Apache Drill学习笔记二:Dremel原理(上)
2015-06-14 11:29
871 查看
《Apache Drill学习笔记一:环境搭建和简单试用》提到过Apache Drill是受Google的Dremel系统启发而设计实现的,这出于Google公开于2010年的论文“Dremel
Interactive Analysis of WebScaleDatasets”。为了弄清楚Apache Drill的运行机制,这篇论文是一定要先仔细研读的,否则就只能像我之前那样仅仅将其作为CSV或者JSON的SQL查询工具使用了,而不能真正发挥其强大的性能优势。
简单说Dremel是Google的“交互式”数据分析系统,可以组建成规模上千的集群,处理PB级别的数据。虽然MapReduce也可以处理这样规模的数据,但它所需要的时间相对比较长,适合数据的批处理,而不适合交互式查询的场景,Dremel正是这样的一个有力补充。
Dremel有2个显著特点:
可以在秒级别的时间查询PB级别的数据。
数据模型是嵌套(nested)的。
而这正是其他数据库、查询引擎的痛点所在,也正是我们需要着重了解的地方。
Dremel使用的数据就是我们熟悉的Protocol Buffer格式,但通常情况我们都是作为序列化方法或者在RPC中传输等场景使用,较少用它来存放大量数据。对于没有接触过Protocol Buffer的读者,可以用JSON类比,二者结构很相似,一个不同是Protocol Buffer不支持JSON的map(或者说是dict、hashmap)。
一个Protocol Buffer的
注意的不是数据本身,而是数据的类型,或者说是数据的schema。但从中已经可以看出2个特点:
类型是可以嵌套的。
同一种类型的数据是可以重复(repeated)和可选(optional)的。
对如此复杂的数据做SQL查询看起来是很让人头疼的,我们自然想到先简化一下,从最简单的情况考虑。
这种数据格式用数学方法严格表示是这样的:
看起来有点复杂,但理解起来很容易。t(原文是希腊字母τ,但为了书写方便这里改成英文字母t)是一个数据类型的定义,而.proto文件就是定义一个或多个数据类型。t有两种可能(|和c语言一样是“或”的意思,一种是基本类型dom(如int、string、float等),另一种是使用递归方式定义的,即t可以由其他之前定义好的t组成,就像c中的结构体一样,与结构体不大相同的是,每个包含的t的值可以有多个(*,repeated,类似c中的数组),还可以是可选的(?,optional,之前那个数组可以不包含任何元素)。A1-An是这些t的命名(也就是A1是某个t类型的变量)。其实从这个定义中更容易看出之前总结的2个特点。
现在我们来考虑简单的Protocol Buffer数据,以及如何查询。
这是一个简化的
而
可以看出我们用二维的方式组织数据,但实际是数据在磁盘的地址是一维的,也就是我们需要按某种方式把它拼接成一维的数据。那最基本的方式有两种:
按行存:
按列存:
我们先考虑下对这个表进行
如果是按行存的话,每读一个
而按列存的情况就好很多,只需要找到第一个
那是不是所有情况都需要按列来存数据呢?显然不是。虽然按列读的情况比较多,但写入一般是按行写的,无论是追加、删除、修改,一般都是按行处理的。数据按列存的话,追加时需要把一行数据按字段拆开,分别插入到不同的地方,删除也是一样,修改更加痛苦。因为如果是类似字符串的不定长字段,按行存的话可以以行为单位预留空间,而按列存的话需要以字段为单位预留空间,或者使用更复杂的方法。想一想就要麻烦许多。
数据库往往需要同时照顾到读和写的效率,简单的按行存或者按列存都存在明显的问题(包括下文提到的表join效率等问题),所以往往需要存储复杂的meta数据、添加各类索引、使用各种树型甚至图型结构,来在读和写之间谋得一个平衡点。
而Dremel要轻松一些,因为它被设计成一个查询引擎,即使也有写入功能也不会过多考虑写入的效率,那么显然按列存是合适的。这样即使一张表字段很多,数据量很大,只要记录每个字段的类型以及对应数据的起始地址等少量信息,查起来就游刃有余。所以如果只是用来查一个巨大的二维表的后,并不是很难。
