents().remove(sm);
//设置了孤儿删除后
//Hibernate: update tbl_student set teacherUuid=null where teacherUuid=? and uuid=?
//上面的SQL是由Set集合中remove对象生成
//Hibernate: delete from tbl_student where uuid=?
//上面的SQL是由cascade="delete-orphan"生成的
t.commit();
s.close();
}
//测试关联关系中的双向维护
//测试该程序需要将孤儿删除拿掉
public void test7(){
Session s = H3Utils.getSession();
Transaction t = s.beginTransaction();
//关系断开时,同一个的操作被两个不同的SQL语句执行了
TeacherModel tm = (TeacherModel) s.get(TeacherModel.class, 1L);
StudentModel sm = (StudentModel) s.get(StudentModel.class, 3L);
//断开关系
//此时关系维护受双方影响,双方都在进行关系维护,为了避免关系维护的重复性,让其中一方不具有关系维护的能力
//设置inverse="true",在设置级联的位置
tm.getStudents().remove(sm);
//sm.setTeacher(null);
t.commit();
s.close();
}四.多对多关联关系
1.模型搭建
表:两张实体表+一张关系表模型:两边都声明存放对方模型的Set集合
配置:两边都配置set,格式一样
配置自己对应的集合对象名
配置关系表名
配置自己的外键名称
配置关联关系为多对多
配置关联关系模型
配置关联关系模型的外键名称
将资源添加到cfg.xml
2.添加操作
单独添加:同单表普通操作同时添加:注意相互绑定关系
级联添加:通常由失去关系维护权的一方发起级联
3.级联删除
单独删除:通常用具有关系维护权的一方发起同时删除:从不具有关系维护权的一方删除,由于级联操作,被关联的对象也被删除,而被关联对象具有关系维护权,所以又被关联对象进行关系维护,他们负责删除关系,然后删除被关联对象,然后删除发起方的数据
TeacherModel.hbm.xml
<hibernate-mapping> <class name="cn.itcast.h3.many2many.TeacherModel" table="tbl_tea"> <id name="uuid"> <generator class="native"/> </id> <property name="name"/> <property name="nick"/> <!-- 配置老师对学生的多对多 --> <!-- set:描述多对多模型 --> <!-- set:name:模型中的集合对象名 --> <!-- set:table:多对多关系表名 --> <!-- 多对多操作中,通常设置一方具有关系维护权,另一方失去关系维护权,根据需求,设置:老师失去维护权 --> <set name="students" table="tbl_tea_stu" cascade="delete" inverse="true"> <!-- key:描述对应关系的外键 --> <!-- key:column:多对多关系中对应的外键名称 --> <key column="teacherUuid"/> <!-- many-to-many:关联关系为多对多 --> <!-- many-to-many:class:多对多关系中对应模型的实体类 --> <!-- many-to-many:column:对应模型在关系表中对应的外键名称 --> <many-to-many column="studentUuid" class="cn.itcast.h3.many2many.StudentModel" /> </set> </class> </hibernate-mapping>
StudentModel.hbm.xml
<hibernate-mapping> <class name="cn.itcast.h3.many2many.StudentModel" table="tbl_stu"> <id name="uuid"> <generator class="native"/> </id> <property name="name"/> <property name="className"/> <set name="teachers" table="tbl_tea_stu"> <key column="studentUuid"/> <many-to-many column="teacherUuid" class="cn.itcast.h3.many2many.TeacherModel" /> </set> </class> </hibernate-mapping>
hibernate集合映射inverse和cascade详解
http://www.cnblogs.com/amboyna/archive/2008/02/18/1072260.html
五.多表关联查询
一.多表关联查询
OID数据查询+OGN数据查询方式***Model sm = s.get(***.class,uuid);
sm.getTeacher().getUuid()
HQL数据查询方式
s.createQuery(“from TeacherModel”);
QBC数据查询方式
s.createCriteria(TeacherModel.class):
本地SQL查询方式
略
二.命名约定
老师对学生一对多查询老师数据时,每个老师数据中包含有学生的数据集合
称老师的数据对象为:主数据
称学生的数据集合为:主关联数据
查询学生数据时,每个学生数据中包含有老师的数据对象
称学生的数据对象为:从数据
称老师的数据对象为:从关联数据
三.实体参数查询
1.HQL查询
在查询时,条件可以写成实体参数格式from StudentModel where teacher = ?
