java代码性能优化
2015-06-05 09:56
381 查看
衡量程序的标准
衡量一个程序是否优质,可以从多个角度进行分析。其中,最常见的衡量标准是程序的时间复杂度、空间复杂度,以及代码的可读性、可扩展性。针对程序的时间复杂度和空间复杂度,想要优化程序代码,需要对数据结构与算法有深入的理解,并且熟悉计算机系统的基本概念和原理;而针对代码的可读性和可扩展性,想要优化程序代码,需要深入理解软件架构设计,熟知并会应用合适的设计模式。首先,如今计算机系统的存储空间已经足够大了,达到了 TB 级别,因此相比于空间复杂度,时间复杂度是程序员首要考虑的因素。为了追求高性能,在某些频繁操作执行时,甚至可以考虑用空间换取时间。其次,由于受到处理器制造工艺的物理限制、成本限制,CPU 主频的增长遇到了瓶颈,摩尔定律已渐渐失效,每隔 18 个月 CPU 主频即翻倍的时代已经过去了,程序员的编程方式发生了彻底的改变。在目前这个多核多处理器的时代,涌现了原生支持多线程的语言(如 Java)以及分布式并行计算框架(如 Hadoop)。为了使程序充分地利用多核 CPU,简单地实现一个单线程的程序是远远不够的,程序员需要能够编写出并发或者并行的多线程程序。最后,大型软件系统的代码行数达到了百万级,如果没有一个设计良好的软件架构,想在已有代码的基础上进行开发,开发代价和维护成本是无法想象的。一个设计良好的软件应该具有可读性和可扩展性,遵循“开闭原则”、“依赖倒置原则”、“面向接口编程”等。
回页首
项目介绍
本文将介绍笔者经历的一个项目中的一部分,通过这个实例剖析代码优化的过程。下面简要地介绍该系统的相关部分。该系统的开发语言为 Java,部署在共拥有 4 核 CPU 的 Linux 服务器上,相关部分主要有以下操作:通过某外部系统 D 提供的 REST API 获取信息,从中提取出有效的信息,并通过 JDBC 存储到某数据库系统 S 中,供系统其他部分使用,上述操作的执行频率为每天一次,一般在午夜当系统空闲时定时执行。为了实现高可用性(High Availability),外部系统 D 部署在两台服务器上,因此需要分别从这两台服务器上获取信息并将信息插入数据库中,有效信息的条数达到了上千条,数据库插入操作次数则为有效信息条数的两倍。
图 1. 系统体系结构图
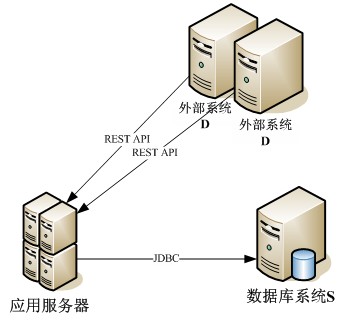
为了快速地实现预期效果,在最初的实现中优先考虑了功能的实现,而未考虑系统性能和代码可读性等。系统大致有以下的实现:(1)REST API 获取信息、数据库操作可能抛出的异常信息都被记录到日志文件中,作为调试用;(2)共有 5 次数据库连接操作,包括第一次清空数据库表,针对两个外部系统 D 各有两次数据库插入操作,这 5 个连接都是独立的,用完之后即释放;(3)所有的数据库插入语句都是使用 java.sql.Statement 类生成的;(4)所有的数据库插入语句,都是单条执行的,即生成一条执行一条;(5)整个过程都是在单个线程中执行的,包括数据库表清空操作,数据库插入操作,释放数据库连接;(6)数据库插入操作的 JDBC 代码散布在代码中。虽然这个版本的系统可以正常运行,达到了预期的效果,但是效率很低,从通过 REST API 获取信息,到解析并提取有效信息,再到数据库插入操作,总共耗时 100 秒左右。而预期的时间应该在一分钟以内,这显然是不符合要求的。
回页首
代码优化过程
笔者开始分析整个过程有哪些耗时操作,以及如何提升效率,缩短程序执行的时间。通过 REST API 获取信息,因为是使用外部系统提供的 API,所以无法在此处提升效率;取得信息之后解析出有效部分,因为是对特定格式的信息进行解析,所以也无效率提升的空间。所以,效率可以大幅度提升的空间在数据库操作部分以及程序控制部分。下面,分条叙述对耗时操作的改进方法。针对日志记录的优化
关闭日志记录,或者更改日志输出级别。因为从两台服务器的外部系统 D 上获取到的信息是相同的,所以数据库插入操作会抛出异常,异常信息类似于“Attempt to insert duplicate record”,这样的异常信息跟有效信息的条数相等,有上千条。这种情况是能预料到的,所以可以考虑关闭日志记录,或者不关闭日志记录而是更改日志输出级别,只记录严重级别(severe level)的错误信息,并将此类操作的日志级别调整为警告级别(warning level),这样就不会记录以上异常信息了。本项目使用的是 Java 自带的日志记录类,以下配置文件将日志输出级别设置为严重级别。清单 1. log.properties 设置日志输出级别的片段
# default file output is in user ’ s home directory. # levels can be: SEVERE, WARNING, INFO, FINE, FINER, FINEST java.util.logging.ConsoleHandler.level=SEVERE java.util.logging.FileHandler.formatter=java.util.logging.SimpleFormatter java.util.logging.FileHandler.append=true
通过上述的优化之后,性能有了大幅度的提升,从原来的 100 秒左右降到了 50 秒左右。为什么仅仅不记录日志就能有如此大幅度的性能提升呢?查阅资料,发现已经有人做了相关的研究与实验。经常听到 Java 程序比 C/C++ 程序慢的言论,但是运行速度慢的真正原因是什么,估计很多人并不清楚。对于 CPU 密集型的程序(即程序中包含大量计算),Java 程序可以达到 C/C++ 程序同等级别的速度,但是对于 I/O 密集型的程序(即程序中包含大量 I/O 操作),Java 程序的速度就远远慢于 C/C++ 程序了,很大程度上是因为 C/C++ 程序能直接访问底层的存储设备。因此,不记录日志而得到大幅度性能提升的原因是,Java 程序的 I/O 操作较慢,是一个很耗时的操作。
针对数据库连接的优化
共享数据库连接。共有 5 次数据库连接操作,每次都需重新建立数据库连接,数据库插入操作完成之后又立即释放了,数据库连接没有被复用。为了做到共享数据库连接,可以通过单例模式(Singleton Pattern)获得一个相同的数据库连接,每次数据库连接操作都共享这个数据库连接。这里没有使用数据库连接池(Database Connection Pool)是因为在程序只有少量的数据库连接操作,只有在大量并发数据库连接的时候才需要连接池。清单 2. 共享数据库连接的代码片段
public class JdbcUtil {
private static Connection con;
// 从配置文件读取连接数据库的信息
private static String driverClassName;
private static String url;
private static String username;
private static String password;
private static String currentSchema;
private static Properties properties = new Properties();
static {
// driverClassName, url, username, password, currentSchema 等从配置文件读取,代码略去
try {
Class.forName(driverClassName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
properties.setProperty("user", username);
properties.setProperty("password", password);
properties.setProperty("currentSchema", currentSchema);
try {
con = DriverManager.getConnection(url, properties);
} catch (SQLException e) {
e.printStackTrace();
}
}
private JdbcUtil() {}
// 获得一个单例的、共享的数据库连接
public static Connection getConnection() {
return con;
}
public static void close() throws SQLException {
if (con != null)
con.close();
}
}通过上述的优化之后,性能有了小幅度的提升,从 50 秒左右降到了 40 秒左右。共享数据库连接而得到的性能提升的原因是,数据库连接是一个耗时耗资源的操作,需要同远程计算机进行网络通信,建立 TCP 连接,还需要维护连接状态表,建立数据缓冲区。如果共享数据库连接,则只需要进行一次数据库连接操作,省去了多次重新建立数据库连接的时间。
针对插入数据库记录的优化 1
使用预编译 SQL。具体做法是使用 java.sql.PreparedStatement 代替 java.sql.Statement 生成 SQL 语句。PreparedStatement 使得数据库预先编译好 SQL 语句,可以传入参数。而 Statement 生成的 SQL 语句在每次提交时,数据库都需进行编译。在执行大量类似的 SQL 语句时,可以使用 PreparedStatement 提高执行效率。使用 PreparedStatement 的另一个好处是不需要拼接 SQL 语句,代码的可读性更强。通过上述的优化之后,性能有了小幅度的提升,从 40 秒左右降到了 30~35 秒左右。清单 3. 使用 Statement 的代码片段
// 需要拼接 SQL 语句,执行效率不高,代码可读性不强
StringBuilder sql = new StringBuilder();
sql.append("insert into table1(column1,column2) values('");
sql.append(column1Value);
sql.append("','");
sql.append(column2Value);
sql.append("');");
Statement st;
try {
st = con.createStatement();
st.executeUpdate(sql.toString());
} catch (SQLException e) {
e.printStackTrace();
}清单 4. 使用 PreparedStatement 的代码片段
// 预编译 SQL 语句,执行效率高,可读性强 String sql = “insert into table1(column1,column2) values(?,?)”; PreparedStatement pst = con.prepareStatement(sql); pst.setString(1,column1Value); pst.setString(2,column2Value); pst.execute();
