Python 下载网络mp4视频资源
2015-06-29 17:18
363 查看
最近着迷化学, 特别是古代的冶炼技术,感叹古人的聪明。




春秋时期的炼铁方法是块炼铁,即在较低的冶炼温度下,将铁矿石固态还原获得海绵铁,再经锻打成的铁块。冶炼块炼铁,一般采用地炉、平地筑炉和竖炉3种。铁矿石在温度较高的炼铁炉中高温还原并渗碳,得到含碳达到3~4%的液态生铁。战国初期,我国已掌握了脱碳、热处理技术方法,发明了韧性铸铁。
在中国,钢铁的总产量在唐代年产已达到1200吨,宋朝为4700吨,明朝最多达到4万吨。在13世纪,中国是世界上最大的铁的生产国和消费国,直到17世纪仍保持着这一领先地位。从汉代到明朝,中国人不仅在数量上处于领先地位,而且还拥有世界上最先进的钢铁冶炼技术。
铸铁脱碳钢 将含碳3~4%的低硅铸铁器在氧化气氛中加热,在适当条件下,特别是厚度不大的情况下,可以避免石墨的形成。早期炼铁温度较低,含硅量低,石墨析出较慢,有利于脱碳,使制造韧性铸铁的工艺发展成为铸铁脱碳成钢的方法。这种钢称为铸铁脱碳钢,这类钢板可加工成的铁镞、环首刀。
炒钢 向熔化的生铁鼓风,同时进行搅拌促使生铁中的碳氧化。用这种方法可将生铁制成熟铁,再经过渗碳锻打成钢。也可有控制地把生铁含碳量炒到需要的程度,再锻制成钢制品。这种钢中含有的硅酸铁夹杂物成分比较一致而数量较少。炒钢技术始于西汉末年,到东汉已相当普及。江苏出土新莽残剑,徐州出土建初二年(77)五十炼钢剑,山东临沂苍山出土的永初六年(112)三十炼钢刀等所用的原料都属于这一类型。曹操(155~220)在《内诫令》提到“百炼利器”,孙权(182~252)有以“百炼”命名的宝刀。初步可以认为百炼钢是用炒钢反复叠打变形,细化晶粒和夹杂物而成的,甚至可以用不同含碳钢材复合组成。炼数大致相当于反复折叠锻打后最后的层数。炼数增多,表明加工量加大,晶粒和夹杂进一步细化,质量提高。炒钢技术的发明是炼钢史上的一次革命。
来源:http://wenku.baidu.com/view/7c9bd28d84868762caaed5ed.html
哎! 就在查找古人是如何冶炼金属、铸造钱币、分离金属元素时,找到了这个大连理工大学讲的“化学与社会”公开课。讲的很有调理,让读者很容易理解,越看越觉的这个公开课是一个经典课程,想收藏页面怕以后链接会失效,所以决定把这个经典的公开课下载下来。
那么问题来了,下载网页嵌入的flash 视频,不是容易的事。试了网上好多视频下载插件(DownLoad Helper 、 VDownLoad嗅探器、flv视频下载、ImovieBox)也么有分析出网页的链接视频。好吧,我使用F12 调试网页工具查看网络响应,发现有type=video/mp4,然后另存为就可以了,但问题是课程有近100个,不可能一个个打开链接,查看网页Network点击视频让其加载出type=video/mp4 类型,再另存为。这样太麻烦了。开动脑筋想用程序直接把视频下载链接分析出来,然后保存在本地。
通过PyQuery可以获取所有课程的视频播放地址

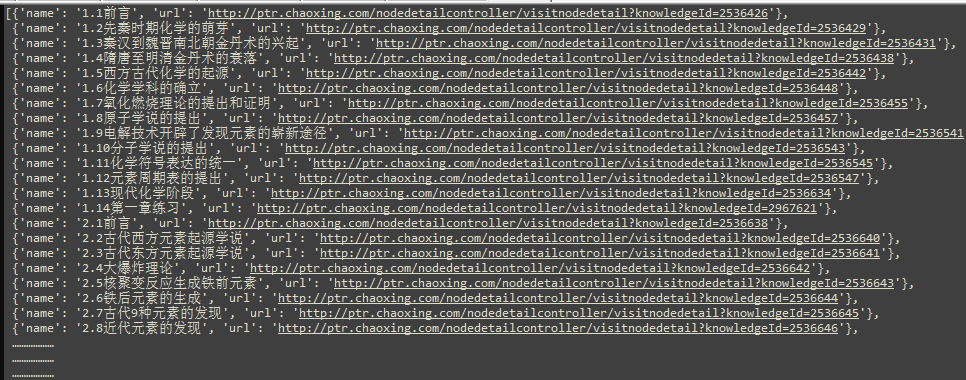

然而我们发现,每一个视频地址页面都会请求一个类似于这样的地址:http://ptr.chaoxing.com/ananas/status/************?k=&_dc=1476770383911
该地址返回一个带有视频mp4路径的Json格式字符串。其中filename为当前视频课程的名称,http为(standard)标准清晰视频 sd.mp4, httphd为(high)高清视频 hd.mp4
进一步的分析我们发现,在该地址请求之前有一个类型为Document的html加载出页面内容区域的html flash播放器
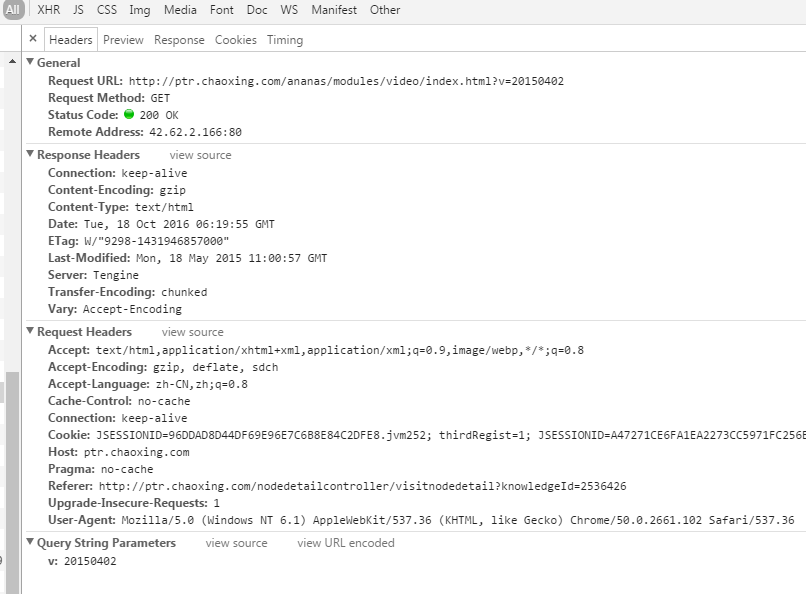
当这个播放器加载完成通过all-classes.js?v=20141027:1的Ajax请求http://ptr.chaoxing.com/ananas/status/************?k=&_dc=***。查看网页源代码,查找status后的这一串字符串发现这个字符串应该是视频播放的objectID

在iframe标签的data属性里面。试着复制一个视频的objectID去模拟请求http://ptr.chaoxing.com/ananas/status/************发现居然成功了!不知道此方法是否也使用其他flash视频下载。