但我们知道,平时使用的数据很难在一张二维表里表达清楚,往往需要多张表,互相还有关联,查询起来就需要各种join。数据量小还好,数据量一大,join效率直线下降,单表select再快也没用,这才是真正棘手的问题。
Dremel的解决方法不是设法提高join的效率,而是换一种思路,使用嵌套的数据解决简单二维表表达能力太弱的缺点。
再拿出之前的
这样的数据如果用二维表来存放一般需要多张才能描述清楚,处理重复字段也比较痛苦,而一个Protocol Buffer类型就可以描述,但在磁盘的实际存放还是要动不少脑筋的。
现在就需要搬出论文里的这张图了:
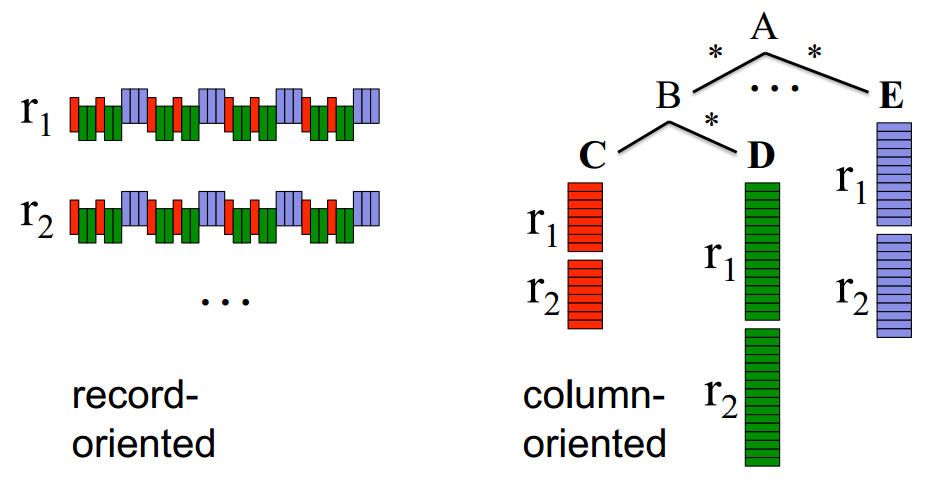
虽然嵌套的数据比之前的二维表更加复杂,还是有按行存和按列存两种基本方法,而且正如我们之前提到的,为了查询效率,我们采用按列存的方法(图中的
我们来准备一些符合
其中
Dremel是这样拆解数据的:
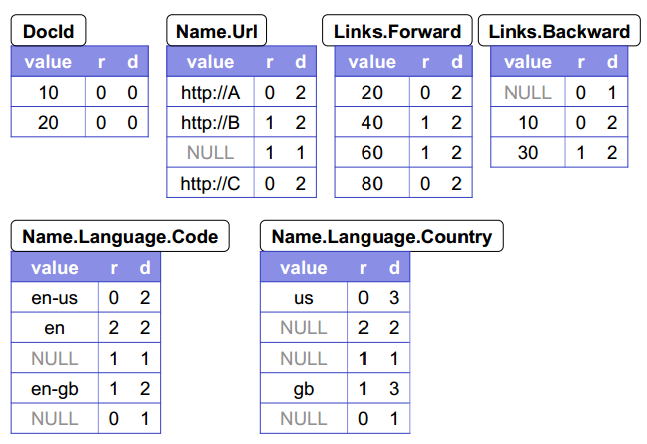
可以看出每个需要存放实际数据的叶子节点都变成了一张二维表,但表中除了字段自身的值。如果是
试想如果去掉上图中
如果
第一个
第二个
这里例子中没有出现多个字段都发生重复的情况,如第二个
之前还有个问题没有回答,为何要记录
如果把图中所有的
那么有了
我们还是假设去掉
读完第一行我们得到了:
第二行是个
第三行又是个
第四行是在第一层也就是
看起来似乎没问题,不过对比原始数据发现第二个
为了解决这个问题,
举例:
对于一般的数据,这个值看起来没什么意义(除了可以区分是否是
Interactive Analysis of WebScaleDatasets”。为了弄清楚Apache Drill的运行机制,这篇论文是一定要先仔细研读的,否则就只能像我之前那样仅仅将其作为CSV或者JSON的SQL查询工具使用了,而不能真正发挥其强大的性能优势。
简单说Dremel是Google的“交互式”数据分析系统,可以组建成规模上千的集群,处理PB级别的数据。虽然MapReduce也可以处理这样规模的数据,但它所需要的时间相对比较长,适合数据的批处理,而不适合交互式查询的场景,Dremel正是这样的一个有力补充。
Dremel有2个显著特点:
可以在秒级别的时间查询PB级别的数据。
数据模型是嵌套(nested)的。
而这正是其他数据库、查询引擎的痛点所在,也正是我们需要着重了解的地方。
数据模型
Dremel使用的数据就是我们熟悉的Protocol Buffer格式,但通常情况我们都是作为序列化方法或者在RPC中传输等场景使用,较少用它来存放大量数据。对于没有接触过Protocol Buffer的读者,可以用JSON类比,二者结构很相似,一个不同是Protocol Buffer不支持JSON的map(或者说是dict、hashmap)。一个Protocol Buffer的
Document.proto文件示例:
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward;
}
repeated group Name {
repeated group Language {
required string Code;
optional string Country;
}
optional string Url;
}
}注意的不是数据本身,而是数据的类型,或者说是数据的schema。但从中已经可以看出2个特点:
类型是可以嵌套的。
同一种类型的数据是可以重复(repeated)和可选(optional)的。
对如此复杂的数据做SQL查询看起来是很让人头疼的,我们自然想到先简化一下,从最简单的情况考虑。
这种数据格式用数学方法严格表示是这样的:
t = dom | <A1:t[*|?], ..., An:t[*|?]>
看起来有点复杂,但理解起来很容易。t(原文是希腊字母τ,但为了书写方便这里改成英文字母t)是一个数据类型的定义,而.proto文件就是定义一个或多个数据类型。t有两种可能(|和c语言一样是“或”的意思,一种是基本类型dom(如int、string、float等),另一种是使用递归方式定义的,即t可以由其他之前定义好的t组成,就像c中的结构体一样,与结构体不大相同的是,每个包含的t的值可以有多个(*,repeated,类似c中的数组),还可以是可选的(?,optional,之前那个数组可以不包含任何元素)。A1-An是这些t的命名(也就是A1是某个t类型的变量)。其实从这个定义中更容易看出之前总结的2个特点。