针对插入数据库记录的优化 2
使用 SQL 批处理。通过 java.sql.PreparedStatement 的 addBatch 方法将 SQL 语句加入到批处理,这样在调用 execute 方法时,就会一次性地执行 SQL 批处理,而不是逐条执行。通过上述的优化之后,性能有了小幅度的提升,从 30~35 秒左右降到了 30 秒左右。针对多线程的优化
使用多线程实现并发 / 并行。清空数据库表的操作、把从 2 个外部系统 D 取得的数据插入数据库记录的操作,是相互独立的任务,可以给每个任务分配一个线程执行。清空数据库表的操作应该先于数据库插入操作完成,可以通过 java.lang.Thread 类的 join 方法控制线程执行的先后次序。在单核 CPU 时代,操作系统中某一时刻只有一个线程在运行,通过进程 / 线程调度,给每个线程分配一小段执行的时间片,可以实现多个进程 / 线程的并发(concurrent)执行。而在目前的多核多处理器背景下,操作系统中同一时刻可以有多个线程并行(parallel)执行,大大地提高了计算速度。清单 5. 使用多线程的代码片段
Thread t0 = new Thread(new ClearTableTask());
Thread t1 = new Thread(new StoreServersTask(ADDRESS1));
Thread t2 = new Thread(new StoreServersTask(ADDRESS2));
try {
t0.start();
// 执行完清空操作后,再进行后续操作
t0.join();
t1.start();
t2.start();
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 断开数据库连接
try {
JdbcUtil.close();
} catch (SQLException e) {
e.printStackTrace();
}通过上述的优化之后,性能有了大幅度的提升,从 30 秒左右降到了 15 秒以下,10~15 秒之间。使用多线程而得到的性能提升的原因是,系统部署所在的服务器是多核多处理器的,使用多线程,给每个任务分配一个线程执行,可以充分地利用 CPU 计算资源。
笔者试着给每个任务分配两个线程执行,希望能使程序运行得更快,但是事与愿违,此时程序运行的时间反而比每个任务分配一个线程执行的慢,大约 20 秒。笔者推测,这是因为线程较多(相对于 CPU 的内核数),使得 CPU 忙于线程的上下文切换,过多的线程上下文切换使得程序的性能反而不如之前。因此,要根据实际的硬件环境,给任务分配适量的线程执行。
针对设计模式的优化
使用 DAO 模式抽象出数据访问层。原来的代码中混杂着 JDBC 操作数据库的代码,代码结构显得十分凌乱。使用 DAO 模式(Data Access Object Pattern)可以抽象出数据访问层,这样使得程序可以独立于不同的数据库,即便访问数据库的代码发生了改变,上层调用数据访问的代码无需改变。并且程序员可以摆脱单调繁琐的数据库代码的编写,专注于业务逻辑层面的代码的开发。通过上述的优化之后,性能并未有提升,但是代码的可读性、可扩展性大大地提高了。图 2. DAO 模式的层次结构

清单 6. 使用 DAO 模式的代码片段
// DeviceDAO.java,定义了 DAO 抽象,上层的业务逻辑代码引用该接口,面向接口编程
public interface DeviceDAO {
public void add(Device device);
}
// DeviceDAOImpl.java,DAO 实现,具体的 SQL 语句和数据库操作由该类实现
public class DeviceDAOImpl implements DeviceDAO {
private Connection con;
public DeviceDAOImpl() {
// 获得数据库连接,代码略去
}
@Override
public void add(Device device) {
// 使用 PreparedStatement 进行数据库插入记录操作,代码略去
}
}回顾以上代码优化过程:关闭日志记录、共享数据库连接、使用预编译 SQL、使用 SQL 批处理、使用多线程实现并发 / 并行、使用 DAO 模式抽象出数据访问层,程序运行时间从最初的 100 秒左右降低到 15 秒以下,在性能上得到了很大的提升,同时也具有了更好的可读性和可扩展性。
一、避免在循环条件中使用复杂表达式在不做编译优化的情况下,在循环中,循环条件会被反复计算,如果不使用复杂表达式,而使循环条件值不变的话,程序将会运行的更快。例子: import java.util.Vector; class CEL { void method (Vector vector) { for (int i = 0; i < vector.size (); i++) // Violation ; // ... } } |
class CEL_fixed {
void method (Vector vector) {
int size = vector.size ()
for (int i = 0; i < size; i++)
; // ...
}
}
二、为'Vectors' 和 'Hashtables'定义初始大小
JVM为Vector扩充大小的时候需要重新创建一个更大的数组,将原原先数组中的内容复制过来,最后,原先的数组再被回收。可见Vector容量的扩大是一个颇费时间的事。通常,默认的10个元素大小是不够的。你最好能准确的估计你所需要的最佳大小。
例子:
import java.util.Vector;
public class DIC {
public void addObjects (Object[] o) {
// if length > 10, Vector needs to expand
for (int i = 0; i< o.length;i++) {
v.add(o); // capacity before it can add more elements.
}
}
public Vector v = new Vector(); // no initialCapacity.
}
更正:
自己设定初始大小。
public Vector v = new Vector(20);
public Hashtable hash = new Hashtable(10);
参考资料:
Dov Bulka, "Java Performance and Scalability Volume 1: Server-Side Programming
Techniques" Addison Wesley, ISBN: 0-201-70429-3 pp.55 ?C 57
三、在finally块中关闭Stream
程序中使用到的资源应当被释放,以避免资源泄漏。这最好在finally块中去做。不管程序执行的结果如何,finally块总是会执行的,以确保资源的正确关闭。例子:
import java.io.*;
public class CS {
public static void main (String args[]) {
CS cs = new CS ();
cs.method ();
}
public void method () {
try {
FileInputStream fis = new FileInputStream ("CS.java");
int count = 0;
while (fis.read () != -1)
count++;
System.out.println (count);
fis.close ();
} catch (FileNotFoundException e1) {
} catch (IOException e2) {
}
}
}
更正:
在最后一个catch后添加一个finally块
参考资料:
Peter Haggar: "Practical Java - Programming Language Guide".
Addison Wesley, 2000, pp.77-79
四、使用'System.arraycopy ()'代替通过循环复制数组
'System.arraycopy ()' 要比通过循环来复制数组快的多。例子:
public class IRB
{
void method () {
int[] array1 = new int [100];
for (int i = 0; i < array1.length; i++) {
array1 [i] = i;
}
int[] array2 = new int [100];
for (int i = 0; i < array2.length; i++) {
array2 [i] = array1 [i]; // Violation
}
}
}
更正:
public class IRB
{
void method () {
int[] array1 = new int [100];
for (int i = 0; i < array1.length; i++) {
array1 [i] = i;
}
int[] array2 = new int [100];
System.arraycopy(array1, 0, array2, 0, 100);
}
}
参考资料: http://www.cs.cmu.edu/~jch/java/speed.html
五、让访问实例变量的getter/setter方法变成”final”
简单的getter/setter方法应该被置成final,这会告诉编译器,这个方法不会被重载,所以,可以变成”inlined”例子:
class MAF {
public void setSize (int size) {
_size = size;
}
private int _size;
}
更正:
class DAF_fixed {
final public void setSize (int size) {
_size = size;
}
private int _size;
}
参考资料:
Warren N. and Bishop P. (1999), "Java in Practice", p. 4-5
Addison-Wesley, ISBN 0-201-36065-9
六、避免不需要的instanceof操作
如果左边的对象的静态类型等于右边的,instanceof表达式返回永远为true。例子:
public class UISO {
public UISO () {}
}
class Dog extends UISO {
void method (Dog dog, UISO u) {
Dog d = dog;
if (d instanceof UISO) // always true.
