使用Talend Open Studio将数据分步从oracle导入到hive中
2015-06-29 13:52
621 查看
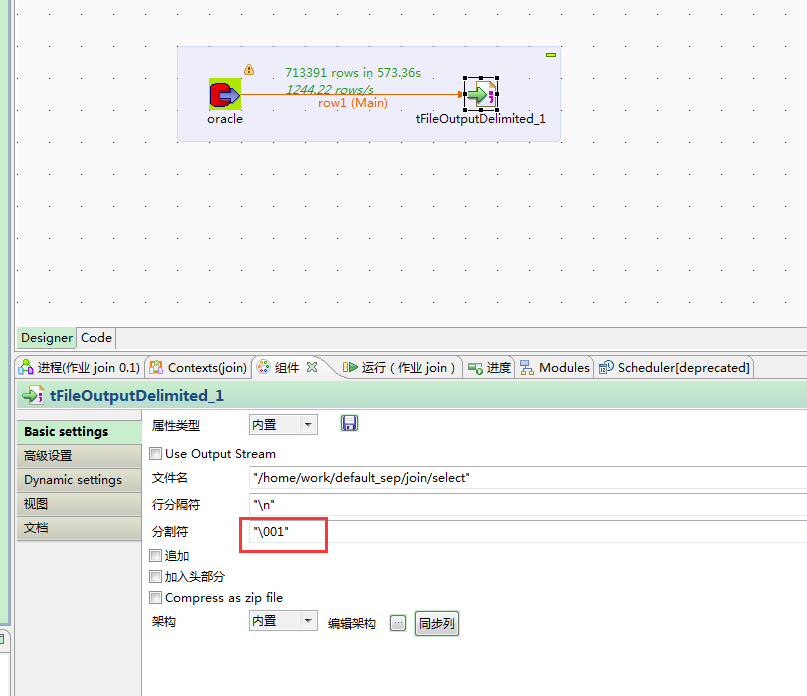
先使用Tos建立模型,将Oracle中的数据导入到本地:
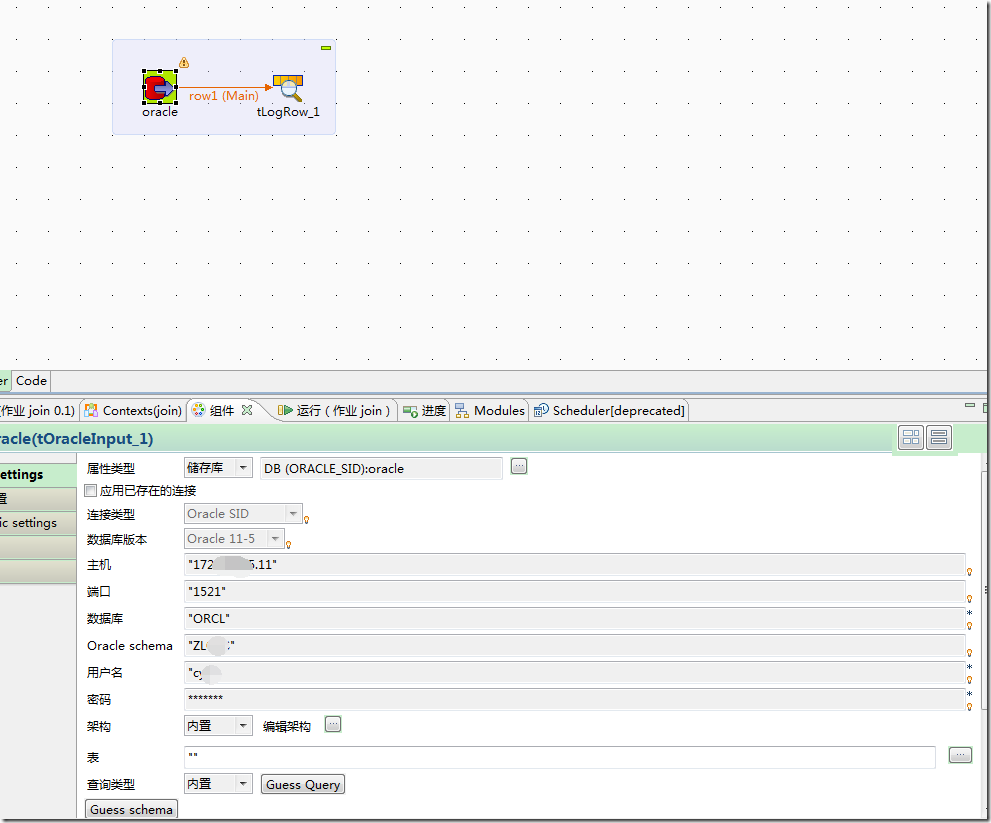
build job后,形成独立可以运行的程序:
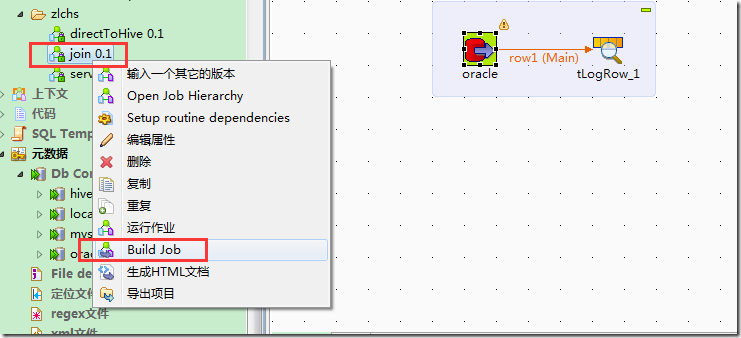
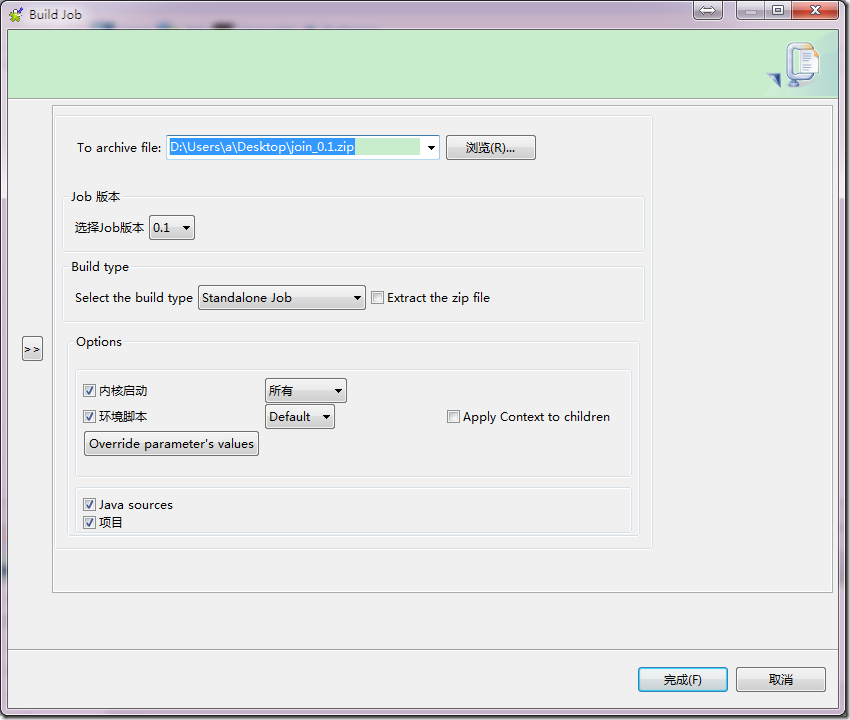
将生成的zip文件,上传到hadoop集群上,有hive环境的机器上:
这样就得到了SQL语句执行的结果,存放在user_activity2中。
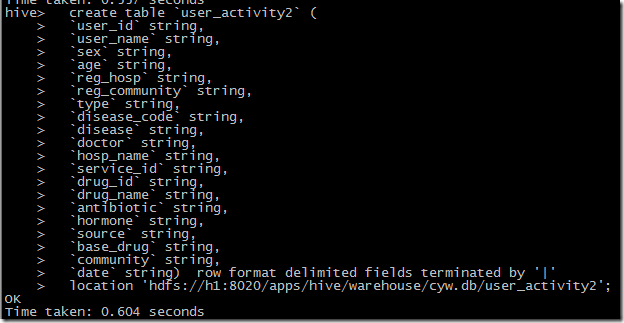
hive建表语句:
将数据导入到hive表中:load data local inpath './user_activity2' into table user_activity2;
查询语句:
加入分区字段:
默认的字段分隔符为ascii码的控制符\001,建表的时候用fields terminated by '\001',如果要测试的话,造数据在vi 打开文件里面,用ctrl+v然后再ctrl+a可以输入这个控制符\001。按顺序,\002的输入方式为ctrl+v,ctrl+b。以此类推。
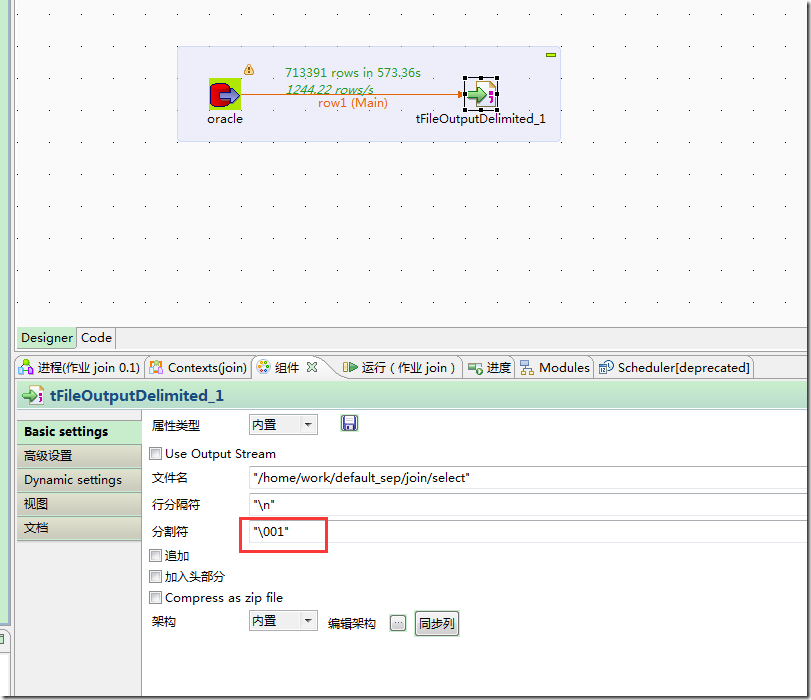
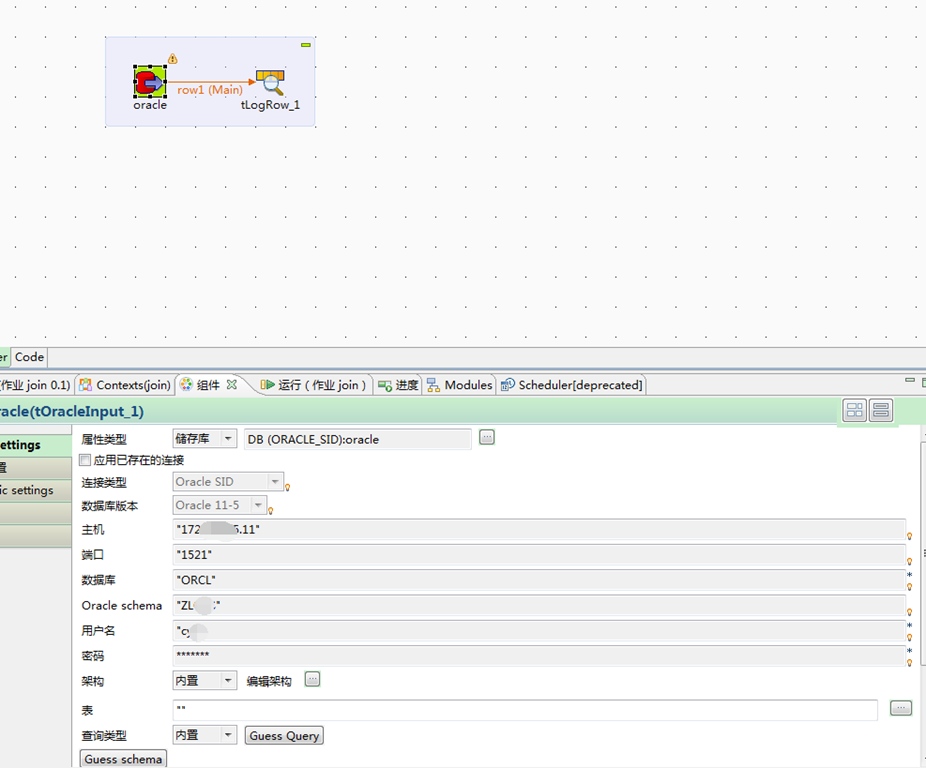
build job后,形成独立可以运行的程序:

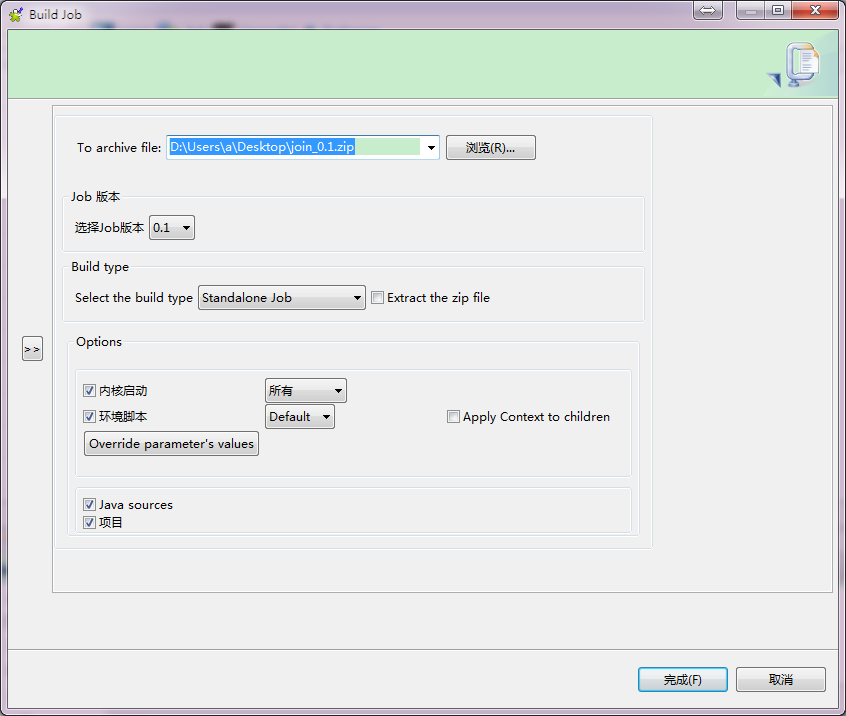
将生成的zip文件,上传到hadoop集群上,有hive环境的机器上:
[hive@h1 work]$ ls file.zip jobInfo.properties join lib [hive@h1 work]$ cd join/ [hive@h1 join]$ ls bigdatademo items join_0_1.jar join_run.bat join_run.sh src user_activity2 [hive@h1 join]$ pwd /home/work/join [hive@h1 join]$ ls bigdatademo items join_0_1.jar join_run.bat join_run.sh src user_activity2 [hive@h1 join]$ pwd /home/work/join [hive@h1 join]$ ./join_run.sh > user_activity2 2>&1 &
这样就得到了SQL语句执行的结果,存放在user_activity2中。
hive建表语句:
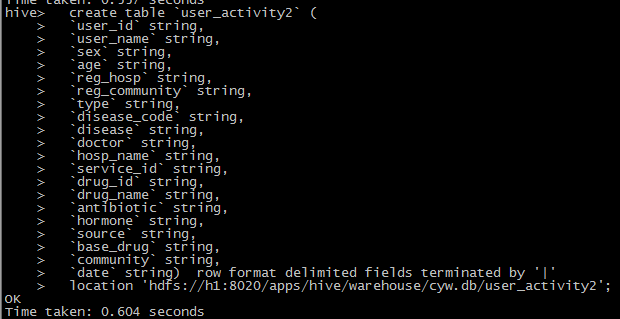
hive> show create table user_activity2; OK CREATE TABLE `user_activity2`( `user_id` string, `user_name` string, `sex` string, `age` string, `reg_hosp` string, `reg_community` string, `type` string, `disease_code` string, `disease` string, `doctor` string, `hosp_name` string, `service_id` string, `drug_id` string, `drug_name` string, `antibiotic` string, `hormone` string, `source` string, `base_drug` string, `community` string, `date` string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://h1:8020/apps/hive/warehouse/cyw.db/user_activity2' TBLPROPERTIES ( 'transient_lastDdlTime'='1435547544') Time taken: 0.288 seconds, Fetched: 31 row(s)