上面的HQL语句中需要的参数是一个对象,因此需要使用实体参数
q.setEntity(0,object);
实体参数对象object必须是一个PO或者DO,必须拥有OID
2.QBC查询
使用实体参数必须是一个PO或者DO,必须拥有OID如果想不使用OID进行查询,可以使用关联对象名.属性名的格式进行条件查询,必须使用别名格式
c.createAlias("teacher","t_name");
c.add(Restrictions.eq("t_name.teacherName", "张三丰"));
3.多态查询
四.HQL多表关联查询(重点)
6种HQL语句的形态(老师数据4个 学生数据40 其中有一个老师没有关联学生数据 其他三个老师关联10个学生)内连接:from TeacherModel tm [inner] join tm.students
//[教师] 姓名: 李若亮 , 绰号: Jock[学生] 姓名: 张三 , 年龄: 20 , 职业技能: Java
数据总量:从表被关联的数据总量30
数据模型:主数据(延迟加载关联数据)+主关联数据
迫切内连接:from TeacherModel tm [inner] join fetch tm.students
数据总量:从表被关联的数据总量30
数据模型:主数据(含关联数据)
隐式内连接:from TeacherModel
数据总量:主表数据总量4
数据模型:主数据(延迟加载关联数据)
左外连接:from TeacherModel tm left [outer] join tm.students
数据总量:从表被关联的数据总量+主表未被关联数据总量31
数据模型:主数据(延迟加载)+主关联数据
迫切左外连接:from TeacherModel tm left [outer] join fetch tm.students
数据总量:从表被关联的数据总量+主表未被关联数据总量31
数据模型:主数据(含关联数据)
右外连接:from TeacherModel tm right [outer] join tm.students
数据总量:从表的数据总量40
数据模型:主数据(延迟加载)+主关联数据
五.QBC多表关联查询
支持模式:两种隐式样内连接与左外连接(JOIN)
通过c.setFetchModel(关联数据对象名,FetchModel.常量);
默认为:SELECT,可以设置为JOIN
十.前面重要知识总结
1. 一级缓存
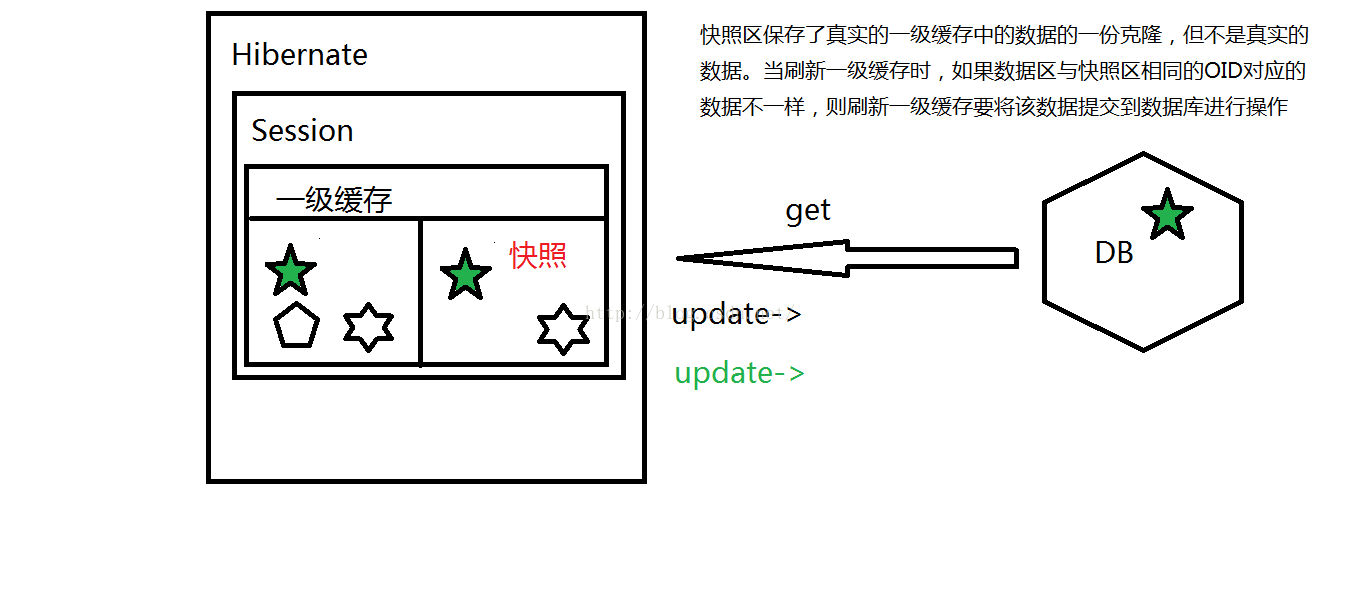
作用:H3存放数据的区域结构划分:
数据区:真正的数据存储空间(SAVE,UPDATE,DELETE,LOAD,GET,HQL,QBC…)
快照区:用于判定是否生成CUD语句
H3完成了将用户的数据和操作转换成SQL语句,并发送给数据库
Save:将save的对象放入数据区,然后在快照区标示这个数据要insert
Update:检测有没有OID,将update的对象放入数据区,然后再快照区标示这个数据update
Delete: 检测有没有OID,将delete的对象放入数据区,然后再快照区标示这个数据delete
Load/get:将读取的数据放入数据区,然后在快照区保存一份该数据的克隆数据
Load/get读取后的数据发生修改,仅修改数据区的数据
HQL/QBC/SQLQuery:将读取的数据放入数据区,然后在快照区保存一份该数据的克隆数据
最后一步:当一级缓存刷新时,根据数据域与快照区比对的结果,确认是否生成何种SQL语句
生成后的SQL语句仅仅是发送到数据库端,(如果再次刷新,将第二次刷新生成的SQL语句发送到数据库端),直到事务提交操作完成时,由数据库将保存的所有执行序列执行
2. 一对多/多对多
描述数据库表间关系一对多,一方设置set,多方设置many-to-one,这两个配置不是要求必须同时出现的
表结构设计:
一对多:多方添加一方的外键
多对多:设置中间关系表,保存多对多双方的外键
模型设计:
只要当前模型对应多个就配置Set,否则配置对象Object
配置:
一对多一方:配置set 使用class表明对应的模型,key中的column描述外键关系
一对多多方:配置many-to-one使用lass表明对应的模型,column描述外键关系
多对多配置时,两边配置格式相同,配置的设置对应:
