决策树ID3算法的java实现
2015-06-09 09:01
393 查看
决策树的分类过程和人的决策过程比较相似,就是先挑“权重”最大的那个考虑,然后再往下细分。比如你去看医生,症状是流鼻涕,咳嗽等,那么医生就会根据你的流鼻涕这个权重最大的症状先认为你是感冒,接着再根据你咳嗽等症状细分你是否为病毒性感冒等等。决策树的过程其实也是基于极大似然估计。那么我们用一个什么标准来衡量某个特征是权重最大的呢,这里有信息增益和基尼系数两个。ID3算法采用的是信息增益这个量。
根据《统计学习方法》中的描述,G(D,A)表示数据集D在特征A的划分下的信息增益。具体公式:
G(D,A)=H(D)-H(D|A)。其中H(D)表示数据集D的熵,熵可以用来描述其混乱度,计算公式为
H(D)=
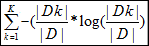
可见对于数据集D而言,|Dk|表示类别为k的数量,其类别越多,越混乱。
而H(D|A)表示数据集D在A的划分下的的不确定性。他们的差也即是信息增益,表示由于特征A使得数据集D的分类的不确定减少的差,所以这个值越大说明A的分类对D越有效,也就是权重越大。
H(D|A)=
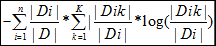
|Dik|表示在特征A中value为i的划分下数据集类别为k的数量。
有了这两个公式,接下来就可以写代码了。这里为了清晰的表示这个结果,采用了xml来输出。由于刚开始学java所以只能即学即用(java和python简直不能比,python写ID3一百行代码妥妥的搞定,java用了将近300行。。。)
算法步骤:
输入:数据集D,特征集A(这里也可以输入一个阀值,如果信息增益小于该阀值就直接作为叶节点,这样可以避免过拟合)
输出:xml文件
1 如果D中的类别是同一类,则作为叶节点,标记为该类Ck
2 如果特征集A中没有特征了,那么作为叶节点,并且用数据集D中类别最多的类作为类标记
3 对D的各个特征求最大信息增益,选择信息增益最大的特征Ag
4 对特征Ag中各个值ai继续对数据集进行分割为Di
5 以Di为数据集,A-Ag为特征集为输入进行1-4步骤
具体代码:
这次除了算法上的理解更加深刻了外,在java上也学到了些关于xml解析,读写等方法。
另外对递归的使用也更加形象些,对于递归一个容易错的点就是函数上的参数,一定要认真对待,要清楚该参数该在什么时候初始化,什么时候被用到。我一开始在第269行上就出现错误了,一开始没有考虑清楚这个next该在什么时候分配,后来发现每次创建节点的时候我们在xml就要创建一个相应的节点用来描述他,所以应该是在for循环里面创建,如果在for外面创建就表示,该特征下的所有值都只有一个element。
当然对于set,map的遍历啥的也更加清晰了。
根据《统计学习方法》中的描述,G(D,A)表示数据集D在特征A的划分下的信息增益。具体公式:
G(D,A)=H(D)-H(D|A)。其中H(D)表示数据集D的熵,熵可以用来描述其混乱度,计算公式为
H(D)=
可见对于数据集D而言,|Dk|表示类别为k的数量,其类别越多,越混乱。
而H(D|A)表示数据集D在A的划分下的的不确定性。他们的差也即是信息增益,表示由于特征A使得数据集D的分类的不确定减少的差,所以这个值越大说明A的分类对D越有效,也就是权重越大。
H(D|A)=
|Dik|表示在特征A中value为i的划分下数据集类别为k的数量。
有了这两个公式,接下来就可以写代码了。这里为了清晰的表示这个结果,采用了xml来输出。由于刚开始学java所以只能即学即用(java和python简直不能比,python写ID3一百行代码妥妥的搞定,java用了将近300行。。。)
算法步骤:
输入:数据集D,特征集A(这里也可以输入一个阀值,如果信息增益小于该阀值就直接作为叶节点,这样可以避免过拟合)
输出:xml文件
1 如果D中的类别是同一类,则作为叶节点,标记为该类Ck
2 如果特征集A中没有特征了,那么作为叶节点,并且用数据集D中类别最多的类作为类标记
3 对D的各个特征求最大信息增益,选择信息增益最大的特征Ag
4 对特征Ag中各个值ai继续对数据集进行分割为Di
5 以Di为数据集,A-Ag为特征集为输入进行1-4步骤
具体代码:
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.XMLWriter;
class Utils{
//用于从文件中获取数据集
public static ArrayList<ArrayList<String>> loadDataSet(String file) throws IOException{
ArrayList<ArrayList<String>> dataSet=new ArrayList<ArrayList<String>>();
FileInputStream fis=new FileInputStream(file);
InputStreamReader isr=new InputStreamReader(fis,"UTF-8");
BufferedReader br=new BufferedReader(isr);
String line="";
line=br.readLine();
while((line=br.readLine())!=null){
String[] words=line.split(",");
ArrayList<String> data=new ArrayList<String>();
for(int i=0;i<words.length;i++){
data.add(words[i]);
}
dataSet.add(data);
}
br.close();
isr.close();
fis.close();
return dataSet;
}
//用于从文件中获取特征
public static ArrayList<String> loadFeature(String file) throws IOException{
FileInputStream fis=new FileInputStream(file);
InputStreamReader isr=new InputStreamReader(fis,"UTF-8");
BufferedReader br=new BufferedReader(isr);
String[] line=br.readLine().split(",");
ArrayList<String> feature=new ArrayList<String>();
for(int i=0;i<line.length-1;i++){
feature.add(line[i]);
}
br.close();
isr.close();
fis.close();
return feature;
}
//用于获得数据集中的类别列表
public static ArrayList<String> getClassList(ArrayList<ArrayList<String>> dataSet){
ArrayList<String> classList=new ArrayList<String>();
int length=dataSet.get(0).size();
for(ArrayList<String> data:dataSet){
String label=data.get(length-1);
classList.add(label);
}
return classList;
}
//返回数据集中的特征数
public static int featureNum(ArrayList<ArrayList<String>> dataList){
int len=dataList.get(0).size()-1;
return len;
}