这样下载课程视频的思路就出来了:在第一步获取下载链接,通过每一个视频页面源码中的objectID去请求http://ptr.chaoxing.com/ananas/status/************ 获取下载地址。然后下载视频教程。so easy!
通过PyQuery 获取视频页面中的objectID
在视频下载中遇到了些小问题,可参考:https://www.zhihu.com/question/41132103
完整代码:
通过pyinstaller打包
查看:



春秋时期的炼铁方法是块炼铁,即在较低的冶炼温度下,将铁矿石固态还原获得海绵铁,再经锻打成的铁块。冶炼块炼铁,一般采用地炉、平地筑炉和竖炉3种。铁矿石在温度较高的炼铁炉中高温还原并渗碳,得到含碳达到3~4%的液态生铁。战国初期,我国已掌握了脱碳、热处理技术方法,发明了韧性铸铁。
在中国,钢铁的总产量在唐代年产已达到1200吨,宋朝为4700吨,明朝最多达到4万吨。在13世纪,中国是世界上最大的铁的生产国和消费国,直到17世纪仍保持着这一领先地位。从汉代到明朝,中国人不仅在数量上处于领先地位,而且还拥有世界上最先进的钢铁冶炼技术。
铸铁脱碳钢 将含碳3~4%的低硅铸铁器在氧化气氛中加热,在适当条件下,特别是厚度不大的情况下,可以避免石墨的形成。早期炼铁温度较低,含硅量低,石墨析出较慢,有利于脱碳,使制造韧性铸铁的工艺发展成为铸铁脱碳成钢的方法。这种钢称为铸铁脱碳钢,这类钢板可加工成的铁镞、环首刀。
炒钢 向熔化的生铁鼓风,同时进行搅拌促使生铁中的碳氧化。用这种方法可将生铁制成熟铁,再经过渗碳锻打成钢。也可有控制地把生铁含碳量炒到需要的程度,再锻制成钢制品。这种钢中含有的硅酸铁夹杂物成分比较一致而数量较少。炒钢技术始于西汉末年,到东汉已相当普及。江苏出土新莽残剑,徐州出土建初二年(77)五十炼钢剑,山东临沂苍山出土的永初六年(112)三十炼钢刀等所用的原料都属于这一类型。曹操(155~220)在《内诫令》提到“百炼利器”,孙权(182~252)有以“百炼”命名的宝刀。初步可以认为百炼钢是用炒钢反复叠打变形,细化晶粒和夹杂物而成的,甚至可以用不同含碳钢材复合组成。炼数大致相当于反复折叠锻打后最后的层数。炼数增多,表明加工量加大,晶粒和夹杂进一步细化,质量提高。炒钢技术的发明是炼钢史上的一次革命。
来源:http://wenku.baidu.com/view/7c9bd28d84868762caaed5ed.html
哎! 就在查找古人是如何冶炼金属、铸造钱币、分离金属元素时,找到了这个大连理工大学讲的“化学与社会”公开课。讲的很有调理,让读者很容易理解,越看越觉的这个公开课是一个经典课程,想收藏页面怕以后链接会失效,所以决定把这个经典的公开课下载下来。
那么问题来了,下载网页嵌入的flash 视频,不是容易的事。试了网上好多视频下载插件(DownLoad Helper 、 VDownLoad嗅探器、flv视频下载、ImovieBox)也么有分析出网页的链接视频。好吧,我使用F12 调试网页工具查看网络响应,发现有type=video/mp4,然后另存为就可以了,但问题是课程有近100个,不可能一个个打开链接,查看网页Network点击视频让其加载出type=video/mp4 类型,再另存为。这样太麻烦了。开动脑筋想用程序直接把视频下载链接分析出来,然后保存在本地。
1. 获取链接地址
查看:http://ptr.chaoxing.com/course/2533204.html 源码,课程的list写在了clas=“p20” ul里面的li标签列表中通过PyQuery可以获取所有课程的视频播放地址
d = self.pq('http://ptr.chaoxing.com/course/2533204.html')
DomTree = d('.p20 ul li a')
for my_div in DomTree.items():
URL = 'http://ptr.chaoxing.com' + my_div.attr('href') # 课时detail URL
l = my_div.find('.l').html() # 课时章节NO
r = my_div.find('.r').html() # 课时Name
self.LessonList.append({'url': URL, "name": l + r})2. 分析下载地址
打开一个课程视频播放时,都会XHR请求加载一个链接,该链接的内容是:然而我们发现,每一个视频地址页面都会请求一个类似于这样的地址:http://ptr.chaoxing.com/ananas/status/************?k=&_dc=1476770383911