System.out.println("Dog is a UISO");
UISO uiso = u;
if (uiso instanceof Object) // always true.
System.out.println("uiso is an Object");
}
}
更正:
删掉不需要的instanceof操作。
class Dog extends UISO {
void method () {
Dog d;
System.out.println ("Dog is an UISO");
System.out.println ("UISO is an UISO");
}
}
七、避免不需要的造型操作
所有的类都是直接或者间接继承自Object。同样,所有的子类也都隐含的“等于”其父类。那么,由子类造型至父类的操作就是不必要的了。例子:
class UNC {
String _id = "UNC";
}
class Dog extends UNC {
void method () {
Dog dog = new Dog ();
UNC animal = (UNC)dog; // not necessary.
Object o = (Object)dog; // not necessary.
}
}
更正:
class Dog extends UNC {
void method () {
Dog dog = new Dog();
UNC animal = dog;
Object o = dog;
}
}
参考资料:
Nigel Warren, Philip Bishop: "Java in Practice - Design Styles and Idioms
for Effective Java". Addison-Wesley, 1999. pp.22-23
八、如果只是查找单个字符的话,用charAt()代替startsWith()
用一个字符作为参数调用startsWith()也会工作的很好,但从性能角度上来看,调用用String API无疑是错误的!例子:
public class PCTS {
private void method(String s) {
if (s.startsWith("a")) { // violation
// ...
}
}
}
更正
将'startsWith()' 替换成'charAt()'.
public class PCTS {
private void method(String s) {
if ('a' == s.charAt(0)) {
// ...
}
}
}
参考资料:
Dov Bulka, "Java Performance and Scalability Volume 1: Server-Side Programming
Techniques" Addison Wesley, ISBN: 0-201-70429-3
九、使用移位操作来代替'a / b'操作
"/"是一个很“昂贵”的操作,使用移位操作将会更快更有效。例子:
public class SDIV {
public static final int NUM = 16;
public void calculate(int a) {
int div = a / 4; // should be replaced with "a >> 2".
int div2 = a / 8; // should be replaced with "a >> 3".
int temp = a / 3;
}
}
更正:
public class SDIV {
public static final int NUM = 16;
public void calculate(int a) {
int div = a >> 2;
int div2 = a >> 3;
int temp = a / 3; // 不能转换成位移操作
}
}
十、使用移位操作代替'a * b'
同上。[i]但我个人认为,除非是在一个非常大的循环内,性能非常重要,而且你很清楚你自己在做什么,方可使用这种方法。否则提高性能所带来的程序晚读性的降低将是不合算的。
例子:
public class SMUL {
public void calculate(int a) {
int mul = a * 4; // should be replaced with "a << 2".
int mul2 = 8 * a; // should be replaced with "a << 3".
int temp = a * 3;
}
}
更正:
package OPT;
public class SMUL {
public void calculate(int a) {
int mul = a << 2;
int mul2 = a << 3;
int temp = a * 3; // 不能转换
}
}
十一、在字符串相加的时候,使用 ' ' 代替 " ",如果该字符串只有一个字符的话
例子:public class STR {
public void method(String s) {
String string = s + "d" // violation.
string = "abc" + "d" // violation.
}
}
更正:
将一个字符的字符串替换成' '
public class STR {
public void method(String s) {
String string = s + 'd'
string = "abc" + 'd'
}
}
十二、不要在循环中调用synchronized(同步)方法
方法的同步需要消耗相当大的资料,在一个循环中调用它绝对不是一个好主意。例子:
import java.util.Vector;
public class SYN {
public synchronized void method (Object o) {
}
private void test () {
for (int i = 0; i < vector.size(); i++) {
method (vector.elementAt(i)); // violation
}
}
private Vector vector = new Vector (5, 5);
}
更正:
不要在循环体中调用同步方法,如果必须同步的话,推荐以下方式:
import java.util.Vector;
public class SYN {
public void method (Object o) {
}
private void test () {
synchronized{//在一个同步块中执行非同步方法
for (int i = 0; i < vector.size(); i++) {
method (vector.elementAt(i));
}
}
}
private Vector vector = new Vector (5, 5);
}
十三、将try/catch块移出循环
把try/catch块放入循环体内,会极大的影响性能,如果编译JIT被关闭或者你所使用的是一个不带JIT的JVM,性能会将下降21%之多!例子:
import java.io.FileInputStream;
public class TRY {
void method (FileInputStream fis) {
for (int i = 0; i < size; i++) {
try { // violation
_sum += fis.read();
} catch (Exception e) {}
}
}
private int _sum;
}
更正:
将try/catch块移出循环
void method (FileInputStream fis) {
try {
for (int i = 0; i < size; i++) {
_sum += fis.read();
}
} catch (Exception e) {}
}
参考资料:
Peter Haggar: "Practical Java - Programming Language Guide".
Addison Wesley, 2000, pp.81 ?C 83
十四、对于boolean值,避免不必要的等式判断
将一个boolean值与一个true比较是一个恒等操作(直接返回该boolean变量的值). 移走对于boolean的不必要操作至少会带来2个好处:1)代码执行的更快 (生成的字节码少了5个字节);
2)代码也会更加干净 。
例子:
public class UEQ
{
boolean method (String string) {
return string.endsWith ("a") == true; // Violation
}
}
更正:
class UEQ_fixed
{
boolean method (String string) {
return string.endsWith ("a");
}
}
十五、对于常量字符串,用'String' 代替 'StringBuffer'
常量字符串并不需要动态改变长度。例子:
public class USC {
String method () {
StringBuffer s = new StringBuffer ("Hello");
String t = s + "World!";
return t;
}
}
更正:
把StringBuffer换成String,如果确定这个String不会再变的话,这将会减少运行开销提高性能。
十六、用'StringTokenizer' 代替 'indexOf()' 和'substring()'
字符串的分析在很多应用中都是常见的。使用indexOf()和substring()来分析字符串容易导致StringIndexOutOfBoundsException。而使用StringTokenizer类来分析字符串则会容易一些,效率也会高一些。例子:
public class UST {
void parseString(String string) {
int index = 0;
while ((index = string.indexOf(".", index)) != -1) {
System.out.println (string.substring(index, string.length()));
}
}
}
参考资料:
Graig Larman, Rhett Guthrie: "Java 2 Performance and Idiom Guide"
Prentice Hall PTR, ISBN: 0-13-014260-3 pp. 282 ?C 283
十七、使用条件操作符替代"if (cond) return; else return;" 结构
条件操作符更加的简捷例子:
public class IF {
public int method(boolean isDone) {
if (isDone) {
return 0;
} else {
return 10;
}
}
}
更正:
public class IF {
public int method(boolean isDone) {
return (isDone ? 0 : 10);
}
}
十八、使用条件操作符代替"if (cond) a = b; else a = c;" 结构
例子:public class IFAS {
void method(boolean isTrue) {
if (isTrue) {
_value = 0;
} else {
_value = 1;
}
}
private int _value = 0;
}
更正:
public class IFAS {
void method(boolean isTrue) {
_value = (isTrue ? 0 : 1); // compact expression.
}
private int _value = 0;
}
十九、不要在循环体中实例化变量
在循环体中实例化临时变量将会增加内存消耗例子:
import java.util.Vector;
public class LOOP {
void method (Vector v) {
for (int i=0;i < v.size();i++) {
Object o = new Object();
o = v.elementAt(i);
}
}
}
更正:
在循环体外定义变量,并反复使用
import java.util.Vector;
public class LOOP {
void method (Vector v) {
Object o;
for (int i=0;i<v.size();i++) {
o = v.elementAt(i);
}
}
}
二十、确定 StringBuffer的容量
StringBuffer的构造器会创建一个默认大小(通常是16)的字符数组。在使用中,如果超出这个大小,就会重新分配内存,创建一个更大的数组,并将原先的数组复制过来,再丢弃旧的数组。在大多数情况下,你可以在创建StringBuffer的时候指定大小,这样就避免了在容量不够的时候自动增长,以提高性能。例子:
public class RSBC {
void method () {
StringBuffer buffer = new StringBuffer(); // violation
buffer.append ("hello");
}
}
更正:
为StringBuffer提供寝大小。
public class RSBC {
void method () {
StringBuffer buffer = new StringBuffer(MAX);
buffer.append ("hello");
}
private final int MAX = 100;
}
参考资料:
Dov Bulka, "Java Performance and Scalability Volume 1: Server-Side Programming
Techniques" Addison Wesley, ISBN: 0-201-70429-3 p.30 ?C 31
二十一、尽可能的使用栈变量
如果一个变量需要经常访问,那么你就需要考虑这个变量的作用域了。static? local?还是实例变量?访问静态变量和实例变量将会比访问局部变量多耗费2-3个时钟周期。例子:
public class USV {
void getSum (int[] values) {
for (int i=0; i < value.length; i++) {
_sum += value[i]; // violation.