// public static void writeToXML(String fileName) throws IOException{
// Document document = DocumentHelper.createDocument();
// Element root = document.addElement("DecisionTree");
// Element outlook=root.addElement("outlook");
// outlook.addAttribute("value","sunny");
// Element humidity1=outlook.addElement("humidity");
// humidity1.addAttribute("value","high");
// humidity1.addText("no");
// Element humidity2=outlook.addElement("humidity");
// humidity2.addAttribute("value","normal");
// humidity2.addText("yes");
//
// XMLWriter writer=new XMLWriter(new FileWriter(fileName));
// writer.write(document);
// writer.close();
// }
//用于获得数据集中第index列的map映射,方便后续的遍历value和计算熵
public static Map<String,Integer> getSubMap(ArrayList<ArrayList<String>> dataSet,int index){
int total=dataSet.size();
Map<String,Integer> subMap=new HashMap();
for(ArrayList<String> data:dataSet){
String lable=data.get(index);
if(subMap.get(lable)==null){
subMap.put(lable,1);
}else{
subMap.put(lable,subMap.get(lable)+1);
}
}
return subMap;
}
//打印map,用于debug的时候
public static void showMap(Map<String,Integer> map){
for(Map.Entry<String,Integer> entry:map.entrySet()){
System.out.println(entry.getKey()+":"+entry.getValue());
}
}
//求熵
public static double getEntropy(ArrayList<ArrayList<String>> dataSet,int index){
int total=dataSet.size();
Map<String,Integer> subMap=getSubMap(dataSet,index);
double entropy=0;
for(Map.Entry<String,Integer> entry:subMap.entrySet()){
double temp=entry.getValue()*1.0/total;
entropy+=temp*(Math.log(temp)/Math.log(2));
}
return -entropy;
}
//求信息增益最大的分割点
public static String bestFeatureSplit(ArrayList<ArrayList<String>> dataSet,ArrayList<String> featureList){
int length=dataSet.get(0).size();
double totalEntropy=getEntropy(dataSet,length-1);
int featureNum=dataSet.get(0).size()-1;
int index=-1;
double maxInfoGain=-1;
for(int i=0;i<featureNum;i++){
double entropy=getEntropy(dataSet,i);
Map<String,Integer> map=getSubMap(dataSet,i);//获得该特征下的map
ArrayList<String> lableList=new ArrayList<String>();
double entropySum=0;
for(Map.Entry<String,Integer> entry:map.entrySet()){//这里的Di就是map中的特征的value值
Map<String,Integer> subMap=new HashMap();
for(ArrayList<String> data:dataSet){
if(data.get(i).compareTo(entry.getKey())==0){
if(subMap.get(data.get(length-1))==null){
subMap.put(data.get(length-1),1);
}else{
subMap.put(data.get(length-1),subMap.get(data.get(length-1))+1);
}
}
}
double x=0;
for(Map.Entry<String,Integer> subEntry:subMap.entrySet()){
double temp=subEntry.getValue()*1.0/entry.getValue();
x+=temp*(Math.log(temp)/Math.log(2));
}
entropySum+=-x*(entry.getValue())/dataSet.size();
}
entropySum=totalEntropy-entropySum;
if(entropySum>maxInfoGain){
index=i;
maxInfoGain=entropySum;
}
}
return featureList.get(index);
}
//分割数据集,index为特征的下标
public static ArrayList<ArrayList<String>> splitDataSet(ArrayList<ArrayList<String>> dataSet,int index,String value){
ArrayList<ArrayList<String>> subDataSet=new ArrayList<ArrayList<String>>();
for(ArrayList<String> data:dataSet){
if(data.get(index).compareTo(value)==0){
ArrayList<String> temp=new ArrayList<String>();
for(int i=0;i<data.size();i++){
if(i!=index){
temp.add(data.get(i));
}
}
subDataSet.add(temp);
}
}
return subDataSet;
}
//list-》map
public static Map<String,Integer> arrayToMap(ArrayList<String> list){
Map<String,Integer> map=new HashMap();
for(String word:list){
if(map.get(word)==null){
map.put(word,1);
}else{