配置set使用key的column描述自身的外键关系,使用many-to-many描述对应关系为多对多,使用many-to-many中的class描述对应的模型,使用many-to-many中的column描述对应模型在关系表中的外键关系,在set元素上使用table声明具体使用的关系表
3. cascade与inverse
cascade设计的原始需求:H3所能操作的对象必须受H3控制,当操作了一个对象具有关联关系,且该对象保存了关联关系数据时,被操作对象通过各种操作(save,delete,update)完成了转换成PO的过程,但是该对象内部保存的关联关系数据,却没有转换成PO,此时必须设置一种方式,将原始对象转换PO时,关联对象也转换成PO,此工作可以通过cascade完成。基于cascade设置,可以决定完成了转换PO后的关联数据进行的操作(save-update,delete,delete-orphan)。inverse设计的原始需求:由于关联关系不可能发生在独立的对象上,那么在操作对象时,如果具有关联关系的对象双方在进行操作数据的同时都对外键进行操作,会造成操作重复,为了避免该操作执行的过于频繁,设定一种机制,保障关系维护不重复进行,靠inverse完成。
实用:
一对多中,一方设置关系维护权丧失
多对多种,根据业务需求设置
4. 多表关联查询:HQL与QBC均可以按照OID进行查询,如果使用实体参数,依据OID查询
多表关联查询:HQL与QBC都可以使用其他数据进行查询5. HQL多表关联查询的6条SQL语句
格式:from 模型 别名 [关联方式] 别名.被关联属性名30 inner join
30 inner join fetch
4 [隐式内连接:from模型]
31 left outer join
31 left outer join fetch
40 right outer join
十一,数据抓取策略
前面研究了数据查询时查找主数据和从数据的现象From TeacherModel tm join tm.students
From StudentModel sm join sm.teacher
研究:查询的数据都是主数据中包含主关联数据和从数据中包含从关联数据
本章研究关联数据的加载策略
fetch:用于控制进行关联查询时,产生的SQL语句
lazy:用于控制进行关联查询时,被关联数据的加载策略
fetch取值范围:select / subselect / join
lazy取值范围:true / false / extra
主关联数据加载策略
QBC查询实际上是先将所有的数据OID查询出来,然后根据OID再进行查询
即N+1次查询
fetch:
select:普通查询语句
subselect:子查询语句(select X from X where Xin(1,2,3,4))
join:左外连接查询(QBC+OID)
lazy:
false:立即加载
true:延迟加载
extra:超级延迟加载(如果仅获取数据总量就执行数据总量的统计语句)
1.fetch=select lazy=false
获取主数据:
查询主数据一条SQL
查询主关联数据N条SQL
获取主关联数据集合中数据数量
不执行SQL语句
获取主关联数据集合中数据的具体数据
不执行SQL语句
2.fetch=select lazy=true
获取主数据:
查询主数据一条SQL
获取主关联数据集合中数据数量(A)
按需执行查询主关联数据的SQL语句X
获取主关联数据集合中数据的具体数据(B)
按需执行查询主关联数据的SQL语句X
说明:A操作与B操作,无论谁先执行,另一个都将不执行
3.fetch=select lazy=extra
获取主数据:
查询主数据一条SQL
获取主关联数据集合中数据数量(A)
按需执行查询主关联数据count(uuid)的SQL语句Y
获取主关联数据集合中数据的具体数据(B)
按需执行查询主关联数据的SQL语句X
说明:先执行A操作,再执行B操作,会按需执行Y和X语句
先执行B操作,再执行A操作,会按需仅执行X语句
4.fetch=subselect lazy=false
获取主数据
查询主数据一条SQL
查询主关联数据一条SQL
获取主关联数据集合中数据数量
不执行SQL语句
获取主关联数据集合中数据的具体数据
不执行SQL语句
5.fetch=subselect lazy=true
获取主数据
查询主数据一条SQL
获取主关联数据集合中数据数量(A)
查询主关联数据执行一条SQL语句Z
获取主关联数据集合中数据的具体数据(B)