}
}
void getSum2 (int[] values) {
for (int i=0; i < value.length; i++) {
_staticSum += value[i];
}
}
private int _sum;
private static int _staticSum;
}
更正:
如果可能,请使用局部变量作为你经常访问的变量。
你可以按下面的方法来修改getSum()方法:
void getSum (int[] values) {
int sum = _sum; // temporary local variable.
for (int i=0; i < value.length; i++) {
sum += value[i];
}
_sum = sum;
}
参考资料:
Peter Haggar: "Practical Java - Programming Language Guide".
Addison Wesley, 2000, pp.122 ?C 125
二十二、不要总是使用取反操作符(!)
取反操作符(!)降低程序的可读性,所以不要总是使用。例子:
public class DUN {
boolean method (boolean a, boolean b) {
if (!a)
return !a;
else
return !b;
}
}
更正:
如果可能不要使用取反操作符(!)
二十三、与一个接口 进行instanceof操作
基于接口的设计通常是件好事,因为它允许有不同的实现,而又保持灵活。只要可能,对一个对象进行instanceof操作,以判断它是否某一接口要比是否某一个类要快。例子:
public class INSOF {
private void method (Object o) {
if (o instanceof InterfaceBase) { } // better
if (o instanceof ClassBase) { } // worse.
}
}
class ClassBase {}
interface InterfaceBase {}
1. 时间优化
1.1 标准代码优化
a. 将循环不变量的计算移出循环
我写了一个测试例子如下:

import util.StopWatch; /** * 循环优化:
* 除了本例中将循环不变量移出循环外,还有将忙循环放在外层
* @author jxqlovejava
* */ public class LoopOptimization { public int size() { try {
Thread.sleep(200); // 模拟耗时操作 } catch(InterruptedException ie) {
} return 10;
} public void slowLoop() {
StopWatch sw = new StopWatch("slowLoop");
sw.start(); for(int i = 0; i < size(); i++);
sw.end();
sw.printEclapseDetail();
} public void optimizeLoop() {
StopWatch sw = new StopWatch("optimizeLoop");
sw.start(); // 将循环不变量移出循环 for(int i = 0, stop = size(); i < stop; i++);
sw.end();
sw.printEclapseDetail();
} public static void main(String[] args) {
LoopOptimization loopOptimization = new LoopOptimization();
loopOptimization.slowLoop();
loopOptimization.optimizeLoop();
}
}测试结果如下:
slowLoop任务耗时(毫秒):2204 optimizeLoop任务耗时(毫秒):211
可以很清楚地看到不提出循环不变量比提出循环不变量要慢10倍,在循环次数越大并且循环不变量的计算越耗时的情况下,这种优化会越明显。
b. 避免重复计算
这条太常见,不举例了
c. 尽量减少数组索引访问次数,数组索引访问比一般的变量访问要慢得多
数组索引访问比如int i = array[0];需要进行一次数组索引访问(和数组索引访问需要检查索引是否越界有关系吧)。这条Tip经过我的测试发现效果不是很明显(但的确有一些时间性能提升),可能在数组是大数组、循环次数比较多的情况下更明显。测试代码如下:
import util.StopWatch; /** * 数组索引访问优化,尤其针对多维数组
* 这条优化技巧对时间性能提升不太明显,而且可能降低代码可读性
* @author jxqlovejava
* */ public class ArrayIndexAccessOptimization { private static final int m = 9; // 9行 private static final int n = 9; // 9列 private static final int[][] array = {
{ 1, 2, 3, 4, 5, 6, 7, 8, 9 },
{ 11, 12, 13, 14, 15, 16, 17, 18, 19 },
{ 21, 22, 23, 24, 25, 26, 27, 28, 29 },
{ 31, 32, 33, 34, 35, 36, 37, 38, 39 },
{ 41, 42, 43, 44, 45, 46, 47, 48, 49 },
{ 51, 52, 53, 54, 55, 56, 57, 58, 59 },
{ 61, 62, 63, 64, 65, 66, 67, 68, 69 },
{ 71, 72, 73, 74, 75, 76, 77, 78, 79 },
{ 81, 82, 83, 84, 85, 86, 87, 88, 89 },
{ 91, 92, 93, 94, 95, 96, 97, 98, 99 }
}; // 二维数组 public void slowArrayAccess() {
StopWatch sw = new StopWatch("slowArrayAccess");
sw.start(); for(int k = 0; k < 10000000; k++) { int[] rowSum = new int[m]; for(int i = 0; i < m; i++) { for(int j = 0; j < n; j++) {
rowSum[i] += array[i][j];
}
}
}
sw.end();
sw.printEclapseDetail();
} public void optimizeArrayAccess() {
StopWatch sw = new StopWatch("optimizeArrayAccess");
sw.start(); for(int k = 0; k < 10000000; k++) { int[] rowSum = new int
; for(int i = 0; i < m; i++) { int[] arrI = array[i]; int sum = 0; for(int j = 0; j < n; j++) {
sum += arrI[j];
}
rowSum[i] = sum;
}
}
sw.end();
sw.printEclapseDetail();
} public static void main(String[] args) {
ArrayIndexAccessOptimization arrayIndexAccessOpt = new ArrayIndexAccessOptimization();
arrayIndexAccessOpt.slowArrayAccess();
arrayIndexAccessOpt.optimizeArrayAccess();
}
}d. 将常量声明为final static或者final,这样编译器就可以将它们内联并且在编译时就预先计算好它们的值
e. 用switch-case替代冗长的if-else-if
测试代码如下,但优化效果不明显:
import util.StopWatch; /** * 优化效果不明显
* @author jxqlovejava
* */ public class IfElseOptimization { public void slowIfElse() {
StopWatch sw = new StopWatch("slowIfElse");
sw.start(); for(int k = 0; k < 2000000000; k++) { int i = 9; if(i == 0) { } else if(i == 1) { } else if(i == 2) { } else if(i == 3) { } else if(i == 4) { } else if(i == 5) { } else if(i == 6) { } else if(i == 7) { } else if(i == 8) { } else if(i == 9) { }
}
sw.end();
sw.printEclapseDetail();
} public void optimizeIfElse() {
StopWatch sw = new StopWatch("optimizeIfElse");
sw.start(); for(int k = 0; k < 2000000000; k++) { int i = 9; switch(i) { case 0: break; case 1: break; case 2: break; case 3: break; case 4: break; case 5: break; case 6: break; case 7: break; case 8: break; case 9: break; default:
}
}
sw.end();
sw.printEclapseDetail();
} public static void main(String[] args) {
IfElseOptimization ifElseOpt = new IfElseOptimization();
ifElseOpt.slowIfElse();
ifElseOpt.optimizeIfElse();
}
}f. 如果冗长的if-else-if无法被switch-case替换,那么可以使用查表法优化
1.2 域和变量优化
a. 访问局部变量和方法参数比访问实例变量和类变量要快得多
b. 在嵌套的语句块内部或者循环内部生命变量并没有什么运行时开销,所以应该尽量将变量声明得越本地化(local)越好,这甚至会有助于编译器优化你的程序,也提高了代码可读性
1.3 字符串操作优化
a. 避免频繁地通过+运算符进行字符串拼接(老生常谈),因为它会不断地生成新字符串对象,而生成字符串对象不仅耗时而且耗内存(一些OOM错误是由这种场景导致的)。而要使用StringBuilder的append方法
b. 但对于这种String s = "hello" + " world"; 编译器会帮我们优化成String s = "hello world";实际上只生成了一个字符串对象"hello world",所以这种没关系
c. 避免频繁地对字符串对象调用substring和indexOf方法
1.4 常量数组优化
a. 避免在方法内部声明一个只包含常量的数组,应该把数组提为全局常量数组,这样可以避免每次方法调用都生成数组对象的时间开销
b. 对于一些耗时的运算比如除法运算、MOD运算、Log运算,可以采用预先计算值来优化
1.5 方法优化
a. 被private final static修饰的方法运行更快
b. 如果确定一个类的方法不需要被子类重写,那么将方法用final修饰,这样更快
c. 尽量使用接口作为方法参数或者其他地方,而不是接口的具体实现,这样也更快
1.6 排序和查找优化
a. 除非数组或者链表元素很少,否则不要使用选择排序、冒泡排序和插入排序。使用堆排序、归并排序和快速排序。
b. 更推荐的做法是使用JDK标准API内置的排序方法,时间复杂度为O(nlog(n))
对数组排序用Arrays.sort(它的实现代码使用改良的快速排序算法,不会占用额外内存空间,但是不稳定)
对链表排序用Collections.sort(稳定算法,但会使用额外内存空间)
c. 避免对数组和链表进行线性查找,除非你明确知道要查找的次数很少或者数组和链表长度很短
对于数组使用Arrays.binarySearch,但前提是数组已经有序,并且数组如包含多个要查找的元素,不能保证返回哪一个的index
对于链表使用Collections.binarySearch,前提也是链表已经有序
使用哈希查找:HashSet<T>、HashMap<K, V>等
使用二叉查找树:TreeSet<T>和TreeMap<K, V>,一般要提供一个Comparator作为构造函数参数,如果不提供则按照自然顺序排序
1.7 Exception优化
a. new Exception(...)会构建一个异常堆栈路径,非常耗费时间和空间,尤其是在递归调用的时候。创建异常对象一般比创建普通对象要慢30-100倍。自定义异常类时,层级不要太多。
b. 可以通过重写Exception类的fillInStackTrace方法而避免过长堆栈路径的生成
class MyException extends Exception { /** * */ private static final long serialVersionUID = -1515205444433997458L; public Throwable fillInStackTrace() { return this;
}
}c. 所以有节制地使用异常,不要将异常用于控制流程、终止循环等。只将异常用于意外和错误场景(文件找不到、非法输入格式等)。尽量复用之前创建的异常对象。
1.8 集合类优化
a. 如果使用HashSet或者HashMap,确保key对象有一个快速合理的hashCode实现,并且要遵守hashCode和equals实现规约
b. 如果使用TreeSet<T>或者TreeMap<K, V>,确保key对象有一个快速合理的compareTo实现;或者在创建TreeSet<T>或者TreeMap<K, V>时显式提供一个Comparator<T>
c. 对链表遍历优先使用迭代器遍历或者for(T x: lst),for(T x: lst)隐式地使用了迭代器来遍历链表。而对于数组遍历优先使用索引访问:for(int i = 0; i < array.length; i++)
d. 避免频繁调用LinkedList<T>或ArrayList<T>的remove(Object o)方法,它们会进行线性查找
e. 避免频繁调用LinkedList<T>的add(int i, T x)和remove(int i)方法,它们会执行线性查找来确定索引为i的元素
f. 最好避免遗留的集合类如Vector、Hashtable和Stack,因为它们的所有方法都用synchronized修饰,每个方法调用都必须先获得对象内置锁,增加了运行时开销。如果确实需要一个同步的集合,使用synchronziedCollection以及其他类似方法,或者使用ConcurrentHashMap
1.9 IO优化
a. 使用缓冲输入和输出(BufferedReader、BufferedWriter、BufferedInputStream和BufferedOutputStream)可以提升IO速度20倍的样子,我以前写过一个读取大文件(9M多,64位Mac系统,8G内存)的代码测试例子,如下:
import java.io.BufferedInputStream; import java.io.BufferedReader; import java.io.DataInputStream; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import util.StopWatch; public class ReadFileDemos { public static void main(String[] args) throws IOException {
String filePath = "C:\\Users\\jxqlovejava\\workspace\\PerformanceOptimization\\test.txt";
InputStream in = null;
BufferedInputStream bis = null;
File file = null;
StopWatch sw = new StopWatch();
sw.clear();
sw.setTaskName("一次性读取到字节数组+BufferedReader");
sw.start();
file = new File(filePath);
in = new FileInputStream(filePath);
BufferedReader br = new BufferedReader(new InputStreamReader(in)); char[] charBuf = new char[(int) file.length()];
br.read(charBuf);
br.close();
in.close();
sw.end();
sw.printEclapseDetail();
sw.clear();
sw.setTaskName("一次性读取到字节数组");
sw.start();
in = new FileInputStream(filePath); byte[] buf = new byte[in.available()];
in.read(buf);// read(byte[] buf)方法重载 in.close(); for (byte c : buf) {
}
sw.end();
sw.printEclapseDetail();
sw.clear();
sw.setTaskName("BufferedInputStream逐字节读取");
sw.start();
in = new FileInputStream(filePath);
bis = new BufferedInputStream(in); int b; while ((b = bis.read()) != -1);
in.close();
bis.close();
sw.end();
sw.printEclapseDetail();
sw.clear();
sw.setTaskName("BufferedInputStream+DataInputStream分批读取到字节数组");
sw.start();
in = new FileInputStream(filePath);
bis = new BufferedInputStream(in);
DataInputStream dis = new DataInputStream(bis); byte[] buf2 = new byte[1024*4]; // 4k per buffer int len = -1;
StringBuffer sb = new StringBuffer(); while((len=dis.read(buf2)) != -1 ) { // response.getOutputStream().write(b, 0, len); sb.append(new String(buf2));
}
dis.close();
bis.close();
in.close();
sw.end();