简单情况
现在我们来考虑简单的Protocol Buffer数据,以及如何查询。这是一个简化的
Document.proto,可以看到它只有一层结构,而且没有
repeated和
optional字段。
message Document {
required int64 DocId;
string Url;
string Country;
int64 Code;
}而
Document的数据就是一张普通的二维表:
| DocId | Url | Country | Code |
|---|---|---|---|
| 10001 | http://1 | America | 10 |
| 10002 | http://2 | America | 20 |
| 10003 | http://3 | China | 30 |
| 10004 | http://4 | America | 40 |
| 10005 | http://5 | Japan | 50 |
| 10006 | http://6 | America | 60 |
| ... | ... | ... | ... |
按行存:
| 10001 | http://1 | America | 10 | 10002 | http://2 | America | 20 | ... |
|---|---|---|---|---|---|---|---|---|
| -> | -> | -> | -> | -> | -> | -> | -> | -> |
| 10001 | 10002 | 1003 | ... | http://1 | http://2 | http://3 | ... |
|---|---|---|---|---|---|---|---|
| -> | -> | -> | -> | -> | -> | -> | -> |
select,如
select Url, Code from Document;
如果是按行存的话,每读一个
Url后,都需要跳到下一个
Url的位置,所有要查出的字段都不是连续存放的。而且因为有字符串这样的非定长字段(如果使用定长的预留空间,又会造成大量的空间浪费),不能通过简单计算就可以得到地址,查起来非常痛苦,效率自然不会很高。
而按列存的情况就好很多,只需要找到第一个
Url和第一个
Code的首地址,然后顺序读取到结尾即可。不仅实现简单,而且磁盘顺序读取好比随机读取要快,加上更容易优化(比如把临近地址的数据预读到内存,连续的同类型数据更容易压缩存放),效率自然不可同日而语。
那是不是所有情况都需要按列来存数据呢?显然不是。虽然按列读的情况比较多,但写入一般是按行写的,无论是追加、删除、修改,一般都是按行处理的。数据按列存的话,追加时需要把一行数据按字段拆开,分别插入到不同的地方,删除也是一样,修改更加痛苦。因为如果是类似字符串的不定长字段,按行存的话可以以行为单位预留空间,而按列存的话需要以字段为单位预留空间,或者使用更复杂的方法。想一想就要麻烦许多。
数据库往往需要同时照顾到读和写的效率,简单的按行存或者按列存都存在明显的问题(包括下文提到的表join效率等问题),所以往往需要存储复杂的meta数据、添加各类索引、使用各种树型甚至图型结构,来在读和写之间谋得一个平衡点。
而Dremel要轻松一些,因为它被设计成一个查询引擎,即使也有写入功能也不会过多考虑写入的效率,那么显然按列存是合适的。这样即使一张表字段很多,数据量很大,只要记录每个字段的类型以及对应数据的起始地址等少量信息,查起来就游刃有余。所以如果只是用来查一个巨大的二维表的后,并不是很难。
但我们知道,平时使用的数据很难在一张二维表里表达清楚,往往需要多张表,互相还有关联,查询起来就需要各种join。数据量小还好,数据量一大,join效率直线下降,单表select再快也没用,这才是真正棘手的问题。
有嵌套数据的情况
Dremel的解决方法不是设法提高join的效率,而是换一种思路,使用嵌套的数据解决简单二维表表达能力太弱的缺点。再拿出之前的
Document.proto:
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward;
}
repeated group Name {
repeated group Language {
required string Code;
optional string Country;
}
optional string Url;
}
}这样的数据如果用二维表来存放一般需要多张才能描述清楚,处理重复字段也比较痛苦,而一个Protocol Buffer类型就可以描述,但在磁盘的实际存放还是要动不少脑筋的。
现在就需要搬出论文里的这张图了:
虽然嵌套的数据比之前的二维表更加复杂,还是有按行存和按列存两种基本方法,而且正如我们之前提到的,为了查询效率,我们采用按列存的方法(图中的
column-oriented)。我们重点关注A、B、C、D、E这些树型关系如何存储。
我们来准备一些符合
Document.proto的简单的数据:
DocId: 10 Links Forward: 20 Forward: 40 Forward: 60 Name Language Code: 'en-us' Country: 'us' Language Code: 'en' Url: 'http://A' Name Url: 'http://B' Name Language Code: 'en-gb' Country: 'gb'
DocId: 20 Links Backward: 10 Backward: 30 Forward: 80 Name Url: 'http://C'
其中
DocId: 10和
DocId: 20是两个
Document。
Dremel是这样拆解数据的:
可以看出每个需要存放实际数据的叶子节点都变成了一张二维表,但表中除了字段自身的值。如果是
repeated字段,则在表中增添行;如果是
optional字段,并且数据中不填充,则用
NULL代替(而不是去掉这一行)。但还出现了
r和
d,这两个又是什么东西,而且为何要记录
NULL呢?
试想如果去掉上图中
r和
d两列,则每个二维表都变成了一个一维表(list),那么我们试图把数据还原回去,
DocId没问题,一定是属于两个
Document的。
Name.Url就出现了问题,因为
Name是
repeated的,我怎么知道这3个
Name.Url是全属于第一个
Document,还是其他情况呢?丢失的信息太多无法还原了。所有我们需要记录每个值是否是重复的以及在哪一层重复的(比如是在第一个
Name的第二个
Code,还是第二个
Name的第一个
Code)。有了这个信息,我们就可以根据之前的记录一个一个往上拼接来还原原始的数据结构。
r就是做这个的。
r是重复层次(Repetition Level),记录该列的值是在哪一个层次上重。
如果
r是0,则表示是第一个(非重复)的元素,如上图中的
DocId,两个DocId都是第一个元素,比较简单。但其他的字段就比较复杂了,如
Name.Language.Code,一共有五行:
en-us是第一个
Document(不同的
Document不算重复,不影响
r和
d的取值,只有
repeated类型的字段才算)里第一个
Name中的第一个
Language里的,重复还没有发生,所以
r是0。
en是第一个
Document里第一个
Name中第二个
Language里的,
Language发生了重复,在/Name/Language层次结构中处于第二层,所以
r是2。
en-gb是第一个
Document里第三个
Name中第一个
Language里的,
Name发生了重复,在/Name/Language层次结构中处于第一层,所以
r是1。
第一个
NULL是第一个
Document里第二个
Name中的,
Name发生了重复,在/Name/Language层次结构中处于第一层,所以
r是1。
第二个
NULL是第二个
Document里第一个
Name中的,没有发生重复,所以
r是0。
这里例子中没有出现多个字段都发生重复的情况,如第二个
Name中的第二个
Language的
Code。如果是这种情况,那么
r取最大的,也就是最近发生重复的字段,这里例子中就是
Language的2。(待验证)
之前还有个问题没有回答,为何要记录
NULL呢?