该地址返回一个带有视频mp4路径的Json格式字符串。其中filename为当前视频课程的名称,http为(standard)标准清晰视频 sd.mp4, httphd为(high)高清视频 hd.mp4
进一步的分析我们发现,在该地址请求之前有一个类型为Document的html加载出页面内容区域的html flash播放器
当这个播放器加载完成通过all-classes.js?v=20141027:1的Ajax请求http://ptr.chaoxing.com/ananas/status/************?k=&_dc=***。查看网页源代码,查找status后的这一串字符串发现这个字符串应该是视频播放的objectID
在iframe标签的data属性里面。试着复制一个视频的objectID去模拟请求http://ptr.chaoxing.com/ananas/status/************发现居然成功了!不知道此方法是否也使用其他flash视频下载。
这样下载课程视频的思路就出来了:在第一步获取下载链接,通过每一个视频页面源码中的objectID去请求http://ptr.chaoxing.com/ananas/status/************ 获取下载地址。然后下载视频教程。so easy!
3. 下载视频
通过上一步分析地址,已经知道获取flash视频objectID并Ajax 请求http://ptr.chaoxing.com/ananas/status/************ 就能获取视频地址。这一步我们就下载视频。通过PyQuery 获取视频页面中的objectID
def getVideo(self, url):
'''
获取视频
'''
d = self.pq(url)
DomTree = d("iframe")
jsonData = DomTree.attr('data')
objectid = json.loads(jsonData)['objectid'] # 获取下载资源视频的对象
downloadUrl = self.pq('http://ptr.chaoxing.com/ananas/status/' + objectid) # 获取下载资源的URL
jsonData = json.loads(downloadUrl.html())['httphd'] # 在这里,我们要下载的是高清视频
return jsonData在视频下载中遇到了些小问题,可参考:https://www.zhihu.com/question/41132103
完整代码:
# -*- coding: UTF8 -*-
from pyquery import PyQuery as pq
import sys, os
import json
import requests
from contextlib import closing
class SaveVideo():
LessonList = []
def __init__(self):
pass
# 获取课时的列表
def getLesson(self):
try:
# 该网站请求时必须带上User-Agent
d = self.pq('http://ptr.chaoxing.com/course/2533204.html')
DomTree = d('.p20 ul li a')
for my_div in DomTree.items():
URL = 'http://ptr.chaoxing.com' + my_div.attr('href') # 课时detail URL
l = my_div.find('.l').html() # 课时章节NO
r = my_div.find('.r').html() # 课时Name
self.LessonList.append({'url': URL, "name": l + r})
except Exception as e:
print(e)
if (len(self.LessonList) > 0):
if not os.path.exists('./Video'):
os.makedirs('./Video')
for lesson in self.LessonList:
video = self.getVideo(lesson['url'])
if video:
self.downloadVideo(video, lesson['name'])
print('完成下载!!!')