sw.printEclapseDetail();
sw.clear();
sw.setTaskName("FileInputStream逐字节读取");
sw.start();
in = new FileInputStream(filePath); int c; while ((c = in.read()) != -1);
in.close();
sw.end();
sw.printEclapseDetail();
}
}结果如下:
一次性读取到字节数组+BufferedReader任务耗时(毫秒):121 一次性读取到字节数组任务耗时(毫秒):23 BufferedInputStream逐字节读取任务耗时(毫秒):408 BufferedInputStream+DataInputStream分批读取到字节数组任务耗时(毫秒):147 FileInputStream逐字节读取任务耗时(毫秒):38122
b. 将文件压缩后存到磁盘,这样读取时更快,虽然会耗费额外的CPU来进行解压缩。网络传输时也尽量压缩后传输。Java中压缩有关的类:ZipInputStream、ZipOutputStream、GZIPInputStream和GZIPOutputStream
1.10 对象创建优化
a. 如果程序使用很多空间(内存),它一般也将耗费更多的时间:对象分配和垃圾回收需要耗费时间、使用过多内存可能导致不能很好利用CPU缓存甚至可能需要使用虚存(访问磁盘而不是RAM)。而且根据JVM的垃圾回收器的不同,使用太多内存可能导致长时间的回收停顿,这对于交互式系统和实时应用是不能忍受的。
b. 对象创建需要耗费时间(分配内存、初始化、垃圾回收等),所以避免不必要的对象创建。但是记住不要轻易引入对象池除非确实有必要。大部分情况,使用对象池仅仅会导致代码量增加和维护代价增大,并且对象池可能引入一些微妙的问题
c. 不要创建一些不会被使用到的对象
1.11 数组批量操作优化
数组批量操作比对数组进行for循环要快得多,部分原因在于数组批量操作只需进行一次边界检查,而对数组进行for循环,每一次循环都必须检查边界。
a. System.arrayCopy(src, si, dst, di, n) 从源数组src拷贝片段[si...si+n-1]到目标数组dst[di...di+n-1]
b. boolean Arrays.equals(arr1, arr2) 返回true,当且仅当arr1和arr2的长度相等并且元素一一对象相等(equals)
c. void Arrays.fill(arr, x) 将数组arr的所有元素设置为x
d. void Arrays.fill(arr, i, j x) 将数组arr的[i..j-1]索引处的元素设置为x
e. int Arrays.hashCode(arr) 基于数组的元素计算数组的hashcode
1.12 科学计算优化
Colt(http://acs.lbl.gov/software/colt/)是一个科学计算开源库,可以用于线性代数、稀疏和紧凑矩阵、数据分析统计,随机数生成,数组算法,代数函数和复数等。
1.13 反射优化
a. 通过反射创建对象、访问属性、调用方法比一般的创建对象、访问属性和调用方法要慢得多
b. 访问权限检查(反射调用private方法或者反射访问private属性时会进行访问权限检查,需要通过setAccessible(true)来达到目的)可能会让反射调用方法更慢,可以通过将方法声明为public来比避免一些开销。这样做之后可以提高8倍。
1.14 编译器和JVM平台优化
a. Sun公司的HotSpot Client JVM会进行一些代码优化,但一般将快速启动放在主动优化之前进行考虑
b. Sun公司的HotSpot Server JVM(-server选项,Windows平台无效)会进行一些主动优化,但可能带来更长的启动延迟
c. IBM的JVM也会进行一些主动优化
d. J2ME和一些手持设备(如PDA)不包含JIT编译,很可能不会进行任何优化
1.15 Profile
2. 空间优化
2.1 堆(对象)和栈(方法参数、局部变量等)。堆被所有线程共享,但栈被每个线程独享
2.2 空间消耗的三个重要方面是:Allocation Rate(分配频率)、Retention(保留率)和Fragmentation(内存碎片)
Allocation Rate是程序创建新对象的频率,频率越高耗费的时间和空间越多。
Retention是存活的堆数据数量。这个值越高需要耗费越多的空间和时间(垃圾回收器执行分配和去分配工作时需要进行更多的管理工作)
Fragmentation:内存碎片是指小块无法使用的内存。如果一直持续创建大对象,可能会引起过多的内存碎片。从而需要更多的时间分配内存(因为要查找一个足够大的连续可用内存块),并且会浪费更多的空间因为内存碎片无法被利用。当然某些GC算法可以避免过多内存碎片的产生,但相应的算法代价也较高。
2.3 内存泄露
2.4 垃圾回收器的种类(分代收集、标记清除、引用计数、增量收集、压缩...)对Allocation Rate、Retention和Fragmentation的时间空间消耗影响很大
2.5 对象延迟创建
附上StopWatch计时工具类:
/** * 秒表类,用于计算执行时间
* 注意该类是非线程安全的
* @author jxqlovejava
* */ public class StopWatch { private static final String DEFAULT_TASK_NAME = "defaultTask"; private String taskName; private long start, end; private boolean hasStarted, hasEnded; // 时间单位枚举:毫秒、秒和分钟 public enum TimeUnit { MILLI, SECOND, MINUTE } public StopWatch() { this(DEFAULT_TASK_NAME);
} public StopWatch(String taskName) { this.taskName = StringUtil.isEmpty(taskName) ? DEFAULT_TASK_NAME : taskName;
} public void start() {
start = System.currentTimeMillis();
hasStarted = true;
} public void end() { if(!hasStarted) { throw new IllegalOperationException("调用StopWatch的end()方法之前请先调用start()方法");
}
end = System.currentTimeMillis();
hasEnded = true;
} public void clear() { this.start = 0; this.end = 0; this.hasStarted = false; this.hasEnded = false;
} /** * 获取总耗时,单位为毫秒
* @return 消耗的时间,单位为毫秒 */ public long getEclapsedMillis() { if(!hasEnded) { throw new IllegalOperationException("请先调用end()方法");
} return (end-start);
} /** * 获取总耗时,单位为秒
* @return 消耗的时间,单位为秒 */ public long getElapsedSeconds() { return this.getEclapsedMillis() / 1000;
} /** * 获取总耗时,单位为分钟
* @return 消耗的时间,单位为分钟 */ public long getElapsedMinutes() { return this.getEclapsedMillis() / (1000*60);
} public void setTaskName(String taskName) { this.taskName = StringUtil.isEmpty(taskName) ? DEFAULT_TASK_NAME : taskName;
} public String getTaskName() { return this.taskName;
} /** * 输出任务耗时情况,单位默认为毫秒 */ public void printEclapseDetail() { this.printEclapseDetail(TimeUnit.MILLI);
} /** * 输出任务耗时情况,可以指定毫秒、秒和分钟三种时间单位
* @param timeUnit 时间单位 */ public void printEclapseDetail(TimeUnit timeUnit) { switch(timeUnit) { case MILLI:
System.out.println(this.getTaskName() + "任务耗时(毫秒):" + this.getEclapsedMillis()); break; case SECOND:
System.out.println(this.getTaskName() + "任务耗时(秒):" + this.getElapsedSeconds()); break; case MINUTE:
System.out.println(this.getTaskName() + "任务耗时(分钟):" + this.getElapsedMinutes()); break; default:
System.out.println(this.getTaskName() + "任务耗时(毫秒):" + this.getEclapsedMillis());
}
}
}一、通用篇
“通用篇”讨论的问题适合于大多数Java应用。