如果把图中所有的
NULL都去掉,看会发生什么。 拿
Links.Backward举例,去掉第一行的
NULL后,我们读到第一个
Links.Backward,必然认为它是属于第一个
Document的,但实际数据中第一个
Document里没有
Links.Backward,完全搞错了。所以即使是
NULL也必须记录,为了后续的数据知道自己在哪。
那么有了
r后,是否信息就完善了呢?
我们还是假设去掉
d的一列,试图还原数据。
DocId依然没问题,
Name.Url也没问题了,直接看
Name.Language.Country吧:
读完第一行我们得到了:
Document Name Language Country : 'us'
第二行是个
NULL,是在第二层也就是
Language重复的:
Document Name Language Country : 'us'Language
Country : NULL
第三行又是个
NULL,是在第一层也就是
Name重复的:
Document Name Language Country : 'us'Language
Country : NULL
Name
Language
Country : NULL
第四行是在第一层也就是
Name重复的:
Document Name Language Country : 'us'Language
Country : NULL
Name
Language
Country : NULL
Name
Language
Country : 'gb'
看起来似乎没问题,不过对比原始数据发现第二个
Name不只没有
Country,连上层的
Language也没有。也就是单看
Name.Language.Country这个表,还是把数据还原错了。虽然把所有的表都还原出来,然后去掉所有的
NULL以及
NULL上边多余的部分,还是可以准确还原,但如果只是去查询某个字段,难道需要把其他所有字段全部分析一遍吗?另外没有发生重复的字段,具体是
required、
repeated、还是
optional的信息也丢了。(此处似乎还有其他问题)
为了解决这个问题,
d被引入了。
d是定义层次(Definition Level),记录这个值是在哪一层被定义的。需要注意的是如果这个值是
required的,则层数不包括自身,否则如果是
repeated或
optional的,则包括自身。目的主要是区分是否是
required字段(但如何区分只有一行的
repeated和
optional呢?)。
举例:
Document.Links.Backward的
d是2(
Document是0)
Document.Name.Language.Code也是2(因为
Code是
required的,所以不包括它自己)
对于一般的数据,这个值看起来没什么意义(除了可以区分是否是
required字段),因为已经有值了,从根到它自身整条路径必然是存在的,但对于
NULL则不同,
d可以说明这个
NULL是在哪一层定义的,也就是解决我们之前还原
Name.Language.Country数据遇到的问题。
r和
d这两个值还是需要好好理解一下,而且还有一些没弄清楚的细节,以及具体查询的复杂逻辑,只能后续继续学习了。

相关文章推荐
- Apache Drill学习笔记一:环境搭建和简单试用
- linux手动安装apache服务器
- Apache域名自动指向虚拟主机目录
- 使用Apache POI将ppt截屏成png格式(+背景和图片)
- Apache Benchmark修改,支持发送不同数据包
- Exception starting filter struts2 java.lang.NoClassDefFoundError: org/apache/commons/lang3/StringUti
- 用Apache的HTACCESS保护密码
- apache kafkac系列lient发展-java
- ubuntu 安装mysql+apache+php
- Apache Curator入门实战
- Apache Curator入门实战
- 使用Apache的ab工具进行压力测试
- apache2.4 以上的版本,cgi-bin中的文件不能运行。
- Apache Pig的前世今生
- 启用Mac(OS X Yosemite)自带的apache
- Apache Spark Resource Management and YARN App Models
- Web开发在Mac下配置Apache、php、MySQL应该注意的地方(Yosemite10.10.3)
- Apache优化
- 配置php和apache结合,测试php
- Apache Cordova