将数据导入到hive表中:load data local inpath './user_activity2' into table user_activity2;
hive> show tables; OK Time taken: 0.794 seconds hive> use cyw; OK Time taken: 0.256 seconds hive> show tables; OK user_activity user_activity2 Time taken: 0.136 seconds, Fetched: 2 row(s) hive> load data local inpath './user_activity2' into table user_activity2; Loading data to table cyw.user_activity2 Table cyw.user_activity2 stats: [numFiles=1, totalSize=216927483] OK Time taken: 10.898 seconds hive> select * from user_activity2; OK F805418B-335F-4CA3-A209-7C9655148146 余泽英 2 47 成都高新区合作社区卫生服务中心 合作 1 急性支气管炎 谭万龙 成都高新区合作社区卫生服务中心 1E972231-C65A-4CE3-9233-8EA1B18058DE 灭菌注射用水 d875aacf-4723-4777-91ec-12d63732b58f 0 0 其他 合作 2014-02-27 F805418B-335F-4CA3-A209-7C9655148146 余泽英 2 47 成都高新区合作社区卫生服务中心 合作
查询语句:
select a.个人id,
b.姓名,
b.性别,
round((sysdate - b.出生日期) / 365) as fage,
b.建档单位,
replace(replace(replace(b.建档单位, '高新区'), '社区卫生服务中心'),
'成都') 建档社区,
1 as ftype,
a.问题编码,
a.问题名称,
a.处理医生,
c.机构名,
a.服务记录id,
f.名称,
f.id 药品ID ,
f.抗生素,
f.激素类药,
case when f.药品来源 is null then '其他' else f.药品来源 end 药品来源,
f.基药分类,
replace(replace(replace(c.机构名, '高新区'), '社区卫生服务中心'),'成都') 诊疗社区,
to_char(a.发现日期,
'yyyy-mm-dd') 诊疗日期
from ZLCHS.个人问题列表 a,
ZLCHS.个人信息 b,
ZLCHS.服务活动记录 c,
(select d.事件id, e.名称, e.id, h.药品来源, h.基药分类, g.抗生素, g.激素类药
from ZLCHS.个人费用记录 d, ZLCHS.收费项目目录 e, ZLCHS.药品规格 h, ZLCHS.药品特性 g
where d.收费项目id = e.id
and d.收据费目 in ('西药费', '中草药费', '中成药费')
and h.药品id(+) = e.id
and h.药名id = g.药名id) f
where a.个人id = b.id(+)
and a.服务记录id = c.id(+)
and a.服务记录id = f.事件id(+)加入分区字段:
CREATE TABLE `user_activity`( `user_id` string, `user_name` string, `sex` string, `age` string, `reg_hosp` string, `reg_community` string, `type` string, `disease_code` string, `disease` string, `doctor` string, `hosp_name` string, `service_id` string, `drug_id` string