def getVideo(self, url):
'''
获取视频
'''
d = self.pq(url)
DomTree = d("iframe")
jsonData = DomTree.attr('data')
video=''
try:
objectid = json.loads(jsonData)['objectid'] # 获取下载资源视频的对象
downloadUrl = self.pq('http://ptr.chaoxing.com/ananas/status/' + objectid) # 获取下载资源的URL
video = json.loads(downloadUrl.html())['httphd'] # 在这里,我们要下载的是高清视频
except:
pass
return video
def pq(self, url, headers=None):
'''
将PyQuery 请求写成方法
'''
d = pq(url=url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'})
return d
def downloadVideo(self, url, file_name=''):
'''
下载视频
:param url: 下载url路径
:return: 文件
'''
with closing(requests.get(url, stream=True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
file_D='./Video/' + file_name + '.mp4'
if(os.path.exists(file_D) and os.path.getsize(file_D)==content_size):
print('跳过'+file_name)
else:
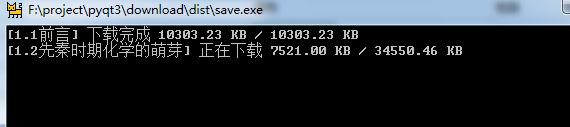
progress = ProgressBar(file_name, total=content_size, unit="KB", chunk_size=chunk_size, run_status="正在下载",fin_status="下载完成")
with open(file_D, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
progress.refresh(count=len(data))
'''
下载进度
'''
class ProgressBar(object):
def __init__(self, title, count=0.0, run_status=None, fin_status=None, total=100.0, unit='', sep='/',
chunk_size=1.0):
super(ProgressBar, self).__init__()
self.info = "[%s] %s %.2f %s %s %.2f %s"
self.title = title
self.total = total
self.count = count
self.chunk_size = chunk_size
self.status = run_status or ""
self.fin_status = fin_status or " " * len(self.statue)
self.unit = unit
self.seq = sep
def __get_info(self):
# 【名称】状态 进度 单位 分割线 总数 单位
_info = self.info % (
self.title, self.status, self.count / self.chunk_size, self.unit, self.seq, self.total / self.chunk_size,
self.unit)
return _info
def refresh(self, count=1, status=None):
self.count += count
# if status is not None:
self.status = status or self.status
end_str = "\r"
if self.count >= self.total:
end_str = '\n'
self.status = status or self.fin_status
print(self.__get_info(), end=end_str)
if __name__ == '__main__':
C = SaveVideo()
C.getLesson()
sys.exit()通过pyinstaller打包
import sys if __name__ == '__main__': from PyInstaller import __main__ params = ['-F','-c','--noupx', '--icon=favicon.ico', 'save.py'] __main__.run(params)
查看:
4:分享课程视频
已经将视频打包分享到云盘中,有兴趣的可以在这 下载
相关文章推荐
- 一个简单的http请求
- iOS开发工具-网络封包分析工具Charles
- DBN深信度网络
- 虚拟机桥接网络设置(转)
- 基于IHttpAsyncHandler的实时大文件传送器
- 初识贝叶斯网络
- HttpWebRequest
- HttpClient get post
- 网络通信
- ZigBee/ZWave注意了:LoRa远距离、低功耗网络技术悄然发展
- HTTP协议详解
- android HttpPost传参数的一些总结
- 利用Fiddler模拟恶劣网络环境
- ejabberd中的http反向推送
- Android中Socket通信之TCP与UDP传输原理
- C#基于socket模拟http请求的方法
- APK动态加载框架 https://github.com/singwhatiwanna/dynamic-load-apk
- Linux 上网络监控工具 ntopng 的安装
- 各种语言使用HTTP Request
- CentOS 安装iftop 监控网络流量