查询主关联数据执行一条SQL语句Z
说明:A操作与B操作,无论谁先执行,另一个都将不执行
6.fetch=subselect lazy=extra
获取主数据
查询主数据一条SQL
获取主关联数据集合中数据数量(A)
按需执行查询主关联数据count(uuid)的SQL语句Y
获取主关联数据集合中数据的具体数据(B)
查询主关联数据执行一条SQL语句Z
说明:先执行A操作,再执行B操作,会按需执行Y和Z语句(N+1)
先执行B操作,再执行A操作,会按需仅执行Z语句(1)
7.fetch=join 如果使用的HQL查询,那么fetch=join等同于fetch=select
8.fetch=join 如果使用的QBC查询,那么lazy失效,此时使用左外连接查询
9.fetch=join 如果使用的OID查询,那么lazy失效,此时使用左外连接查询
从关联数据加载策略
fetch:
select:
join:
lazy:
false:立即加载
proxy:交由被关联对象自身控制lazy
1.fetch=select lazy=false
获取从数据
查询从数据一条SQL
查询从关联数据N条SQL
获取从关联具体数据
不执行SQL语句
2.fetch=select lazy=proxy
获取从数据
查询从数据一条SQL
如果关联对象自身lazy=false,执行查询从关联数据N条SQL
获取从关联具体数据
如果关联对象自身lazy=true,按需执行查询从关联数据的SQL语句
3.使用HQL查询,fetch=join 等同于fetch=select
4.使用OID查询,fetch=join 生成左外连接查询,此时lazy失效
抓取策略优化
在进行抓取策略设置时,如果一次性产生多条完成相同任务的SQL语句,此可以根据业务需要进行优化,将同一任务下的多条SQL语句合并成多干次完成,通过设置batch-size=”数字”,注意该值不是越大越好
容易混淆:
A:6条SQL语句:可以用于控制加载主数据或从数据的SQL
B:3*3和2*2配置:用于控制加载主关联数据或从关联数据的SQL和加载策略
如果A策略已经将关联数据加载完毕,那么B策略失效
如果A策略是延迟加载,此时B策略才生效
十二.二级缓存
1.缓存意义:
加快查询速度,将要查询的数据的克隆放置在一个临时空间内,查询时访问这个临时空间,而不去访问原始数据存放的位置2.二级缓存的意义:弥补一级缓存的不足
一级缓存缺点:Session范围的缓存数据,不同的Session不共享数据二级缓存优点:有效弥补一级缓存间数据不共享的缺点,在Session间进行数据共享
3.二级缓存实现技术:
H3一级缓存是H3自带的,内置H3二级缓存是使用第三方技术设置,常用ehcache
一级缓存是Session级别的缓存
二级缓存是SessionFactory级别的缓存
4.缓存中的数据要求
适合加入二级缓存的数据大量访问
很少被修改的数据(100次修改,100亿访问)
不是很重要的数据,允许出现偶尔并发的数据
不会被并发访问的数据
参考数据
不适合加入二级缓存的数据
经常被修改的数据
财务数据,绝对不允许出现并发
与其他应用共享的数据
5.H3二级缓存配置格式
1.导入ehcache的jar包(3个)2.在hibernate.cfg.xml中开启使用二级缓存
<property name="cache.use_second_level_cache">true</property>
3.指定二级缓存供应商
<property name="cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
4.制作ehcache.xml(Ehcache的配置文件)
参看PPT(略)
5.设置加入二级缓存的数据
方式一:写入到hbm.xml
在class元素中加入配置,实现当前模型加入二级缓存
<span style="font-size:14px;"><class name="cn.itcast.h3.relation.vo.TeacherModel" table="tbl_teacher" lazy="false">
<!-- 设置当前类模型加入二级缓存 -->
<cache usage="read-write"/>
<id name="uuid" column="uuid">。。。。</span>
在set集合中加入配置,实现当前模型的关联数据加入二级缓存