, `drug_name` string, `antibiotic` string, `hormone` string, `source` string, `base_drug` string, `community` string, `date` string) PARTITIONED BY ( `dt` string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://h1:8020/apps/hive/warehouse/cyw.db/user_activity' TBLPROPERTIES ( 'transient_lastDdlTime'='1435559269') Time taken: 0.252 seconds, Fetched: 33 row(s)
默认的字段分隔符为ascii码的控制符\001,建表的时候用fields terminated by '\001',如果要测试的话,造数据在vi 打开文件里面,用ctrl+v然后再ctrl+a可以输入这个控制符\001。按顺序,\002的输入方式为ctrl+v,ctrl+b。以此类推。

相关文章推荐
- Oracle批量执行SQL文件
- oracle数据库使用之数据查询入门
- oracle数据库使用之数据查询入门
- oracle数据库使用之数据查询入门
- oracle数据库使用之数据查询入门
- DBA成长箴言
- Oracle SQL 优化精萃
- Oracle 11gR2修改服务器端字符集
- C#连接Oracle数据库的方法
- Oracle 数据库命令导入、导出
- 在oracle数据库中如果查询一个数据库中有哪几张表?
- Oracle中 Instr 这个函数
- oracle ORA-01000: maximum open cursors exceeded问题的解决方法
- ORACLE的sign函数和DECODE函数
- oracle代理用户
- oracle数据库敏感操作前创建还原点
- oracle数据快速删除
- oracle数据快速删除
- oracle数据快速删除
- oracle数据快速删除