map.put(word,map.get(word)+1);
}
}
return map;
}
//求label中某个数量最多的类别
public static String major(ArrayList<String> labelList){
Map<String,Integer> map=arrayToMap(labelList);
int max=0;
String label="";
for(Map.Entry<String,Integer> entry:map.entrySet()){
if(entry.getValue()>max){
label=entry.getKey();
}
}
return label;
}
public static Set<String> getValueFromDataSet(ArrayList<ArrayList<String>> dataSet,int index){
ArrayList<String> values=new ArrayList<String>();
for(ArrayList<String> data:dataSet){
try{
values.add(data.get(index));
}catch(Exception e){
System.out.println("index is "+index);
}
}
Set<String> set=new HashSet();
for(String value:values){
set.add(value);
}
return set;
}
public static ArrayList<String> copyArrayList(ArrayList<String> src){
ArrayList<String> dest=new ArrayList<String>();
for(String s:src){
dest.add(s);
}
return dest;
}
public static void showArrayList(ArrayList<ArrayList<String>> dataSet){
for(ArrayList<String> data:dataSet){
System.out.println(data);
}
}
}
public class DecisionTree {
public static int createTree(ArrayList<ArrayList<String>> dataSet,ArrayList<String> featureList,Element e){
ArrayList<String> labelList=Utils.getClassList(dataSet);//获取数据集中label的列表
if(Utils.arrayToMap(labelList).size()==1){//表示label中只有一种类别,所以此时不需要再分类了
e.addText(labelList.get(0));
return 1;
}
if(dataSet.get(0).size()==1){//表示此时已经没有特征了,所以也不需要再继续了,此时以label中最多的类别为该节点的类别
e.addText(Utils.major(labelList));
return 1;
}
ArrayList<String> subFeatureList=Utils.copyArrayList(featureList);
String feature=Utils.bestFeatureSplit(dataSet,featureList);
subFeatureList.remove(feature);
int index=featureList.indexOf(feature);
Set<String> valueSet=Utils.getValueFromDataSet(dataSet,index);
// Element next=e.addElement(feature);//原来的代码位置
for(String value:valueSet){
Element next=e.addElement(feature);//后来放到这里之后,xml的输出就正确了,原因在于每递归一次就需要创建一个element,所以应该在for内创建。
next.addAttribute("value",value);
ArrayList<ArrayList<String>> subDataSet=Utils.splitDataSet(dataSet,index,value);
createTree(subDataSet,subFeatureList,next);
}
return 1;
}
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String file="C:/Users/Administrator/Desktop/upload/DT.txt";
String xml="C:/Users/Administrator/Desktop/upload/DT1.xml";
ArrayList<ArrayList<String>> dataSet=Utils.loadDataSet(file);
ArrayList<String> featureList=Utils.loadFeature(file);
Document document = DocumentHelper.createDocument();
Element root = document.addElement("DecisionTree");
createTree(dataSet,featureList,root);
XMLWriter writer=new XMLWriter(new FileWriter(xml));
writer.write(document);
writer.close();
System.out.println("finished");
}
}这次除了算法上的理解更加深刻了外,在java上也学到了些关于xml解析,读写等方法。
另外对递归的使用也更加形象些,对于递归一个容易错的点就是函数上的参数,一定要认真对待,要清楚该参数该在什么时候初始化,什么时候被用到。我一开始在第269行上就出现错误了,一开始没有考虑清楚这个next该在什么时候分配,后来发现每次创建节点的时候我们在xml就要创建一个相应的节点用来描述他,所以应该是在for循环里面创建,如果在for外面创建就表示,该特征下的所有值都只有一个element。
当然对于set,map的遍历啥的也更加清晰了。

相关文章推荐
- 【j2ee spring】30、巴巴运动网-整合hibernate4+spring4(5)分页
- 【ssh2学习记录】2、struts.xml和struts.properties的编写注意事项
- ClassLoader加载指定的类需注意六个细节或报ClassNotFundEception异常总结
- [java设计模式]之单例模式
- struts2中action的配置
- SpringMVC应用
- java操作cookie
- Java代码设计思想之静态工厂方法..
- java之 ------ 可变参数和卫条件
- Java路径中的空格问题(转载)
- Java学习推荐书目
- at java.net.InetAddress.getLocalHost(InetAddress.java:1475)
- java NIO Netty实现原理浅析(转)
- Java NIO使用及原理分析 (四)
- 【JAVA入门】Hello world
- 在java中 i++和++i有什么区别
- Java复习
- Java synchronized
- java之集合
- Mac OS X终端(iterm) javac乱码的解决