<span style="font-size:14px;"><set name="students">
<cache usage="read-write"/>
<key column="teacherUuid"/>
<one-to-many class="cn.itcast.h3.relation.vo.StudentModel"/>
</set></span>
方式二:写入到cfg.xml
<!-- 配置二级缓存中的数据 -->
<!-- 对象缓存设置格式 -->
<class-cache usage="read-write" class="cn.itcast.h3.relation.vo.TeacherModel"/>
<class-cache usage="read-write" class="cn.itcast.h3.relation.vo.StudentModel"/>
<!-- 集合缓存设置格式 :配置的是某个类的某个集合属性加入二级缓存-->
<collection-cache usage="read-write" collection="cn.itcast.h3.relation.vo.TeacherModel.students"/>
6.验证二级缓存存在性
使用同一个SessionFactory开启不同的Session一个Session读取数据,执行SQL
另一个Session读取前面已经读取的数据,不执行SQL,直接从二级缓存中获取该数据
7.读取操作对二级缓存的影响
OID查询:可以将数据加入二级缓存,也可以从二级缓存中读取数据HQL查询:可以将数据加入二级缓存,但不从二级缓存中读取数据
QBC查询:可以将数据加入二级缓存,但不从二级缓存中读取数据
原因:H3基于OID管理对象,所以提供OID查询获取二级缓存的方式,HQL与QBC查询仅仅是基于你的操作生成SQL语句,然后传递到数据库服务器进行执行,H3不具有执行SQL语句的能力
问题:将年龄大于50岁的所有人的信息加入到了二级缓存,使用HQL/QBC查询年龄在45到55岁之间的
总结:所有的查询操作都可以将查询结果放入二级缓存,但是只能使用load/get方法读取二级缓存中已经存在的数据
8.增加操作对二级缓存的影响
执行添加操作:1.H3监控到执行save方法
2.判断主键生成策略是不是需要提供主键OID
3.由数据库生成了下面一个添加数据的OID给H3
4.获取的OID赋值给了TO,TO此时受H3控制->PO
5.提交事务
6.关闭Session
执行二级缓存读取时,如果save的数据进入了二级缓存,万一数据库事务提交失败,数据库中没有数据,二级缓存中有该数据,出错。
9.修改和删除操作对二级缓存的影响
修改操作与删除操作对二级缓存产生影响
说明:删除操作对二级缓存的影响会造成该数据从二级缓存中删除掉,此时再次读取二级缓存中的该数据,如果获取不到,才算影响二级缓存。
10.二级缓存的存储区域
四大区域
类对象缓存区域
存储H3查询的散装数据,基于二级缓存专用的ID进行识别
关联关系集合对象缓存区域
存储的是对应的集合中每个数据的二级缓存专用ID数组,需要数据时,使用该ID去类对象缓存区中查找具体的数据
更新标识时间戳区域
服务于类对象缓存区,如果执行了DML语句对某个模型进行了修改,那么此区域将记 录哪些模型发生了修改,下次访问这类数据时,强制进行一次更新(查询)
查询缓存区域
首先在配置中开启使用查询缓存:
<property name="cache.use_query_cache">true</property>
查询缓存区查询出的数据绑定SQL语句
Select * from tbl_user 数据A对应
Select * from tbl_user where … 数据B对应
基于查询缓存绑定SQL语句,此种操作使用时一定要小心,否则二级缓存瞬间崩溃
为避免上述问题的出现,查询缓存使用时,强制要求每次声明使用查询缓存
Query.setCacheable(true);
14:30:00 2分
14:31:22 访问 最大生命周期3分
14:30:00 5分 最大10分
14:32:00
14:35:00
14:37:00
应该是14:40干掉
14:30:30检测,60秒检测一次
14:40:30
从14:40:00-14:40:30之间该数据

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树
- [原创]java局域网聊天系统