1.1 不用new关键词创建类的实例
用new关键词创建类的实例时,构造函数链中的所有构造函数都会被自动调用。但如果一个对象实现了Cloneable接口,我们可以调用它的clone()方法。clone()方法不会调用任何类构造函数。
在使用设计模式(Design Pattern)的场合,如果用Factory模式创建对象,则改用clone()方法创建新的对象实例非常简单。例如,下面是Factory模式的一个典型实现:
public static Credit getNewCredit() {
return new Credit();
}
改进后的代码使用clone()方法,如下所示:
private static Credit BaseCredit = new Credit();
public static Credit getNewCredit() {
return (Credit) BaseCredit.clone();
}
上面的思路对于数组处理同样很有用。
1.2 使用非阻塞I/O
版本较低的JDK不支持非阻塞I/O API。为避免I/O阻塞,一些应用采用了创建大量线程的办法(在较好的情况下,会使用一个缓冲池)。这种技术可以在许多必须支持并发I/O流的应用中见到,如Web服务器、报价和拍卖应用等。然而,创建Java线程需要相当可观的开销。
JDK 1.4引入了非阻塞的I/O库(java.nio)。如果应用要求使用版本较早的JDK,在这里有一个支持非阻塞I/O的软件包。
请参见Sun中国网站的《调整Java的I/O性能》。
1.3 慎用异常
异常对性能不利。抛出异常首先要创建一个新的对象。Throwable接口的构造函数调用名为fillInStackTrace()的本地(Native)方法,fillInStackTrace()方法检查堆栈,收集调用跟踪信息。只要有异常被抛出,VM就必须调整调用堆栈,因为在处理过程中创建了一个新的对象。
异常只能用于错误处理,不应该用来控制程序流程。
1.4 不要重复初始化变量
默认情况下,调用类的构造函数时, Java会把变量初始化成确定的值:所有的对象被设置成null,整数变量(byte、short、int、long)设置成0,float和 double变量设置成0.0,逻辑值设置成false。当一个类从另一个类派生时,这一点尤其应该注意,因为用new关键词创建一个对象时,构造函数链中的所有构造函数都会被自动调用。
1.5 尽量指定类的final修饰符
带有final修饰符的类是不可派生的。在Java核心API中,有许多应用final的例子,例如java.lang.String。为String类指定final防止了人们覆盖length()方法。
另外,如果指定一个类为final,则该类所有的方法都是final。Java编译器会寻找机会内联(inline)所有的final方法(这和具体的编译器实现有关)。此举能够使性能平均提高50%。
1.6 尽量使用局部变量
调用方法时传递的参数以及在调用中创建的临时变量都保存在栈(Stack)中,速度较快。其他变量,如静态变量、实例变量等,都在堆(Heap)中创建,速度较慢。另外,依赖于具体的编译器/JVM,局部变量还可能得到进一步优化。请参见《尽可能使用堆栈变量》。
1.7 乘法和除法
考虑下面的代码:
for (val = 0; val < 100000; val +=5) { alterX = val * 8; myResult = val * 2; }
用移位操作替代乘法操作可以极大地提高性能。下面是修改后的代码:
for (val = 0; val < 100000; val += 5) { alterX = val << 3; myResult = val << 1; }
修改后的代码不再做乘以8的操作,而是改用等价的左移3位操作,每左移1位相当于乘以2。相应地,右移1位操作相当于除以2。值得一提的是,虽然移位操作速度快,但可能使代码比较难于理解,所以最好加上一些注释。
性能优化的基本原则
Java 性能优化是一个持续不断的、通常历时很长且令人沮丧的过程。调优很少会一次性解决性能问题。有时,不管您添加了多少硬件,或者花了多长时间试图调整晦涩难懂的内存参数,可能都难以达到理想性能。要获得最佳性能,需要明确的性能目标、深思熟虑的设计、坚实的执行情况,并且最终要执行彻底的性能优化。首先要制定明确的性能目标
在采取任何步骤优化性能之前,首先要确定性能目标。这是因为预期的行为和用户数、数据量以及请求大小在很大程度上决定着您将作出什么类型的优化决策。每个环境都是唯一的,清楚地了解应用程序和环境的限制以及您希望达到的性能和负载水平,对于您日后深入过程将有所帮助。优化 WebLogic Server 设置
可以调整的 WebLogic 设置差不多有几百个:池大小、调整连接积压缓冲、缓存、JDBC 和 JMS 设置、使用工作管理器设置优先级、集群等。您可以先从查看 WebLogic Server 的几大优化建议开始。查找瓶颈
问题并不总是与 JVM 或 WebLogic 设置有关。请确保正确调整操作系统和网络设置以满足应用程序要求,尤其在使用 UNIX 或 Linux 时。在负载状态下监视服务器的磁盘和网络 I/O 以及 CPU 利用情况。如果数据库性能不佳,还应检查您的数据库块大小、池大小和其他特定于供应商的性能优化设置。任何基础资源限制都可能导致显著的性能下降。请记住,最终目的只是达到您的性能目标,而不是清除每一个瓶颈。系统中将始终存在一个瓶颈或最慢部分,但最要紧的是达到您的性能目标并使客户满意。
优化应用程序代码
设计应用程序时需要考虑性能因素,这一点是显而易见的。在当前的 SOA 环境中,应用程序很容易变得过于复杂,并存在很多影响性能的问题。设计不良的应用程序可能会引发系统资源、网络或数据库瓶颈。请使用经过验证的性能模式来设计应用程序,并使应用程序尽量简单。优化堆
无论使用什么应用程序,如果堆不足或花费大量时间进行垃圾收集,您都应该尝试调整整个堆及其新生代的大小。可用堆的大小通常会显著提高或降低应用程序的性能。为 WebLogic 服务器确定合适的堆大小对于提高性能非常重要。作为确定大小的一般规则,您希望在每次垃圾收集结束时释放大约一半的堆空间。换言之,即堆的大小应至少是其活动对象的两倍。
也许最基本的堆性能优化步骤是将最小堆大小设置成与最大堆大小相同。此建议同样适用于新生代(在 Sun HotSpot 中为 New generation,在 Oracle JRockit 中为 Nursery)大小的设置。默认情况下,经常出现堆扩展和堆收缩时 JVM 会浪费资源。
您尽可以将堆大小设置为系统可以处理的最大值(除去操作系统和其他应用程序所需的内存)。较大的堆会降低垃圾收集的频率,但可能需要花费较长时间来执行较大的垃圾收集。
VM 用于处理本地库和 permGen(如果使用 Sun HotSpot)的内存始终大于堆大小,因此请注意,不要超出物理 RAM 的总大小。操作系统将内存分页到磁盘时将显著降低性能。
试用垃圾收集器
垃圾收集是用于从不再使用的对象中回收堆空间的一种机制。有多种垃圾收集模式(从 JVM 到 JVM),这些模式都以不同方式使用系统资源。您在优化过程中的工作是确定什么类型的垃圾收集模式最适用于您的特定应用程序和性能目标。选择收集器时的目标就是使垃圾收集暂停时间尽量缩短,从而提高垃圾收集吞吐量。有关如何使用 JRockit 垃圾收集模式的信息,请参见“选择和优化垃圾收集器”部分。有关 Sun HotSpot VM 可用的垃圾收集模式的详细概述,请参见 Sun 的 Tuning Garbage Collection with the 5.0 Java Virtual Machine(使用 5.0 Java 虚拟机优化垃圾收集)。
其他注意事项
JRockit 和 Hotspot JVM 提供了许多特定的 JVM 性能选项。影响性能的 WebLogic 设置非常多。要进行有效优化,最重要的是使开发人员、架构师、系统工程师、QA 测试网络工程师和 DBA 作为一个团队进行协作。在优化过程中实现跨学科参与可以精简工作,获得更佳结果,从而最终降低优化所需的成本和时间。自动化的优点
我们已经了解了 WebLogic 性能优化的几个基本原则,现在来看一下自动执行这些任务如何真正使性能优化更容易、更省时、更有效。快速更改,频繁优化
我曾多次看到,自动执行性能优化过程所产生的结果比专家独自执行优化所产生的结果更好。这主要是因为,自动过程可以快速执行更改并确定和衡量更改对性能的影响,比神经最兴奋的人还要快,还要周到。另外,由于调优变成一个省力的过程,您还可以针对每次代码发布进行优化,从而与应用程序更改取得同步。对应用程序功能的细微更改都会导致很多预料不到的性能问题。另外,很多人错误地认为调优是可做可不做的事情,因为他们当前的响应时间很充裕。人们很容易忽略这样一个事实,即正确的调整可以提高服务器的稳定性和持久性。不调整或错误调整可能会导致故障,而经过正确调整的环境运行起来更具可预测性且更稳定。
节省时间,挖掘性能潜力
我们在优化服务器上通常做得不够频繁或不够彻底,仅仅因为这一过程非常费时。当您自动执行此过程时,手动执行需要几天时间的工作现在在无人干预的情况下一晚上即可完成。以前花无数个小时进行调优的人员现在可以节省这些时间做更有意义的事情。随着故障减少、性能提高、正确利用硬件、“繁重工作”减少以及可以利用节省的时间做更多工作,自动执行 Java 优化所带来的财务结余将会快速增长。在当今苛刻的环境中,性能上的细小收益通常都会带来显著的资源节省。
边看边学
了解代码更改和不同调优变量如何影响性能非常具有启发作用。自动执行优化和分析允许您尝试更多不同的设置组合,并且通过适当的监视,您可以同时看到结果。这就像站在性能专家团队的肩膀上;您开始了解为何作出某些优化决策,在这个过程中您能够学到很多知识。您还能够针对每次代码发布轻松地优化服务器,这也算是一个很不错的意外收获吧。由于知道将不会有惊喜,因此在部署生产时,您会拥有一个比较平和的心态。
逐步执行自动优化
在本部分中,您将了解使用 Arcturus Applicare 优化向导查找最佳 JVM 设置的过程。为了节省时间,我将演示测试各种垃圾收集设置的过程。简单来讲,优化向导将启动负载测试、监视服务器、分析行为、基于嵌入式智能作出决策、优化配置并回弹服务器。此过程将重复执行,自动优化各种 JVM、操作系统和 WebLogic 设置,直至找到最佳组合。以下是每个步骤的分解内容。
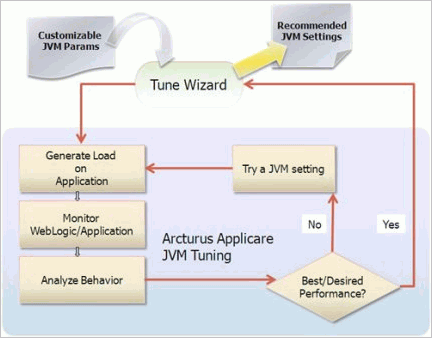
图 1. JVM 自动优化过程
由于自动执行时优化变得非常容易,因此您可能很快就希望进行微调和试验。在优化向导中,有很多可用于控制资源利用的高级选项,我将在后面进行详细介绍。与在任何性能优化过程中一样,您需要对应用程序行为有所了解。如果应用程序有预热时间或初始缓存时间段,必须确保运行足够时间的负载才能获取精确结果。
选择负载测试设置
优化向导与 Apache JMeter、HP Load Runner 和 The Grinder 负载生成工具进行了集成,它还能够触发您自己的自定义 Java 应用程序和 shell 脚本所生成的负载。我还没有生成负载工具设置或任何负载脚本,因此我使用 JMeter(系统自带)并遵循以下指令来记录测试脚本。启动优化向导时,我指定了负载脚本,它允许自定义要模拟的用户数。在本次测试中我选择了 70 个用户,因为根据以前的测试我知道,当用户数达到此数值时我的应用程序性能开始下降。
第一次优化服务器时,您可能不了解您的应用程序处理多少用户才会导致性能下降。如果我不清楚我的环境可以处理多少用户,我可能会使用一个称为“容量确定”的简洁功能(图 2),而不必进行猜测和购买更多服务器。容量确定的目的是找到良好吞吐量的最佳平衡,而不超出您的资源利用限制。容量确定允许您设置初始用户数和将要尝试的最大用户数,在优化时它将增加负载,直至在吞吐量和资源利用之间找到平衡点。
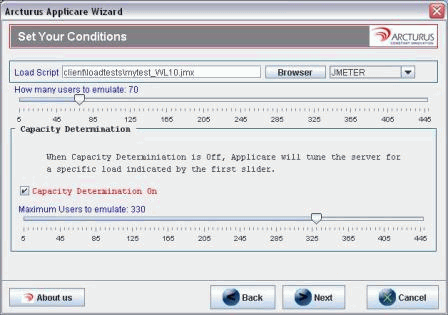
图 2. 自动执行容量确定功能
选择测试条件
接下来,您需要选择每个优化会话要采用的监视样例数,以及这些会话之间的时间间隔。正如我在前面提到的,如果您的应用程序有预热时间或初始缓存时间段,则此时您可以通过优化设置来确保测试时间足够长,以便得到精确的基准值。我选择每个会话采用 20 个样例,时间间隔为 60 秒。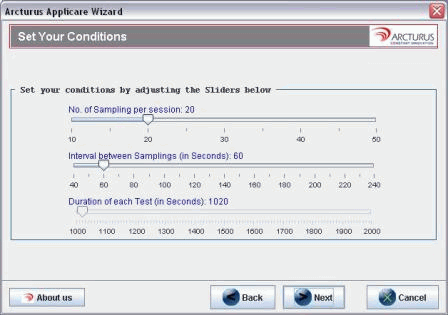
图 3. 由于应用程序各不相同,您可以根据需要调整样例数及样例时间间隔,以获得精确的基准值。
开始“执行”
现在您可以坐下来放松一下。您还可以安排在任意时间开始优化,这样,如果您要在以后的非高峰时间进行优化,则不必亲临现场。优化向导将尝试其中每个设置,当优化结束后,优化向导会生成报表,给出有关哪些设置提供最佳性能的建议。当服务器处于负载状态下时,优化向导将监视服务器的性能和运行情况。向导通过查看吞吐量、堆信息、CPU 利用情况、线程、等待者、队列(基本上包括了您所观察的全部内容 — 如果您亲自运行负载测试的话)完成此任务。在启动优化会话时可以设置和自定义样例之间的频率和时间间隔。
这是优化向导和 Applicare 其他功能最具吸引力、最有价值的一个方面。它随制定智能化性能优化决策的人工智能引擎一起提供。根据性能优化顾问的综合经验、经过验证的优化方法和最佳实践构建了知识库。可以查看负载测试过程中生成的数据,并对下一步将要优化的内容作出明智的决策。优化向导在达到最佳可能组合后,将结束优化过程。
我可以在 Applicare 控制台中实时查看进度表,也可以等到测试结束后查看报表。如果您要查看数据以便得出自己的结论,可以参考大量的报表和图表,它们针对每个优化设置的行为提供了完整的详细信息。
结果
在这里,我简要讨论优化结果,显示 Applicare 创建的一些有关优化会话的图表,并讨论 Applicare 给出的一些其他建议。这不是详尽的优化练习,但它显示了优化向导在少量负载状态下可以在短时间内完成的任务。优化过程历时 4 小时完成,它尝试了 9 个不同的设置组合,并优化了 JVM 设置和其他设置,包括线程、JDBC 设置等。优化向导查找过小或过大的配置区域并进行适当设置。根据我为优化向导提供尝试的参数,最佳设置如下:-Xms512m -Xmx512m -XX:CompileThreshold=8000 -XX:PermSize=48m -XX:MaxPermSize=128m -Xverify:none -XX:NewRatio=3 -XX:SurvivorRatio=6 -XX:+UseParallelGC
Applicare 提供一组显示优化结果的图表,为了节省空间,我给出了显示优化前后变化的吞吐量和堆图表。您可以看到堆的利用率较低,并且主要垃圾收集的暂停时间较短。您还可以看到,在主要垃圾收集发生时吞吐量下降,这表明优化前的初始设置在主要垃圾收集期间会导致很长的暂停时间。

图 4. 此图表显示优化后的吞吐量(蓝色)好于优化前的吞吐量(绿色)。
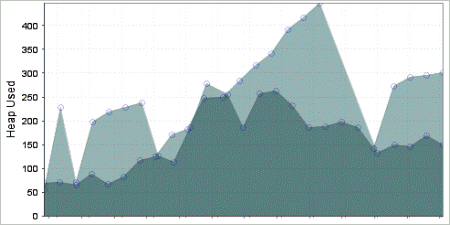
图 5. 会话之间的堆利用情况对比。优化后的最终结果是内存使用率较低。
其他建议
Applicare 还检测到应用程序运行时行为和服务器配置方面的问题。它检测出 EJB 缓存配置不当,并建议增加缓存大小。另外,Applicare 的诊断结果还指出,在优化过程中打开的会话数太多以致于影响了性能(有时超出 17,000 个会话)。它指出了一些实例,在这些实例中对我的应用程序的某些 Web 应用程序的会话失效间隔秒数设置过高,并建议进行重新评估,以免非活动会话打开时间过长。
幸运的是,我不必猜测或查找这些瓶颈,因为工具已将这些瓶颈清晰地显示出来。
高级选项
优化向导提供了一些预定义的选项,供每个 WebLogic 支持的 JVM 试用,以便找到适用于您的环境的最佳垃圾收集器,但它也为高级用户提供了尝试任意所需选项的灵活性。在此次测试中,我尝试了一些我自己的设置,向导仅用几个小时就找到了最佳设置,为我节省了很多精力。applicare.jvmparams.param6= -Xmn256m -Xss128k -XX\:+UseConcMarkSweepGC -XX\:+UseParNewGC -XX\:SurvivorRatio\=8 -XX\:TargetSurvivorRatio\=90 -XX\:MaxTenuringThreshold\=3 -Xms512m -Xmx512m -XX:CompileThreshold=8000 -XX:PermSize=48m -XX:MaxPermSize=128m -Xverify:none applicare.jvmparams.param5= -Xmn256m -Xss128k -XX\:+UseParallelGC -XX\:+UseParallelOldGC -XX\:+UseBiasedLocking -Xms512m -Xmx512m -XX:CompileThreshold=8000 -XX:PermSize=48m -XX:MaxPermSize=128m -Xverify:none applicare.jvmparams.param4= -Xmn256m -Xss128k -XX\:+UseParallelGC -XX\:+UseParallelOldGC -Xms512m -Xmx512m -XX:CompileThreshold=8000 -XX:PermSize=48m -XX:MaxPermSize=128m -Xverify:none applicare.jvmparams.param3= -XX\:NewRatio\=3 -XX\:SurvivorRatio\=6 -XX\:+UseConcMarkSweepGC -Xms512m -Xmx512m -XX:CompileThreshold=8000 -XX:PermSize=48m -XX:MaxPermSize=128m -Xverify:none applicare.jvmparams.param2=-XX\:NewRatio\=3 -XX\:SurvivorRatio\=6 -XX\:+UseParallelGC -Xms512m -Xmx512m -XX:CompileThreshold=8000 -XX:PermSize=48m -XX:MaxPermSize=128m -Xverify:none applicare.jvmparams.param1=-XX\:+UseParallelGC -XX\:MaxGCPauseMillis\=3 -Xms512m -Xmx512m -XX:CompileThreshold=8000 -XX:PermSize=48m -XX:MaxPermSize=128m -Xverify:none
您还可以配置在容量确定优化运行期间要利用的 CPU 数量。通常情况下,多个受管理服务器共处同一环境中,因此您自然希望限制负载状态下每个过程所占用的硬件空间。通过对可接受的队列长度、等待者数量和其他可配置选项进行限制,可以使工具满足您环境的独特优化需求。

相关文章推荐
- java中将param的值自动存到bean中
- Eclipse插件安装
- Flex调用Java异常处理
- java高分局之JVM命令参数大全(概述)
- spring配置声明式事物处理报错
- JDK7 AIO初体验
- Java TreeSet 介绍
- Java中栈的实现
- spring源码程序
- JDK8环境变量的配置
- java下拉框,滚动条
- spring mvc 和junit 4集成的注意点
- Java HashMap 介绍及使用
- Java 反射机制
- 让Eclipse和NetBeans共享同一个项目
- 【转】为什么做java的web开发我们会使用struts2,springMVC和spring这样的框架?
- java环境变量配置
- java SE 运算符(五)
- java随机数总结
- Java并发编程,并发编程大合集